
Figure 1:
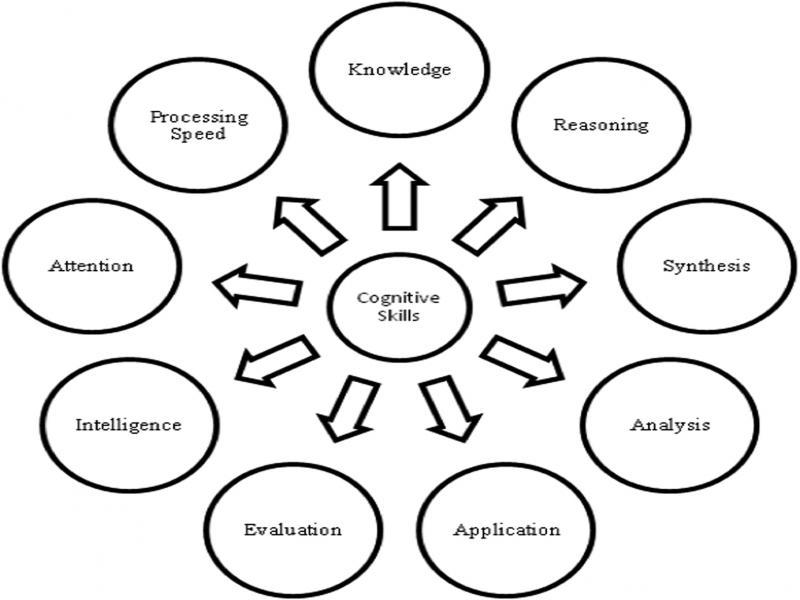
Figure 2:
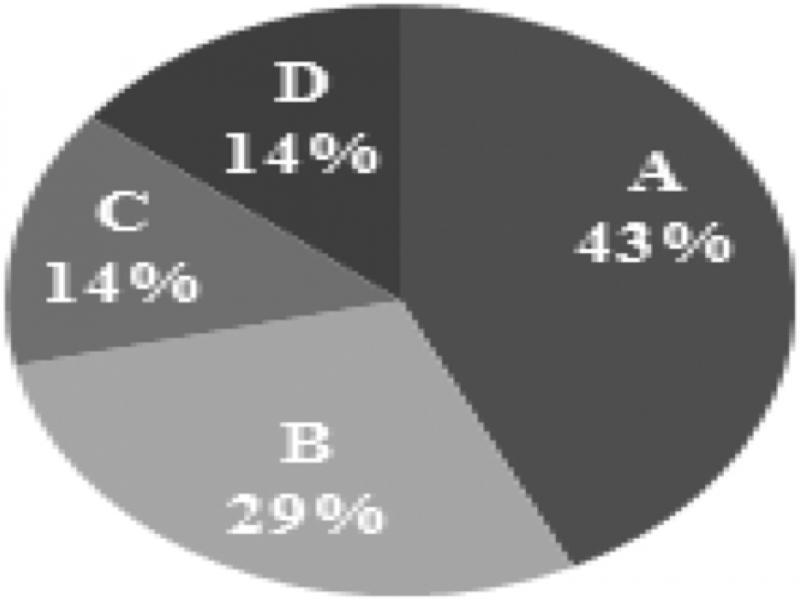
Figure 3:
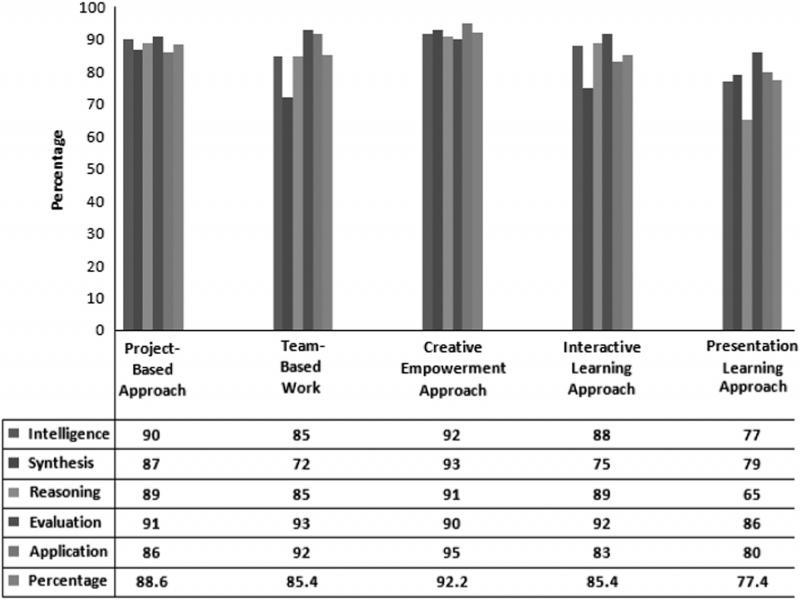
Figure 4:
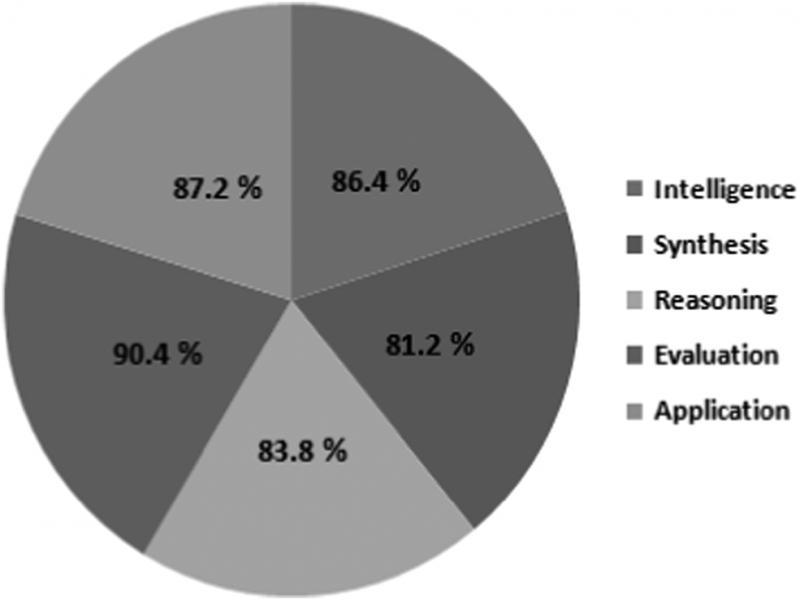
Figure 5:
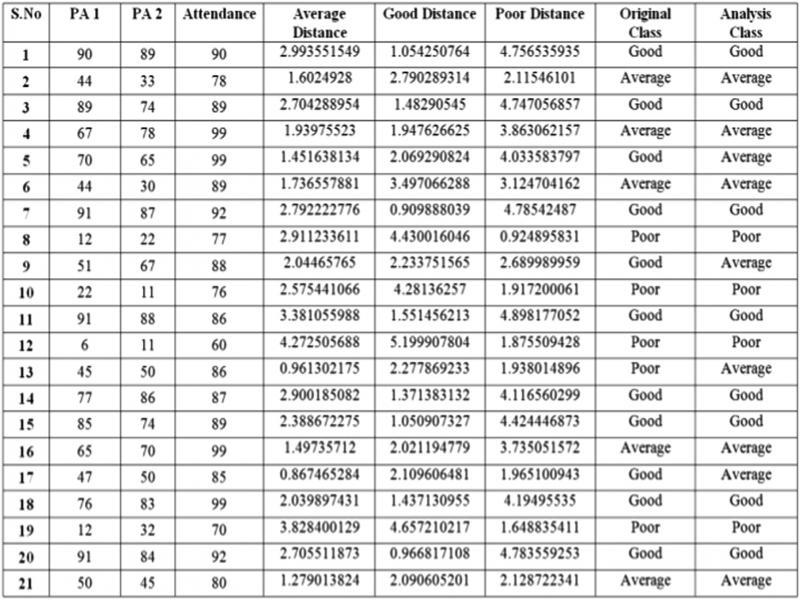
Figure 6:
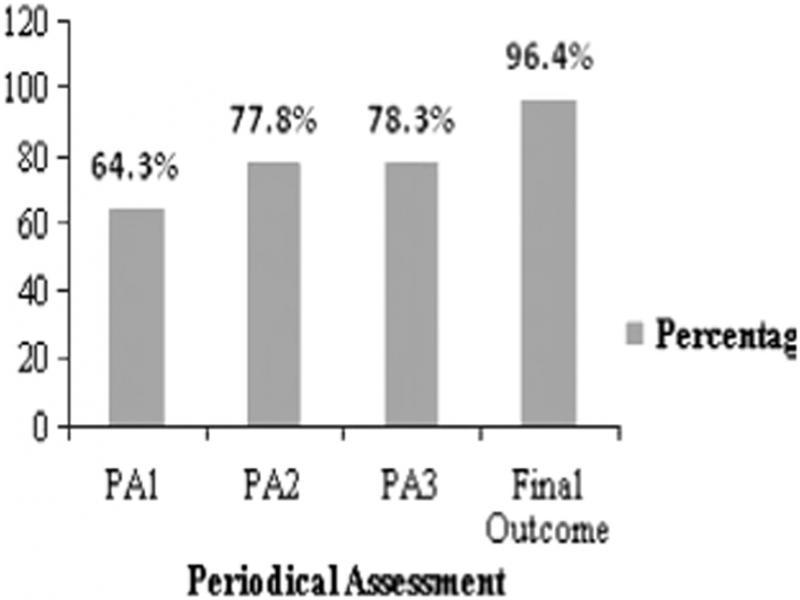
Figure 7:
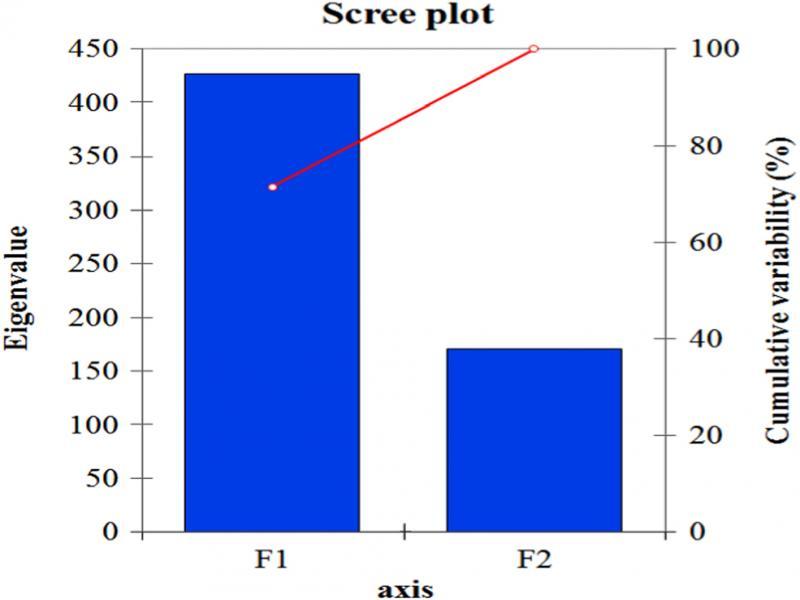
Figure 8:
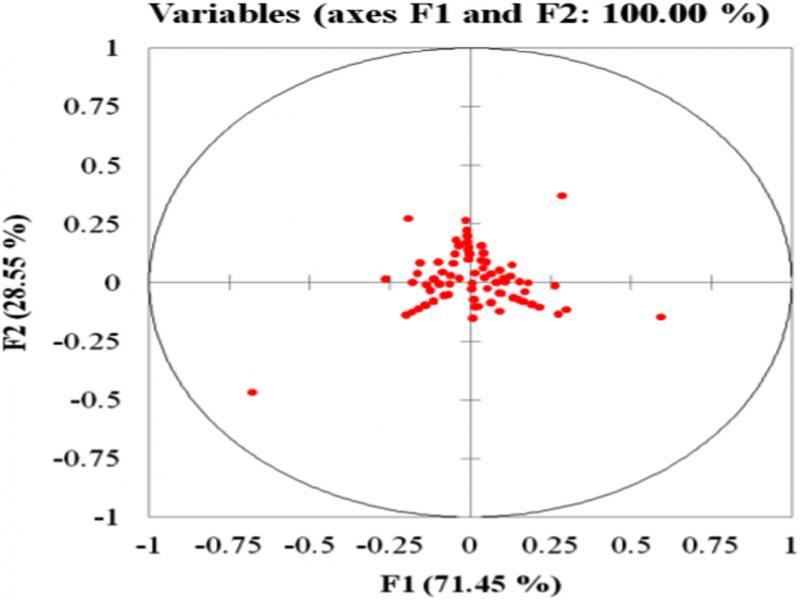
Figure 9:
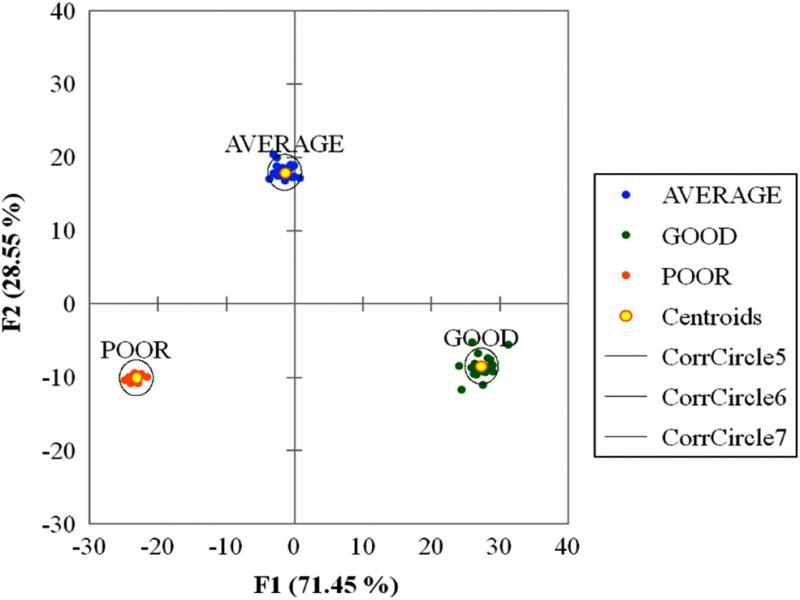
Figure 10:
Wilks’ Lambda test (Rao’s approximation)_
| Lambda | 0.000 |
| F (observed value) | 7.018 |
| F (critical value) | 2.551 |
| DF1 | 384 |
| DF2 | 10 |
| P value | 0.001 |
| alpha | 0.05 |
Sum of weights and prior probabilities for each class_
| Class | Sum of weights | Prior probabilities |
|---|---|---|
| Average | 68.000 | 0.342 |
| Good | 62.000 | 0.312 |
| Poor | 69.000 | 0.347 |
Pillai’s trace_
| Trace | 1.992 |
| F (observed value) | 7.610 |
| F (critical value) | 2.310 |
| DF1 | 384 |
| DF2 | 12 |
| P value | 0.000 |
| alpha | 0.05 |
Classification matrix_
| Classification matrix | Average | Good | Poor | Correct |
|---|---|---|---|---|
| Average | 5 | 0 | 0 | 100 |
| Good | 3 | 8 | 0 | 72.7272727 |
| Poor | 1 | 0 | 4 | 80 |
P values for Fisher distances_
| Class | Average | Good | Poor |
|---|---|---|---|
| Average | 1 | 0.021 | 0.028 |
| Good | 0.021 | 1 | 0.006 |
| Poor | 0.028 | 0.006 | 1 |
Hotelling–Lawley trace_
| Trace | 596.480 |
| F (observed value) | 7.256 |
| F (critical value) | 3.923 |
| DF1 | 384 |
| DF2 | 6 |
| P value | 0.011 |
| alpha | 0.05 |
Confusion matrix for the validation sample_
| From/to | AVERAGE | GOOD | POOR | Total | % correct |
|---|---|---|---|---|---|
| AVERAGE | 0 | 0 | 0 | 0 | 0.00 |
| GOOD | 0 | 0 | 0 | 0 | 0.00 |
| POOR | 0 | 0 | 1 | 1 | 100.00 |
| Total | 0 | 0 | 1 | 1 | 100.00 |
Summary classification_
| Correct | 81.0% |
| Base | 52.4% |
| Improvement | 60.0% |
Summary statistics_
| Variable | Categories | Frequencies | % |
|---|---|---|---|
| Predicted performance | Average | 68 | 34.171 |
| Good | 62 | 31.156 | |
| Poor | 69 | 34.673 |
Canonical correlations_
| F1 | F2 |
| 0.999 | 0.997 |
Generalized squared distances_
| Class | Average | Good | Poor |
|---|---|---|---|
| Average | 2.147594 | 1,529.279 | 1,259.779 |
| Good | 1,529.094 | 2.332341 | 2,556.248 |
| Poor | 1,259.809 | 2,556.462 | 2.118397 |
Roy’s greatest root_
| Root | 426.213 |
| F (observed value) | 13.319 |
| F (critical value) | 3.691 |
| DF1 | 192 |
| DF2 | 6 |
| P value | 0.002 |
| alpha | 0.05 |
Bartlett’s test for eigenvalue significance_
| F1 | F2 | |
|---|---|---|
| Eigenvalue | 426.213 | 170.267 |
| Bartlett’s statistic | 1125.651 | 516.894 |
| P value | 0.000 | 0.000 |
Confusion matrix for the cross-validation results_
| From\to | AVERAGE | GOOD | POOR | Total | % correct |
|---|---|---|---|---|---|
| AVERAGE | 23 | 26 | 19 | 68 | 33.82 |
| GOOD | 16 | 36 | 10 | 62 | 58.06 |
| POOR | 5 | 8 | 56 | 69 | 81.16 |
| Total | 44 | 70 | 85 | 199 | 57.79 |
Discriminant analysis for performance_
| Sample summary | Sample size | Internal 1 mean | Internal 2 mean | Attendance mean |
|---|---|---|---|---|
| Average | 5 | 54 | 51.2 | 89 |
| Good | 11 | 78 | 77 | 90.54545455 |
| Poor | 5 | 19.4 | 25.2 | 73.8 |
Matrix of variance and covariance_
| Matrix of vars and covars | PA 1 | PA 2 | Attendance |
|---|---|---|---|
| Average | |||
| PA 1 | 126.5 | 243.5 | 96.5 |
| PA 2 | 243.5 | 472.7 | 178 |
| Attendance | 96.5 | 178 | 100.5 |
| Good | |||
| PA 1 | 258 | 163.6 | 10.4 |
| PA 2 | 163.6 | 152.2 | 7 |
| Attendance | 10.4 | 7 | 22.27273 |
| Poor | |||
| PA 1 | 237.8 | 190.4 | 126.85 |
| PA 2 | 190.4 | 268.7 | 107.8 |
| Attendance | 126.85 | 107.8 | 92.2 |
| Pooled | |||
| PA 1 | 224.289 | 187.31 | 55.41111 |
| PA 2 | 187.311 | 249.31 | 67.4 |
| Attendance | 55.4111 | 67.4 | 55.19596 |
Fisher distances_
| Class | Average | Good | Poor |
|---|---|---|---|
| Average | 0 | 6.580 | 5.723 |
| Good | 6.580 | 0 | 11.082 |
| Poor | 5.723 | 11.082 | 0 |
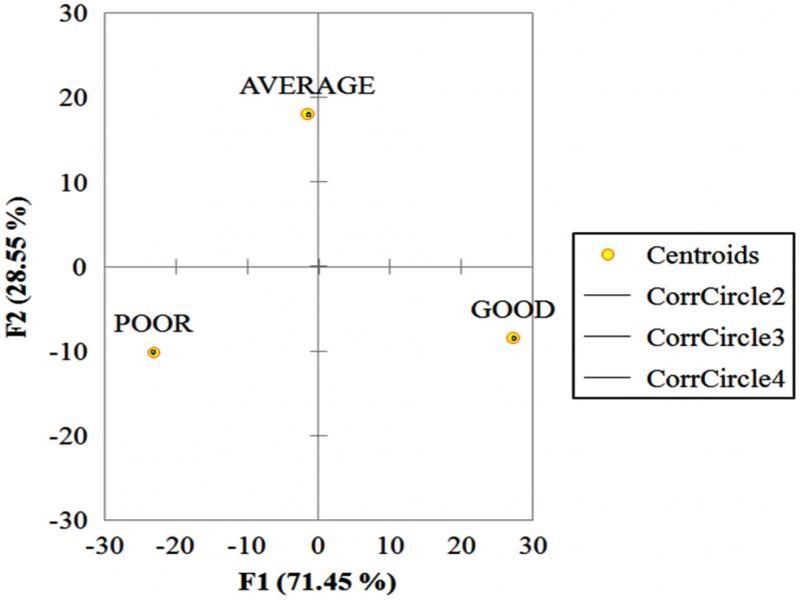
Functions at the centroids_
| F1 | F2 | |
|---|---|---|
| AVERAGE | −1.441 | 17.951 |
| GOOD | 27.354 | −8.465 |
| POOR | −23.159 | −10.085 |
Mahalanobis distances_
| Class | Average | Good | Poor |
|---|---|---|---|
| Average | 0 | 1,526.947 | 1,257.661 |
| Good | 1,526.947 | 0 | 2,554.130 |
| Poor | 1,257.661 | 2,554.130 | 0 |
Summary statistics (validation)_
| Variable | Categories | Frequencies | % |
|---|---|---|---|
| Predicted performance | Average | 0 | 0.000 |
| Good | 0 | 0.000 | |
| Poor | 1 | 100.000 |
Eigenvalue_
| F1 | F2 | |
|---|---|---|
| Eigenvalue | 426.213 | 170.267 |
| Discrimination (%) | 71.455 | 28.545 |
| Cumulative % | 71.455 | 100.000 |
Confusion matrix for the training sample_
| From/to | AVERAGE | GOOD | POOR | Total | % correct |
|---|---|---|---|---|---|
| AVERAGE | 68 | 0 | 0 | 68 | 100.00 |
| GOOD | 0 | 62 | 0 | 62 | 100.00 |
| POOR | 0 | 0 | 69 | 69 | 100.00 |
| Total | 68 | 62 | 69 | 199 | 100.00 |