

Granulation plays a key role in human cognition. For humans, it serves as a way of achieving data compression. This is one of the pivotal advantages accruing through the use of words in human, machine, and man-machine communication [1]. Zadeh emphasized two keynotes [2]: the concept of granulation is unique to fuzzy logic [3] and closely related to the concept of a rough set [4]. Granulation involves partitioning a set into granules and a granule may be interpreted as a restriction on the values that a variable can takes. In this sense, words in a natural language are, in large measure, labels of granules.
Since a linguistic variable is a variable whose values are words or, equivalently, granules, the concept of granulation is rooted in the concept of linguistic variables [5].
In general sense, by "information granule”, one regards a collection of elements drawn together by their closeness (resemblance, proximity or functionality) articulated in terms of some useful spatial, temporal or functional relationships. When we decompose an uncertain decision-making problem into granules, temporal relationships are very important to focus on the most suitable level of detail.
As decision environments and contents become increasingly complex, the use of single-granule information alone fails to accurately describe dynamic, ambiguous and fragmentary cognitive information. Dynamic multi-attribute decisionmaking frameworks offer to decision-makers a way of dealing with uncertainty, since this kind of solution enables for an iterative and interactive process in which the decision information is usually collected from different period [6–9]. That is, the dynamic decision-making problem consists of selecting the best alternatives from a set of available ones but considering time granulation [10]. Dynamic multiattribute decision-making approaches are implicitly granule-based because they generally model a dynamic problem as a collection of static decisionmaking problems that are solved first and then their results are aggregated using a dynamic weighted aggregation operator and its weighting vector.
The concept of the linguistic dynamic multiattribute decision-making (LDMADM) problem reveals situations in which decision data gathered in multiple periods, which is represented by linguistic terms by means of linguistic variables.
With a granule being a collection of elements which are drawn together by equivalence, proximity, similarity or functionality, in the LDMADM process, uncertainty is managed in these two granule-based dimensions: (a) linguistic variables and (b) time periods. Let’s get into the twofold complexity in brief.
To deal with (a) linguistic variables in LDMADM, the 2-tuple linguistic representation model [11] provides a powerful approach because it can express any counting of information in the discourse universe; meanwhile, it improves the interpretability and effectiveness of the decision-making results by avoiding losing information in computations. Studies of 2-tuple linguistic representation model not only have a strong theoretical research value, but also have wide application prospects in practice, specifically in decisionmaking and decision analysis.
To deal with (b) time periods in LDMADM, the resolution process has been structuredin [12]. The selection of a suitable time-dependent linguistic aggregation operator, and its weighting vector if necessary, is a key element due to the properties that can highly modify the computing cost as well as results themselves and their accuracy and interpretability. The aggregation is a multi-step process: first, a collective assessment is calculated for each alternative for each period, i.e., each static problem is solved; second, a dynamic collective assessment for each alternative is calculated using values obtained previously, i.e., the general dynamic problem is solved and an overall result is obtained.
This dynamic aggregation is generally carried out using time-dependent aggregation operators considering the diverse influence of time periods in results by means of weighting vectors. Based on the above reviews, we face the need of proper 2-tuple linguistic aggregation operators for such a time-dependent aggregation process.
What kind of 2-tuple linguistic time-dependent aggregation operators are available in the literature? As far as we knows, the 2-tuple linguistic Dynamic Weighted Averaging (2TDWA) [14], the 2-tuple linguistic Dynamic Averaging (2TDA) [14], the 2-tuple linguistic Dynamic Weighted Geometric (2TDWG) [15] and the 2-tuple linguistic Dynamic Geometric (2TDG) [15] aggregation operators only weight the 2-tuple linguistic arguments themselves. That is, they weight each time period in relation to their reliability but they can not synthetically consider the importance of time periods and the importance of non-dynamic evaluations.
What kind of hybrid weighted aggregation operators are available in the literature? Numeric aggregation operators have been studied for a long time. Among the large number of aggregation operators and functions, the arithmetic mean (AM) and the weighted mean (WM) are the most popular ones. A related operator, the ordered weighted averaging (OWA) operator, was proposed by Yager in [16]. This operator is similar to the WM as both are a linear combination of the input data. The difference between the WM and the OWA operator is that the latter orders the data before applying the linear combination [17]. This ordering step causes the semantics (or meaning) of the weights to be radically different in the weighted mean and the OWA. In fact, the weights in the weighted mean measure the reliability of the sources and the weights in the OWA measure the importance of the values (with respect to their ordering). The need of combining both functions has been developed by different authors [18,19] and three main classes of functions have been proposed for generalizing them: the weighted OWA (WOWA) operator [18], the hybrid weighted averaging(HWA) operator [19], and the ordered weighted averaging-weighted average (OWAWA) operator [20]. The main advantage of the last approach is that it unifies the OWA and the WA, taking into account the degree of importance that each concept has in the formulation.
Motivated by this gap, in this paper, we propose a new 2-tuple linguistic dynamic hybrid weighted aggregation operator which is useful to model different attitudes in decision-making by simultaneously weighting the given arguments as well as their ordered positions.
The remainder of this paper is structured as follows. Section 2 reviews basic concepts of the 2-tuple linguistic representation model. Section 3 introduces a new 2-tuple linguistic OWAWA aggregation operator which is integrated in the 2-tuple LDMADM approach described in Section 4. Section 5 gives an illustrative example, and Section 6 summarizes the key findings of this research.
This section revises concepts and methods to be referred to in this paper, including the 2-tuple linguistic representation model and its computational model.
In [11], Herrera and Martinez progressed the fuzzy linguistic decision-making field by representing the linguistic information with the name 2-tuple, constructed by a linguistic term and a numerical value, supporting the information of the symbolic translation.
The 2-tuple linguistic model [11] aimed to improve the accuracy and facilitate the processes of computing with words by treating the linguistic domain as continuous but keeping the linguistic basis (syntax and semantics). The 2-tuple fuzzy linguistic representation model consists of modelling the linguistic information by means of a pair of elements [21]:
- –
Let S = {s0, …, sg} be a linguistic term defined by the fuzzy linguistic approach whose semantics (provided by a fuzzy membership function) and syntax are also defined according to the fuzzy linguistic approach.
- –
α is a numerical value, Symbolic Translation, that indicates the translation of the fuzzy membership function which represents the closest term, si ∈ {s0, …, sg} if si does not match exactly the computed linguistic information. The value of a is then defined as
1 \alpha \in = \left\{ {\matrix{ {[ - 0.5,0.5)} \hfill & {if} \hfill & {{s_i} \in \left\{ {{s_1},{s_2}, \ldots ,{s_{g - 1}}} \right\}} \hfill \cr {[0,0.5)} \hfill & {if} \hfill & {{s_i} = {s_0}} \hfill \cr {[ - 0.5,0)} \hfill & {if} \hfill & {{s_i} = {s_g}} \hfill \cr } } \right.
The linguistic information is then expressed by a pair of elements noted as (si, α). A symbolic computation on linguistic terms in S obtains a value β ∈ [0, g] that will be transformed into a equivalent 2tuple linguistic value, (si, α), by means of the Δ function defined as follows:
[21] Let S = {s0, …, sg} the set oflinguistic terms, the associated 2-tuple is
The Δ and Δ−1 transformation functions support conversions between numerical values and 2-tuple linguistic values without information loss. The 2-tuple linguistic model only guarantees accuracy when dealing with a uniformly and symmetrically distributed linguistic term set.
The recent two decades have witnessed the booming interest and growing development in research of 2-tuple linguistic time-independent aggregation operators. Functions Δ and Δ−1 greatly help the extension of conventional numerical operators to the 2-tuple linguistic domain. In what follows, two seminal 2-tuple linguistic time independent aggregation operators are revised.
[11] Let
Especially, if
The significant characteristic of the 2-tuple linguistic variable is that it involves the dimension of time, and this concept is pivotal in understanding 2tuple LDMADM problems.
[10] Let t be the variable of time, then ns
Operation laws and properties on the conventional 2-tuple linguistic value also hold for the discrete time 2-tuple linguistic variable because if omitting the parameter of the time (tλ), the later can be mathematically taken as the former.
The concept of discrete time 2-tuple linguistic variable addresses the representation of changes of experts’ assessments on given alternatives over an attribute but considers different time periods in the LDMADM process.
The 2-tuple linguistic aggregation operators are logically required to develop the dynamic aggregation phase in the LDMADM resolution process. Let’s analyze some of the existing aggregation operators.
[14] Let
Especially, if
[22] Let
On the one hand, in the 2TDWA the i-th 2-tuple linguistic value is weighted according to the weight w(tλ). On the other hand, in 2TDOWA each w(tλ) is attached to the i-th value in decreasing order without considering from which information source the value comes. Notice that the OWA operator is commutative. That is, all information sources (or experts) have an equal contribution to the final solution.
The behavior of weighted averaging operators allows us to weight each information source in relation to their reliability while ordered weighted operators allow to weight the values according to their ordering.
The 2TDWA [14,15] operator only weights the 2tuple arguments themselves, but ignores the importance of the ordered position of the arguments, while the 2TDOWA [22] operator only weights the ordered position of each given arguments, but ignores the importance of the arguments. To solve this drawback, a new 2-tuple aggregation operators will be defined for time dependent 2-tuple linguistic arguments, which weight all the given arguments and their ordered positions based on OWAWA operator [20].
In the rest of the paper, we will recall or introduce definitions of weighted aggregation operators. It is worth noting that these functions are defined by means of vectors with non-negative components whose sum is 1.
A vector w ∈ ℝn is a weighting vector if w ∈ [0,1]n and
In the following, W is a weighting vector defined on the ordered set, while V is a weighting vector defined on the discrete time 2-tuple linguistic set, which is defined on the time period set.
Let
This formulation of the 2TDOWAWAV,W operator separates the part that strictly affects the OWA operator and the part that affects the WA operator. In this way, we can see both models in the same formulation.
By modulating the ℓ coefficient in the 2TDOWAWAv,w operator, we may construct diverse aggregation operators. If ℓ = 0, then we get the 2TDWA while if ℓ = 1, we get the 2TDOWA operator. It is also possible to obtain a wide range of particular 2TDOWAWAv, w cases by giving different values and interpretations to the ℓ value. For instance, we may introduce the 2TDOWA with a low degree of importance, such as ℓ ∈ [0,0.2], and analyse the effect in the outputs; or we may also introduce the 2TDOWA in such a way that it is more important than the WA, by considering higher degrees of importance such as ℓ E [0.8,1]. The greater the ℓ value, the more important the 2TDOWA operator, and vice versa. Along the same line, we can introduce the WA to a problem formulated with the OWA.
Each family is just a particular case useful in some special situations according to the interests of the analysis.
In this section, a LDMADM Approach with the 2TDOWAWAV,W is given to introduce how this operator can be used to support a decision.
Let T = {tλ|λ ∈ (1,…, q)} denotes the discrete set of evaluation time periods and V = {vλ|λ ∈ (1,…,q)} represents the time weighting set that satisfies vλ ∈ [0,1] with
Alternatives are evaluated according to a criteria set C = {cj|j ∈ (1,…,n)} whose weights are given by the weighting vector
Note that we also suppose that weights
Then, the dynamic evaluation of alternatives is defined as a discrete time 2-tuple linguistic variable whose values can be considered as the non-dynamic evaluations generated during the period T, since we consider the temporal problem as a succession of q individual LDMADM problems.
The 2-tuple LDMADM approach based on the 2TDOWAWAV,W Aggregation Operator is aimed to solve decision-making problems in which linguistic preferences are gathered in multiple periods and a final decision is made considering all the linguistic information provided. Then, all non-dynamic evaluations are considered to have been conducted in the past. In other words, the aim of the 2-tuple LDMADM approach is to give a global order of alternatives set A based on dynamic linguistic evaluations, with respect to the criteria set C and after being evaluated during the period T.
The 2TDOWAWAV,W operator is applied to LDMADM problems based on 2-tuple linguistic information.
A stepwise description of the 2-tuple LDMADM approach is provided in the following.
- Step 1:
Generate 2-tuple linguistic values for each period. An original linguistic term can be directly written as (si, 0) 2-tuple linguistic since si represents the linguistic label center of the information (si, α) and α = 0 represents no difference from the original value β to the transformed value i. Then from gathered xijk(tλ) = sijk(tλ) ∈ S, we will obtain 2-tuple linguistic values
{{\tilde x}_{ijk}}\left( {{t_\lambda }} \right) = {(s,0)_{ijk}}\left( {{t_\lambda }} \right) \in \tilde S - Step 2:
Calculate the collective value for each criterion for each period, using a classical time independent 2-tuple linguistic aggregation operator ϒU and the weighting vector U.
9 \hat X\left( {{t_\lambda }} \right) = {\left( {{{\hat x}_{ij}}\left( {{t_\lambda }} \right)} \right)_{m \times n}} = {\Upsilon _U}\left( {{{\tilde x}_{ijk}}\left( {{t_\lambda }} \right)} \right) - Step 3:
Calculate the non-dynamic evaluation for each alternative for each period, using a classical time independent 2-tuple linguistic aggregation operator ψH and the weighting vector H. Results from this step can be seen as solutions for each individual or static LDMADM problem.
10 \bar X\left( {{t_\lambda }} \right) = {\left( {{{\tilde x}_i}\left( {{t_\lambda }} \right)} \right)_m} = {\Psi _H}\left( {{{\hat x}_{ij}}\left( {{t_\lambda }} \right)} \right) - Step 4:
Calculate the dynamic evaluation for each alternative, if no other period will be considered in the LDMADM problem, using the 2TDOWAWAV,W.
11 \mathord{\buildrel{\lower3pt\hbox{\scriptscriptstyle\smile}}\over X} \left( {{t_\lambda }} \right) = {\left( {{{\mathord{\buildrel{\lower3pt\hbox{\scriptscriptstyle\smile}}\over x} }_i}\left( {{t_\lambda }} \right)} \right)_m} = 2TDOWAW{A_{V,W}}\left( {{{\bar x}_i}\left( {{t_\lambda }} \right)} \right) - Step 5:
Order dynamic evaluation
{{\mathord{\buildrel{\lower3pt\hbox{\scriptscriptstyle\smile}}\over x} }_i}\left( {{t_\lambda }} \right) {{\mathord{\buildrel{\lower3pt\hbox{\scriptscriptstyle\smile}}\over x} }_i}\left( {{t_\lambda }} \right)
The flowchart of the proposed approach is presented in Figure 1.
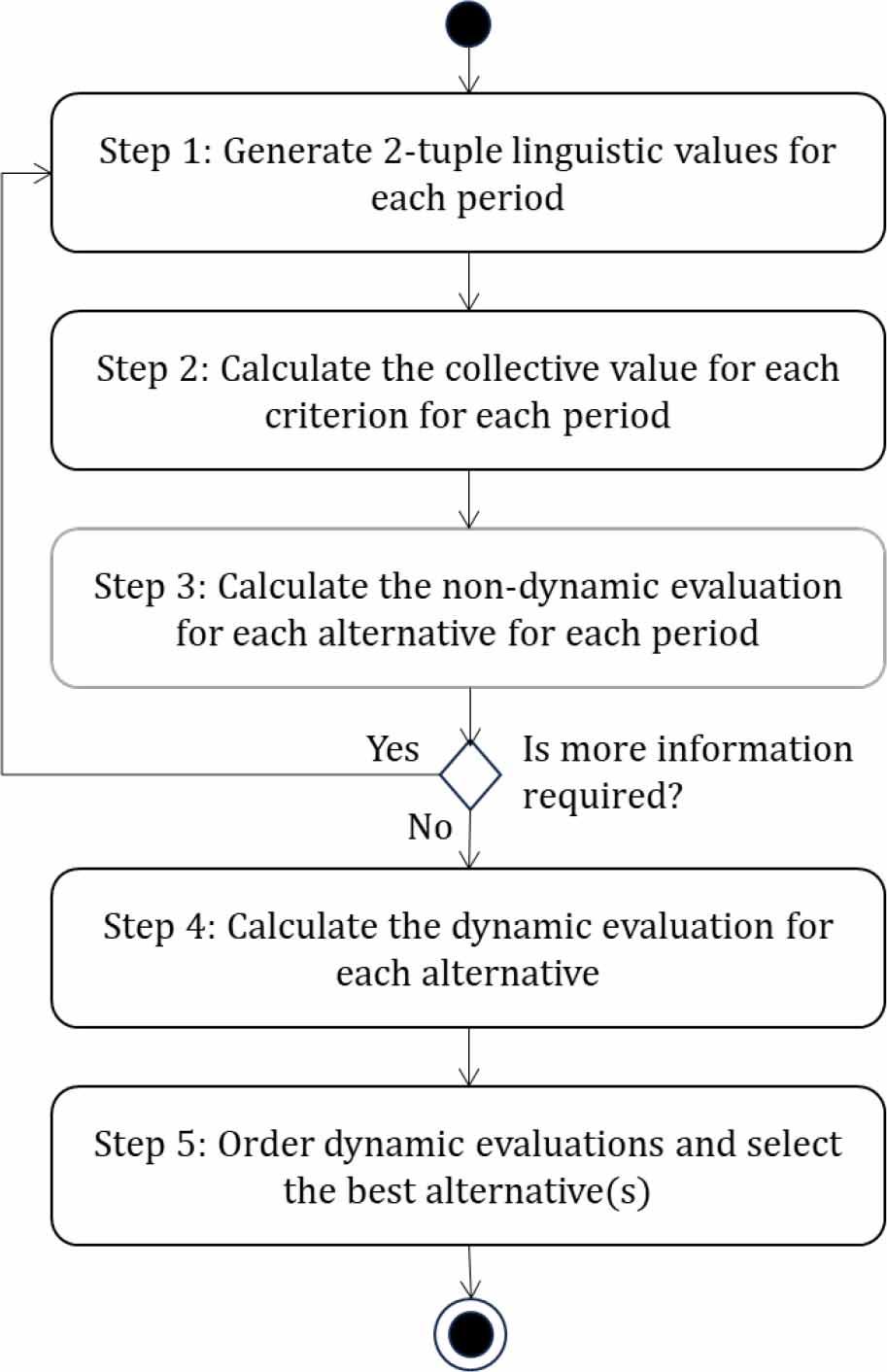
The flowchart of the proposed approach
In this section, we explore the applicability of the 2TDOWAWAV,W operator extending an illustrative example presented in [14] to a 2-tuple linguistic context. A risk investment company wants to invest a sum of money in the best option. This problem involves the evaluation of four possible enterprises denoted as A = {a1, a2, a3, a4}. The attributes, C = {c1, c2, c3, c4} are: c1, the ability of sale, c2, the ability of production, c3, the ability of technology and c4, the ability of financing. Three experts, E = {e1, e2, e3}, provide assessment information on C in order to prioritize these enterprises A with respect to their performance. Weights of experts and criteria are assumed to be equal and constant over T = {t1, t2, t3}.
In the following, we utilize the developed approach to select the best enterprise.
- Step 1:
Generate 2-tuple linguistic values for each period. Experts use the linguistic term set:
\matrix{ S \hfill & { = \left\{ {{s_0}:{\rm{ Extremely Poor }}(EP),{s_1}:{\mathop{\rm VeryPoor}\nolimits} (VP),} \right.} \hfill \cr {} \hfill & {{s_2}:{\mathop{\rm Poor}\nolimits} (P),{s_3}:{\rm{ Medium }}(M),{s_4}:{\mathop{\rm Good}\nolimits} (G),} \hfill \cr {} \hfill & {\left. {{s_5}:{\mathop{\rm VeryGood}\nolimits} (VG),{s_6}:{\rm{ Extremely Good }}(EG)} \right\},} \hfill \cr } The original linguistic information is listed in Tables 1–3. The 2-tuple linguistic values for each period are listed in Table 4, where t1 denotes 2006, t2 denotes 2007 and t3 denotes 2008.
- Step 2:
To compute the collective value
\hat X\left( {{t_\lambda }} \right) - Step 3:
For computing the non-dynamic 2-tuple linguistic evaluation
\bar X\left( {{t_\lambda }} \right) - Step 4:
Dynamic evaluations for each alternative are computed using different settings for the 2TDOWAWAV,W as illustrated in Table 5. The weighting vectors are assumed to be W = (0.5,0.3,0.2) and V = (0.1,0.3,0.6). With V we can emphasize the higher importance of later evaluations.
- Step 5:
Orders of alternatives are listed in Table 6 per different ℓ values in the 2TDOWAWAV,W operator.
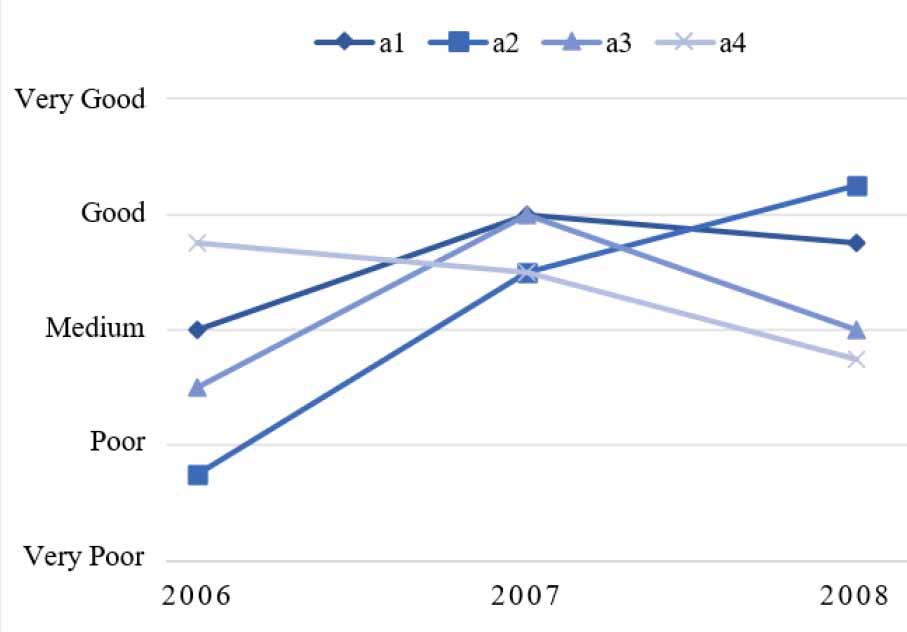
Non-dynamic 2-tuple linguistic evaluation of alternatives
xijk linguistic values for period t1
| ek | ai | c1 | c2 | c3 | c4 |
|---|---|---|---|---|---|
| e1 | a1 | VP | P | G | M |
| a2 | M | EP | M | VP | |
| a3 | EP | VP | VG | G | |
| a4 | M | VG | VG | M | |
| e2 | a1 | G | P | M | G |
| a2 | P | VP | P | VP | |
| a3 | EP | EP | EG | P | |
| a4 | VG | G | M | G | |
| e3 | a1 | VP | VG | VG | P |
| a2 | G | VP | VP | P | |
| a3 | VP | M | G | G | |
| a4 | G | G | M | P |
xijk linguistic values for period t2
| ek | ai | c1 | c2 | c3 | c4 |
|---|---|---|---|---|---|
| e1 | a1 | M | G | VG | M |
| a2 | P | VG | G | G | |
| a3 | M | G | VG | G | |
| a4 | G | VG | G | M | |
| e2 | a1 | G | G | M | G |
| a2 | G | M | M | G | |
| a3 | G | VG | EG | P | |
| a4 | P | G | P | VG | |
| e3 | a1 | M | M | EG | EG |
| a2 | G | M | VP | VG | |
| a3 | P | G | VG | G | |
| a4 | M | G | M | M |
xijk linguistic values for period t3
| ek | ai | c1 | c2 | c3 | c4 |
|---|---|---|---|---|---|
| e1 | a1 | VP | V | G | M |
| a2 | G | G | M | G | |
| a3 | VP | P | V | G | |
| a4 | M | G | P | VP | |
| e2 | a1 | P | P | E | G |
| a2 | VG | V | G | VG | |
| a3 | M | V | E | P | |
| a4 | P | M | M | G | |
| e3 | a1 | VP | V | E | EG |
| a2 | G | V | M | VG | |
| a3 | VP | M | G | G | |
| a4 | G | P | P | M |
| ai | t1 | t2 | t3 |
|---|---|---|---|
| a1 | (s3,0) | (s4,0) | (s4,–0.25) |
| a2 | (s2,–0.25) | (s4,–0.50) | (s4, 0.25) |
| a3 | (s3,–0.50) | (s4,0) | (s3,0) |
| a4 | (s4,–0.25) | (s4,–0.50) | (s3,–0.25) |
| ℓ | a1 | a2 | a3 | a4 |
|---|---|---|---|---|
| 0 | (s4, –.25) | (s4, –.22) | (s3, .25) | (s3,.08) |
| 0.1 | (s4, –.25) | (s4, –.25) | (s3, .27) | (s3, .12) |
| 0.2 | (s4, –.25) | (s4, –.27) | (s3, .28) | (s3, .16) |
| 0.5 | (s4,–.26) | (s4, –.35) | (s3,.33) | (s3.28) |
| 0.8 | (s4,–.27) | (s4,–.42) | (s3,.37) | (s3, .40) |
| 0.9 | (s4,–.27) | (s4, –.45) | (s3, .39) | (s3, .44) |
| 1.0 | (s4,–.27) | (s4, –.47) | (s3,.40) | (s3, .48) |
| 2TDWA | (s4,–.25) | (s4,–.22) | (s3, .25) | (s3, .08) |
| 2TDOWA | (s4,-^7) | (s4, –.47) | (s3,.40) | (s3, .48) |
| 2TDWG [23] | (s4,–.26) | (s4, –.33) | (s3, .21) | (s3,.05) |
| 2TDWHA [23] | (s4,–.27) | (s4, –.48) | (s3,.17) | (s3,.03) |
Dynamic aggregation operators, order and solution obtained
| ℓ | Order |
|---|---|
| 0 | a2 ≺ a1 ≺ a3 ≺ a4 |
| 0.1 | a1 = a2 ≺ a3 ≺ a4 |
| 0.2 | a1 ≺ a2 ≺ a3 ≺ a4 |
| 0.5 | a1 ≺ a2 ≺ a3 ≺ a4 |
| 0.8 | a1 ≺ a2 ≺ a4 ≺ a3 |
| 0.9 | a1 ≺ a2 ≺ a4 ≺ a3 |
| 1.0 | a1 ≺ a2 ≺ a4 ≺ a3 |
| 2TDWA | a2 ≺ a1 ≺ a3 ≺ a4 |
| 2TDOWA | a1 ≺ a2 ≺ a4 ≺ a3 |
| 2TDWG [23] | a1 ≺ a2 ≺ a3 ≺ a4 |
| 2TDWHA [23] | a1 ≺ a2 ≺ a3 ≺ a4 |
The order of alternatives varies depending on the 2TDOWAWAV,W class obtained by modulating the aggregation attitude with the 𝓁 value. The main advantage of the 2TDOWAWAV,W operator is that it can provide different results regarding uncertainty according to the particular interests of the decision maker in the specific problem considered.
That is, if the experts consider the order of the evaluations without taking into account the periods, they can assign ℓ=0 and 2TDOWAWAV,W will behave as the 2TDWA aggregation operator, with a2 being the best company. Otherwise, if they take into account only the importance of periods, they can assign ℓ=1 and 2TDOWAWAV,W will behave as the 2TDOWA aggregation operator; in this case a1 would be the best company Now, if the experts need to weight both the order of the values and the importance of the periods, the coefficient ℓ allows modeling that attitude, in such a way that it is possible to assign it values in the [0,1] interval whose midpoint (ℓ=0.5) would mean that both elements have the same weight in the decision; in that case company a1 is better than company a2. However, in this example it is clear that a1 or a2 is the optimal choice. In addition, we compare these results with those obtained using the 2-tuple dynamic weighted geometric (2TDWG [23]) andthe2-tuple dynamic weighted harmonic average (2TDWHA [23]) aggregation operators. As shown in Tables 5 and 6, the results are similar, with the particularity that operators 2TDWG and 2TDWHA produce a single fixed result, while 2TDOWAWAV,W offers a range of options that allows modeling different attitudes in the problem solving process.
Figure 3 visualizes the behavior of the 2TDOWAWAV,W operator for a set of ℓ values.
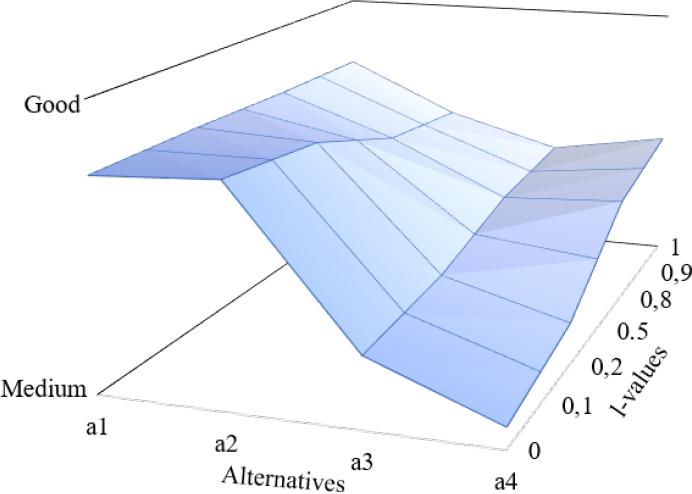
Dynamic 2-tuple linguistic evaluation of alternatives using different ℓ values
The proposed approach offers several advantages: The introduction of the ℓ parameter in the 2TDOWAWAV,W provides decision-makers with a high degree of flexibility. They can adjust these parameters according to the specific requirements of the LDMADM problem.
This feature makes the 2-tuple LDMADM approach based on the 2TDOWAWAV,W applicable to a wide range of real-world scenarios.
The selection of a suitable time-dependent 2-tuple linguistic aggregation operator is relevant due to its properties, which can highly modify the computing cost as well as results themselves and their accuracy and interpretability. The existing 2-tuple linguistic aggregation operators, such as 2TDAϕ, 2TDWAθ and 2TDOWAϑ operators, can not simultaneously consider the information about the importance of the linguistic non-dynamic evaluation being aggregated and the importance of periods, and thus cannot equilibrate the influence of both kind of arguments on the final dynamic evaluation and the decision result. To solve this drawback, this paper introduced a new 2tuple linguistic dynamic hybrid weighted aggregation operator, which is very useful to model different attitudes in decision-making by simultaneously weighting the given arguments as well as their ordered positions. The novel 2TDOWAWAV,W weights not only the importance of a particular time period, but also the importance of non-dynamic evaluations in such a time period. Its main advantage is that it can unify the weighting behaviour of OWA and WA families by including the degree of importance of each concept in the aggregation. 2TDOWAWAV,W is able to flexibly model situations where either the 2TDOWA or the 2TDWA fits the analysis. The parametric nature of the proposed 2TDOWAWAV,W allows decision-makers to fine-tune the influence of time periods as well as non-dynamic evaluations at those periods. This level of control empowers decision-makers to precisely tailor the aggregation process to their preferences regarding the characteristics of the problem. Thus, the 2TDOWAWAv.w is a more general approach to LDMADM.
In future work, we expect to develop further research on several families of 2TDOWAWAV,W operators regarding the reordering process and the use of hybrid aggregation operators.