
Table 1
Queries used for each time block.
| Time blocks | Search Key | ||
|---|---|---|---|
| Years | Duration | Token 1 | |
| 0–1950 | ‑ | A AND B | |
| 1951–1970 | 20 | A AND B | |
| 1971–1990 | 20 | A AND B | |
| A AND C | |||
| 1991–2000 | 10 | A AND C | |
| 2001–2010 | 10 | A AND C AND D ‑optical | |
| 2011–2015 | 5 | A AND C AND D ‑optical | |
| 2016–2018 | 3 | A AND C AND D ‑optical | |
| 2019–2020 | 2 | A AND C AND D ‑optical | |
| 2021–2023 | 2 | A AND C AND D ‑optical | |
| 2024– | 1 | A AND C AND D ‑optical | |
| Legend | |||
| A | music AND composer AND style | ||
| B | computer OR information OR statistics OR algorithm | ||
| C | classification OR identification OR recognition OR attribution | ||
| D | ‘symbolic level’ OR ‘music score’ OR midi OR musicxml OR kern | ||

Figure 1
Preferred Reporting Items for Systematic Reviews and Meta‑Analyses flowchart (Haddaway et al., 2022) of the literature review conducted in this work.
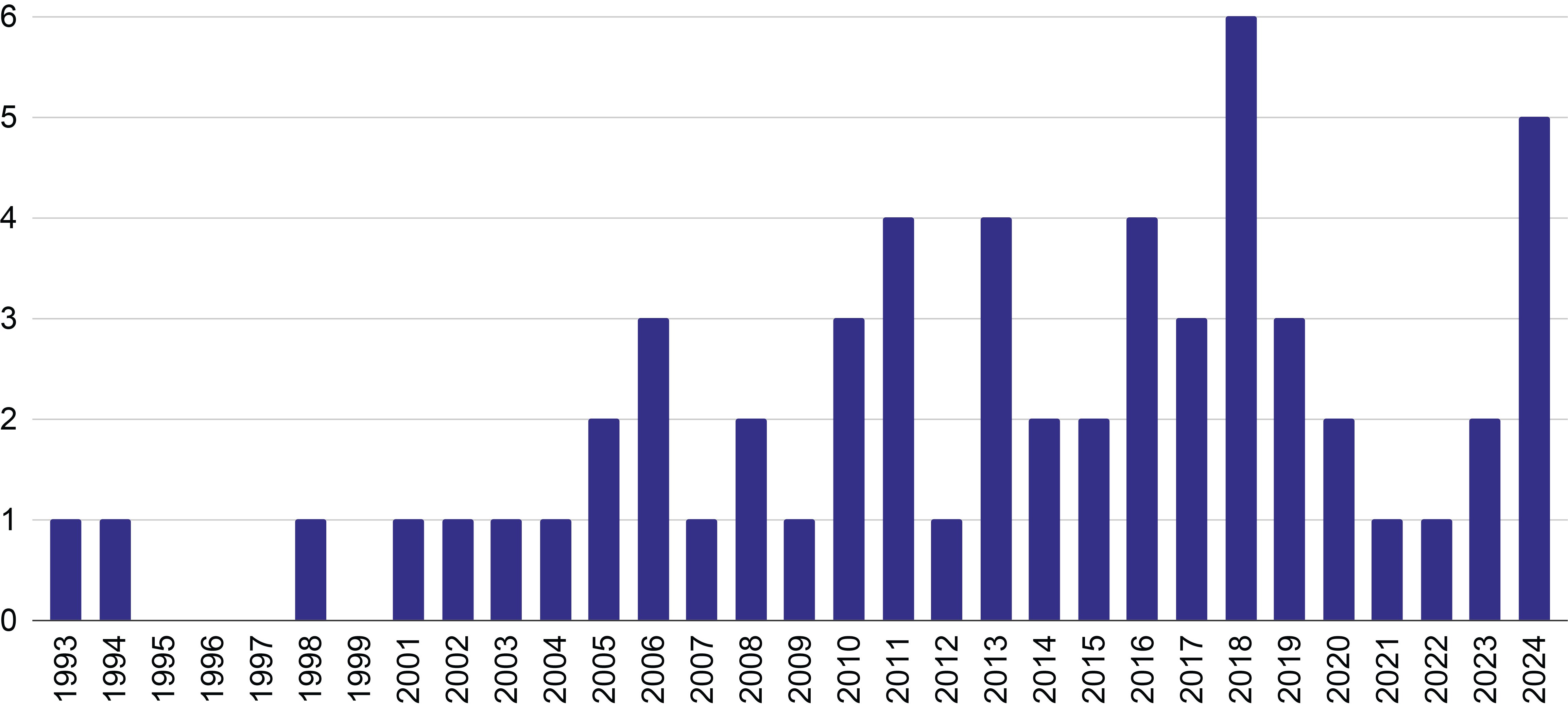
Figure 2
Distribution of the number of publications across the years.
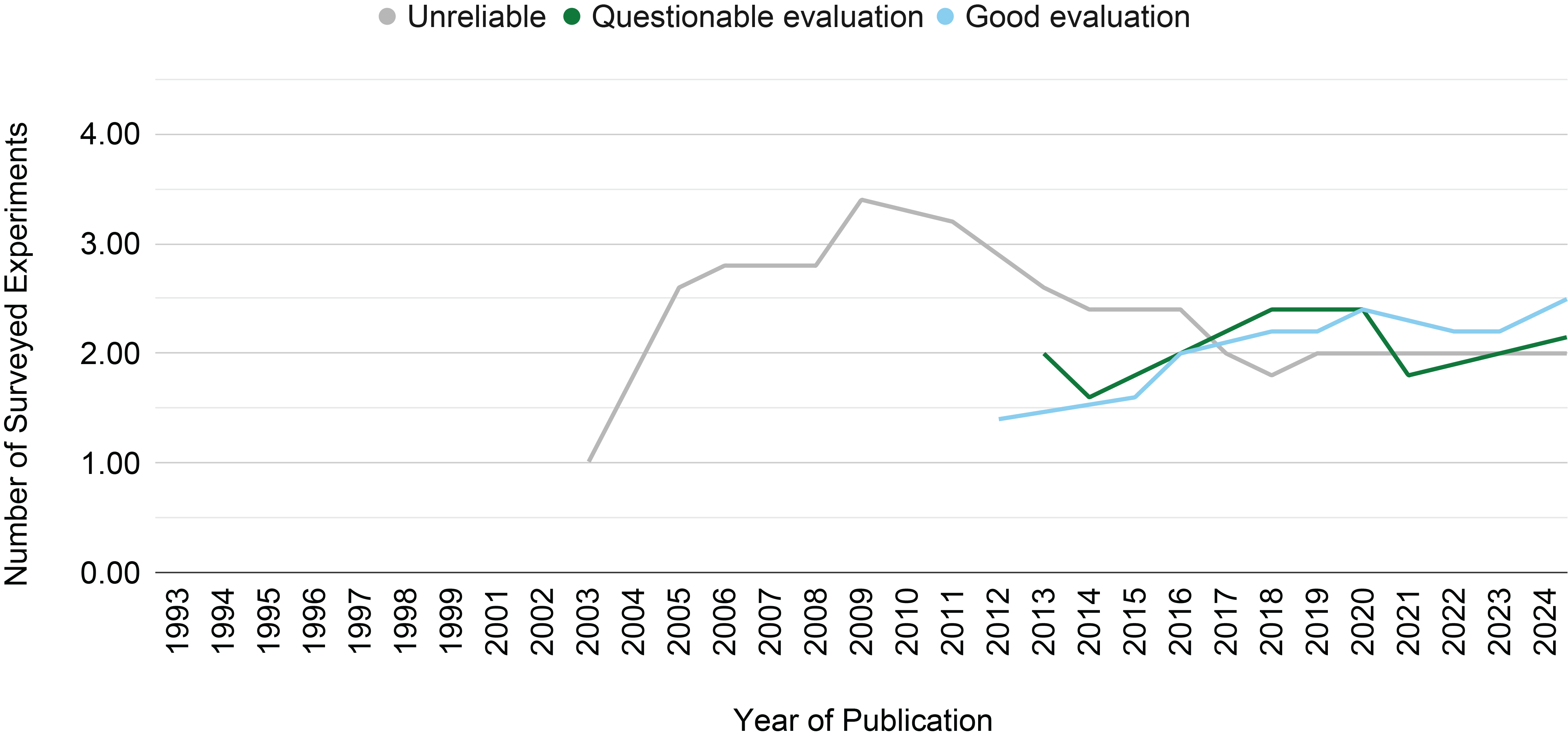
Figure 3
The moving average on a window of five years of the number of surveyed experiments per year of publication across the evaluation categories identified in this survey.
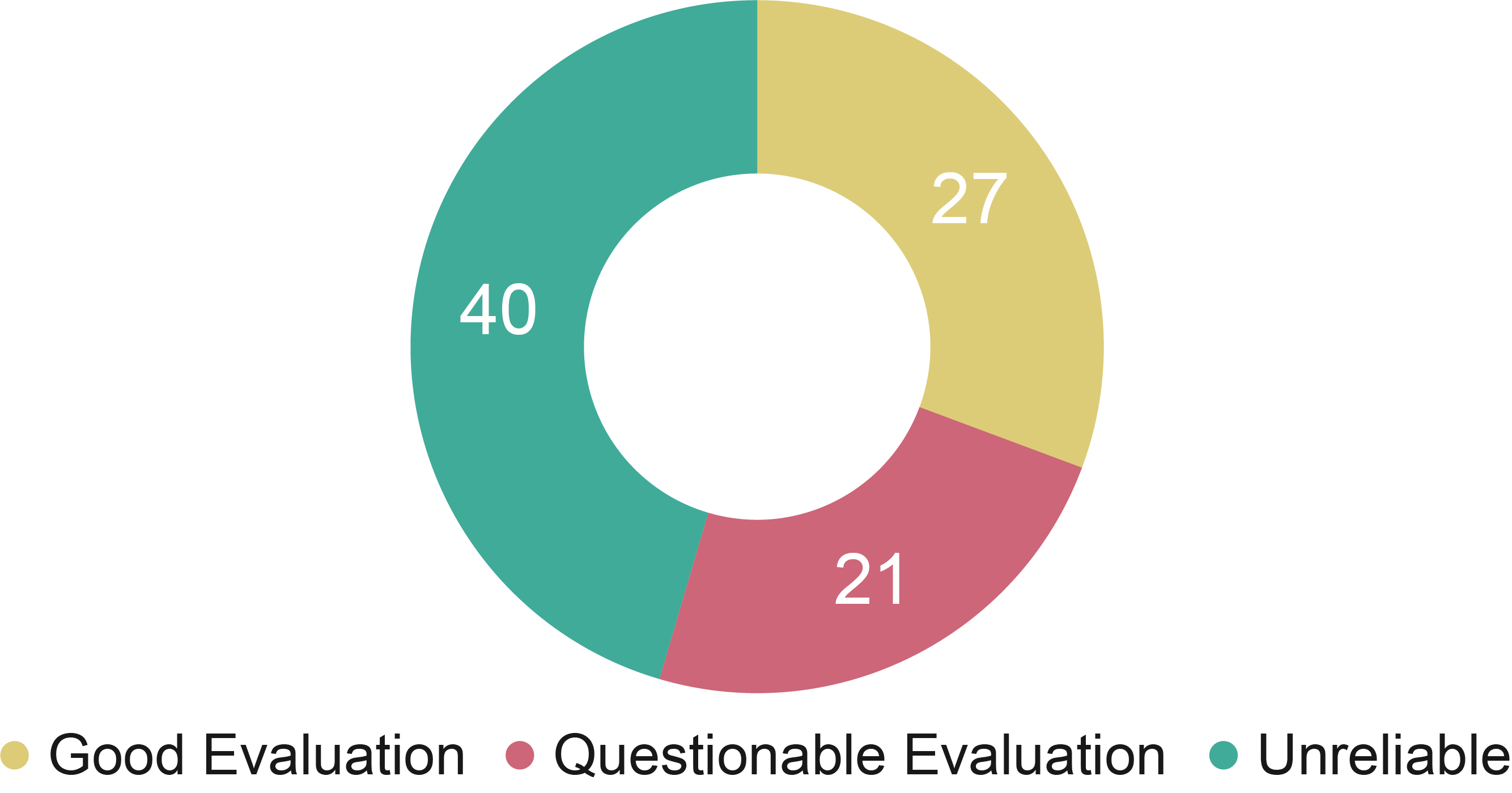
Figure 4
Distribution of the recorded experiments across the evaluation classes identified.
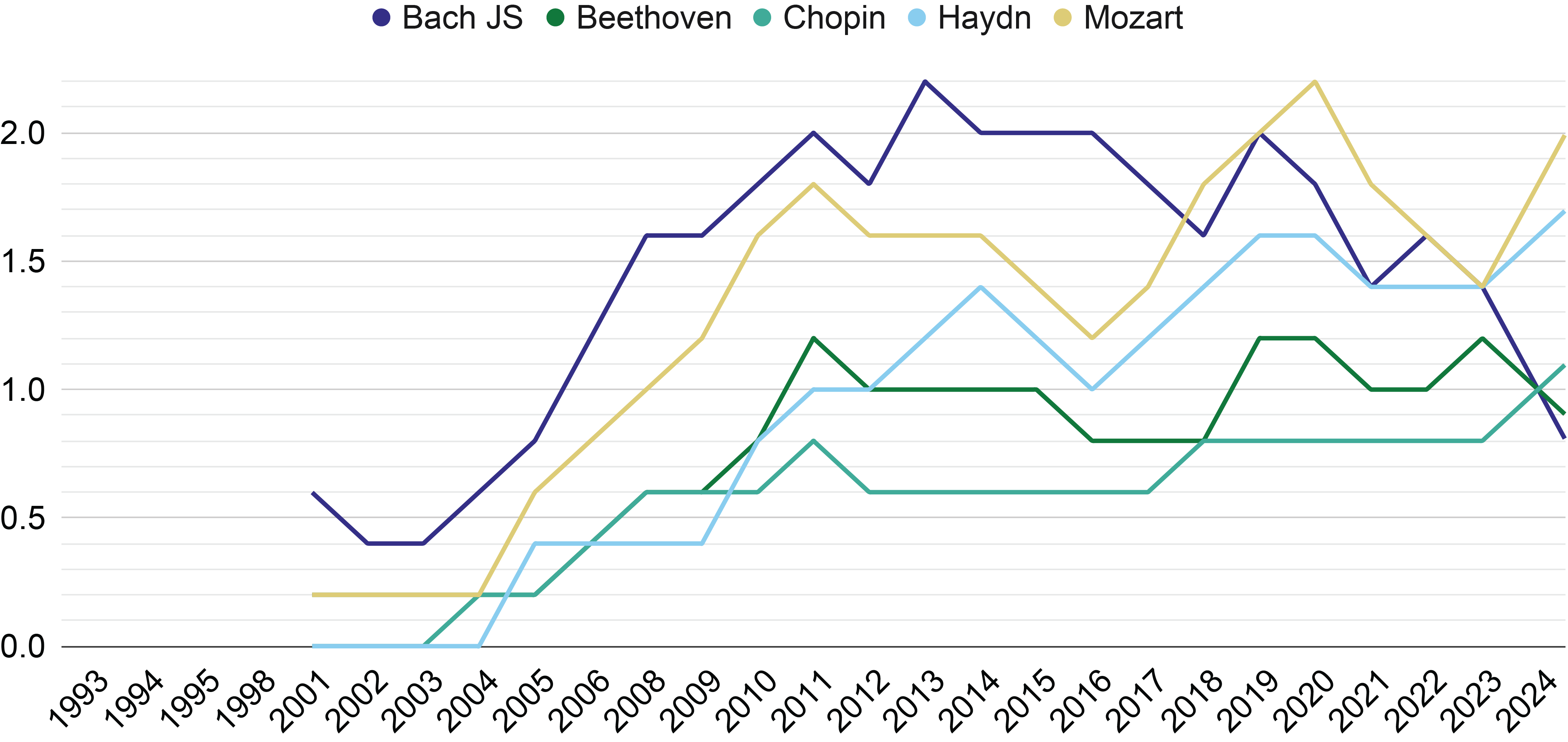
Figure 5
The moving average on a window of five years of the number of papers per composer, for the five most common composers.
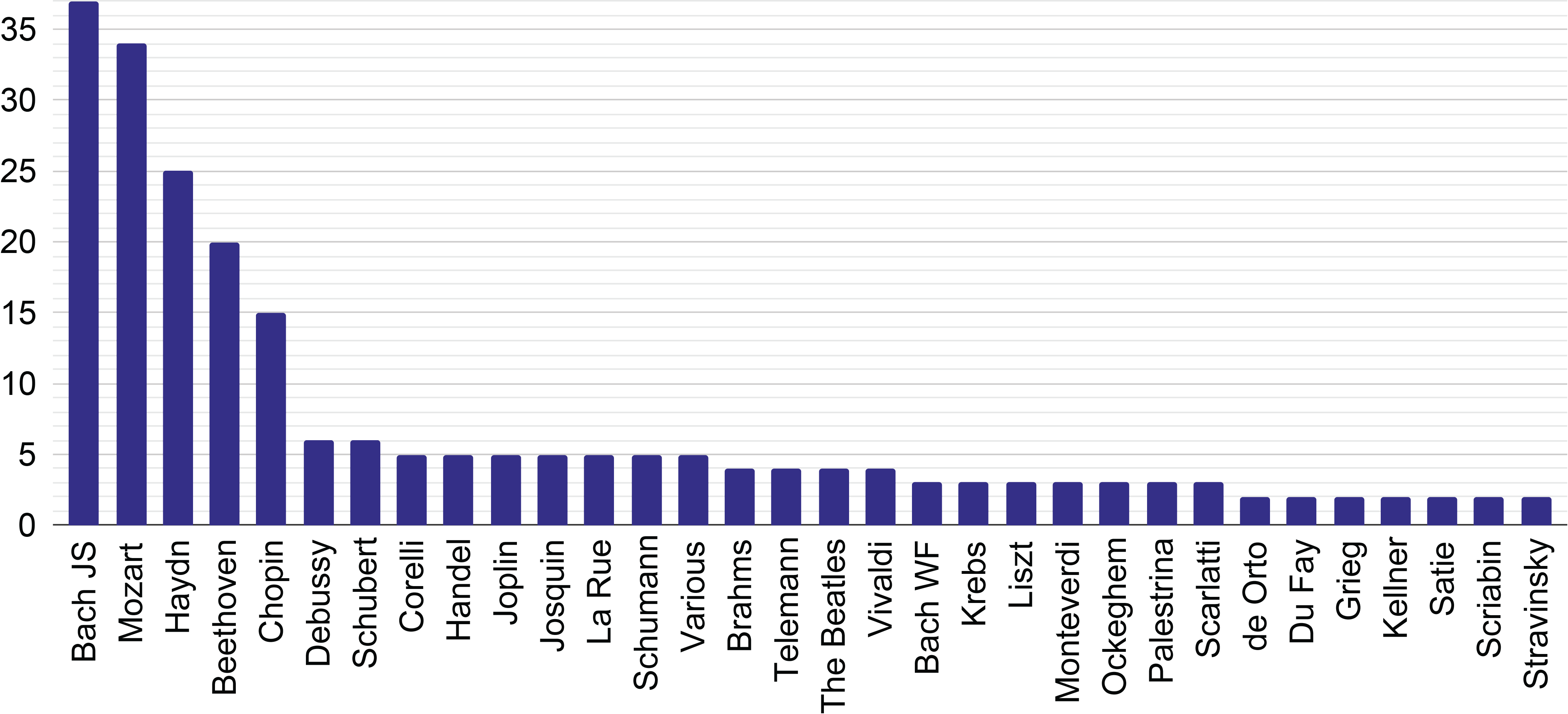
Figure 6
Visualization of the number of papers for composers, excluding composers for which only one paper was published.
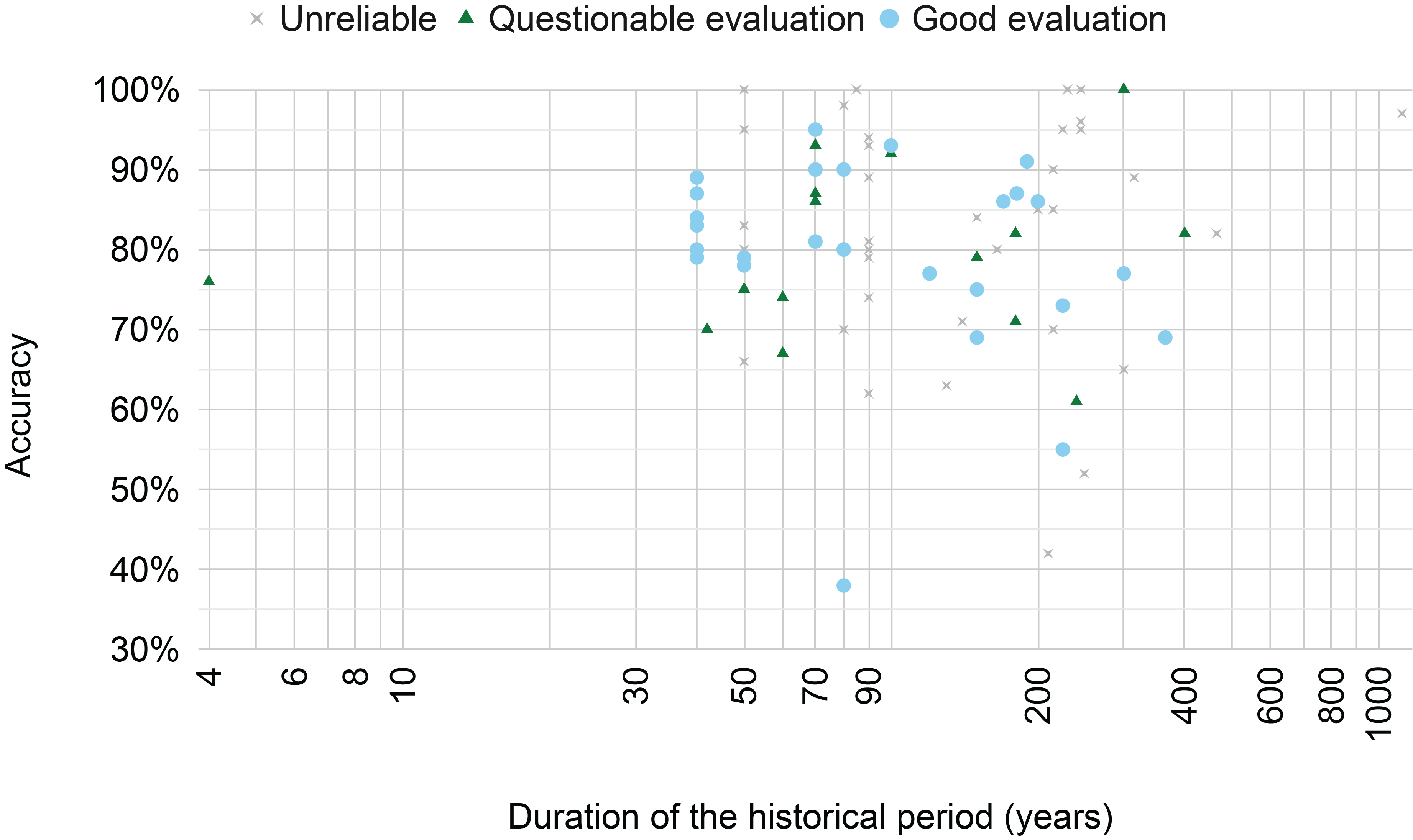
Figure 7
The best accuracy reported by each paper across the length of the period considered by the respective paper. The classification ‘unreliable’/‘questionable evaluation’/‘good evaluation’ is made by the author based on the discussion in Section 4.
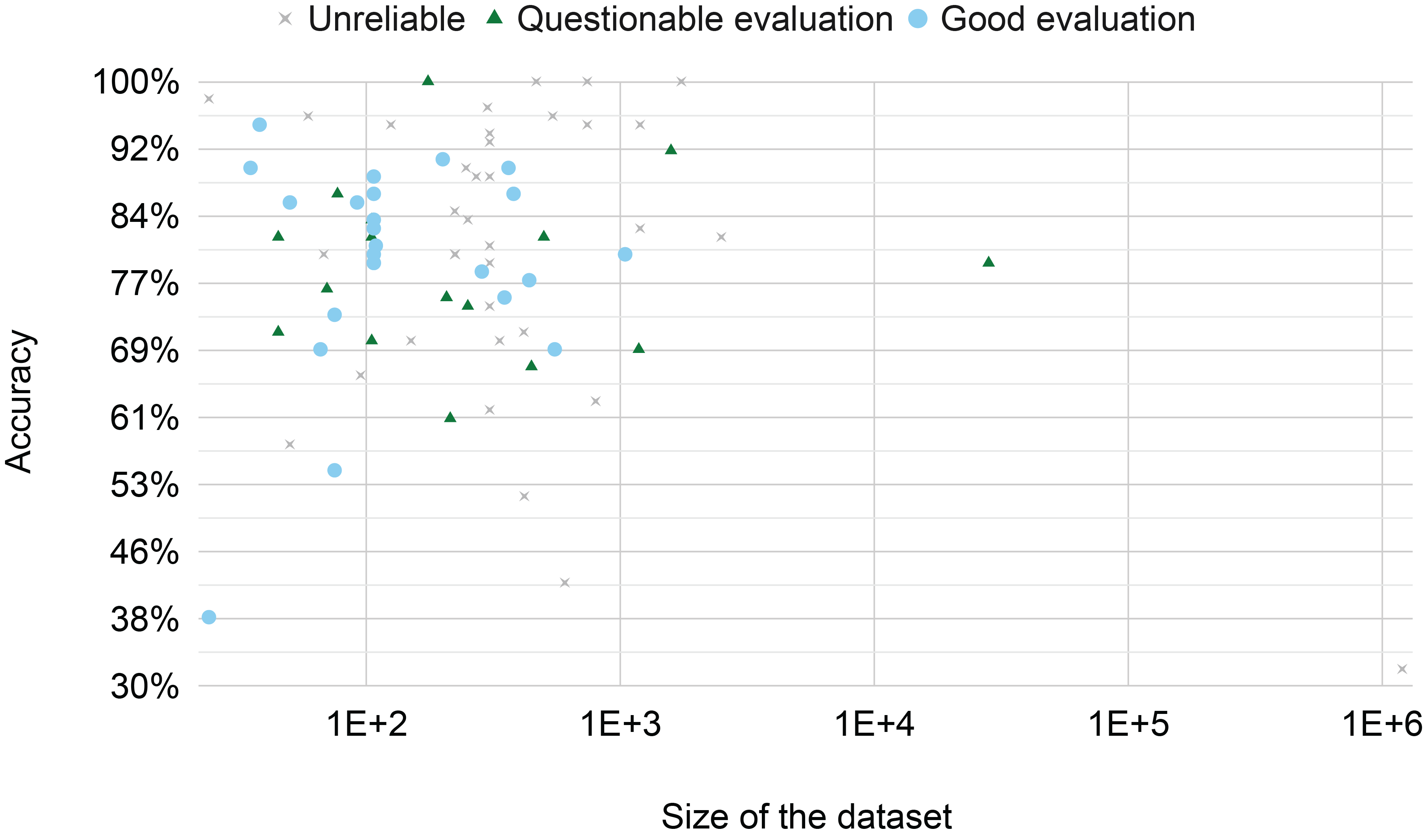
Figure 8
The best accuracy reported by each paper across the size of the dataset. The classification ‘unreliable’/‘questionable evaluation’/‘good evaluation’ is made by the author based on the discussion in Section 4.
Table 2
Datasets used by at least three studies and related accuracies.
| Dataset | Classes | Dataset Size | Imbalance | Paper | Accuracy | Cross‑Validation | Evaluation Class |
|---|---|---|---|---|---|---|---|
| 1 | Bach, Handel + Telemann + Haydn + Mozart | 306 | 2.33 | Backer & Kranenburg (2005) | 93% | LOO | Unreliable |
| Backer & Kranenburg (2005) | 94% | LOO | Unreliable | ||||
| Hontanilla et al. (2011) | 89% | Not specified | Unreliable | ||||
| 2 | Bach, Handel, Telemann, Haydn, Mozart | 306 | 1.74 | Backer & Kranenburg (2005) | 74% | LOO | Unreliable |
| Backer & Kranenburg (2005) | 81% | LOO | Unreliable | ||||
| Hontanilla et al. (2011) | 79% | Not specified | Unreliable | ||||
| Velarde et al. (2018) | 62% | 5‑fold | Unreliable | ||||
| 3 | Haydn, Mozart | 107 | 1.02 | Backer & Kranenburg (2005) | 79% | LOO | Good |
| Velarde et al. (2016) | 79% | LOO | Good | ||||
| Velarde et al. (2018) | 80% | LOO | Good | ||||
| Kempfert & Wong (2020) | 84% | LOO | Good | ||||
| Takamoto et al. (2024) | 83% | LOO | Good | ||||
| Alvarez et al. (2024) | 87% | LOO | Good | ||||
| Gelbukh et al. (2024) | 89% | LOO | Good | ||||
| 4 | Haydn, Mozart | 207 | 1.18 | Hillewaere et al. (2010) | 75% | LOO | Questionable |
| Wołkowicz & Kešelj (2013) | 75% | LOO | Questionable | ||||
| Velarde et al. (2018) | 75% | LOO | Questionable |
[i] The ‘imbalance’ has been computed as the ratio between the largest and the smallest class.
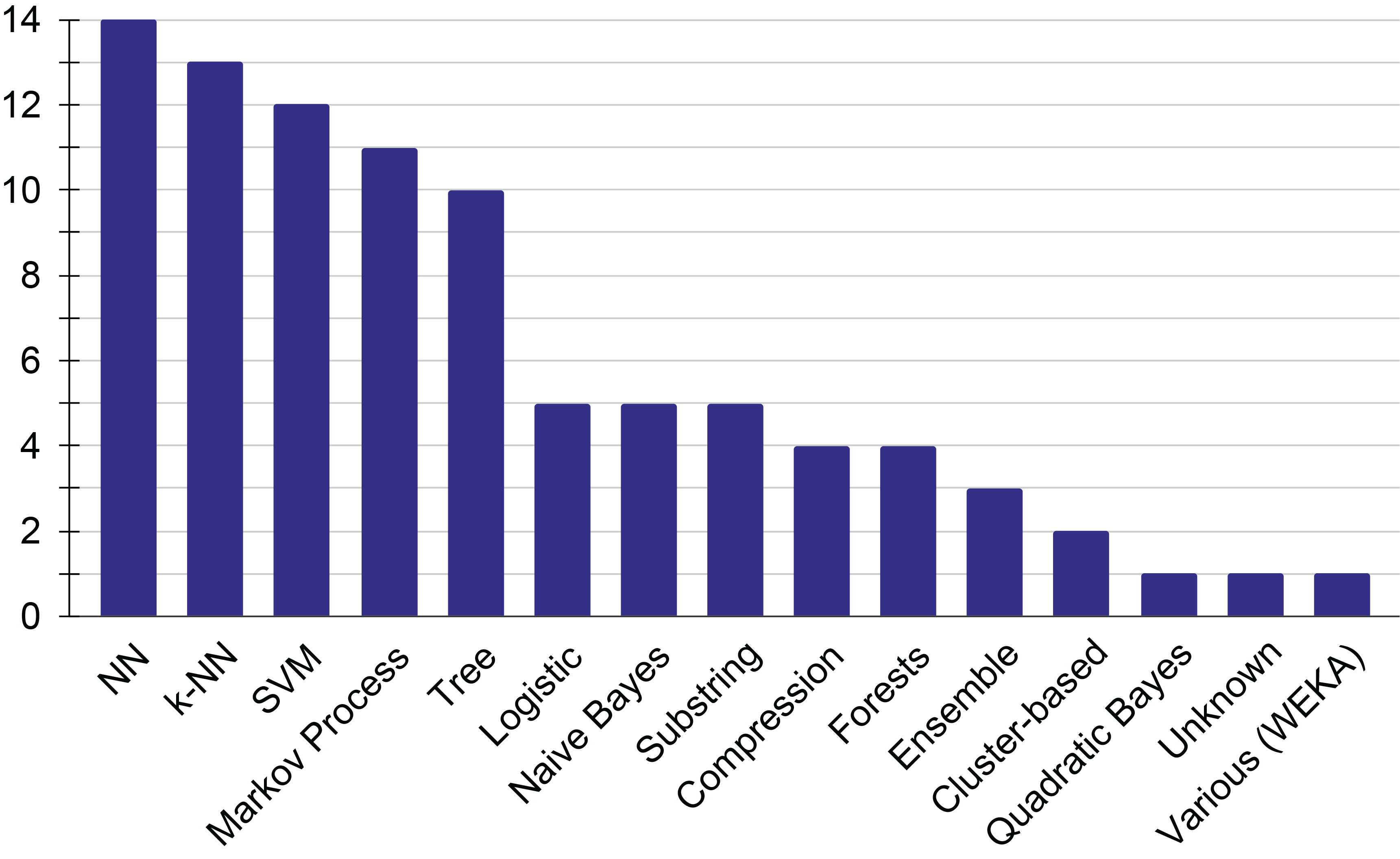
Figure 9
Visualization of the number of papers for each approach.

Figure 10
The moving average on a window of five years of the number of papers per approach, for the five most common approaches.
Table 3
Summary of music authorship attribution problems in the analyzed literature.
| Disputed attribution | Bach | Josquin des Prez | Lennon–McCartney |
|---|---|---|---|
| Originating work | van Kranenburg and Backer (2005) | Brinkman et al. (2016) | Glickman et al. (2019) |
| Number of papers | 3 | 3 | 1 |
| Best accuracy | >90% (van Kranenburg, 2008) | 91% (McKay et al., 2018) | 76% (Glickman et al., 2019) |
| Evaluation class | Good | Questionable | Questionable |
| Data integrity | Closed set, reliance on CCARH collection, no investigation on editorial choices | Closed set, reliance on JRP collection, weak transcription protocol | Closed set, manual transcription based on previous editions, no investigation on editorial choices |
