
1 Introduction
The ILLIAC system by Hiller and Isaacson (1955–1956) was one of the first applications of information technology in music (Hiller and Isaacson, 1958). Around the same time, Youngblood published the first statistical analysis of compositional styles (Youngblood, 1958). The field of computational stylistic analysis has since evolved, encompassing a diverse range of literature and overlapping with tasks like genre recognition and algorithmic composition. Youngblood's work highlights the longstanding significance of this topic in music computing, with important applications in musicology and database labeling (van Nuss et al., 2017).
In this work, computational methods applied to symbolic scores are considered in the attempt to systematically analyze the literature about composer identification.
The task of identifying the composer of a musical composition based on its symbolic score has been explored from various research perspectives. Computer scientists and statisticians refer to it as ‘composer identification’ or ‘composer classification,’ while musicologists and historians call it ‘authorship attribution.’ Despite differing aims, the typical scenario remains the same: given a set of music scores, develop an algorithm to predict the composer of a new score.
The synthesis of the surveyed literature reveals several distinct research perspectives from which the composer‑identification task is approached. One reason why scientists approach the composer‑identification task is to assess the ability of a model to capture the stylistic characteristics of a composer. In this case, composer identification is often associated with genre recognition and style or epoch classification. Another application is the labeling of large databases, often mined from the web, that present a large number of music documents but with noisy or erroneous metadata. In this latter case, the task of composer identification is associated with generic document tagging. In other works, the task is presented as a benchmark for comparing different feature extractors or architectures. When one of these scenarios occurs, the main focus is usually on the computational methods, with the final task hidden behind generic nomenclature such as ‘music tagging’ or ‘music classification.’
The aim of authorship attribution is instead to infer the author of a piece of music, given a set of possible authors. This task is often associated with the re‑attribution of works whose authorship is uncertain or disputed. A more in‑depth discussion of what authorship attribution is presented in Section 2. From a machine learning perspective, the authorship attribution problem may be regarded as a particular case of the composer‑identification task.
In this work, the existing literature about composer identification from symbolic music scores is critically reviewed, providing details of the methodology and criteria adopted during the analyses. Specifically, three main research questions motivated the study:
What computational approaches have been developed and applied to composer identification of symbolic music scores?
To what extent can music composer identification methods based on compositional style be considered reliable for authorship attribution?
How can the research community improve the reliability and reproducibility of music authorship attribution studies?
Many studies treat ‘composer identification’ as a machine‑learning benchmark—exploiting gross stylistic differences (e.g., Baroque vs. Romantic) to compare feature extractors or architectures—without any claim to musicological authorship attribution. By contrast, the primary focus is on those works whose aim is to support musicological re‑attribution of disputed or anonymous pieces, relying on subtle, individual stylistic traits rather than broad period or genre cues. Nonetheless, the two tasks are closely related, and the distinction is not always clear‑cut. While I have attempted to navigate this distinction throughout the analysis, it is often challenging to definitively categorize studies; many works, even when framing composer identification primarily as a benchmarking task, present findings or interpretations that could be perceived as having musicological relevance or broader implications for understanding style, making a rigid separation problematic. Moreover, ‘composer identification’ models may still be used for ‘authorship attribution,’ and their study is valid for having a better understanding of the literature and in trying to answer the research questions. My critique throughout this survey, therefore, evaluates the reliability and applicability of methods primarily through this lens of musicological authorship attribution.
While a systematic approach that enforces an objective view on the existing literature was adopted, the heterogeneity of the applications and of the nomenclature used in the literature made the effort of collecting existing works particularly difficult. Nonetheless, the first comprehensive analysis of the field is provided, achieving a greater understanding of the possibilities that computational techniques open for the re‑attribution of existing works.
In Section 2, the concept of authorship attribution and its similarities and differences with the more general task of composer identification are discussed. In Section 3, the systematic collection of papers is described. In Section 4, the evaluation methodologies adopted in the literature are reviewed, and a classification among reliable and unreliable protocols is defined. In Sections 5, 6, and 7, the repertoires, models, features, and file formats used in the literature are summarized. In Section 8, the existing problems of authorship attribution approached with computational style analysis are analyzed. Finally, in Section 9, the literature is numerically analyzed, and guidelines are drawn for future research in the composer‑identification task.
2 Defining Authorship Attribution in MIR
According to Juola (2007), authorship attribution can be defined as ‘any attempt to infer the characteristics of the creator of a piece of [linguistic] data.’ In this context, ‘characteristics of the creator’ refer to the stylistic and, in the original linguistic domain, textual patterns manifest in their work, which can be used for tasks such as identifying the author (attribution) or inferring other authorial traits (profiling). The problem is usually presented in one of three possible forms:
In the closed‑set problem, the author is known to be one of a finite set of possible authors.
In the open‑set problem, the author may not be one of the authors in the training set.
In the profiling problem, the author is unknown, and the task is to infer the author's characteristics.
In the case of music composer identification, the literature does not report forms of types 2 and 3, so the present work is mainly focused on problems of type 1.
In practice, in an authorship‑attribution task, a sample of data with uncertain authorship is available. To infer the true attribution based on statistical analysis, researchers collect a dataset to train a model and apply it to , obtaining predictions . A key issue with this approach is determining how much trust can be placed in the predictions .
Therefore, it is important to obtain a measure of merit for , which serves as a measure of reliability for . This remains an unsolved problem because the inherent complexity and high dimensionality of artistic style mean that the dataset used to train , even if generally representative of the authors, frequently does not provide dense coverage for the specific region of the input space defined by a particular .
A key challenge in applying composer‑identification techniques to musicological authorship attribution is distinguishing between features that genuinely reflect a composer's individual style and those that are merely indicative of broader categories such as historical period, genre, or nationality. While models trained to differentiate, for example, Baroque from Romantic composers might perform well for general classification or benchmarking purposes by leveraging these broad characteristics, their utility for fine‑grained authorship attribution—such as distinguishing between two contemporaneous composers of the same school—is limited if they rely primarily on such extramusical factors rather than nuanced, individual stylistic traits. This survey critically examines the literature with this distinction in mind.
In the context of a typical machine learning experiment, the authorship‑attribution task has three key peculiarities:
Researchers need to create a dataset that is as similar as possible to the questionable data and should avoid introducing confounding variables or editorial choices that obscure the composer's intrinsic style. In the case of music, this means:
defining the possible authors to be included in ;
collecting works and transcriptions that are musicologically valid and include minimal musicological interpretations or editorial choices;
encoding the music in a digital symbolic format that does not introduce confounding variables irrelevant to compositional style;
ensuring that the collected data encompass all the composers' stylistic characteristics; and
taking care of the quantitative aspects of the dataset, making it balanced with respect to styles and composers.
The final inference on is meaningless without a measure of merit computed on a sufficiently large evaluation dataset that differs from the one used to train the model .
In the open‑set problem, the evaluation of the model is particularly difficult, since the content of a class ‘anything else’ is extremely difficult to define.
Despite these peculiarities, the authorship‑attribution task can be considered a special case of the composer‑identification task.
While composer identification and authorship attribution can be applied to various media, this survey focuses on methods applied to symbolic music scores when the goal is to attribute authorship based on intrinsic compositional style. Consequently, I exclude studies that primarily rely on MIDI performances, audio recordings, or direct images of scores as their input. This exclusion is because these media types can introduce significant confounding variables that are distinct from the composer's original stylistic intent and can obscure the features relevant for musicological attribution:
MIDI performances are shaped by a performer's interpretation (e.g., dynamics, articulation, timing), which introduces variables related to performance choices rather than purely compositional ones. These interpretations might themselves be influenced by the performer's idea of the composer or prevailing cultural practices, further complicating the signal.
Audio recordings are subject to performer interpretation, recording technology, room acoustics, and audio engineering choices, all of which can obscure or alter the purely compositional features.
Images of music scores can introduce additional variables such as the quality of printing, specific editorial choices (especially in non‑urtext editions), and the graphical style of particular editions, which are not direct reflections of the composer's intrinsic style.
Such confounding variables are not merely random noise but can introduce systematic patterns (e.g., a performer's consistent interpretation shaped by their understanding of the composer, or artifacts from a specific recording process or edition). If a model learns from these patterns, it might achieve high classification accuracy, but it becomes ambiguous whether the model is identifying the composer's intrinsic style or these external factors. This ambiguity undermines the goal of genuine authorship attribution based on compositional style, as the classification task itself may no longer reliably target the composer's unique stylistic traits. For this reason, the survey focuses on symbolic representations that aim to minimize these external influences.
For genres like popular music, ‘symbolic representation’ for attribution purposes can encompass published scores, lead sheets, or other forms of notation that capture core compositional elements (melody, harmony, rhythm), provided the analysis focuses on these authorial aspects rather than on performance or audio production characteristics. The key criterion for inclusion in this survey is that the input data aim to represent the composer's notated or structurally intended musical information, minimizing confounding variables from performance interpretation or audio production. Studies like Glickman et al. (2019), which base their work on symbolic transcriptions of audio recordings to analyze compositional style, therefore fit within this scope.
For broader context and to delineate the survey's scope from its primary focus on composer attribution, I note that a related area involves works adopting computer vision techniques for attributing the scribe of a manuscript. While these works do not take into account the stylistic properties of the music, they are obviously of interest in the field of authorship attribution. Consequently, an additional search of documents was conducted and found 12 documents falling into this category. Of these, four make use of the dataset CVC‑MUSCIMA (Fornés et al., 2012), which contains images of handwritten music collected in modern times, thus not focusing on historical composer identification problems. Another four studies are authored by Fornés (Fornés et al., 2008, 2009, 2010; Fornés and Lladós, 2010) and the remaining four articles (Bruder et al., 2004; Göcke, 2003; Niitsuma et al., 2013, 2016) focus on historical manuscripts and set the purpose of their efforts in the automatic organization of digital archives. I found no real‑world attribution problem that was tackled with computer vision techniques. The reason probably lies in the fact that manuscripts of the real composers are rarely available and, when they are, other, more reliable techniques can be used for assessing the provenance of the manuscript.
3 Collecting Literature
3.1 Search methodology
The topic under investigation spans multiple decades, during which the lexicon of computer science and statistics has evolved. Consequently, different queries were employed for distinct time periods. To account for this variation, time blocks were selected, and academic search engines were used to locate scientific papers in the field of composer identification from symbolic scores. In particular, the growing availability of digital academic documents in recent years necessitated the use of shorter time blocks for more recent periods. The selected time blocks are detailed in Table 1.
Table 1
Queries used for each time block.
| Time blocks | Search Key | ||
|---|---|---|---|
| Years | Duration | Token 1 | |
| 0–1950 | ‑ | A AND B | |
| 1951–1970 | 20 | A AND B | |
| 1971–1990 | 20 | A AND B | |
| A AND C | |||
| 1991–2000 | 10 | A AND C | |
| 2001–2010 | 10 | A AND C AND D ‑optical | |
| 2011–2015 | 5 | A AND C AND D ‑optical | |
| 2016–2018 | 3 | A AND C AND D ‑optical | |
| 2019–2020 | 2 | A AND C AND D ‑optical | |
| 2021–2023 | 2 | A AND C AND D ‑optical | |
| 2024– | 1 | A AND C AND D ‑optical | |
| Legend | |||
| A | music AND composer AND style | ||
| B | computer OR information OR statistics OR algorithm | ||
| C | classification OR identification OR recognition OR attribution | ||
| D | ‘symbolic level’ OR ‘music score’ OR midi OR musicxml OR kern | ||
A set of search queries was formulated using terminology adapted to different historical periods. These queries are listed in Table 1. The terms ‘music,’ ‘composer,’ and ‘style’ were retained consistently across all queries due to their specificity to the task. However, during the era of Youngblood's contributions, terms such as ‘classification’ or ‘recognition’ were not associated with statistical learning methods. Consequently, more generic terms relevant to automation processes, such as ‘information,’ ‘statistics,’ ‘computer,’ and ‘algorithm’ were used as substitutes.
Initially, computational limitations precluded large‑scale digital analysis of sound signals. By the 2000s, however, the field of Music Information Processing (MIP) began to explore the audio domain extensively. Presently, the majority of literature in MIP focuses on audio signal processing methods. To refine the search results to studies using the symbolic level, specific terms such as ‘symbolic level,’ ‘music score,’ ‘MIDI,’ ‘kern,’ and ‘musicXML’ were included. As discussed in Section 2, this focus is essential for investigating authorship attribution in music scores, which cannot be reliably applied to performance data or audio recordings due to potential confounding variables introduced by a performer's stylistic interpretation, which are distinct from the composer's intrinsic style. Accordingly, studies employing audio recordings or MIDI performance data were excluded. A further refinement involved excluding works on optical music recognition.
The search engine used was Google Scholar, which retrieves results from major academic publishers and databases, including those indexed in Scopus and the Web of Science, while extending the corpus to potentially include other documents. This engine's capability to search within the full texts of available works, rather than being limited to reviewing only metadata such as titles and abstracts, was critical for identifying publications that, while not primarily focused on composer identification, still contained relevant information and experiments. Despite this advantage, the results often included noisy entries, and there was no assurance that all retrieved documents had undergone peer review. Only papers published in academic journals or presented at scientific conferences with a peer‑review process involving at least two field experts were included. This criterion led to the exclusion of Bachelor's, Master's, and Ph.D. theses, as well as recent preprint papers without peer review.
To further narrow the analysis, works that did not implement a full task of classifying musical compositions by composer were excluded. Specifically, papers providing only generic analysis without demonstrating the effectiveness of methodologies through classification tests with numerical results were not considered. However, studies using both composers and genres in the classification labels were included, as such investigations are potentially relevant for characterizing composers' styles.
The first 10 pages of results from each of the 10 queries listed in Table 1 were analyzed, resulting in the consideration of 1,000 papers. From these, 53 papers meeting the specified criteria—peer review, full classification tasks, and use of symbolic scores—were selected. During the peer‑review process, another five papers were added, primarily published during the review time‑frame. The Preferred Reporting Items for Systematic Reviews and Meta‑Analyses flowchart summarizing the literature review process is presented in Figure 1.

Figure 1
Preferred Reporting Items for Systematic Reviews and Meta‑Analyses flowchart (Haddaway et al., 2022) of the literature review conducted in this work.
3.2 Search results
The statistical characterization of composers' styles has been studied since at least 1958 (Youngblood, 1958). However, the first work addressing the problem through the implementation of computational tools was published in 1993 at the Italian Colloquio di Informatica Musicale (Johnson, 1993). In the intervening period, particularly in the 1960s, several studies followed Youngblood's methodology by applying information theory to music analysis, but these did not compute proper classification performance (Fucks, 1962a,b; Gabura and Oliver, 1965; Knopoff and Hutchinson, 1983; Mendel, 1969; Siromoney and Rajagopalan, 1964) and generally did not utilize computational tools, with the exception of Mendel (1969).
Two additional studies were published in the 1990s (Hörnel and Menzel, 1998; Westhead and Smaill, 1994) prior to the work that is often cited as the earliest significant publication in the field (Pollastri and Simoncelli, 2001). Subsequently, 12 papers from the decade 2000–2009, 32 papers from the decade 2010–2019, and 11 papers since 2020 (excluding the present work) were identified. The distribution of these publications across the years is depicted in Figure 2.
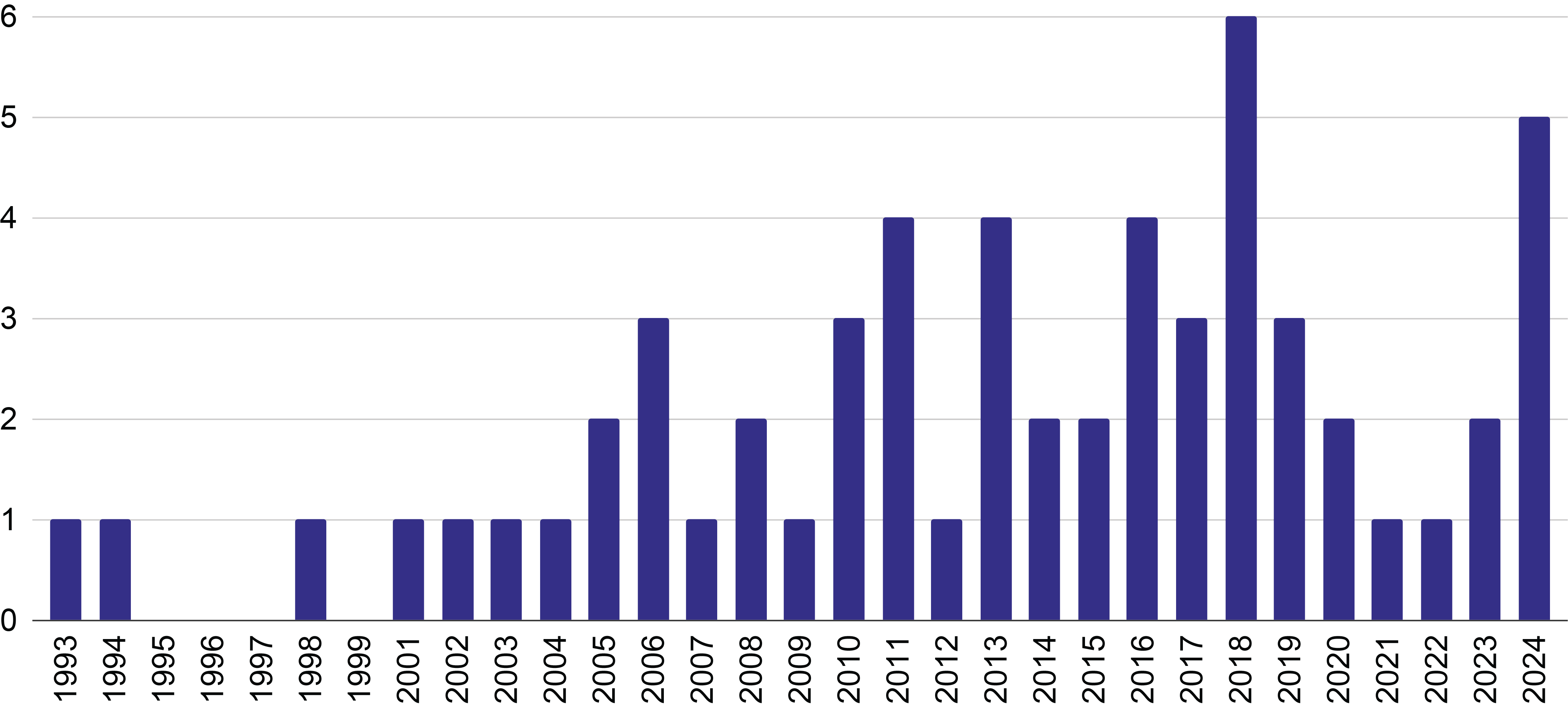
Figure 2
Distribution of the number of publications across the years.
It should be noted that, since 2020, some studies have addressed composer identification using MIDI performance data (Chou et al., 2021; Foscarin et al., 2022; Kong et al., 2020; Lee et al., 2020; Yang and Tsai, 2021). These works were intentionally excluded to avoid confounding variables related to performer interpretation, as detailed in Section 2.
In total, 58 works meeting the criteria outlined in Section 3.1 were collected. From each paper, all experiments involving composer‑identification tasks were reviewed, and the best‑performing models for each dataset used in each paper were recorded. This process resulted in the identification of 87 models.
4 Evaluation Methodologies
Given the critical importance of reliable evaluation protocols in authorship attribution (Rudman, 2012), it is essential to employ robust metrics that accurately reflect model performance. A model with unsatisfactory performance metrics is unsuitable for authorship attribution because there its predictions are not reliable. However, this principle is often overlooked in the literature, with some authors attributing works based on model parameters despite low classification effectiveness—see Section 8.
Additionally, the reliability of the measure of merit strongly depends on the evaluation protocol, as Sturm (2014) highlights: a well‑designed protocol free from confounding variables is essential, and reproducibility requires selecting experimental components based on the scientific question rather than convenience. In any case, the evaluation measure is fundamental: if it is flawed, any conclusion drawn from it is questionable. To gain a comprehensive understanding of the literature, I categorized works based on their evaluation measures and analyzed other variables of the datasets for each category.
While this methodology may seem overly critical, it is essential to obtain a deeper understanding and define strong guidelines for future works regarding experimental design—see Section 9. It is also important to consider that the evaluation strategies in the surveyed literature may reflect the original aims of the studies. For instance, a paper focused on benchmarking a new algorithm might employ a dataset with clearly distinct composer styles and report ‑measure, which, while potentially valid for its specific benchmarking goal, would be insufficient for assessing reliability in a nuanced musicological authorship attribution context. My critique primarily assesses evaluation choices from the perspective of their suitability for the latter.
While accuracy is a straightforward measure, it is often inadequate for imbalanced datasets, which are common in composer‑identification tasks. Despite its widespread use in the literature, accuracy can be misleading, as it does not account for the distribution of classes. The vast majority of the existing works in the analyzed literature adopt the standard accuracy, often as the only metric.
Some studies have used ROC curves, which plot the true‑positive rate against the false‑positive rate (FPR) across different threshold settings. ROC curves provide qualitative insights into model performance, particularly in binary classification tasks. However, their applicability is limited when dealing with multiclass problems or when true labels for are unavailable. The area under the ROC curve (AUC) shares these limitations, making it less suitable for comprehensive evaluation. Four works (Glickman et al., 2019; Herremans et al., 2015, 2016; Tan et al., 2019) used AUCs.
The ‑measure, originating from information retrieval, combines precision and recall into a single metric. While useful for highly imbalanced datasets, the ‑measure can be problematic when the negative class is the minority, potentially leading to inflated scores that do not accurately reflect model performance. Additionally, its non‑linear nature with respect to True Positive Rate (TPR) and True Negative Rate (TNR) can complicate interpretation (Christen et al., 2023). In the literature, six works (Hedges et al., 2014; McKay et al., 2018; Tan et al., 2019; Karystinaios et al., 2020; Zhang et al., 2023; Mirza et al., 2024) adopted the ‑measure in their analysis, while one work (van Nuss et al., 2017) used the AUC of the precision–recall curve.
Recent advances have highlighted the Matthews correlation coefficient (MCC) and balanced accuracy (BA) as more reliable alternatives (Chicco et al., 2021). BA, in particular, has gained traction due to its simplicity, interpretability, and linearity with respect to TPR and TNR. This metric ensures balanced error rates across classes and is equivalent to standard accuracy when the dataset is perfectly balanced. For multiclass scenarios, BA is extended by averaging the TPRs for all classes—i.e., the average recall—providing a fair evaluation across all categories and maintaining linear equivalence to the mean per class error and informedness. In the literature, three works explicitly adopted the BA (Simonetta et al., 2023; Nakamura and Takaki, 2015), while another two reported it under different names (‘overall accuracy’ or ‘average recall’) (Verma and Thickstun, 2019; Mirza et al., 2024).
In this work, BA is recommended as the preferred evaluation metric due to its robustness and interpretability, ensuring a more reliable assessment of model performance in the context of authorship attribution. Moreover, it can be derived directly from the confusion matrix and is equivalent to standard accuracy when the classes are evenly distributed. The BAs of studies providing confusion matrices was recalculated for 10 works. Additionally, 19 works used the standard accuracy for datasets perfectly balanced. Overall, 33 works out of 58 were included in the analysis using BA as measure of merit.
Regarding the hold‑out strategies, only 56 of the 88 recorded experiments use some form of cross‑validation, of which 25 use a ‘leave‑one‑out’ strategy. Of the remaining 32 experiments, 5 use random folds and 27 use a simple hold‑out strategy.
The selected studies were categorized into three groups: ‘unreliable,’ ‘questionable evaluation,’ and ‘good evaluation.’ The ‘unreliable’ category includes publications using inappropriate evaluation metrics and/or lacking cross‑validation. The ‘good evaluation’ category includes studies where balanced accuracy could be computed and a ‑fold cross‑validation strategy was employed. The ‘questionable evaluation’ category encompasses all remaining works, such as those using random‑fold cross‑validation or relying on the ‑measure. It must be noted that, in those cases in which the dataset size and model complexity are really large, cross‑validation procedures are hardly applicable.
As illustrated in Figure 4, we classified 27 experiments as having a ‘good evaluation,’ 21 as having a ‘questionable evaluation,’ and 40 as having an ‘unreliable’ evaluation. Additionally, Figure 3 shows the number of experiments per year among publications across the three evaluation categories. The ‘unreliable’ category is prevalent in the earlier years, while the ‘good evaluation’ category has gained prominence in recent years, particularly since 2010.
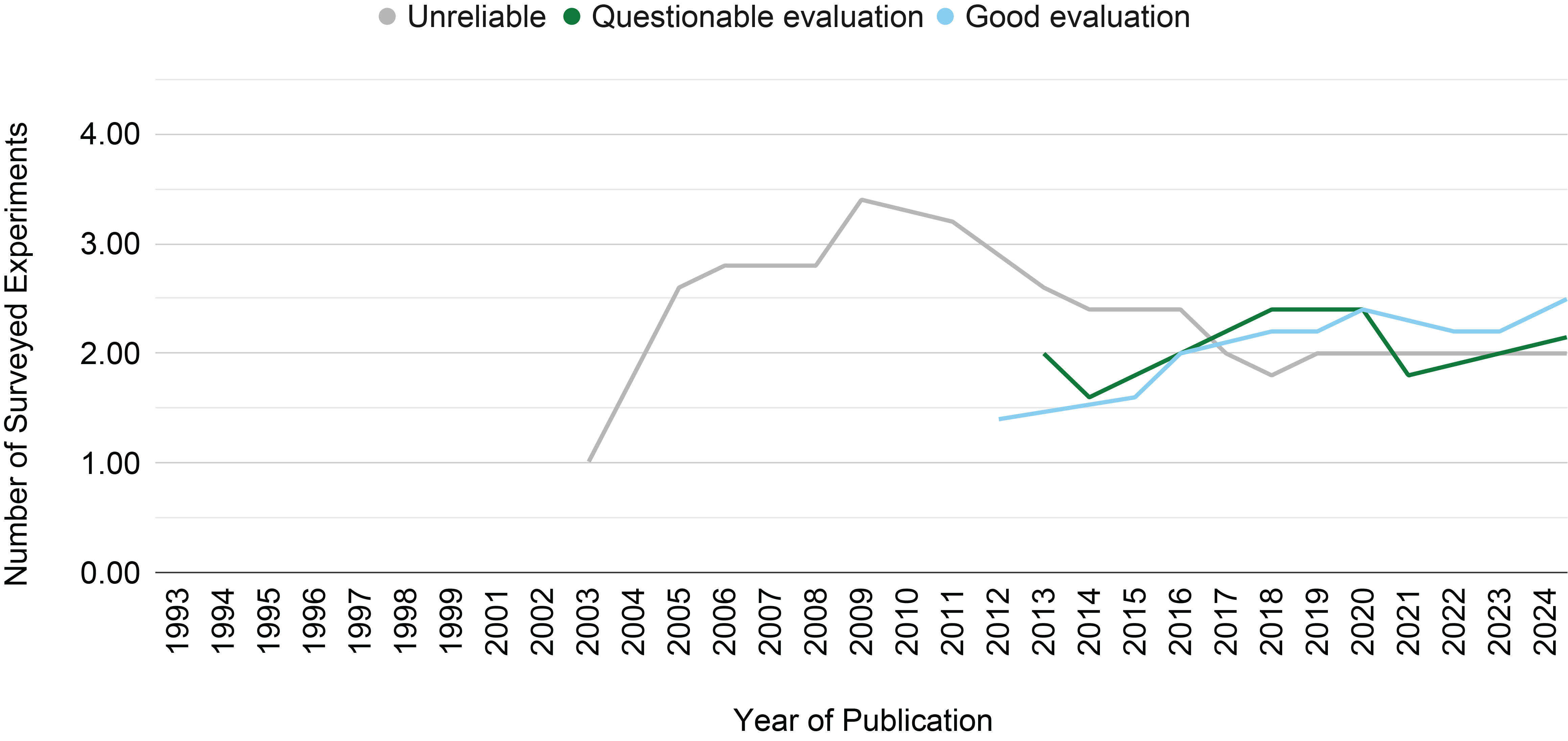
Figure 3
The moving average on a window of five years of the number of surveyed experiments per year of publication across the evaluation categories identified in this survey.
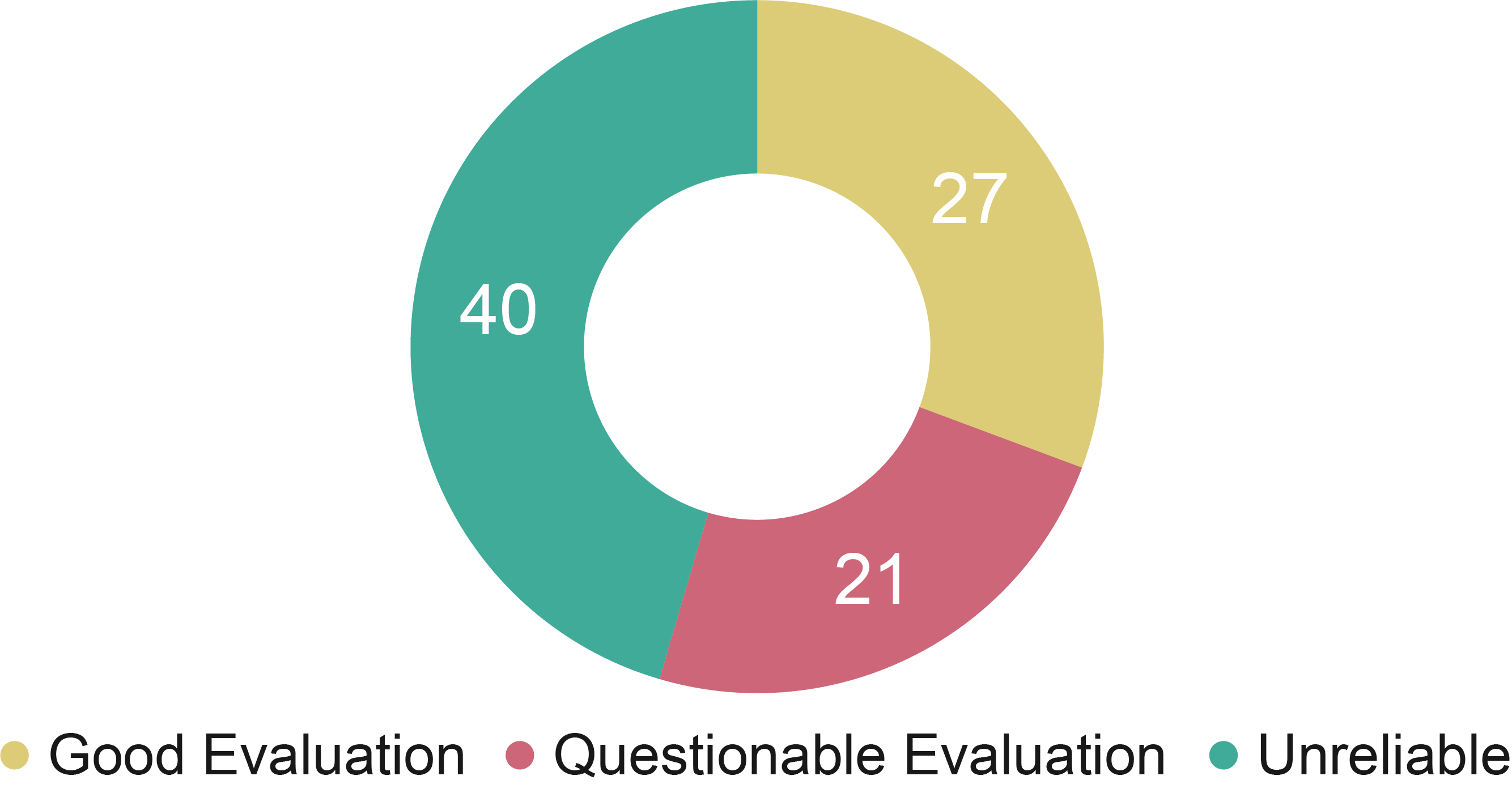
Figure 4
Distribution of the recorded experiments across the evaluation classes identified.
5 Repertoire and Datasets
Some existing studies approach composer identification primarily as a classification benchmark rather than as a musicological authorship–attribution task. Particularly in earlier decades, computational models were frequently tested on heterogeneous repertoires, often spanning from the Baroque era to the 20th century, and, in some instances, including medieval Gregorian chants (Cruz‑Alcázar et al., 2003). Such material is typically selected because, when the composers compared have markedly different cultural and aesthetic backgrounds, their musical styles can often be distinguished more easily through quantitative methods, simplifying the statistical challenge. While this approach may be suitable for preliminary evaluations or for benchmarking tasks where the goal is to test a model's ability to capture gross stylistic differences, it is insufficient to demonstrate a model's capability to identify composers' styles accurately for the purpose of musicological attribution. Effective evaluation for musicological authorship attribution must ensure the model is discriminating based on nuanced, individual musical style rather than easily separable extra musical factors that may correlate with style, such as genre, historical period, or geographical region (Rudman, 2012). Relying on these broader factors limits the model's applicability for distinguishing between, for example, contemporaneous composers within the same tradition or school.
Beyond the authorship‑attribution task, related MIR tasks include the automatic tagging of music in large databases (van Nuss et al., 2017) and comparative studies of composers' styles—often focusing on Mozart and Haydn—without addressing specific attribution problems (Backer and van Kranenburg, 2005; Hillewaere et al., 2010; Hontanilla et al., 2011; Wołkowicz and Kešelj, 2013; Velarde et al., 2016; Hajj et al., 2018; Velarde et al., 2018; Verma and Thickstun, 2019; Kempfert and Wong, 2020). Even in these cases, the material selected for evaluation should not be distinguishable based on extra musical factors to ensure the validity of the results.
As shown in Figure 6, the most frequently studied composer in composer‑identification tasks is Bach, followed by Mozart, Haydn, Beethoven, and Chopin. In recent years, there has been increased focus on Mozart, Haydn, and Beethoven, as illustrated in Figure 5. This distribution is likely influenced by the popularity of the CCARH corpora (Sapp, 2005), which are often used for music analysis in the symbolic domain. Custom datasets have been rarely employed, and, when used, they were typically unsupervised by musicologists, mined from user‑contributed archives, and biased towards German composers and Western art music. Exceptions exist, primarily involving Chinese and Japanese folk music (Shan et al., 2002; Ruppin and Yeshurun, 2006) and popular music, particularly The Beatles (Pollastri and Simoncelli, 2001; Glickman et al., 2019).
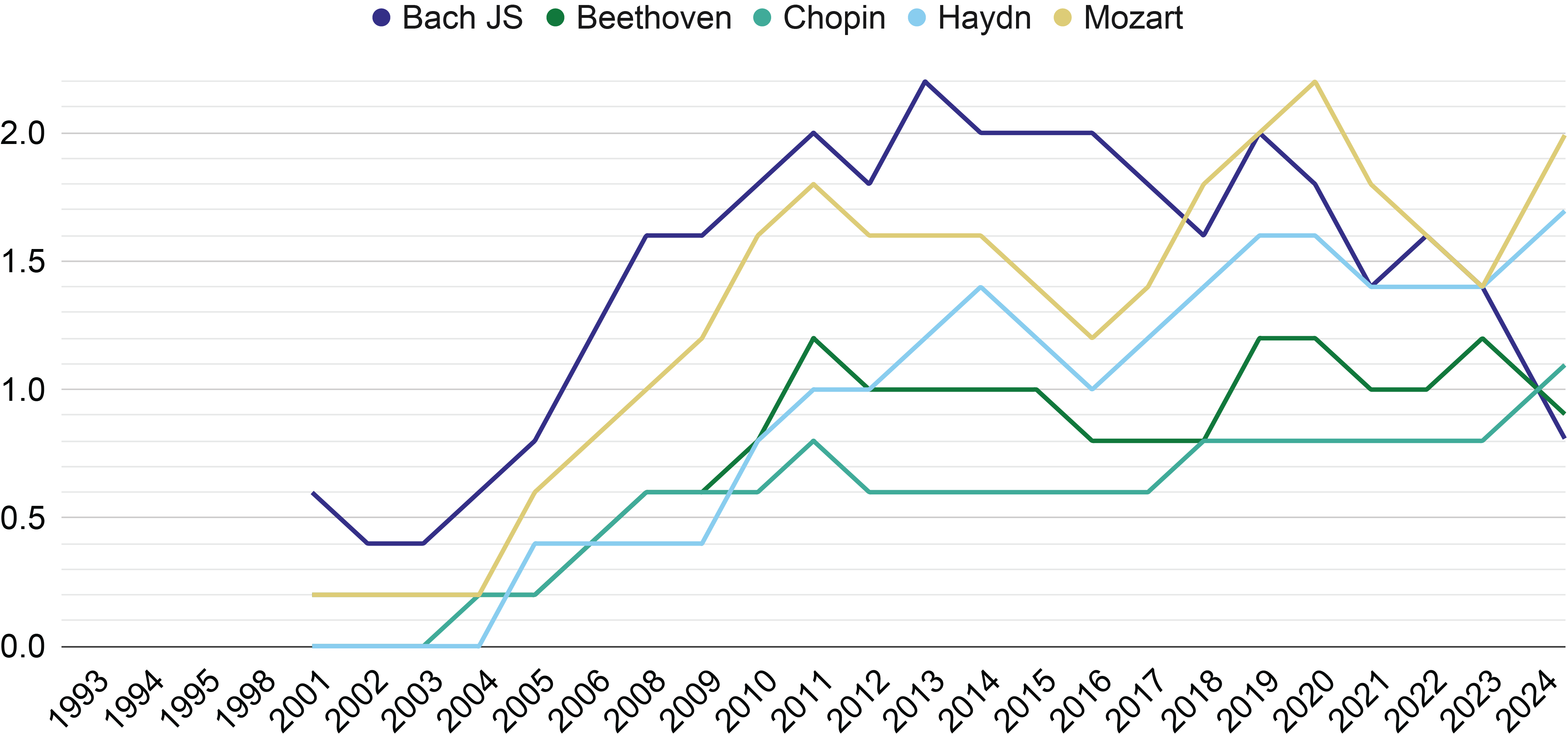
Figure 5
The moving average on a window of five years of the number of papers per composer, for the five most common composers.
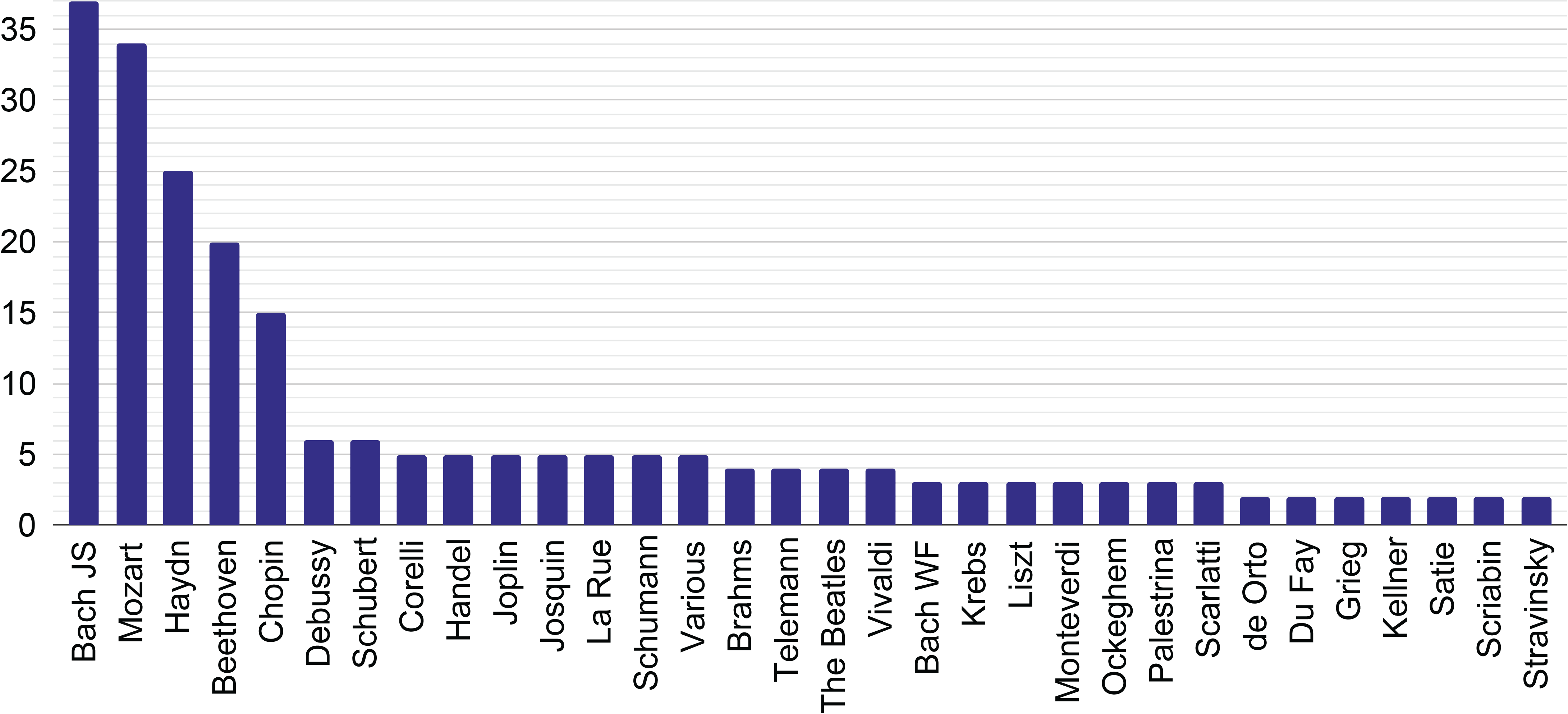
Figure 6
Visualization of the number of papers for composers, excluding composers for which only one paper was published.
The median dataset size in the reviewed experiments is 251 instances, with a minimum of 24 and a maximum of 1.2 million. A total 85% of the experiments used a dataset with less than 1000 instances—Figure 8 shows the distribution of the dataset size. However, comparing dataset sizes is challenging because individual instances may differ in duration, number of notes, measures, or movements. While this variation is less significant during the training phase, it is critical for the test phase, where true and false positives/negatives are counted in terms of instances.
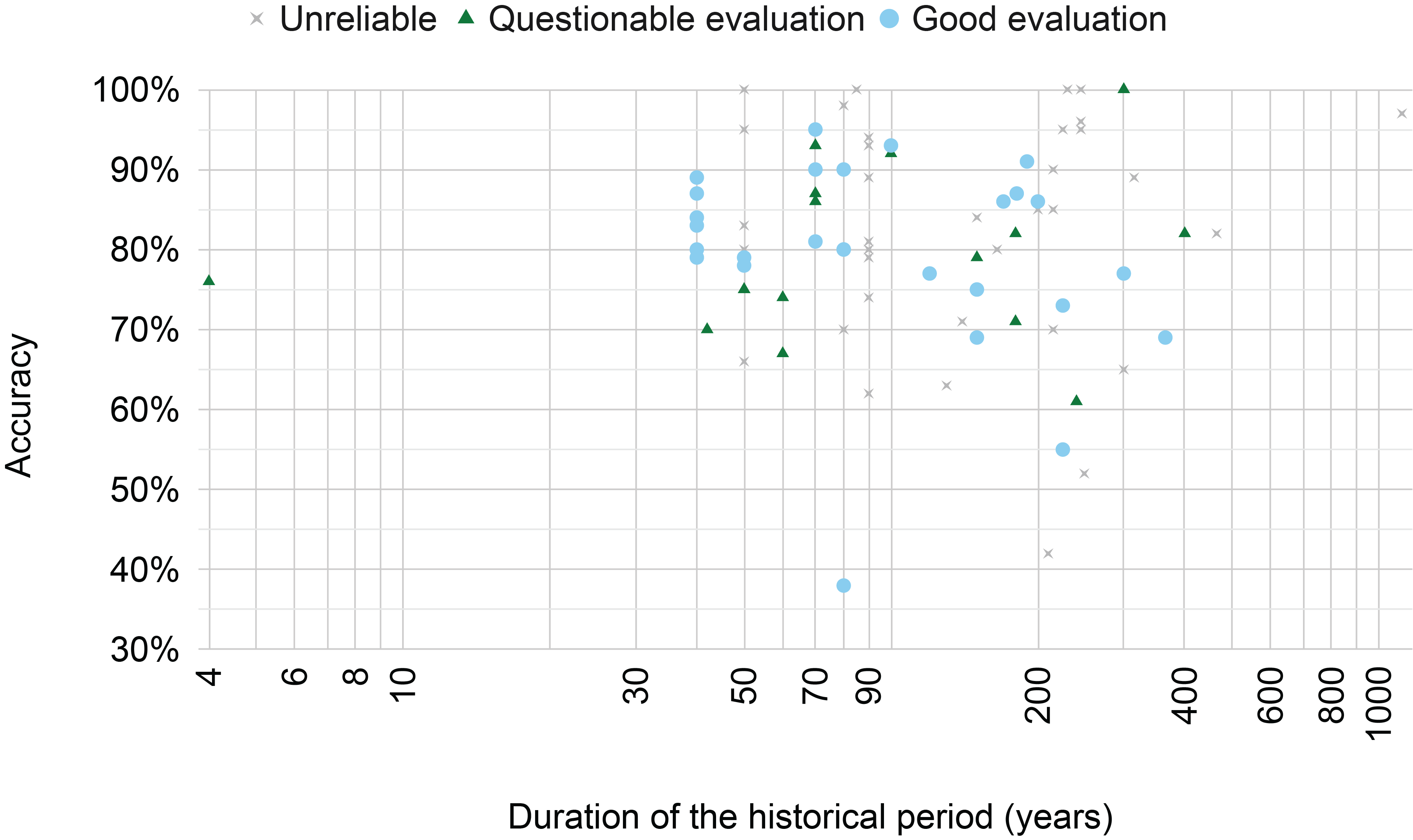
Figure 7
The best accuracy reported by each paper across the length of the period considered by the respective paper. The classification ‘unreliable’/‘questionable evaluation’/‘good evaluation’ is made by the author based on the discussion in Section 4.
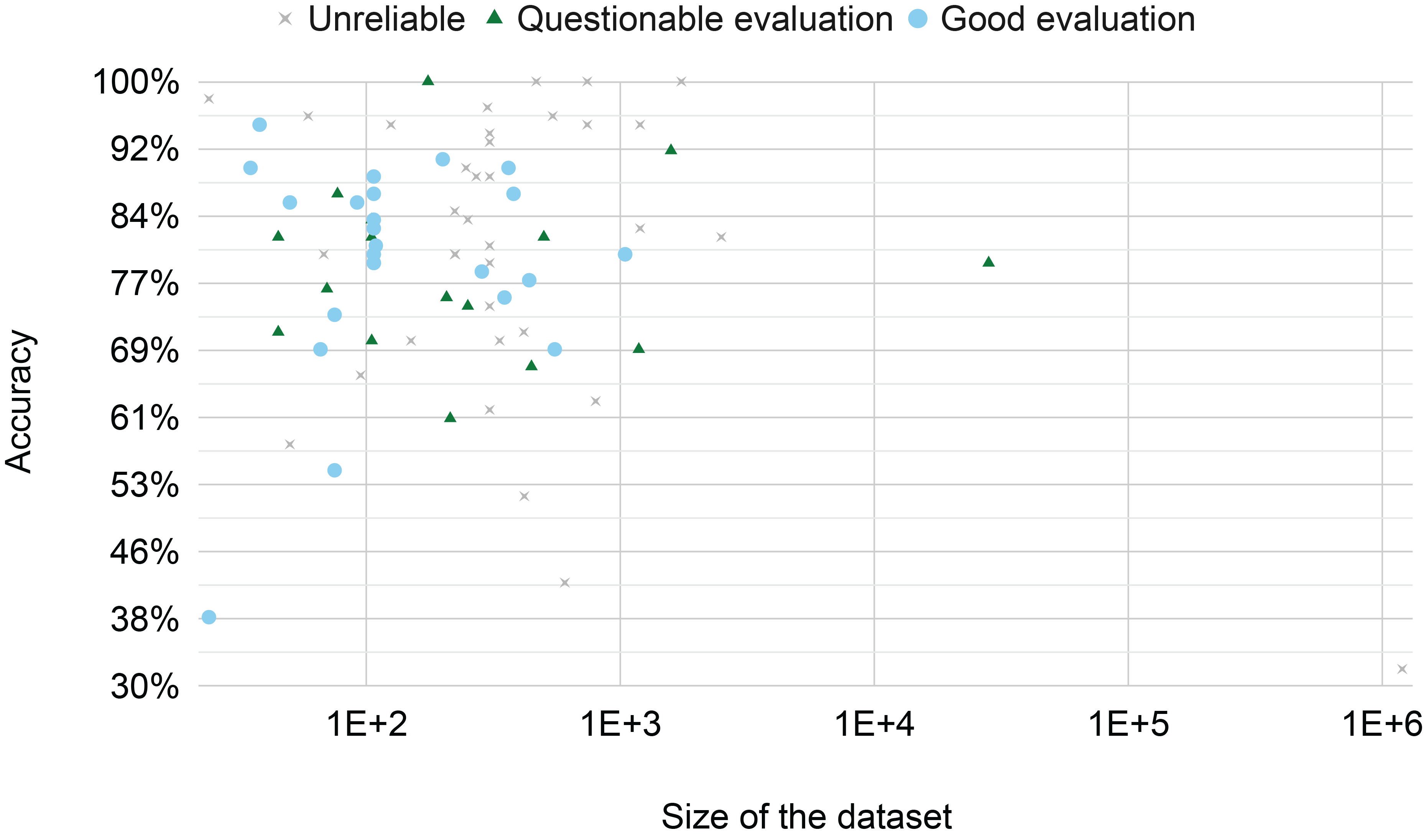
Figure 8
The best accuracy reported by each paper across the size of the dataset. The classification ‘unreliable’/‘questionable evaluation’/‘good evaluation’ is made by the author based on the discussion in Section 4.
The average number of classes in the datasets is 4, with a minimum of 2 and a maximum of 19, but some authors did not report this aspect (Dor and Reich, 2011; van Nuss et al., 2017). For practical applications, the capacity to handle a large number of classes is generally advantageous but not essential if the composers are carefully selected by domain experts.
Only a few datasets have been used in more than three studies. Their details and associated accuracies are summarized in Table 2.
Table 2
Datasets used by at least three studies and related accuracies.
| Dataset | Classes | Dataset Size | Imbalance | Paper | Accuracy | Cross‑Validation | Evaluation Class |
|---|---|---|---|---|---|---|---|
| 1 | Bach, Handel + Telemann + Haydn + Mozart | 306 | 2.33 | Backer & Kranenburg (2005) | 93% | LOO | Unreliable |
| Backer & Kranenburg (2005) | 94% | LOO | Unreliable | ||||
| Hontanilla et al. (2011) | 89% | Not specified | Unreliable | ||||
| 2 | Bach, Handel, Telemann, Haydn, Mozart | 306 | 1.74 | Backer & Kranenburg (2005) | 74% | LOO | Unreliable |
| Backer & Kranenburg (2005) | 81% | LOO | Unreliable | ||||
| Hontanilla et al. (2011) | 79% | Not specified | Unreliable | ||||
| Velarde et al. (2018) | 62% | 5‑fold | Unreliable | ||||
| 3 | Haydn, Mozart | 107 | 1.02 | Backer & Kranenburg (2005) | 79% | LOO | Good |
| Velarde et al. (2016) | 79% | LOO | Good | ||||
| Velarde et al. (2018) | 80% | LOO | Good | ||||
| Kempfert & Wong (2020) | 84% | LOO | Good | ||||
| Takamoto et al. (2024) | 83% | LOO | Good | ||||
| Alvarez et al. (2024) | 87% | LOO | Good | ||||
| Gelbukh et al. (2024) | 89% | LOO | Good | ||||
| 4 | Haydn, Mozart | 207 | 1.18 | Hillewaere et al. (2010) | 75% | LOO | Questionable |
| Wołkowicz & Kešelj (2013) | 75% | LOO | Questionable | ||||
| Velarde et al. (2018) | 75% | LOO | Questionable |
[i] The ‘imbalance’ has been computed as the ratio between the largest and the smallest class.
I attempted to evaluate the model accuracy—or balanced accuracy where it could be computed—based on the type of dataset. The resulting scatter plots are shown in Figures 7 and 8.
6 Representational Frameworks for Symbolic Music
The way symbolic music is represented significantly impacts the effectiveness of composer identification models. The literature showcases a variety of approaches, which can be broadly categorized by how features are derived and their fundamental representational form, as detailed below. These representations are typically derived from various digital music file formats (see Section 6.2).
6.1 Feature representations
Different feature representations emphasize distinct aspects of musical structure, influencing both the interpretability and effectiveness of computational models. This section outlines the primary categories of feature representations, their construction, relevance, and applications.
6.1.1 Statistically‑derived descriptors
Statistically‑derived descriptors summarize musical content using statistical measures or counts of predefined elements. These features include frequencies of pitches, intervals, chords, or rhythmic values, as well as higher‑order statistics like means, variances, entropy, and Zipf–Mandelbrot parameters (Marques and Reis, 2013; Machado et al., 2004). Tools such as jSymbolic (McKay et al., 2018), Music21 (Cuthbert et al., 2011), and Musif (Llorens et al., 2023) automate the extraction of these descriptors. A recent comparative study by Simonetta et al. (2023) highlights that the choice and combination of statistically‑derived descriptors are crucial for effective composer identification. Their findings indicate that the optimal feature set is often task‑dependent—meaning that different musical characteristics become more or less salient depending on the specific analytical goal (e.g., broad period classification versus distinguishing closely related composers). Furthermore, the study suggests potential benefits from combining features derived from different extraction tools or methodologies, as these can capture complementary facets of musical style, leading to a more comprehensive representation. This type of descriptors can capture pitch‑class distributions, harmonic dissonance, or adherence to compositional rules (Doerfler and Beck, 2013; Johnson, 1993). These features are typically represented as scalar values or numerical vectors, such as histograms or frequency distributions, and are widely used with machine learning models like support vector machines (SVMs), naive Bayes, decision trees, and k‑nearest neighbors (k‑NN). Their strengths lie in their ability to adeptly summarize overall musical characteristics into compressed, often interpretable values, and their computational efficiency; however, they typically abstract away temporal information and may require extensive hand‑crafting. Despite these limitations, they remain effective for tasks like composer classification, music similarity, and corpus analysis (Backer and van Kranenburg, 2005; Sadeghian et al., 2017).
6.1.2 Sequential and pattern‑based descriptors
Sequential and pattern‑based descriptors explicitly model the order and recurrence of musical events. N‑grams, motif mining, and grammar‑based approaches are common in this category. N‑grams extract contiguous subsequences of items (e.g., notes, intervals, chords) and are often paired with frequency counts, term frequency–inverse document frequency weighting, or probabilistic models like Markov chains (Alvarez et al., 2024; Hontanilla et al., 2011; WoŁkowicz et al., 2008). Motif mining identifies repeated subsequences, while grammar‑based methods infer hierarchical structures using formal grammars (Cruz‑Alcázar et al., 2003; Mondol and Brown, 2021). Compression‑based techniques, which rely on repetitive patterns, also fall within this category (Junior and Batista, 2012; Ruppin and Yeshurun, 2006). Recent tokenization schemes, such as REMI (Huang and Yang, 2020) and Compound Word (Hsiao et al., 2021), encode multiple musical aspects into single tokens, facilitating sequential modeling. These representations, whether as token sequences, frequency vectors, or grammar‑derived structures, are particularly effective for capturing temporal dependencies, melodic contours, and harmonic progressions. Yet, significant challenges persist: sparsity, particularly for high‑order ‑grams, inherently limits generalization and scalability; tokenization choices critically affect all symbolic sequential methods, trading off information capture and vocabulary size; the local focus of ‑grams struggles with music's long‑range dependencies, which computationally expensive and potentially ambiguous grammar induction addresses only partially; the rigidity to variations in exact ‑gram and motif matching hampers robustness against minor musical alterations; and high computational demands, especially for uxhaustive motif mining and complex grammar induction, restrict large‑scale applications. These factors necessitate careful design and often motivate hybrid approaches. Nevertheless, sequential and pattern‑based descriptors remain widely applied in classification, melody retrieval, music generation, and structural analysis.
6.1.3 Transformational and geometric representations
Transformational and geometric representations map symbolic music into alternative spaces where patterns may be more apparent or amenable to specific processing techniques. Examples include piano‑roll matrices, which represent pitch versus time as binary or valued grids (Velarde et al., 2016; Zhang et al., 2023); spectrogram‑like representations derived from symbolic data via synthesis and time‑frequency transforms (Velarde et al., 2018); geometric spaces like the Tonnetz, which map harmonic relationships onto a lattice (Karystinaios et al., 2020); and wavelet or time‑frequency transforms applied to musical parameters (Mirza et al., 2024). These formats are particularly suited for convolutional neural networks (CNNs), which can exploit spatial locality to identify structural patterns. While these representations can reveal holistic or multi‑scale patterns, they are often high‑dimensional. Parameterization, such as defining time/pitch resolution for piano‑rolls or selecting parameters for wavelet transforms (e.g., Velarde et al., 2016; Mirza et al., 2024), can be critical and extensive, shaping the core representation more significantly than the selection process for many statistical descriptors or the use of fixed pre‑trained learned representations. Regarding interpretability, while base forms like piano‑rolls or the Tonnetz lattice (e.g., Karystinaios et al., 2020) are conceptually intuitive, they are used in literature by deriving features or transformed representations for modeling, obscuring direct musical elements. They consequently offer less direct linkage to specific musical meaning compared to features from statistical or simple sequential approaches. They are primarily used for classification, segmentation, and visualization.
6.1.4 Graph‑based representations
Graph‑based representations conceptualize music as networks of interconnected entities, such as notes or chords, with edges encoding relationships like succession, simultaneity, or voice leading (Karystinaios et al., 2024; Zhang et al., 2023). Features can be derived from node or edge attributes, global graph statistics (e.g., centrality, clustering), or learned embeddings from graph NNs (GNNs). Some approaches extend this paradigm to model higher‑level structures, such as entire MIDI files and their components, as nodes in a graph (Lisena et al., 2022). Graph‑based representations excel at capturing complex, non‑local dependencies and structural properties, making them powerful for tasks requiring a nuanced understanding of musical relationships. However, designing graphs that meaningfully capture music's multi‑dimensional, concurrent, and often non‑linear relational structure—defining appropriate nodes, varied edge types, and attributes to form an explicit relational representation—is an intricate process, entailing a more multifaceted design of relational structures than defining linear token sequences or statistical aggregates. While GNNs can be parameter‑efficient (Zhang et al., 2023), their computational aspects, such as processing time for message passing over large or intricate musical graphs and the potential for extended convergence times (Zhang et al., 2023; Karystinaios et al., 2024), warrant careful consideration, especially as graph size and complexity scale.
6.1.5 Learned and latent representations
Learned and latent representations leverage deep learning models to automatically infer relevant features from raw or other primary symbolic representations. These representations correspond to activations of hidden or embedding layers within NNs—such as CNNs, recurrent NNs (RNNs), transformers, or autoencoders—trained on musical tasks, or arise from graph‑embedding techniques (Lisena et al., 2022; Karystinaios et al., 2024). While other methods produce intermediate results, these learned features are distinct as they are optimized by the model and designed to be reusable across diverse tasks. Crucially, such pre‑computed representations can potentially be adopted by other researchers for novel applications, potentially without the need for complete retraining from scratch. For example, MIDI2vec embeddings are used for predicting various metadata (Lisena et al., 2022), and perception‑inspired graph convolutions generate hidden representations applicable to multiple music understanding problems (Karystinaios et al., 2024). Learned representations are highly expressive and can capture subtle characteristics that elude manual feature engineering. However, they are generally opaque, require large datasets and computational resources, and their effectiveness depends on the quality and diversity of training data.
6.2 Source file formats
The aforementioned representations are derived from various digital symbolic music file formats. The choice of format can influence the type and richness of information available for feature extraction or representation learning.
Standard MIDI File (SMF): Widely adopted due to its simplicity and broad software support. It primarily encodes performance‑oriented data like pitch, duration (as onset and offset or duration), and velocity. While excellent for capturing basic note events, it often lacks detailed notational information like precise beaming, enharmonics, or high‑level structural annotations, which can be crucial for some stylistic analyses. Examples of studies that use SMF are Chan and Potter (2006), Costantini et al. (2006), Cumming et al. (2018), Hajj et al. (2018), and Simonetta et al. (2023).
**kern: This is effective for representing polyphony in Western classical music and can encode a wide range of musicological details. It is relatively human‑ readable but can be complex to create manually. Examples of works using **kern format include Alvarez et al. (2024), Brinkman et al. (2016), Hillewaere et al. (2010), and Simonetta et al. (2023).
MusicXML: A de facto standard for exchanging modern music notations between different softwares. It is more comprehensive than MIDI, capable of representing detailed notational elements like slurs, dynamics, and articulations. However, its verbosity can be a challenge, and it primarily focuses on common Western music notation. Examples of articles that used MusicXML are Doerfler and Beck (2013) and Simonetta et al. (2023).
Other formats like ABC notation and Guido Music Notation also exist, often prioritizing human readability or specific notational capabilities, but are less frequently encountered as primary sources in the surveyed articles. A major effort is being undertaken by the Music Encoding Initiative (MEI), an XML framework designed for encoding a wide variety of music notations with rich metadata, including editorial and critical annotations, with a special focus on scholarly applications.
Interestingly, studies by Simonetta et al. (2023) and Zhang et al. (2023) have found that, for certain composer‑identification tasks, using highly informative file formats like MusicXML or MEI did not always yield significantly better results than using simpler formats like MIDI when using current feature‑extraction tools or neural representation methods. This may indicate that existing tools and models do not yet fully exploit the rich semantic information these formats provide. Traditional feature extraction often relies on aspects readily available or derivable from MIDI‑like data, and many neural models are designed to learn features from more fundamental representations. This suggests an opportunity for future research to develop methods that can more effectively leverage the detailed musicological information captured in comprehensive encoding formats for improved stylistic analysis.
7 Model Architectures
The task of composer identification has been approached with various models, each leveraging different strengths in statistical learning. This section categorizes these models based on their underlying architecture and discusses their suitability for different types of feature representations, as detailed in Section 6. Figure 9 shows the distribution of papers employing each approach.
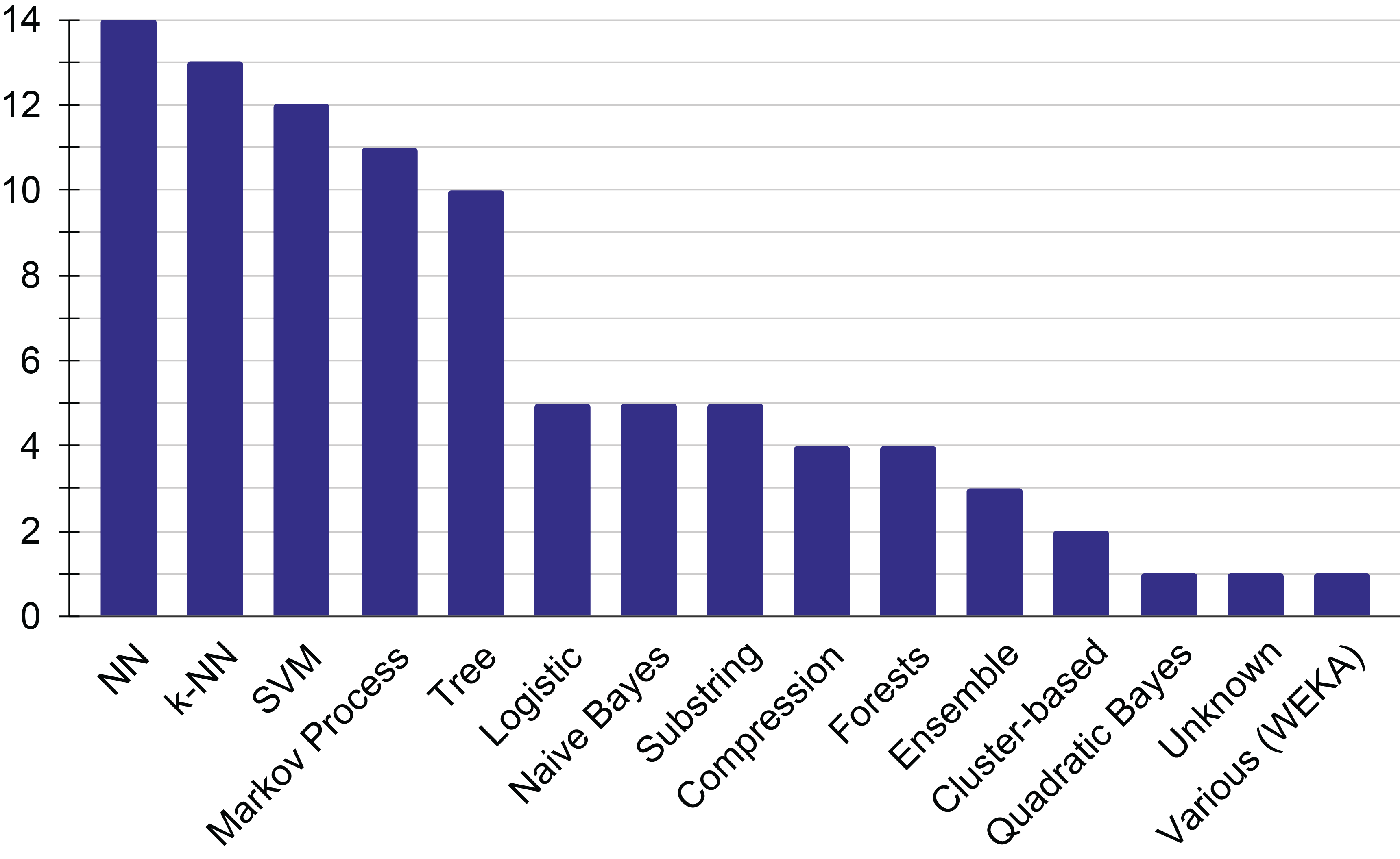
Figure 9
Visualization of the number of papers for each approach.
To create these statistics, base classes of approaches were identified, and each recorded experiment was associated with a specific class. For instance, decision trees fall into the class of ‘Trees,’ random forests into the class of ‘Forests,’ and the same applies to CNNs, transformers, and feed‑forward NNs, all classified as ‘NN’. Similarly, ‘Markov Processes’ are used for any methodology that leverages the theory of Markov processes, including hidden Markov models and simple Markov chains.
7.1 ‑NN
‑NN is a frequently used, simple approach in music classification. These models operate directly on feature vectors, where each dimension represents a specific musical characteristic. The representation space can be formed using statistically‑derived descriptors (e.g., Backer and van Kranenburg, 2005; Brinkman et al., 2016), transformational and geometric representations like piano‑roll (Velarde et al., 2018) and Tonnentz (Karystinaios et al., 2020), and ad‑hoc bit‑level representations suitable for compression‑based distances (Takamoto et al., 2016), which relate to sequential and pattern‑based descriptors (Hajj et al., 2018; Ruppin and Yeshurun, 2006). The drawbacks of ‑NN are its poor interpretability and its increasing computational cost with larger training sets.
7.2 NNs
NNs encompass a broad range of architectures, each suited to different input representations:
Feed‑forward NNs (Johnson, 1993; Hörnel and Menzel, 1998; Machado et al., 2004; Costantini et al., 2006; Kaliakatsos‑Papakostas et al., 2010; Marques and Reis, 2013; Tan et al., 2019; Lisena et al., 2022; Sadeghian et al., 2017): These typically take fixed‑size feature vectors as input, making them compatible with statistically‑derived descriptors.
CNNs (Verma and Thickstun, 2019; Zhang et al., 2023; Velarde et al., 2018): CNNs are often applied to matrix‑based representations like piano rolls, aligning with transformational and geometric representations. They can learn hierarchical patterns across time and pitch.
RNNs and transformer models (Chou et al., 2021; Zhang et al., 2023): These are well‑suited for sequence‑based representations, such as streams of musical events (e.g., notes, rests, tokens representing pitch and duration). Transformers are one of the most‑used architecture typologies in modern NN, but they suffer from memory limitations when processing long sequences and generally require large datasets to train effectively.
GNNs (Zhang et al., 2023; Karystinaios et al., 2024): GNNs operate on graph structures representing relationships between musical elements, directly leveraging graph‑based representations.
Other variants like fuzzy NNs (Sadeghian et al., 2017) and cortical algorithms (Hajj et al., 2018) also exist. Compared to trends in machine learning, where NNs are increasingly prevalent, their application in composer identification remains relatively less explored, potentially due to the limited size of curated datasets.
7.3 Markov processes
Markov processes are based on the assumption that music is a Markov process, where the probability of a musical symbol depends solely on the preceding one. This approach aligns with sequential and pattern‑based descriptors. The musical symbol can vary but often includes discrete elements like pitches, intervals, durations, or combinations thereof. This category includes Markov chains (Kaliakatsos‑Papakostas et al., 2011; Nakamura and Takaki, 2015; Neto and Pereira, 2017), ‑grams (Cruz‑Alcázar et al., 2003; WoŁkowicz et al., 2008; Hillewaere et al., 2010; Hontanilla et al., 2011, 2013; Wołkowicz and Kešelj, 2013; Hedges et al., 2014; Alvarez et al., 2024; Ruppin and Yeshurun, 2006; Shan et al., 2002), and hidden Markov models (Pollastri and Simoncelli, 2001). Markov models often struggle with representing music polyphony. Methods dealing with polyphonic music range from considering only the highest part, simplifying it and automatically extracting the melody (Simonetta et al., 2019), to concatenating the various parts sequentially and modeling each part with a different model. As shown in Figure 10, the use of Markov processes has declined in recent times, likely being replaced by NNs with long short‑term memory or attention methods (Chou et al., 2021; Zhang et al., 2023).

Figure 10
The moving average on a window of five years of the number of papers per approach, for the five most common approaches.
7.4 SVMs
SVMs apply a non‑linear transformation to the data, seeking a space where the data are linearly separable. SVMs typically operate on feature vectors derived from various musical aspects, such as statistical summaries of melody, harmony, and rhythm, often extracted using tools discussed in Section 6. Thus, they are well suited for statistically‑derived descriptors. SVMs have been used both in comparison to other methods (Costantini et al., 2006; Hillewaere et al., 2010; Herremans et al., 2015; Hajj et al., 2018; Velarde et al., 2018; Herlands et al., 2014; Brinkman et al., 2016; Chan and Potter, 2006; Naccache et al., 2009) and as a sole choice (Velarde et al., 2016; McKay et al., 2018; Alvarez et al., 2024; Gelbukh et al., 2024).
7.5 Decision trees and random forests
Ten works used decision trees—including RIPPER— primarily as an option to interpret the model decision (Chan and Potter, 2006; Costantini et al., 2006; Naccache et al., 2009; Mearns et al., 2010; Cuthbert et al., 2011; Marques and Reis, 2013; Herlands et al., 2014; Herremans et al., 2015, 2016; Costa and Coca, 2018; Dor and Reich, 2011). These also operate on feature vectors, making them suitable for statistically‑derived descriptors. Their use is controversial, as they rarely achieve high accuracies but are a good choice for interpretability. Random forests, an ensemble of decision trees, provide a more effective framework that is more commonly used in machine learning, albeit with decreased model interpretability, and have been adopted by only three works in the context of composer identification (Herlands et al., 2014; Tan et al., 2019; Karystinaios et al., 2020).
7.6 Other methods
Other methods found in the literature include naive Bayes, mainly adopted as a baseline (Chan and Potter, 2006; Costantini et al., 2006; Naccache et al., 2009; Mearns et al., 2010; Herlands et al., 2014; Dor and Reich, 2011), which also uses feature vectors; compression‑based distances used for clustering or ‑NN (Ruppin and Yeshurun, 2006; Junior and Batista, 2012; Takamoto et al., 2016; Mondol and Brown, 2021), which operate on sequential representations; quadratic Bayes (Backer and van Kranenburg, 2005); and ad‑hoc clustering (Doerfler and Beck, 2013). Substring matching was adopted by four works, operating on sequences of musical symbols (Hedges et al., 2014; Shan et al., 2002; Westhead and Smaill, 1994; Takamoto et al., 2024). This method is based on the classification of a test sequence with the label whose training set has the highest number of sub‑sequences shared with the test instance. Some authors utilized the WEKA framework to compare a variety of methods (Dor and Reich, 2011; Simonetta et al., 2023), while, more recently, AutoML methods have been successfully used with surprising efficacy (Simonetta et al., 2023).
The methods analyzed in the literature were not used homogeneously across time, but followed trends of the general machine learning field. Figure 10 shows the trend of the five most common approaches.
8 Authorship Attribution Problems
Only three cases of unknown or questionable authorship have been approached with composer identification models. The first case involves a set of keyboard fugues originally attributed to Johann Sebastian Bach but then recently re‑attributed to Krebs, supported by various statistical analyses (van Kranenburg and Backer, 2005; van Kranenburg, 2008; Hontanilla et al., 2011). The second case pertains to more than 200 works of questionable attribution by Josquin des Prez (Brinkman et al., 2016; McKay et al., 2018; Verma and Thickstun, 2019). Finally, the third case concerns eight songs (or portions of songs) with disputed attribution to John Lennon and Paul McCartney (Glickman et al., 2019). A synthesis of the existing authorship attribution problems is shown in Table 3.
Table 3
Summary of music authorship attribution problems in the analyzed literature.
| Disputed attribution | Bach | Josquin des Prez | Lennon–McCartney |
|---|---|---|---|
| Originating work | van Kranenburg and Backer (2005) | Brinkman et al. (2016) | Glickman et al. (2019) |
| Number of papers | 3 | 3 | 1 |
| Best accuracy | >90% (van Kranenburg, 2008) | 91% (McKay et al., 2018) | 76% (Glickman et al., 2019) |
| Evaluation class | Good | Questionable | Questionable |
| Data integrity | Closed set, reliance on CCARH collection, no investigation on editorial choices | Closed set, reliance on JRP collection, weak transcription protocol | Closed set, manual transcription based on previous editions, no investigation on editorial choices |
In the Bach fugue problem, the initial work (van Kranenburg and Backer, 2005) identified a set of possible alternative authors based on historical observations and musicological considerations, thus restricting the inference problem to three authors: Johann Sebastian Bach, Wilhelm Friedemann Bach, and Johann Ludwig Krebs. The authors collected music scores from the CCARH collection (Sapp, 2005). The same authors later included Johann Peter Kellner as an option in a more extended analysis (van Kranenburg, 2008). Other researchers approached the problem in the second formulation, obtaining similar results (Hontanilla et al., 2011). It should be noted that the full text of the latter work was not accessible, and the analysis was based on the conference slides made available by the authors and on a subsequent publication describing the same method in full detail but excluding the authorship attribution problem (Hontanilla et al., 2013). Upon examining the evaluation procedures of these three works, it was found that the first work did not adopt proper evaluation measures for the imbalanced dataset at hand, while the third work showed poor classification performance, thus undermining the reliability of the model. The second work (van Kranenburg and Backer, 2005), however, allowed for proper evaluations based on the confusion matrix reported in the original publication, showing a balanced accuracy greater than 90% in a leave‑one‑out evaluation procedure. Therefore, it is suggested that this latter work (van Kranenburg, 2008) contains the most definitive evaluation up to now. Regarding the construction of the dataset, not much attention was paid by the authors on the elimination of potential confounding factors stemming from editorial choices in the CCARH collection. The authors acknowledged the limits of the closed set formulation, stating ‘the possibility that a composer not represented in the dataset wrote the piece should be kept open’ (van Kranenburg, 2008).
Regarding the case of Josquin's works, the originating publication (Brinkman et al., 2016) did not perform careful musicological research to restrict the set of possible authors. Instead, reliance was placed on a musicologically curated dataset containing various well‑known Renaissance composers collected by the Joquin Research Project (JRP).1 This approach enabled the automatic attribution of labels to more than 200 questionable works. While this method is more suitable for large‑scale problems, it lacks the reliability of a meticulous musicological analysis that narrows the possible attribution labels. Observing the evaluation procedure, the originating work employed a single hold‑out strategy, resulting in a balanced accuracy of 50%. A subsequent study (McKay et al., 2018) adopted a 10‑fold cross‑validation procedure and evaluated the ‑measure, which partially accounts for dataset imbalance. This study achieved 91% and 82% accuracy for two different two‑classes problems (Josquin vs. Ockeghem and Josquin vs. La Rue, respectively). Additionally, the average balanced accuracy of a 10‑fold cross‑validation performed on the six classes was computed by Verma and Thickstun, yielding a value of 77% (Verma and Thickstun, 2019). Overall, recent improvements allow for a more rigorous approach to the problem, but the attribution of suspicious Josquin works remains an open challenge. Even in this case, the authors rely on a weak process for data collection, with only one musicologist responsible for the transcription—thus, no external review was performed—and with no musicological variants encoded. From the information available in the JRP documentation, it is not clear how dubious passages have been transcribed and encoded and how potential biases from the transcriber (e.g., systematic interpretation or error patterns) have been mitigated. However, McKay et al. (2018) placed particular attention on the automatic handling of confounding factors deriving from encoding choices, which can partly mitigate the problem.
In the case of the disputed attribution of Lennon–McCartney song portions, the originating work by Glickman et al. (2019) approached the problem by analyzing symbolic representations. Specifically, they used published music score editions of 70 songs by The Beatles as their primary source material. From these symbolic scores, they manually extracted a set of hand‑crafted features designed to capture compositional style, distinct from performance or recording artifacts. These features were then used to train a logistic linear regression model with both and regularization factors. The model's performance was evaluated using standard accuracy in a leave‑one‑out validation scheme, achieving 76% correct predictions for disputed song excerpts. This study is notable as one of the few prominent computational authorship attribution investigations in popular music that operates on symbolic data, employing a methodology of feature extraction from scores comparable to approaches used for classical music. However, the result indicates that the re‑attribution of these song excerpts remains an open challenge. The authors, interested in establishing ‘the stylistic fingerprint of a songwriter based solely on a corpus of songs' musical content,’ based their training on existing published collections. The study did not delve into a detailed investigation of potential editorial choices within these music transcriptions, which can be a complex factor for popular music that often has a strong oral tradition alongside published forms. Future work could enhance the validation and feature extraction using more recent tools and methodologies.
9 Takeaways for Future Research in Composer Identification
This section summarizes the major findings of the research that may be useful to the MIR community for further investigations in the analysis of musical styles and especially for improving composer identification models.
9.1 Number of classes
While reducing the number of classes or merging stylistically similar ones can artificially boost accuracy, such modifications must be approached with caution, as they can alter the fundamental research question. For instance, in the study by Brinkman et al. (2016), changing class definitions would shift the inquiry from ‘who is the author of these works?’ to ‘is Josquin the author of these works?.’ Ultimately, adherence to the robust evaluation protocols detailed in Section 4 is key to obtaining reliable numerical results whose susceptibility to variations in the number of classes is minimized.
9.2 Historical period length
The interpretation of dataset period length must consider the research goal. For some benchmarking purposes, a wide historical period might be intentionally chosen to test a model's ability to distinguish very disparate styles, potentially making the task easier if the number of classes is small and the stylistic differences are gross. However, for musicological authorship attribution, particularly when attempting to distinguish between contemporaneous composers or those from a similar school, a narrow historical focus is crucial. Using a wide historical span in an attribution context risks the model learning period–specific or broad genre‑specific cues rather than the nuanced, individual stylistic traits of a composer. Thus, while an experiment using a wide period might be valid for its stated benchmarking goal, its resulting model may have limited utility or generalizability for fine‑grained attribution tasks.
9.3 Number of instances
The dataset should be balanced in terms of the number of instances per class. Imbalances, especially in large datasets, can negatively impact the evaluation stage, particularly for less reliable classes. Moreover, the number of instances should be a trade‑off between a large number for improving the generalization ability of the model and a small number to allow curated data collection, which is often costly and time‑consuming. Developing models using not well‑curated data can generate inaccurate systems that are hardly usable in different datasets.
9.4 Problem formulation
In the analyzed literature, composer‑identification experiments were carried out among a finite set of composers. This is the ‘closed set’ formulation of the authorship attribution problem as defined by Juola (2007). However, a more appropriate choice of model architecture and data analysis could pave the way for the ‘open set’ formulation, where an additional class ‘other’ is added. The use of a residual class allows researchers to check for the validity of the possible attributions included in the dataset. The construction of the residual class is challenging and is likely the reason why the literature has not adopted this approach. However, Bayesian machine learning offers a different perspective that is useful to the ‘open set’ formulation.
In the typical frequentist formulation, the model predicts a point‑estimate of the possible composer, while, in the Bayesian formulation, the model predicts a probability distribution over the possible composers. This distribution can be used to compute the probability of the ‘other’ class, which is the probability that the model is uncertain about the attribution. While an uncertainty measure can also be computed from frequentist models, the Bayesian approach offers the opportunity to disentangle aleatory and epistemic uncertainty (Depeweg et al., 2017; Valdenegro‑Toro and Mori, 2022). Epistemic uncertainty is tied to the data seen during training, while aleatory probability is connected with some intrinsic error in the data, due to, for instance, the transcriber errors, the feature extraction, or the encoding system. In an authorship attribution case, having a large epistemic uncertainty for a certain musical work means that the work is not represented in the train set. This is a clear indication that the model is not able to predict the authorship of the work given the information encoded in the dataset. Thus, a large epistemic uncertainty means that the music style of the input music is different from any composer, as represented in the dataset.
In the context of MIR and the categorization of large databases, the ‘open set’ formulation could be particularly useful when the dataset is collected from different sources using automated scraping, consequently being subject to possible encoding incoherence and errors. In general, it allows testing the homogeneity of the train and test sets, thus allowing for further checks during the use of the model in real‑world applications.
9.5 Data collection
Data integrity has a fundamental role in the validity of the experiments. In the existing literature about authorship attribution cases, no author has paid adequate attention to the data‑collection protocol. The same happens in the more general context of composer identification when large datasets are collected for training models that are used on different data. Here, I reference Pugin (2015) and Sculley and Pasanek (2008) for a detailed description of a musicological approach to data collection, which can be summarized using the following recommendations:
Ensure data quality and transparency by continuous validation and correction by multiple independent experts while making underlying assumptions explicit.
Promote interoperability and standardization by using widely accepted and extensible standards, such as MIDI, MEI, and MusicXML, to ensure compatibility across different research domains and datasets (Ludovico et al., 2019).
Apply diverse methodologies and data representations to capture different aspects of complex problems, avoiding reliance on a single data model. This includes different file formats and multiple representations for distinguishing levels of editorial interventions.
Facilitate open access and reproducibility by making data and methods available whenever possible, ensuring that research can be independently verified and built upon.
9.6 Encoding formats
It is also possible to derive some insights by examining the encoding formats discussed in the literature. According to the author's experience, musicologists emphasize the comprehensive representation of all musical elements, including accidentals, editorial interpretations, variations, dynamics, and more. Consequently, the musicological approach often harbors skepticism toward formats perceived as overly simplistic, such as MIDI. While this skepticism may have some theoretical basis, the absence of technical tools to fully use the detailed information that musicologists value remains a significant barrier (Simonetta et al., 2023; Zhang et al., 2023). Excessive effort in gathering highly detailed data may be a misallocation of resources that could be better spent on eliminating potential confounding factors from editorial and encoding choices from the data as well as enlarging the size of the dataset.
9.7 Validation protocols
Regarding the validation protocols, many studies used a simple hold‑out scheme or inaccurate measures of merit. While measures solely based on precision and recall may be meaningful, they do not offer a comprehensive representation of the reliability of the model. Moreover, using a simple hold‑out split for validating the model, when combined with the typical data scarcity problem connected with curated musicological corpuses, likely leads to imprecise evaluation measures. As discussed in Section 4, it is recommended to use ‑fold validation with BA or (MCC) as measures of merit.
9.8 Pondering claims
In general, authors often overstate the effectiveness of their models, which can result in questionable attributions. For example, BWV 534 was initially credited to J.L. Krebs by van Kranenburg and Backer (2005), but this attribution was later reconsidered and withdrawn by the same researchers (van Kranenburg, 2008).
A claim too optimistic may influence the future research in the field, leading to a waste of resources and time. It is important to be cautious in the interpretation of the results and to always consider the limitations of the model. In general, a musical work should be considered as re‑attributed only after multiple meticulous studies using different data collections, classes, and tests.
It must be kept in mind that the accuracy measure is not the sole aspect of the evaluation, where data integrity, experimental protocol, and research question play a fundamental role. It is the opinion of the author that computational methods alone cannot suffice for authorship attribution problems. Their predictions must be carefully interpreted and guided by domain experts.
It is worth mentioning that the repertoire studied by the literature is extremely focused on the famous German composers (Bach, Mozart, Haydn, Beethoven). Little has been reported about other composers, thus limiting the understanding of the full potential of automated composer identification for authorship attribution problems.
10 Conclusions
This systematic review has meticulously surveyed the landscape of composer identification and authorship attribution from symbolic music scores, drawing critical insights from 58 peer‑reviewed studies spanning decades of computational musicology. My analysis underscores a pivotal challenge: while technological advancements have introduced sophisticated machine learning models, the reliability and musicological validity of attribution claims often remain compromised by inconsistent evaluation practices and inherent dataset limitations.
Key findings highlight the critical importance of robust evaluation metrics, particularly BA and MCC, over traditional accuracy, especially when dealing with imbalanced datasets common in this domain. I identify a pervasive reliance on simple hold‑out validation and a concentration on a limited repertoire of Western classical composers, often overlooking crucial aspects of data integrity and musicological curation. The case studies on Bach, Josquin des Prez, and Lennon–McCartney illustrate the complex interplay between computational predictions and musicological interpretation, revealing that even high classification scores do not automatically translate to definitive authorship.
To address these gaps, this work proposes a comprehensive set of guidelines for future research. These recommendations emphasize the necessity of transparent, musicologically informed data‑collection protocols, the adoption of rigorous cross‑validation strategies, and the judicious interpretation of model outputs, ideally within a Bayesian framework to quantify uncertainty. Ultimately, while computational methods offer powerful tools for stylistic analysis, their true potential for authorship attribution can only be realized through interdisciplinary collaboration and a cautious, evidence‑based approach that integrates machine learning insights with deep musicological expertise.
Acknowledgments
I am indebted to the anonymous reviewers for their exceptionally thorough and insightful critiques. Their guidance was instrumental in reshaping this work, and the manuscript has been substantially strengthened as a direct result of their generous contribution of time and expertise.
Funding Statement
This work has been funded by the European Union (Horizon Programme for Research and Innovation 2021–2027, ERC Advanced Grant ‘The Italian Lauda: Disseminating Poetry and Concepts Through Melody (12th–16th century),’ acronym LAUDARE, project no. 101054750). The views and opinions expressed are, however, only those of the author and do not necessarily reflect those of the European Union or the European Research Council. Neither the European Union nor the awarding authority can be held responsible for such matters.

Competing Interests
The author has no competing interests to declare.
Note
Additional Files
The additional files for this article can be found using the links below:
Supplementary File 1
Symbolic Composer Classification Survey – Datasets. DOI: https://doi.org/10.5334/tismir.240.s1.
Supplementary File 2
Symbolic Composer Classification Survey – Works. DOI: https://doi.org/10.5334/tismir.240.s2.
Supplementary File 3
Symbolic Composer Classification Survey. DOI: https://doi.org/10.5334/tismir.240.s3.