
(1) Overview
Introduction
Stochastic models are crucial in the analysis of commodity futures, serving important roles in various financial areas such as price forecasting, risk management, and portfolio optimisation. Typically, the underlying spot price, denoted as St, is modelled as a function of certain factors. In 1990, the Ornstein-Uhlenbeck (OU) process was introduced to model oil futures in a two-factor setup, representing spot price and convenience yield [12]. Building on this foundation, Schwartz and Smith [22] modelled the logarithm of the underlying spot price of crude oil futures as the sum of two latent factors. These factors, assumed to follow the OU process, capture short-term fluctuations and the long-term equilibrium price level, respectively. This latent factor model and its extensions have been widely used in stochastic modelling in various fields, including biology [8], electricity forwards [17], agricultural commodity futures [23], and crude oil futures [1621].
In this framework, the positivity of the futures price is ensured via an exponential transformation. However, in some markets, prices can become negative. For instance, in 2019, the natural gas price in the Permian Basin, West Texas, turned negative several times. On 20 April 2020, the front-month May 2020 WTI crude oil futures settled at –$37.63 per barrel on the New York Mercantile Exchange, see, e.g., [9]. Negative prices occur even more frequently in the electricity market. In 2009, the province of Ontario, Canada, recorded 280 hours of negative electricity prices. In 2017, German electricity prices turned negative over 100 times. Between early 2018 and late 2020, electricity prices in Texas, USA, were negative for nearly 19% of total hours. Such cases illustrate that the previously mentioned framework is not applicable to these markets.
The polynomial diffusion model relaxes this assumption. In this framework, the spot price is represented as a polynomial of any order in terms of the factors. In particular, under certain conditions, it can be proven that the conditional expectation of the spot price, which is equivalent to the futures price under the assumption of an arbitrage-free market and non-stochastic interest rate, is also a polynomial in terms of factors. The mathematical foundations of the polynomial diffusion model were introduced in [10], with applications of this framework seen in the modelling of electricity forwards, where the spot price is represented by a quadratic form of two factors [18].
In this paper, we introduce the R package PDSim, which is specifically designed to simulate futures prices and estimate latent factors using the polynomial diffusion model. PDSim consists of two components: the core package and a Shiny application of the same name. The core package provides exported functions for simulation as well as for linear and non-linear filtering. It is intended for users who wish to simulate data or fit real-world data. The Shiny app, by contrast, is designed exclusively for simulating data through a graphical user interface (GUI) and for visualising the results in a straightforward manner. This app has also been deployed on a Shiny server, allowing users to access it without requiring any local installation. This separation reflects the computational demands of parameter estimation when working with real-world data. Given the high dimensionality of the parameter space, estimation is computationally expensive, making R scripts a more suitable choice than a web-based interface in such cases.
In this paper, we provide a guide for using the GUI to simulate data and examples of how to use R scripts to both simulate and fit real-world data. The primary focus of PDSim is on simulation and joint estimation of state variables and model parameters, enabling users to explore the properties of the polynomial diffusion model. For applications involving real-world data, we recommend combining PDSim with established optimisation algorithms to minimise the negative log-likelihood returned by the KF, EKF, or UKF functions.
I. Schwartz-Smith two-factor model
Under the Schwartz-Smith framework, the logarithm of spot price St is modelled as the sum of two factors χt and ξt,
where χt represents the short-term fluctuation and ξt is the long-term equilibrium price level. Additionally, we assume both χt and ξt follow a risk-neutral Ornstein-Uhlenbeck (OU) process,
and
where are the speed of mean-reversion parameters, μξ∈ℝ is the mean level of the long-term factor, are the volatility parameters, and are risk premiums. The processes and are correlated standard Brownian Motions with
In the original Schwartz-Smith model [22], γ = 0, and only the short-term factor χt follows an OU process. Since 2000, many studies such as [151921] and others considered the extended version of the Schwartz-Smith model by introducing γ ≥ 0. For simplicity, further, we continue to refer to this model with γ ≥ 0 as the Schwartz-Smith model. Setting in Equation 2 and Equation 3 gives the “real processes” of the factors under statistical measure. The risk-neutral processes are used to calculate futures prices, and the real processes are for modelling state variables in real time.
In discrete time, χt and ξt are jointly normally distributed. Therefore, the spot price is log-normally distributed. Moreover, under the arbitrage-free assumption and non-stochastic interest rate, the futures price Ft,T at current time t with maturity time T must be equal to the expected value of spot price at maturity time T,
where ℱt is the information known at time t and is the expectation under the risk-neutral processes from Equation 2 and Equation 3. Then we can get the linear Gaussian state space model:
where
and m is the number of futures contracts. The function A(⋅) is given by
where τ is the time to maturity; wt and vt are multivariate Gaussian noise sequences with mean 0 and covariance matrix Σw and Σv respectively, where
and we assume Σv is diagonal, i.e.,
Δt is the time step. Under this framework, and Σv are deterministic but dt and Ft are time-variant.
II. Polynomial diffusion model
In this section, we present a general framework of the polynomial diffusion model. A simulation study is given in [14].
Under the polynomial diffusion framework, the spot price St is expressed as a polynomial function of the latent state vector xt (with components χt and ξt):
In this context, we assume that the polynomial pn(xt) has a degree of 2 (or 1 if ). However, it is worth noting that all the theorems presented here are applicable even for polynomials of higher degrees. Additionally, similar to the Schwartz-Smith model, we assume that χt and ξt follow an Ornstein–Uhlenbeck process
for real processes and
for risk-neutral processes.
Now, consider any processes that follow the stochastic differential equation
where Wt is a d-dimensional standard Brownian Motion and map is continuous. Define . For maps and , suppose we have aij∈Pol2 and bi∈Pol1. 𝕊d is the set of all real symmetric d×d matrices and Poln is the set of all polynomials of degree at most n. Then the solution of the SDE is a polynomial diffusion. Moreover, we define the generator 𝒢 associated to the polynomial diffusion Xt as
for x∈ℝd and any C2 function f. ∇2 and ∇ denote the Hessian and Jacobian matrix of the function f(⋅), respectively, and Tr(⋅) denotes the trace of a matrix. Let N be the dimension of Poln, and be a function whose components form a basis of Poln. Then for any p∈Poln, there exists a unique vector such that
and is the coordinate representation of p(x). Moreover, there exists a unique matrix representation of the generator 𝒢, such that is the coordinate vector of 𝒢p. So we have
Theorem 1: Let p(x)∈Poln be a polynomial with coordinate representation , be a matrix representation of generator 𝒢, and Xt∈ℝd satisfies the SDE. Then for , we have
where ℱt represents all information available until time t.
Obviously, the latent state vector xt satisfies the SDE with
The basis
has a dimension N = 6. The coordinate representation is
By applying 𝒢 to each element of H(xt), we get the matrix representation
Then, by Theorem 1, the futures price Ft,T is given by
Therefore, we have the non-linear state-space model
III. Filtering methods
The Kalman Filter (KF) [13] is a commonly used filtering method in estimating latent state variables. However, KF can only deal with the linear Gaussian state model. To capture the non-linear dynamics in the polynomial diffusion model, we use Extended Kalman Filter (EKF) [15] and Unscented Kalman Filter (UKF) [1624]. Suppose we have a non-linear state-space model
The EKF linearises the state and measurement equations through the first-order Taylor series. To run KF, we replace Jf and Jh with E and Ft respectively, where Jf and Jh are the Jacobians of f(⋅) and h(⋅). In contrast, the UKF uses a set of carefully chosen points, called sigma points, to represent the true distributions of state variables. Then, these sigma points are propagated through the state equation. The flowcharts of EKF and UKF are given in Figures 1 and 2, where some notations are defined as follow:
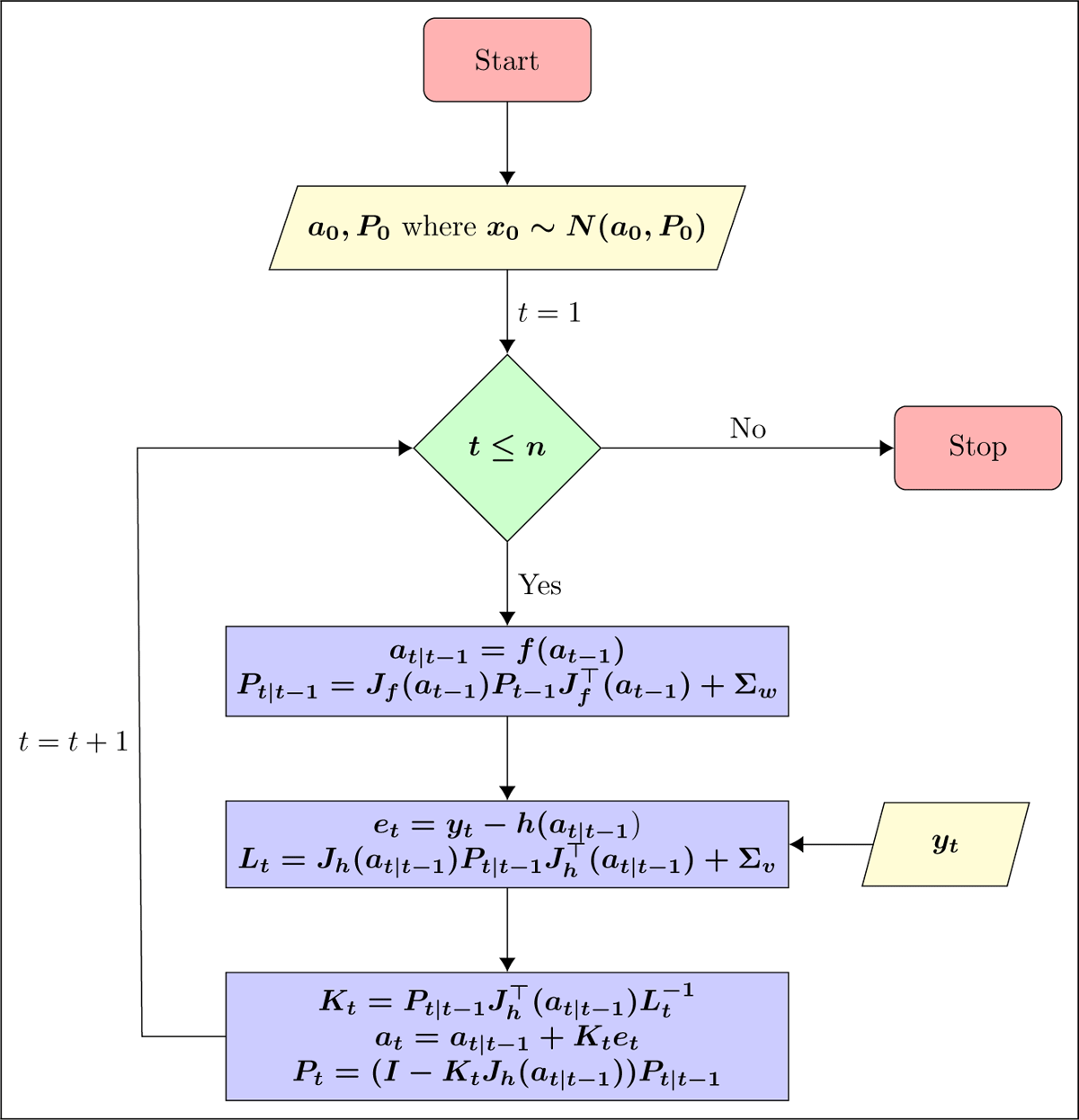
Figure 1
Flowchart of EKF.
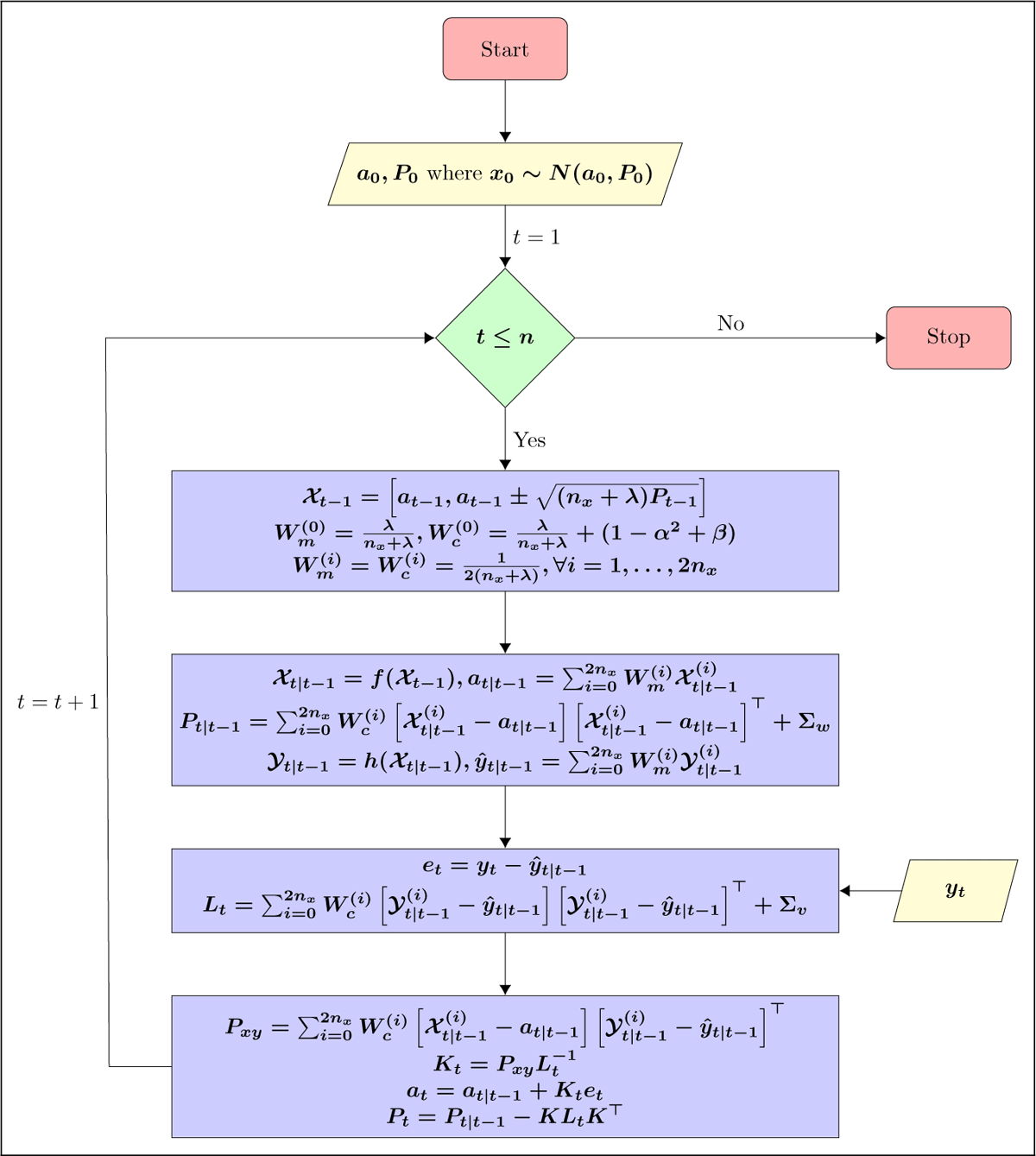
Figure 2
Flowchart of UKF.
In this application, we use KF for the Schwartz-Smith model, and EKF/UKF for the polynomial diffusion model.
IV. Comparison with existing libraries
The R package “NFCP” [2] was developed for multi-factor pricing of commodity futures, which is a generalisation of the Schwartz-Smith model. However, this package doesn’t accommodate the polynomial diffusion model. There are no R packages available for PD models currently.
There are many packages in R for Kalman Filter, for example, “dse”, “FKF”, “sspir”, “dlm”, “KFAS”: “dse” can only take time-invariant state and measurement transition matrices; “FKF” emphasizes computation speed but cannot run smoother; “sspir”, “dlm” and “KFAS” have no deterministic inputs in state and measurement equations. For the non-linear state-space model, the functions “ukf” and “ekf” in package “bssm” run the EKF and UKF respectively. However, this package was designed for Bayesian inference where a prior distribution of unknown parameters is required. To achieve the best collaboration of filters and models, we developed functions of KF, EKF and UKF within this code.
Implementation and architecture
The graphical user interface (GUI) provides an easy way for anyone to use the PDSim package, even without programming knowledge. Simply enter the necessary parameters, and PDSim will simulate the data and generate well-designed interactive visualisations. Currently, PDSim supports data simulation from two models: the Schwartz-Smith two-factor model [22] and the polynomial diffusion model [10]. In this section, we first provide the guide to simulate data using GUI and R script. Then, we give an application of fitting WTI crude oil futures data using PDSim.
I. Implementation of the Schwartz-Smith model
First, we establish some global configurations, as illustrated in Figure 3, including defining the number of observations (trading days) and contracts. Additionally, we select the model from which the simulated data will be generated.
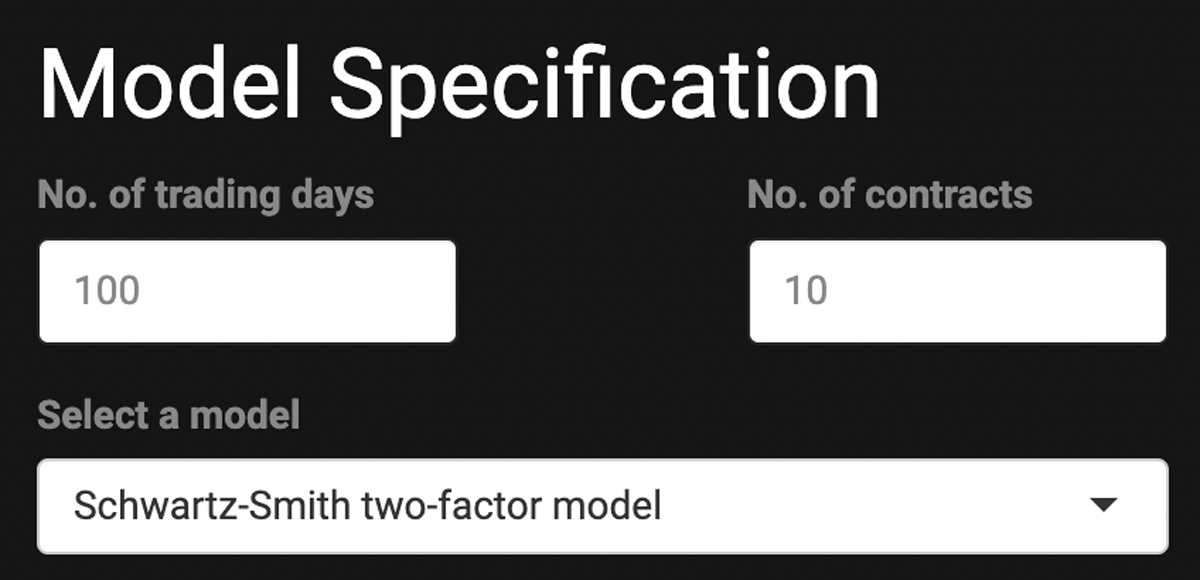
Figure 3
Establish global configurations.
For the Schwartz-Smith model, we assume that the logarithm of the spot price St is the sum of two latent factors:
where χt represents the short term fluctuation and ξt is the long term equilibrium price level. Both χt and ξt are assumed to follow a risk-neutral mean-reverting process:
Here, are the speed of mean-reversion parameters, controlling how quickly these two latent factors converge to their mean levels. Most experiments suggest that κ and γ fall within the range (0,3]. To avoid issues with parameter identification, we recommend setting κ greater than γ, meaning the short-term fluctuation factor converges faster than the long-term factor. The parameter μξ∈ℝ represents the mean level of the long-term factor ξt, and we assume the short-term factor converges to zero. The parameters are volatilities, representing the degree of variation in the price series over time. The parameters represent risk premiums. While we price commodities under the arbitrage-free assumption, in reality, mean term corrections, represented by λχ and λξ, are necessary. and are correlated standard Brownian Motions with a correlation coefficient ρ. In discrete time, these processes are discretised to Gaussian noises, and all parameters are to be specified. Additionally, for simplicity, we assume that the standard errors for futures contracts are evenly spaced, i.e., . All required parameters are shown in Figure 4.

Figure 4
Specify model parameters (Schwartz-Smith model).
Finally, all the simulated data can be downloaded. Click the “Download prices” and “Download maturities” buttons to download the data for the futures prices and maturities, respectively. Note that although the Schwartz-Smith model specifies the logarithm of the spot price, all downloaded or plotted data are in real prices – they have been exponentiated. The “Generate new data” button allows users to simulate multiple realisations from the same set of parameters. Clicking on it will generate another set of random noises, resulting in different futures prices. This button is optional if users only need one realisation. Any change in parameters triggers an automatic data update. These three buttons are shown in Figure 5.
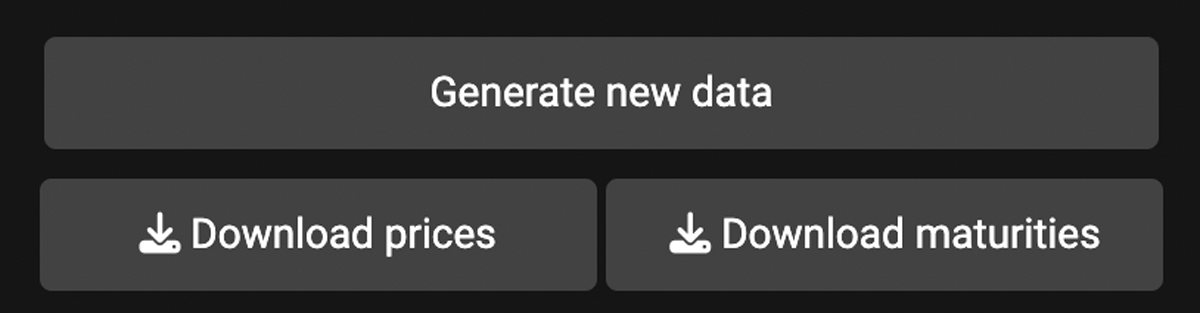
Figure 5
Download simulated data.
II. Implementation of the polynomial diffusion model
The procedure for data simulation from the polynomial diffusion model closely mirrors that of the Schwartz-Smith model, but it requires the specification of additional parameters.
Both the polynomial diffusion model and the Schwartz-Smith model assume that the spot price St is the function of two latent factors, χt and ξt. However, while the Schwartz-Smith model assumes that the logarithm of St is the sum of these two factors, the polynomial diffusion model assumes that St takes on a polynomial form. Currently, the PDSim GUI supports polynomials of degree 2, which can be expressed as:
The coefficients are additional parameters specific to the polynomial diffusion model. If users wish to specify a polynomial of degree 1, they can simply set . Users are also required to choose one of the non-linear filtering methods: the Extended Kalman Filter (EKF) or the Unscented Kalman Filter (UKF). All other procedures for data simulation follow the same steps as those in the Schwartz-Smith model. Additional parameters of the polynomial diffusion model are shown in Figure 6.
Figure 6
Specify model parameters (polynomial diffusion model).
III. Implementation of the models using R script
The Shiny application simplifies the simulation and estimation procedures. However, if users require greater control over the simulated data, the R script can be used. This section demonstrates how to use scripts to simulate data through the polynomial diffusion model and estimate the latent state variables.
First, load PDSim and specify the global settings:
n_obs <- 100 # number of observations n_contract <- 10 # number of contracts dt <- 1/360 # interval between two consecutive time points, # where 1/360 represents daily data
Next, specify the parameters and model coefficients:
# set of parameters par <- c(0.5, 0.3, 1, 1.5, 1.3, -0.3, 0.5, 0.3, seq(from = 0.1, to = 0.01, length.out = n_contract)) x0 <- c(0, 1/0.3) # initial values of state variables n_coe <- 6 # number of model coefficient par_coe <- c(1, 1, 1, 1, 1, 1) # model coefficients
Currently, PDSim supports a polynomial of order 2, which corresponds to six model coefficients. The next step is to define the measurement and state equations. We recommend using “state_linear” and “measurement_polynomial” within the package for a linear state equation and a polynomial measurement equation, respectively. However, users may also define their own functions:
# state equation func_f <- function(xt, par) state_linear(xt, par, dt) # measurement equationfunc_g <- function(xt, par, mats) measurement_polynomial(xt, par, mats, 2, n_coe)
Finally, simulate the data:
dat <- simulate_data(c(par, par_coe), x0, n_obs, n_contract, func_f, func_g, n_coe, ”Gaussian”, 1234) price <- dat$yt # simulated futures price mats <- dat$mats # time to maturity xt <- dat$xt # state variables
The latent state variables can then be estimated using either EKF or UKF:
est_EKF <- EKF(c(par, par_coe, x0), price, mats, func_f, func_g, dt, n_coe, “Gaussian”) est_UKF <- UKF(c(par, par_coe, x0), price, mats, func_f, func_g, dt, n_coe, “Gaussian”)
IV. Application to WTI crude oil futures data
We now demonstrate the implementation of PDSim on real-world data. Specifically, we use weekly WTI crude oil futures prices from 2 January 1990 to 14 February 1995, which is the exact same dataset used in [22]. This dataset is available in the R package “NFCP”.
For this implementation, we use the following code:
library(PDSim) library(NFCP) data(SS_oil) contracts <- SS_oil$stitched_futures n_obs <- dim(contracts)[1] n_contract <- dim(contracts)[2] maturities <- matrix(rep(SS_oil$stitched_TTM, n_obs), nrow = n_obs, byrow = TRUE) dt <- SS_oil$dt
################################ ##### Schwartz Smith model ##### ################################
#state equation func_f <- function(xt, par) state_linear(xt, par, dt) # measurement equation func_g <- function(xt, par, mats) measurement_linear(xt, par, mats)
# initial guesses par0 <- c(1.5, 1.3, 2, 1.5, 1.5, 0.5, 1, 1, rep(0.1, n_contract)) x0 <- c(0, 0)
# negative log-likelihood nll <- function(par) KF(par = par, yt = as.matrix(log(contracts)), mats = maturities, delivery_time = 0, dt = dt, smoothing = FALSE, seasonality = “None”)$nll
# bounds lb <- c(1e-04, 1e-04, -5, 1e-04, 1e-04, -0.9999, -5, -5, rep(1e-04, n_contract), -5, -5) # lower bound sub <- c( 3, 3, 5, 3, 3, 0.9999, 5, 5, rep( 1, n_contract), 5, 5) # upper bounds
# parameter estimation result_SS <- optim(par = c(par0, x0), fn = nll, method = ”L-BFGS-B”, lower = lb, upper = ub)
# estimated futures contracts est_SS <- KF(par = result_SS$par, yt = as.matrix(log(contracts)), mats = maturities, delivery_time = 0, dt = dt, smoothing = FALSE, seasonality = “None”) yt_hat_SS <- data.frame(exp(func_g(t(est_SS$xt_filter), result_SS$par, maturities)$y))
# mean absolute error of SS model mae_SS <- colMeans(abs(log(contracts) - log(yt_hat_SS)))
###################################### ##### Polynomial diffusion model ##### ###################################### n_coe <- 6
# state equation func_f <- function(xt, par) state_linear(xt, par, dt) # measurement equation func_g <- function(xt, par, mats) measurement_polynomial(xt, par, mats, 2, n_coe)
# initial guesses par0 <- c(1.5, 0.3, 0, 1.5, 1.5, 0, 0.5, 0.5, rep(0.1, n_contract)) par_coe0 <- c(1, 1, 1, 1, 1, 1) x0 <- c(0, 0)
# negative log–likelihood nll_EKF <- function(par) EKF(par = par, yt = as.matrix(contracts), mats = maturities, func_f = func_f, func_g = func_g, dt = dt, n_coe = n_coe, noise = "Gaussian")$nll
# bounds lb <- c(1e–04, 1e–04, –5, 1e–04, 1e–04, –0.9999, –5, –5, rep(1e–04, n_contract), rep(–5, n_coe), –5, –5) # lower bounds ub <- c( 3, 3, 5, 3, 3, 0.9999, 5, 5, rep( 1, n_contract), rep( 5, n_coe), 5, 5) # upper bounds
# parameter estimation result_PD_EKF <- optim(par = c(par0, par_coe0, x0), fn = nll_EKF, method = ”L–BFGS–B”, lower = lb, upper = ub, control = list(maxit = 10000))
# estimated futures contracts est_EKF <- EKF(result_PD_EKF$par, as.matrix(contracts), maturities, func_f, func_g, dt, n_coe, ”Gaussian”) yt_hat_EKF <- data.frame(func_g(t(est_EKF$xt_filter), result_PD_EKF$par, maturities)$y)
# mean absolute error of PD model mae_EKF <- colMeans(abs(log(contracts) – log(yt_hat_EKF)))
Table 1 reports the mean absolute errors (MAEs) of the logarithm of futures prices estimated using both the Schwartz–Smith (SS) model and the polynomial diffusion (PD) model. For comparison, we also include the results from Schwartz and Smith’s original paper [22]. The MAEs obtained using PDSim for the SS model are comparable to those reported in the original study.
Table 1
Estimation mean absolute errors of the logarithm of futures prices with different maturities.
| Maturity | SS paper | PDSim – SS MODEL | PDSim – PD MODEL |
|---|---|---|---|
| 1 month | 0.0314 | 0.0268 | 0.0519 |
| 5 months | 0.0035 | 0.0005 | 0.0279 |
| 9 months | 0.0020 | 0.0030 | 0.0290 |
| 13 months | 0.0000 | 0.0000 | 0.0338 |
| 17 months | 0.0028 | 0.0038 | 0.0410 |
The performance of the polynomial diffusion model varies across markets and time periods. In the earlier example (Table 1), the Schwartz–Smith model provides more accurate estimates than the polynomial diffusion model for all contracts. However, Table 2 presents another application of PDSim to WTI crude oil futures data for the period 2015–2018. In this case, the polynomial diffusion model outperforms the Schwartz–Smith model, achieving a mean RMSE of 0.1921.
Table 2
Root mean square errors (RMSE) for each futures contract using the polynomial diffusion (PD) model and the Schwartz-Smith (SS) model for the period from 2015 to 2018.
| CONTRACTS | PDSim – PD MODEL | PDSim – SS MODEL |
|---|---|---|
| Contract 1 | 1.1481 | 0.8884 |
| Contract 2 | 0.7283 | 0.5043 |
| Contract 3 | 0.4262 | 0.2460 |
| Contract 4 | 0.2522 | 0.1189 |
| Contract 5 | 0.1347 | 0.0614 |
| Contract 6 | 0.0516 | 0.0903 |
| Contract 7 | 0.0136 | 0.1056 |
| Contract 8 | 0.0323 | 0.1080 |
| Contract 9 | 0.0385 | 0.0963 |
| Contract 10 | 0.0251 | 0.0708 |
| Contract 11 | 0.0018 | 0.0526 |
| Contract 12 | 0.0322 | 0.0611 |
| Contract 13 | 0.0693 | 0.0933 |
| Mean | 0.2272 | 0.1921 |
It is worth noting that fitting real data can be computationally expensive. This is primarily due to the high dimensionality of the parameter space, which leads to slow optimisation. For reference, fitting the WTI crude oil futures data using the polynomial diffusion model takes approximately 30 minutes. In this case, we employ the “L-BFGS-B” optimisation method introduced in [4]. We recommend that users experiment with different optimisation algorithms depending on the dataset, in order to achieve more efficient estimation.
Quality control
We conducted several tests to ensure that all functionalities of PDSim are operating correctly.
First, we replicated selected results from [22] using PDSim. The reproduced figures match exactly with the two figures in [22], as presented in the “Replicating Schwartz and Smith’s Results” section on the GitHub page. Moreover, the mean absolute errors estimated by PDSim are very close to those reported in the original paper, as discussed in the “Application to WTI crude oil futures data” section of this paper.
Second, we plotted the simulated and estimated futures prices with 95% confidence intervals for both the Schwartz-Smith model and the polynomial diffusion model. These plots specifically validate the implementation of the filtering methods. Users can reproduce these plots using the code provided in the sections “Tests for Schwartz-Smith Model” and “Tests for Polynomial Diffusion Model” on the GitHub page.
Third, users can perform a unit test via the “Unit Tests” navigation bar of PDSim. This unit test calculates the coverage rate, defined as the proportion of simulated trajectories where over 95% of points fall within the confidence interval for a specific set of parameters. If the coverage rate exceeds 95%, we consider the set of parameters to be reasonable. A detailed introduction to the unit test is available in the “Unit Tests” section on the GitHub page.
Finally, we used the “tinytest” package to test the three main functions of PDSim, KF, EKF, and UKF. The outputs from PDSim are compared with corresponding analytical results. Users can re-run these tests after installing PDSim by executing:
tinytest::test_package(“PDSim”)
(2) Availability
Operating system
PDSim can be run on any operating system that supports R. Additionally, it can be run on the Shiny server at https://peilunhe.shinyapps.io/pdsim/ or via Docker.
Programming language
R 4.3.0 or above.
Additional system requirements
None.
Dependencies
PDSim requires the following R packages:
DT (> = 0.31)
ggplot2 (> = 3.4.4)
lubridate (> = 1.9.3)
MASS (> = 7.3.60)
plotly (> = 4.10.4)
scales (> = 1.3.0)
shiny (> = 1.8.0)
shinythemes (> = 1.2.0)
tidyr (> = 1.3.1)
List of contributors
All authors contributed to the software.
Software location:
Code repository
Name: GitHub
Persistent identifier: https://github.com/peilun-he/PDSim
Licence: MIT
Date published: 14/08/24
Language
English
(3) Reuse potential
Some of the functions in PDSim were originally developed and used in [14] to estimate latent state variables and futures prices using the Schwartz-Smith model and the polynomial diffusion model. This package not only allows for detailed estimation but also offers a dynamic web application that vividly visualises the parameter identification challenges discussed in [14]. It serves as a valuable tool for researchers and practitioners in finance who are focused on commodity futures pricing. The interactive interface provides users with a convenient tool for exploring both models, and analysing their sensitivity to individual parameter changes. The user-friendly design ensures accessibility for all users, even those with no programming experience. Additionally, the downloadable plots can be seamlessly incorporated into professional reports or academic papers.
(4) Discussions and Limitations
PDSim consists of both a Shiny application and an R package. The Shiny app provides a straightforward interface for simulating commodity futures data and estimating latent factors, making it accessible to a wide range of users. The R package, in contrast, contains the core functions and offers greater flexibility, allowing users to fit real-world data through R scripts. This separation is primarily due to computational considerations. Parameter estimation in high-dimensional spaces is computationally expensive, making R scripts more suitable than a web-based application for such tasks.
In financial modelling, stochastic processes with jumps are commonly employed. At present, the incorporation of jumps is out of the the scope of the current version of PDSim. However, the inclusion of jump components have been analysed in the following studies, [3], [7], or [20], and in particular, the polynomial diffusion model with jumps has been studied in [11] and its practical implementation would significantly broaden the applicability of PDSim. PDSim focuses on adapting and implementing the standard polynomial diffusion model rather than extending it to jump-diffusion settings.
Acknowledgements
This study was presented at the 17th International Conference on Computational and Financial Econometrics, Mathematics of Risk 2022, 4th Australasian Commodity Markets Conference, and 24th International Congress on Insurance: Mathematics and Economics. We would like to thank the audiences and organisers for their valuable feedback and suggestions.
Competing Interests
The authors have no competing interests to declare.