
Table 1
Experiment 1 & 2. Published articles from which we selected many of the identical cognates and interlingual homographs that were rated in the two experiments. The first column lists the sources of identical cognates for the first experiment. The second column lists the sources of identical interlingual homographs for the second experiment.
| Sources of identical cognates | Sources of identical interlingual homographs |
|---|---|
| Dijkstra, Grainger, and Van Heuven (1999) | Dijkstra, Grainger, and Van Heuven (1999) |
| Dijkstra, Van Jaarsveld, and Ten Brinke (1998) | Dijkstra, Timmermans, and Schriefers (2000) |
| Lemhöfer and Dijkstra (2004) | Dijkstra, Van Jaarsveld, and Ten Brinke (1998) |
| Peeters, Dijkstra, and Grainger (2013) | Kerkhofs, Dijkstra, Chwilla and De Bruijn (2006) |
| Poort, Warren, and Rodd (2016) | Poort, Warren, and Rodd (2016) |
| Van Hell and De Groot (1998) | Schulpen, Dijkstra, Schriefers, and Hasper (2003) |
| Van Hell and Dijkstra (2002) | Smits, Martensen, Dijkstra, and Sandra (2006) |
Table 2
Experiment 1 & 2. Means (and standard deviations) and minimum and maximum values for the Dutch and English characteristics and orthographic similarity measure for the 65 identical cognates, 80 non-identical cognates, 87 identical interlingual homographs and 80 translation equivalents rated across both experiments. Frequency refers to the word’s SUBTLEX frequency in occurrences per million [see Keuleers et al. (2010) for Dutch and Brysbaert & New (2009) for English]; log10(frequency) refers to the SUBTLEX log-transformed raw word frequency [log10(raw frequency+1)]; OLD20 refers to Yarkoni et al.’s (2008) measure of orthographic complexity of a word, expressed as its mean orthographic Levenshtein distance to its 20 closest neighbours; orthographic similarity refers to the measure of objective orthographic similarity discussed in the text (measured on a scale from 0 to 1), which was calculated as the Levenshtein distance between the Dutch and English forms of the words divided by the length of the longest of the two forms.
| Characteristics Dutch words | Characteristics English words | Orthographic similarity | |||||||
|---|---|---|---|---|---|---|---|---|---|
| frequency | log10(frequency) | word length | OLD20 | frequency | log10(frequency) | word length | OLD20 | ||
| identical cognates | 41.5 (61.2) min: 2.17 max: 254 | 2.94 (0.51) min: 1.98 max: 4.05 | 4.52 (1.08) min: 3 max: 8 | 1.58 (0.42) min: 1.00 max: 2.50 | 44.9 (61.5) min: 2.35 max: 308 | 3.08 (0.49) min: 2.08 max: 4.20 | 4.52 (1.08) min: 3 max: 8 | 1.60 (0.36) min: 1.00 max: 2.60 | 1.00 (0.00) min: 1.00 max: 1.00 |
| non-identical cognates | 37.7 (44.7) min: 2.26 max: 244 | 2.95 (0.50) min: 2.00 max: 4.03 | 4.95 (1.05) min: 3 max: 8 | 1.55 (0.35) min: 1.00 max: 2.45 | 47.9 (57.0) min: 2.59 max: 266 | 3.15 (0.46) min: 2.12 max: 4.13 | 4.96 (1.00) min: 3 max: 8 | 1.69 (0.39) min: 1.00 max: 2.60 | 0.69 (0.12) min: 0.50 max: 0.83 |
| interlingual homographs | 39.2 (95.1) min: 0.09 max: 580 | 2.57 (0.77) min: 0.70 max: 4.40 | 4.22 (1.13) min: 3 max: 7 | 1.32 (0.37) min: 1.00 max: 2.70 | 65.8 (153) min: 0.22 max: 828 | 2.81 (0.81) min: 1.08 max: 4.63 | 4.22 (1.13) min: 3 max: 7 | 1.43 (0.36) min: 1.00 max: 2.80 | 1.00 (0.00) min: 1.00 max: 1.00 |
| translation equivalents | 34.1 (35.6) min: 2.15 max: 179 | 2.96 (0.45) min: 1.98 max: 3.89 | 4.90 (1.00) min: 3 max: 7 | 1.49 (0.31) min: 1.00 max: 2.25 | 37.5 (38.4) min: 3.63 max: 215 | 3.10 (0.41) min: 2.27 max: 4.04 | 4.64 (1.02) min: 3 max: 8 | 1.63 (0.34) min: 1.00 max: 2.50 | 0.11 (0.14) min: 0.00 max: 0.50 |
Table 3
Experiment 1 & 2. Examples of items for each of the word types and the Dutch sentence that provided a context for the word (with English translations). The non-identical interlingual homographs only served as fillers in these experiments. The catch items were included to determine whether the participants were carefully reading the sentences. During the experiments, the participants were only shown the Dutch sentence (with the Dutch word form, as here, marked in bold) and the English word form.
| Dutch word form | English word form | Sentence (Dutch original) | Sentence (English translation) | |
|---|---|---|---|---|
| identical cognate | wolf | wolf | De hond is een gedomesticeerde ondersoort van de wolf. | The dog is a domesticated subspecies of the wolf. |
| non-identical cognate | kat | cat | Haar ouders hebben een dikke, grijze kat. | Her parents have a fat, grey cat. |
| translation equivalent | wortel | carrot | Een ezel kun je altijd blij maken met een wortel. | You can always make a donkey happy with a carrot. |
| identical interlingual homograph | angel | angel | Alleen vrouwelijke bijen en wespen hebben een angel. | Only female bees and wasps have a sting. |
| non-identical interlingual homograph | brutaal | brutal | Als klein meisje was ze behoorlijk brutaal. | When she was a little girl she was quite cheeky. |
| catch item | vorst | frost | Een andere aanduiding voor monarch is vorst. | A different term for monarch is sovereign. |
Table 4
Experiment 1 & 2. Means (and standard deviations) and minimum and maximum values for the Dutch and English characteristics and similarity ratings for the set 58 identical cognates, 76 non-identical cognates, 72 identical interlingual homographs and 78 translation equivalents selected for inclusion in our database. Frequency refers to the word’s SUBTLEX frequency in occurrences per million [see Keuleers et al. (2010) for Dutch and Brysbaert & New (2009) for English]; log10(frequency) refers to the SUBTLEX log-transformed raw word frequency [log10(raw frequency+1)]; OLD20 refers to Yarkoni et al.’s (2008) measure of orthographic complexity of a word, expressed as its mean orthographic Levenshtein distance to its 20 closest neighbours. The similarity ratings were provided on a scale from 1 (not at all similar) to 7 [(almost) identical]. For the 28 items (7 identical cognates, 7 non-identical cognates and 14 translation equivalents) that were included in both experiments, only the average ratings from the first experiment were used.
| Characteristics Dutch words | Characteristics English words | Similarity ratings | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| frequency | log10(frequency) | word length | OLD20 | frequency | log10(frequency) | word length | OLD20 | meaning | spelling | pronunciation | |
| identical cognates | 37.0 (56.3) min: 2.17 max: 254 | 2.90 (0.49) min: 1.98 max: 4.05 | 4.57 (1.11) min: 3 max: 8 | 1.61 (0.42) min: 1.00 max: 2.50 | 41.5 (54.0) min: 2.35 max: 280 | 3.07 (0.47) min: 2.08 max: 4.15 | 4.57 (1.11) min: 3 max: 8 | 1.63 (0.35) min: 1.00 max: 2.60 | 6.83 (0.22) min: 6.20 max: 7.00 | 7.00 (0.02) min: 6.92 max: 7.00 | 5.91 (0.67) min: 4.21 max: 7.00 |
| non-identical cognates | 38.3 (45.6) min: 2.26 max: 244 | 2.96 (0.50) min: 2.00 max: 4.03 | 5.00 (1.06) min: 3 max: 8 | 1.57 (0.35) min: 1.00 max: 2.45 | 48.8 (58.1) min: 2.59 max: 266 | 3.16 (0.46) min: 2.12 max: 4.13 | 4.99 (1.01) min: 3 max: 8 | 1.69 (0.39) min: 1.00 max: 2.55 | 6.86 (0.21) min: 6.00 max: 7.00 | 5.35 (0.53) min: 4.00 max: 6.08 | 5.06 (0.72) min: 3.62 max: 6.80 |
| interlingual homographs | 55.4 (126) min: 0.09 max: 662 | 2.74 (0.74) min: 0.70 max: 4.46 | 3.96 (0.86) min: 3 max: 7 | 1.26 (0.32) min: 1.00 max: 2.70 | 70.9 (163) min: 0.29 max: 828 | 2.91 (0.73) min: 1.20 max: 4.63 | 4.01 (0.94) min: 3 max: 7 | 1.37 (0.32) min: 1.00 max: 2.80 | 1.16 (0.28) min: 1.00 max: 2.20 | 7.00 (0.01) min: 6.91 max: 7.00 | 5.49 (0.79) min: 3.83 max: 7.00 |
| translation equivalents | 33.5 (35.2) min: 2.15 max: 179 | 2.95 (0.45) min: 1.98 max: 3.89 | 4.90 (1.00) min: 3 max: 7 | 1.49 (0.31) min: 1.00 max: 2.25 | 35.4 (33.1) min: 3.63 max: 175 | 3.09 (0.40) min: 2.27 max: 3.95 | 4.63 (1.02) min: 3 max: 8 | 1.63 (0.33) min: 1.00 max: 2.50 | 6.88 (0.17) min: 6.23 max: 7.00 | 1.20 (0.43) min: 1.00 max: 2.92 | 1.18 (0.41) min: 1.00 max: 3.08 |
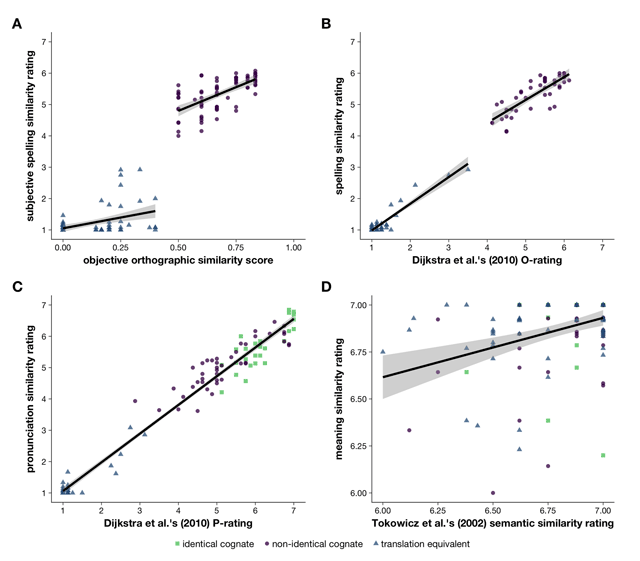
Figure 1
A Objective orthographic similarity score (x-axis) plotted against subjective spelling similarity rating (y-axis). B Dijkstra et al.’s (2010) orthographic similarity rating (O-rating; x-axis) plotted against the spelling similarity ratings obtained in the current experiments (y-axis). C Dijkstra et al.’s (2010) phonological similarity rating (P-rating; x-axis) plotted against the pronunciation similarity ratings obtained in the current experiments (y-axis). D Tokowicz et al.’s (2002) semantic similarity rating (x-axis) plotted against the meaning similarity ratings obtained in the current experiments (y-axis).
Panels A and B display two regression lines fitted separately for each word type, while panels C and D display a single regression line fitted across all items. Word types are distinguished by colours and shapes (identical cognates, squares in green; non-identical cognates, circles in purple; translation equivalents, triangles in blue).