
1 Introduction
Carnatic Music is a prominent art music tradition that originated in the royal courts and temples of South India and is still performed today in concert halls and at temple festivals. Alongside Hindustani Music (originating in North India), it constitutes one of the two main musical traditions of Indian Art Music (IAM). With its fan base encompassing millions of listeners and practitioners around the globe (Gulati et al., 2014), the interest in developing computational approaches for the analysis of Carnatic Music has grown in recent years (Tzanetakis, 2014). The most common contemporary instrumentation in Carnatic concerts involves a solo vocalist accompanied by violin and percussion, therefore, the vocal melody is highly musicologically significant in this style. In this work we contribute to analytical work on this musical repertoire by improving the automatic extraction of predominant vocal melody, or pitch, from mixed recordings using a Carnatic Music informed generation of ground-truth data for this task.
Because isolated vocal audio signals for Carnatic Music are scarce, the predominant melody is usually extracted from audio mixtures (Rao et al., 2014; Gulati et al., 2014, 2016; Ganguli et al., 2016; Nuttall et al., 2021). However, predominant pitch extraction is a difficult and not completely solved problem (Bittner et al., 2017). In particular, Carnatic Music constitutes a difficult case for vocal pitch extraction. Although performances place strong emphasis on a monophonic melodic line from the soloist singer, heterophonic melodic elements also occur, for example from the accompanying violinist who shadows the melody of the soloist often at a lag and with variation. Also, there is the tanpura (plucked lute that creates an oscillating drone) and pitched percussion instruments.
Many well-known predominant pitch extraction methods are heuristic-based (Rao and Rao, 2010; Durrieu et al., 2010; Salamon and Gomez, 2012). More recently, these have been outperformed by Deep Learning (DL) approaches (Kum et al., 2016; Kum and Nam, 2019; Yu et al., 2021). Data to train these models, however, is scarce and limited to Western music styles (LabROSA, 2005; Bittner et al., 2014). In this work, we hypothesize that these models generalize poorly to Carnatic Music given the melodic and instrumental uniqueness of this tradition, with domain transfer or re-training proving difficult due to the lack of Carnatic vocal pitch annotations (Benetos et al., 2018).
In order to understand why vocal pitch extraction is important for the computational analysis of Carnatic music we should first consider the melodic structure of the style. Rāgas are the primary melodic frameworks in Carnatic Music, best expressed through their characteristic sañcāras (melodic patterns, phrases or motifs) (Ishwar et al., 2013; Gulati et al., 2014). Although rāgas are also conceptualized as having constituent pitch positions (svarasthānas) – which might be presented as something like a musical scale – in practice, the svaras (notes) are performed with gamakas (ornaments) that create melodic movement both on and between svaras (Krishna and Ishwar, 2012; Pearson, 2016). These can be experienced as small melodic atoms (Krishnaswamy, 2004; Morris, 2011). The gamakas that may be used on any given svara are determined in part by the rāga, and therefore, also contribute to the identification of the raga (Viswanathan, 1977). In fact, two rāgas may have the same constituent pitch positions, and in such cases it is the particular gamakas and sañcāras employed that disambiguate the two ragas (Viswanathan, 1977; Kassebaum, 2000). Furthermore, the significance of sañcāras can be seen in the format known as rāga ālāpana, in which the performer extemporises based on stock phrases: characteristic sañcāras that are typical of the raga (Viswanathan, 1977; Pearson, 2021). As sañcāras and gamakas play an important role in rāga identity, ālāpana performance and musical compositions, the automated discovery of such melodic patterns has formed an important strand in recent computational research on the style (Ishwar et al., 2013; Gulati et al., 2014; Nuttall et al., 2021).
Typically, the task of melodic pattern discovery in Carnatic Music has been based on time-series of predominant or vocal pitch extracted from audio recordings (Rao et al., 2014; Gulati et al., 2016; Nuttall et al., 2021). Approaches that depend on symbolic notation are another option, but manual transcription is extremely time consuming, and automated transcription is not a trivial problem in Carnatic music, since svaras are performed with gamakas that can radically shift the sound of the resulting unit from the theoretical pitch position referred to by the svara name. Furthermore, the same svara may be performed with different gamakas in different musical contexts, e.g. ascending or descending phrases (Ramanathan, 2004). Recently, the quantization of pitch tracks and identification of stable pitches and extremes (peaks and valleys) of the pitch contour has been used as an approach for creating a promising descriptive symbolic annotation/transcription of audio recordings (Ranjani et al., 2017, 2019). However, these rely on extracted pitch tracks and hence would benefit from any improvements in that process, such as those proposed here.
This work contributes to a more reliable and informative computational melodic analysis of Carnatic Music by improving the state-of-the-art for vocal pitch extraction in this tradition. The specific contributions are: (1) the Saraga-Carnatic-Melody-Synth dataset: a novel, large and open ground-truth vocal pitch dataset for Carnatic Music that is generated using a tradition-specific method inspired by Salamon et al. (2017), (2) we train a state-of-the-art data-driven vocal melody extraction model (Yu et al., 2021) using the proposed dataset, and perform evaluation across multiple traditions, showing the positive impact of our tradition-specific approach for this task in a Carnatic context, and (3) we study the impact of the newly extracted pitch tracks on the musicologically relevant task of repeated melodic pattern discovery in Carnatic Music, evaluating the results using expert annotations.
2 Literature Review
2.1 Datasets
The Dunya Carnatic and Hindustani corpora, built within the CompMusic project (Serra, 2014), provide many relevant datasets. Saraga (Srinivasamurthy et al., 2020) includes audio recordings of live performances containing, in many cases, close-microphone2 recordings of violin, mridangam, ghatam and vocals. Although automatically-extracted pitch tracks are included in Saraga, these are not suitable for training data-driven models given the numerous errors that can result from automatic extraction using a heuristic algorithm (Salamon and Gomez, 2012), which may propagate to the trained models or prevent the training algorithm from reaching a decent minimum. To our best knowledge, no open ground-truth vocal melody dataset for Carnatic Music currently exists.
In general, pitch tracks are difficult and time consuming to annotate manually. Salamon et al. (2017) approached this issue by artificially creating these annotations in a reverse-engineering manner using an Analysis/Synthesis framework, first automatically extracting the pitch from melodic instruments, and then resynthesizing the audio signals over their corresponding extracted pitch tracks, forcing the harmonic structure of the regenerated signals to be built on top of frequency values at hand. Thus, the pitch tracks become ground-truth annotations for the resynthesized signals. However, this method is implemented for the MedleyDB dataset (Bittner et al., 2014), assuming isolated and studio-quality recordings of particular instrumentation and styles (mainly Pop and Rock), making it infeasible to be directly reproduced for the case of Carnatic music and its available datasets, which do not have the same characteristics.
2.2 Methods for pitch extraction
Melodia (Salamon and Gomez, 2012) is a heuristic-based algorithm for predominant melody extraction that has been broadly used for computational melodic analysis of Carnatic Music (Koduri et al., 2014; Gulati et al., 2014; Ganguli et al., 2016; Nuttall et al., 2021). Atlı et al. (2014) adapt the heuristic rules in Melodia so that the longest detected pitch segments are prioritized, useful for musical contexts in which sustained melodic lines are recurrent. This approach is named PredominantMelodyMakam (PMM). In addition to including 20 parameters that need to be manually set, Melodia is not optimized to discriminate melodic sources, which represents an important problem for Carnatic Music in which all instruments are pitched and the violin plays a prominent role.
Recent DL-based models for predominant pitch extraction can focus on a specific source (Kum et al., 2016; Kum and Nam, 2019; Yu et al., 2021). In this work, we refer to the Frequency-Time Attention Network (FTA-Net) (Yu et al., 2021), a deep neural network that achieves state-of-the-art performance for vocal pitch extraction. FTA-Net is formed by: (1) the Frequency-Time Attention branch, which consists of four layers, each formed by a Frequency-Temporal Attention (FTA) module connected to a Selective Fusion (SF) module. FTA modules mimic human hearing behaviour by drawing attention to the predominant melody source, while the SF dynamically selects and fuses the attention maps created by the FTA modules, (2) the Melody Detection branch is formed by four fully-stacked convolutional layers to perform iterative downsampling of the input data. In an ablation study, this branch is shown to improve the voicing detection.
FTA-Net is fed with the Combined Frequency and Periodicity (CFP) features (Su and Yang, 2015), which combine the power spectrum (frequency domain), the generalized cepstrum (time domain), and the generalized cepstrum of the spectrum (frequency domain), blending information of harmonics (frequency domain) and sub-harmonics (temporal domain) to emphasize the fundamental frequency and facilitate its detection. CFP are widely-used for predominant pitch extraction (Hsieh et al., 2019; Yu et al., 2021).
2.3 Methods for melodic pattern discovery
A common pipeline for melodic pattern discovery in Carnatic music is to apply predominant pitch extraction to audio signals and compute pairwise distance measures between subsets of the data (Ishwar et al., 2013; Gulati et al., 2014; Rao et al., 2014; Nuttall et al., 2021). However, there is a lack of standardized baselines, evaluation datasets and metrics. Ishwar et al. (2013) and Gulati et al. (2014) involve experts after the results are collected to vote on their quality, whereas Rao et al. (2014) use expert annotations gathered beforehand. Owing to the expensive nature of creating expert annotations, they are limited in number. The Saraga dataset includes melodic pattern annotations, but for most recordings, only a few instances of a very limited number of patterns, normally from two to four, are available.
In this work we rely on Nuttall et al. (2021) for the melodic pattern finding approach. We refer the reader to the original paper and accompanying repository for a full explanation of the process, summarising here the particular elements relevant to the current paper. The pipeline computes the matrix profile (Yeh et al., 2016), M, of the input pitch track, T, for a specified length, m. M returns, for each subsequence in T, the distance to its most similar subsequence in T. Similarity is computed using non-z-normalised Euclidean distance since the goal is to match subsequences identical in shape and y-location i.e. pitch. Pattern groups are identified by locating minima in the matrix profile to identify a parent pattern and querying the entirety of T with this parent. Groups include every retrieved subsequence with a distance to the parent below some threshold, ϕ, the only tunable parameter of the process.
In order to return full melodic motifs with plausible segmentation points, Nuttall et al. (2021) exclude subsequences that either contain long periods of silence (0 values in T) or stability (periods of constant pitch in T), since these are likely to lie at the borders of musically salient patterns (sañcāras) in Carnatic music.3 For that reason, here in this work we do not discard all stable pitches, as such points of stability are also salient in rāga performance (Viraraghavan et al., 2017). Instead, we have used long stability periods as cues for plausible segmentation, based on perceptual grouping tendencies in music perception (Deutsch, 1982; Deliege, 1987).
3 Dataset
3.1 Data creation
Our approach to generate ground-truth vocal pitch annotations is inspired by Salamon et al. (2017). Our Carnatic-specific methodology intends to (1) characterize the main features of Carnatic melodies and instrumentation, and (2) adapt to the characteristics of currently available Carnatic Music data. Related to the latter point, the input dataset for our process is the close-microphone Carnatic collection in Saraga (Srinivasamurthy et al., 2020). See Figure 1 for a complete diagram of the data generation process.
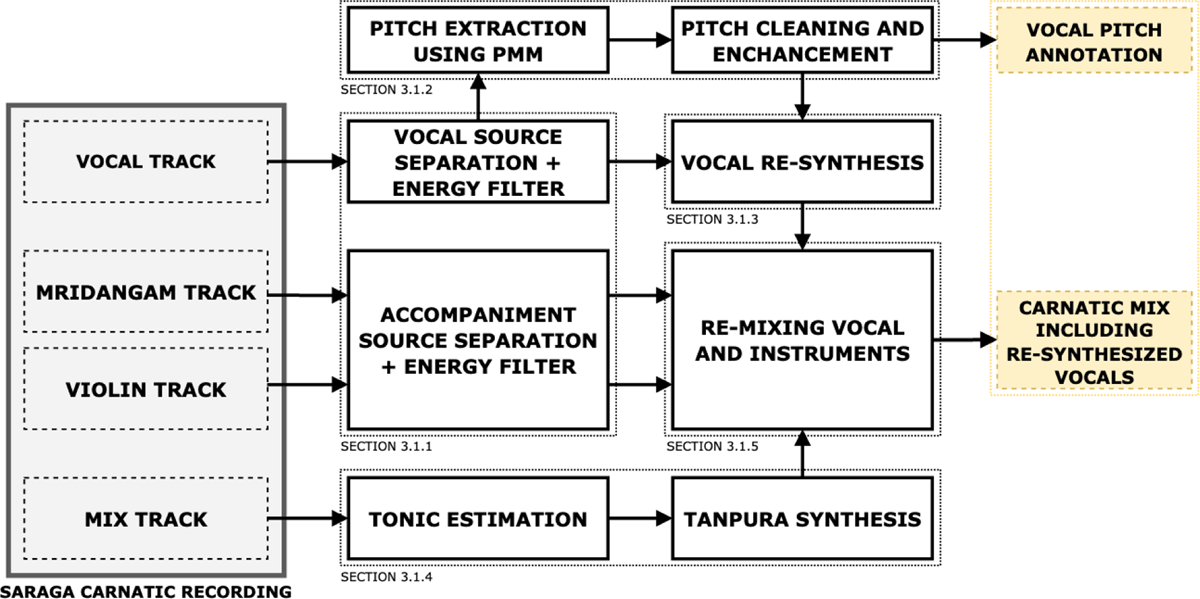
Figure 1
Block diagram of the data generation pipeline for a particular Saraga recording. We also indicate in which sections in this paper each building block is presented.
3.1.1 Leakage removal
The close-microphone audio in Saraga is recorded in live performances. The instruments are predominant in their corresponding tracks, but microphones also capture interference from the other instruments. We remove the accompaniment leaked in the singing voice using U-Net-based singing voice separation (Yu et al., 2021), which has recently shown promising results in source separation when the target source is predominant in the signal (Hennequin et al., 2020). We use the same approach to remove the voice from the recordings corresponding to the violin and mridangam. Finally, we compute the window-wise energy of the separated signals and remove leaked background noise with an energy below a predefined threshold. We do not aim at removing the mridangam interference in the violin signal and vice versa given that in the remixing step (Section 3.1.5) the accompaniment instruments are mixed together and all possible interferences between mridangam and violin are summed in the resulting accompaniment track.
3.1.2 Preliminary pitch extraction
We automatically extract the pitch curve from the cleaned vocal signal to be used as a reference for the singing voice resynthesis (Section 3.1.3). To account for possible unresolved interferences and source separation errors we decide against using a monophonic pitch tracker and use PMM (Atlı et al., 2014) instead. In preliminary experiments, PMM showed better performance than the original Melodia algorithm in capturing gamakas, since the heuristics in PMM contribute to a better detection of sustained melodies. For the same reason, sporadic violin traces that may be present in the pitch are lessened at this point.
Next, the raw pitch track is enhanced through the following steps: (1) filling gaps shorter than 250 ms using 1D interpolation between boundaries (Ganguli et al., 2016; Nuttall et al., 2021), (2) smoothing the pitch curves using the Gaussian filter in Equation 1:
where σ is the filter width and t the time index of the pitch track, and (3) restricting pitch track values to an interval of [80, 600] Hz (Venkataraman et al., 2020), annotating silent regions with 0 Hz.
Because the pitch extraction is run in an ideal scenario in which the singing voice is predominant and the leakage has been reduced, we can expect to obtain decent quality pitch tracks after post-processing. As a matter of fact, several computational studies of Carnatic Music build on top of pitch tracks obtained using a similar pipeline (excluding the leakage removal in Section 3.1.1) (Gulati et al. 2014, 2016; Ganguli et al., 2016), and the pitch tracks in Saraga are also computed as such (Srinivasamurthy et al., 2020). However, given the shortage of ground-truth vocal pitch annotations for Carnatic Music, we are currently unable to evaluate the quality of these objectively. Some available datasets have been validated by active listening (Eremenko et al., 2018), nonetheless, for the case of pitch track annotations, and especially in the melodically complex Carnatic context, such strategy may be time-consuming and a confident validation difficult to ensure. Another factor to consider is that this pipeline includes a combination of data-driven techniques and several heuristic steps, hence it is computationally expensive and its scalability may be compromised. Consequently, an improved, scalable, and straightforwardly runnable method would be beneficial.
3.1.3 Re-synthesis of the vocal audio signal
We denote the pitch track obtained with the pipeline in Sections 3.1.1 and 3.1.2 as reference pitch. Next, we reconstruct the spectral harmonic structure of the vocal signal on top of the reference pitch, so that it perfectly matches the new vocal audio signal and can be used for training and evaluating data-driven approaches. Thus, we consider the generated data as ground-truth. To perform the vocal resynthesis, we rely on the Harmonic plus Residual (HpR) model of Serra and Smith (1990).
We first compute the Short-Time Fourier Transform (STFT) of the original signal and identify the energy peaks in the magnitude spectrum and the corresponding values in the phase. The peaks are interpolated to infer the frequency, magnitude and phase peak trajectories. More intuitively, for a vocal signal, these trajectories are the fundamental frequency plus the harmonics above, from which we also compute the magnitude and phase spectral values at each time-step. Next, we iterate through the trajectories while comparing the analyzed frequency peaks with perfectly formed harmonic series that are precomputed on top of the reference pitch. Given that both reference pitch and audio signal are sampled at the same rate, we can relate the time indexes in both. Let fh be a certain precomputed harmonic over the reference pitch value, the closest peak to fh in the trajectories obtained in the analysis, f0 the reference pitch represented in Hz, and δ a harmonic deviation tolerance parameter. The lower δ is, the more restrictive we are. If the absolute difference between the analyzed frequency peak and the theoretical harmonic is smaller than a pre-defined acceptance threshold β, we consider the analysis successful and accept the peak. As proposed in the Python implementation of Serra and Smith’s HpR (Serra et al., 2015), a definition of β that is found to be effective is:
We use β to filter out problematic regions that may lead to unnatural synthesis or artifacts. As per the successfully analyzed peaks, we substitute the analyzed frequency value in the trajectory by the perfect harmonic computed on top of the reference pitch track, to ensure the correspondence between the output regenerated signal and pitch annotation. We repeat the same approach for the entire number of harmonics in a window. When is greater than β, we consider the synthesis not feasible and the peak is removed. If none or less than a predefined number of harmonics are accepted for a certain window, the window in the signal is completely silenced and the reference pitch value is set to 0. This prevention strategy averts unnatural synthesis and artifacts produced by the use of reference pitch values too distant from the actual note. Octave errors, apart from being reduced during pitch post-processing, are also addressed at this point, by setting to silence the affected regions. Reference pitch values with no corresponding predominant analyzed peaks are set to 0 Hz.
Next, we run additive synthesis using (1) the newly computed frequency peaks, and (2) the magnitude and phase trajectories originally analyzed from the input signal. The output of this operation is a resynthesized vocal signal whose harmonic structure has been generated on top of the reference pitch. We propose an adaptation of the HpR algorithm so that we are able to use the reference pitch at each window instead of automatically computing it using the Two-Way Mismatch algorithm (Maher and Beauchamp, 1994), as proposed by Serra et al. (2015). Moreover, the original HpR performs the resynthesis over the frequency peaks that are estimated in the analysis of the input signal, while we mathematically compute the fundamental and harmonic frequency peaks over the reference pitch to ensure the annotation confidence.
Although we may miss the inharmonic content in the signal – mainly related to consonants and breathing – given that we resynthesize the sound using harmonic sinusoids, we focus on better characterizing ornamentations which are mainly present in sung vowels than consonants. Hence, we are interested in resynthesizing correctly the sung vowels while leaving the refinement of consonants for future work. As presented in Section 1, these ornamentations in Carnatic Music play a key role in the melodic framework and therefore are prioritized. By selecting a considerable number of harmonics we can output an intelligible vocal signal.
3.1.4 Tanpura synthesis
The tanpura instrument is not included in the close-microphone audio in Saraga but is an essential element in a Carnatic music arrangement, therefore we synthesize this instrument using a signal processing based model (Van Walstijn et al., 2016), which we adapt to allow any given tonic in Hertz as input. Since the tonic annotations in Saraga are automatically extracted and may be inconsistent for certain recordings, we estimate the tonic (Salamon et al., 2012) for an entire concert and use the most recurrent estimation, since a single tonic is expected to be maintained throughout the concert.
3.1.5 Remixing the stems
We generate an artificial mix by combining the synthesized vocal with the close-microphone audio tracks corresponding to the other instruments (tanpura, violin and mridangam). We use the remixing technique proposed by Bittner et al. (2014) for the MedleyDB dataset. The algorithm aims at estimating the mixing weights of the instrument audio signals using the original mix as reference by minimizing the following non-negative least squares objective constraining the mixing weights ai:
Here, X is a 3-rank tensor containing the STFT of the instruments and therefore shaped as (number of instruments, frequency bins, time steps), a is the list of mixing weights, and Y is the STFT of the original mix used as target, in this case shaped as (1, frequency bins, time steps). In contrast to Bittner et al. (2014), we include additional constraints to Equation 3 considering the characteristics of a Carnatic Music rendition. The vocal source is, without an exception, the predominant source in the performance and therefore, we restrict the vocal weights to be within [4, 5]. The tanpura is never predominant but a background generator very rich in timbre, therefore we restrict its weights to [1, 3]. The final restriction is to avoid the violin to be louder than the vocal source, to ensure the predominance of such from the lead melodic sources. These rules contribute to the generation of a more natural Carnatic recording following the traditional mixing configuration for each instrument in the arrangement. We relate the remixed stems including the resynthesized vocal signal, with the corresponding pitch annotation we used as reference for the resynthesis.
3.2 Data generation setup
The presented pipeline is applied to the recordings in Saraga that have available close-microphone audio, 168 out of the total 249. There is no convention in the literature about the length in seconds of individual samples. Given that our dataset is intended to serve as training data (rather than to be listened to) and that the duration of Carnatic Music performances often last over an hour, we split the recordings into chunks of 30 s. The pipeline is run at a sampling rate of 44.1 kHz.
(Section 3.1.1) The source separation is performed using Spleeter (Hennequin et al., 2020). The threshold in the energy filtering for leakage removal is 1.25% of the peak energy in the signal.
(Section 3.1.2) PPM is applied using a window of 2048 samples and hop size of 128. Before running the algorithm, we apply an equal loudness filter to the signal (Salamon and Gomez, 2012). The pitch curve is Gaussian smoothed with a sigma of 1.
(Section 3.1.3) The window and hop sizes are set to 2048 and 128 respectively corresponding to the pitch extraction parameters. We use 30 harmonics, δ = 0.001, and set to 5 harmonics the minimum to perform resynthesis. The remaining parameters can be found in the implementation referenced in Section 7.
(Section 3.1.4) The tanpura synthesis model is used out-of-the-box (including our modification presented in Section 3.1.4). Since the model is designed to synthesize a single pass throughout the instrument strings, the generated tone has a duration of ≈3 s. We generate multiple instances, concatenating them using a triangular window to obtain a 30 s signal.
(Section 3.1.5) We apply a single scalar mixing weight per instrument for the entire 30 s chunk. Given the extensive duration of Carnatic renditions and the sections in a performance, and also the roughly stable mix in live concerts, we perceptually observe no notable mixing imbalance in the audio chunks.
3.3 Dataset specifications
The dataset resulting from the presented process is named Saraga-Carnatic-Melody-Synth (SCMS), and is made publicly available for research purposes (see Section 7). The dataset occupies 25GB of space. We split the dataset into train (11 artists, 1683 files, ⋍845 minutes) and test (5 artists, 777 files, ⋍390 minutes) sets, ensuring that the singer gender and tonic range are equally-distributed between both sets, and the recordings of a single artist are never in both train and test sets simultaneously. Audio chunks containing solely unvoiced melody segments are disregarded.
The audio files are in WAVE format, 16 bit depth, and sampled at 44.1 kHz. The melodic annotations are in CSV format with two columns: timestamp in seconds (hop size of 29 ms) and fundamental frequency values, represented in Hertz (Hz). Unvoiced timestamps are annotated with 0 Hz. The dataset includes a folder for the audio recordings, and a folder for the annotations. Note that audio and annotations for a particular chunk, artist, or even tonic, can be retrieved using the included JSON dataset metadata. As such, one can easily parse our proposed and curated splits to reproduce our results. See Table 1 for a detailed comparison of the specifications in terms of style and size between SCMS and available pitch extraction datasets.
Table 1
Specification comparison between our SCMS and different state-of-the-art-melody datasets (Goto et al., 2002)*, (LabROSA, 2005)⊚, (Hsu and Jang, 2010)†, (Bittner et al., 2014)∧, (Salamon et al., 2017)⋉. Table inspired by a similar comparison by Bittner et al. (2014).
| DATASET | CONSIDERED GENRES | LENGTH | % VOCAL | NO. SAMPLES | SAMPLE LENGTH | AVAILABLE AUDIO? |
|---|---|---|---|---|---|---|
| MedleyDB V1∧ | Rock, pop, jazz, rap | ⋍447 min | 57% | 108 | ∼20–600 sec | Upon request |
| MedleyDB V2∧ | Rock, pop, jazz, rap | ⋍750 min | 57% | 196 | ∼20–600 sec | Upon request |
| MDB-mel-synth⋉ | Rock, pop, jazz, rap | ⋍190 min | 64% | 65 | ∼20–600 sec | Yes |
| MIR1K† | Chinese pop | ⋍113 min | 100% | 1000 | ∼4–13 sec | Yes |
| RWC* | Japanese & US pop | ⋍407 min | 100% | 100 | ∼240 sec | No |
| ADC2004⊚ | Rock, pop, opera | ⋍10 min | 60% | 20 | ∼30 sec | Yes |
| MIREX05⊚ | Rock, pop | ⋍6 min | 80% | 12 | ∼30 sec | Yes |
| MIREX09 | Chinese pop | ⋍167 min | 100% | 374 | ∼20–40 sec | No |
| INDIAN08 | Hindustani Music | ⋍8 min | 100% | 8 | ∼60 sec | No |
| SCMS | Carnatic Music | ⋍1235 min | 100% | 2460 | ∼30 sec | Yes |
4 Experiments
4.1 Vocal pitch extraction
In order to evaluate the impact of the SCMS on the computational melodic analysis of Carnatic Music, we perform two vocal pitch extraction experiments using the generated data.
Experiment A – Cross-cultural evaluation of FTA-Net: Empirical comparison between FTA-Net trained and evaluated on data collections from both IAM and Western music domains. We aim at studying the extent of the domain-drift (Quiñonero-Candela et al., 2009) between different musical repertoires in a DL-based vocal pitch extraction context.
Experiment B – Comparison between FTA-Net and Melodia: Empirical comparison between FTA-Net trained with the SCMS and baseline Melodia.
4.1.1 Experimental setup
The CFP features to feed FTA-Net are computed at a sampling rate of 8 kHz to reduce the computational expense. We use a window size of 2048 samples (256 ms at 8 kHz) and hop of 80 (10 ms at 8 kHz). We do not use the complete SCMS in our experimentation to prevent the difference in training data size to be a determining factor when comparing the models. Correspondingly, for each artist in the training set of the SCMS, we randomly select 85 samples, in total, from all renditions performed by said artist. Therefore, we consider 85*11 = 935 samples, from a total of 95 renditions performed by the 11 artists in training set. For training we use the ADAM optimizer with a learning rate of 0.001, batch-size of 16, and binary cross-entropy loss.
We denote the FTA-Net trained on the vocal subset of MedleyDB as FTA-W (W stands for Western Music). We resynthesize the singing voice in MedleyDB using our method in Section 3.1.3 and remix it back with the rest of instruments to bypass biases that may arise from the synthesis algorithm. We denote by FTA-C (C stands for Carnatic Music) the FTA-Net trained on the SCMS. We evaluate FTA-W and FTA-C on (1) the test set of SCMS, (2) a collection of Hindustani data of the same size, referred to as SHMS, and generated using our synthesis method applied only on selected mixture recordings where the singing voice is clearly dominant, since no close-microphone data is available in this case, (3) Western datasets from the literature – ADC2004, and MIREX05. We use the melody metrics of Bittner and Bosch (2019) including Voicing Recall (VR), Voicing False Alarm (VFA), Raw Pitch Accuracy (RPA), Raw Chroma Accuracy (RCA) and Overall Accuracy (OA).
4.2 Melodic pattern discovery
Ultimately, vocal pitch tracks are used as features for further computational musicology research. To assess the impact of our extracted pitch tracks, we use them for the musicologically relevant task of melodic pattern discovery. Nuttall et al. (2021) present a computational approach that utilizes the main melodic vocal line, extracted using Melodia, to identify and group melodic patterns in the sung melody from a performance in Saraga Carnatic. With the subsequent availability of expert annotations of melodic patterns in this performance (Section 4.2.2) we are able to apply this pattern finding approach to our newly extracted pitch tracks and the current state-of-the-art, Melodia, evaluating the results empirically.
Experiment C – Melodic pattern discovery comparison: We assess the suitability of eight pitch track candidates for melodic pattern discovery. To this end, a match between a detected pattern and our expert-annotated sañcāra and phrases is evaluated in terms precision, recall, and F1-score.
4.2.1 Experimental setup
We extract eight pitch tracks from the audio of a performance from an artist not present in the training data of the SCMS: the Akkarai Sisters performance of a composition titled Koti Janmani,4 by the composer Oottukkadu Venkata Kavi, set in the Carnatic rāga Rītigauḷa, used also by Nuttall et al. (2021). Each of the eight pitch tracks correspond to one of the following four methods applied to either the audio of the mixed recording or the close-microphone vocal stem in Saraga:
Melodia – Current baseline method.
Melodia-S – Melodia applied to vocal source separated audio (Hennequin et al., 2020).
FTA-W – FTA-Net trained on MedleyDB, vocal stem passed through our resynthesis algorithm.
FTA-C – FTA-Net trained on the SCMS
For each of the eight pitch tracks we apply the melodic pattern discovery process of Nuttall et al. (2021). To account for the variable length of patterns, the process is run for each integer length in the range [2, 7]s. Pattern groups are restricted to a maximum of 20 per group, with a maximum of 20 groups for each pattern length. In practice, no pattern groups reach these limits. ϕ is determined individually for each pitch track and chosen as the threshold which delivers the maximum F1 score when evaluated on our expert annotations (Table 4). We optimize for F1 so as to control the quantity and relevance of the retrieved patterns.
Table 4
Comparison of different pitch extraction methods for melodic pattern discovery.
| PITCH TRACK | STEM | COVERAGE (%) | PRECISION | RECALL | F1 | NO. PATTERNS | NO. GROUPS | Φ |
|---|---|---|---|---|---|---|---|---|
| Melodia | Mix | 69.0 | 0.323 | 0.297 | 0.310 | 164 | 21 | 2.7 |
| Melodia-S | Mix | 71.4 | 0.341 | 0.371 | 0.356 | 170 | 20 | 2.8 |
| FTA-W | Mix | 74.8 | 0.250 | 0.007 | 0.113 | 4 | 2 | 2.9 |
| FTA-C | Mix | 80.3 | 0.396 | 0.655 | 0.494 | 283 | 66 | 2.2 |
| Melodia | Vocal | 76.0 | 0.514 | 0.574 | 0.542 | 181 | 48 | 1.0 |
| Melodia-S | Vocal | 75.3 | 0.523 | 0.574 | 0.547 | 197 | 50 | 1.0 |
| FTA-W | Vocal | 75.3 | 0.395 | 0.155 | 0.223 | 43 | 20 | 2.9 |
| FTA-C | Vocal | 78.0 | 0.485 | 0.669 | 0.562 | 227 | 49 | 2.4 |
It is important to consider that (1) there is some variation possible in where an annotator might choose to segment a longer pattern, and (2) the process only accepts fixed values of pattern length m rather than a range; consequently, since the annotations themselves are of variable length, the process will almost always return a pattern whose length does not correspond exactly to the annotation. Therefore, we consider a returned pattern, R, to be a match with an annotation, A, if the intersection between them is more than two-thirds the length of A and more than two-thirds the length of R.
4.2.2 Melodic pattern annotations
As mentioned in Section 2, no open and complete annotations to evaluate the task of melodic pattern discovery are available. For the evaluation of the melodic pattern finding experiment we use expert annotations created, as part of this work, by a professional Carnatic vocalist. These contain all sañcāras in the audio recording, annotated in the software ELAN (Sloetjes and Wittenburg, 2008), using sargam syllables (the notation traditionally used by Carnatic musicians to refer to the underlying svaras). Sañcāras (musically meaningful phrases and motifs) are defined according to the annotator’s lived experience as a professional performer of 21 years standing. It should be noted that there exists no definitive list of such sañcāras, and although there will be a good degree of agreement between professional musicians, there will also be subtle points of difference in defining the borders of a sañcāra/phrase (the segmentation), as is also the case in the annotation of other musical styles (Bruderer, 2008; Nieto, 2015). Although these annotations are subjective to some degree, they have the virtue of being informed by expert knowledge of the style rather than based on an externally imposed metric, and thus should be highly relevant to Carnatic performance practice.
As sañcāras in Carnatic compositions are often varied on their subsequent repetitions, but are still recognizably connected musically, we capture these connections by grouping such variations together with an ‘underlying sañcāra’ annotation, where the underlying annotation is the first occurrence of the sañcāra group (typically the simplest version). Furthermore, as Carnatic music can be segmented hierarchically, wherein sometimes two or more shorter segments will lie within one longer segment, we also create longer phrase-level annotations which consist of either one long or several short sañcāras. This is done to capture the multi-level nature of musical structure (McFee et al., 2017; Popescu et al., 2021). Finally, the evaluation is made on the two levels – ‘underlying sañcāras’ and ‘underlying full phrases’.
5 Results and Discussion
Experiment A. Cross-cultural evaluation of FTA-Net. In Table 2 a cross-cultural evaluation of FTA-Net is displayed. We observe a notable performance difference due to the change of repertoire in the testing data. On the test set of SCMS, FTA-W performs worse than FTA-C, ≈20% less in terms of overall accuracy, showing that training the FTA-Net with data that does not include the idiosyncratic melodic features of Carnatic Music produces subpar performance on the Carnatic repertoire. We observe a similar trend when evaluating on the Western music datasets. We study a selection of Carnatic vocal pitch tracks extracted using FTA-W to identify specific problems in comparison to Western recordings. The most common observed problem is the effect of the violin, which typically overlaps with the lead singer, playing a similar melody line, causing the false alarm detection to rise (see VFA column in Table 2). Another observed problem is that FTA-W fails to capture the gamakas in detail. Such strong and fast vocal ornaments are not commonly seen in Pop/Rock.
Table 2
Performance comparison between FTA-Net trained using the SCMS (FTA-C) and MDB-synth (FTA-W). Results presented as percentages (%).
| MELODY EXTRACTION METRICS | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| VR | VFA | RPA | RCA | OA | ||||||
| ↓TEST SET/MODEL → | FTA-C | FTA-W | FTA-C | FTA-W | FTA-C | FTA-W | FTA-C | FTA-W | FTA-C | FTA-W |
| SCMS (test) | 96.35 | 83.26 | 8.38 | 31.43 | 90.17 | 69.30 | 90.46 | 70.62 | 90.99 | 67.72 |
| SHMS | 91.25 | 80.18 | 17.04 | 17.53 | 78.96 | 68.76 | 81.78 | 70.20 | 81.39 | 73.84 |
| MIREX05 | 86.74 | 89.21 | 21.40 | 19.23 | 68.11 | 73.94 | 69.68 | 74.18 | 72.44 | 76.66 |
| ADC2004 | 77.25 | 87.79 | 29.17 | 27.94 | 64.01 | 77.98 | 66.62 | 79.98 | 64.46 | 77.32 |
Note the reduced number of false alarm detections of the FTA-C on the SCMS testing set, in addition to the improvement on pitch and chroma accuracies. The high performance that FTA-C achieves in the Carnatic repertoire is probably due to the fact that the SCMS is less diverse in terms of instrument arrangement and vocal style, representing as such the current performance practice in Carnatic music, where concerts with vocalists as soloists greatly outnumber those where other instruments act as the soloist. In Table 2 we also observe that the FTA-C generalizes better to Hindustani than to Western music, yet achieving better performance than the model trained on modern Western music, FTA-W, from which we can infer that the model is not overfitting to the SCMS but learning the idiosyncratic features of the music repertoire. Despite being two different music traditions, Carnatic and Hindustani include many common concepts and features.
Experiment B. Comparison between FTA-C and Melodia. In Table 3 we observe the comparison between FTA-C and Melodia. From this table we can conclude that (1) FTA-C is able to outperform Melodia, a broadly used pitch extraction algorithm for the computational analysis of Carnatic Music and (2) Melodia scores a vocal pitch extraction accuracy comparable to the performance reported in the original paper for diverse test datasets (Salamon and Gomez, 2012), which may suggest that the SCMS dataset includes standard quality audio with high-accuracy annotations.
Table 3
Performance comparison between FTA-Net trained using the SCMS (FTA-C) and Melodia (Salamon and Gomez, 2012). Results presented as percentages (%).
| MELODY EXTRACTION METRICS | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| VR | VFA | RPA | RCA | OA | ||||||
| MODEL → ↓ TEST SET | FTA-C | MELODIA | FTA-C | MELODIA | FTA-C | MELODIA | FTA-C | MELODIA | FTA-C | MELODIA |
| SCMS (test) | 96.35 | 85.75 | 8.38 | 17.17 | 90.17 | 77.51 | 90.46 | 79.81 | 90.99 | 77.07 |
Experiment C. Quantitative evaluation of melodic pattern discovery. Table 4 presents the recall, precision and F1 score of the melodic pattern discovery algorithm applied to the eight pitch tracks. The results extracted from the FTA-C pitch tracks outperform the others in almost all metrics except for precision on the vocal stem, in which Melodia-S, which is the second best performing pitch track, is leading. However, FTA-C pitch track achieves +28.4% recall and +13.8% F1 over Melodia-S for the mixed stem, and an improvement of +9.5% recall and +1.5% F1 for the vocal stem.
We observe that Melodia and Melodia-S struggle to achieve anywhere near competitive results when applied to the mixed recording, but do provide comparable results for the vocal stems, however data of this kind is rarely available in practice. The results also suggest that using Spleeter to clean the accompaniment is not sufficient to solve the issue, showing the relevance of FTA-C. The “coverage” in Table 4, refers to the proportion of the returned pitch track which corresponds to non-zero values; note that this does not reflect the proportion of the pitch track which is annotated correctly. The pitch tracks returned from FTA-C have slightly more coverage with a +8.9% and +3.3% improvement on Melodia-S for the mix and vocal stem respectively. Note also that the pitch tracks extracted using FTA-W (trained on Western music) perform considerably worse than all others in metrics, coverage and number of groups returned.
There are 148 annotated patterns in total; 41 are identified by both FTA-C and Melodia-S. FTA-C identifies a further 56 that Melodia-S is unable to and Melodia-S identifies a further 14 that FTA-C is unable to. In total there are 37 patterns that neither manage to identify. Figure 2 illustrates four examples of annotations that only FTA-C is able to identify. It is obvious from exploring these comparative plots that Melodia struggles to correctly annotate regions of quite intense oscillations from the mixed recording, as seen in the third plot in Figure 2 between ∼153.0 s and ∼153.6 s, again between ∼154.0 s and ∼154.3 s, and further throughout the annotation plots that can be found in the accompanying GitHub repository.

Figure 2
Four different example patterns identified by FTA-C but disregarded by Melodia-S (pitch extraction run on the mixture audio).
Figure 3 shows four instances of motif group 39 starting at different parts of the performance. The pitch track in the Figure has been extracted by FTA-C on the mixed recording. We can see two forms of the same phrase – the first, appearing at 3:01 and 3:19 is the simplest version (covering the svara annotation “nnsndmgmnns”), while a melodic variation on this phrase can be seen at 6:57 and 7:08. In fact, an underlying sañcāra included in this phrase occurs eight times in this recording, seven of which were found and correctly placed into one group of related sañcāras, notwithstanding the fact they show considerable variation. Such returned groups of motifs could be of interest to musicologists who wish to examine variations in performance of sañcāras and related phrases across audio recordings, for example, for the purposes of comparative and/or historical performance analysis, as well as the analysis of musical compositions. Any such study would ultimately depend on the quality and accuracy of their extracted vocal pitch annotations.
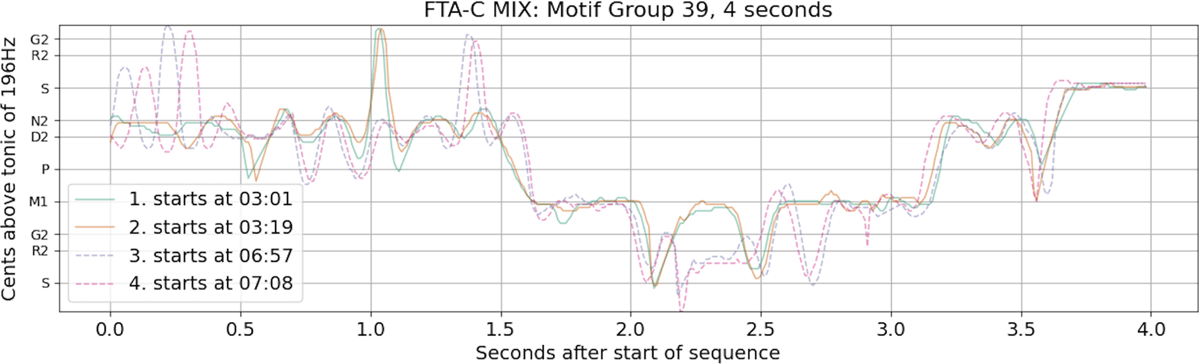
Figure 3
4 occurrences of motif 39 retrieved using FTA-C on the mixed recording. The dashed and solid lines refer to two distinct variations of the same underlying melodic pattern.
The reader is referred to the accompanying repository where Experiment C is run for two additional recordings including different artists and rāgas.
6 Conclusions
In this work we present a methodology to automatically generate a novel, large, and open collection of vocal pitch annotations for Carnatic Music: the SCMS. We use the Saraga dataset which serves as input for a bespoke Analysis/Synthesis method that accounts for the features and challenges of Carnatic Music, as well as data availability for this style. To study the impact of the SCMS, we then train a state-of-the-art vocal pitch extraction model, aiming to equal the performance that this model obtains for currently available datasets, which mainly include Pop, Rock, and related music repertoires. We run a comprehensive cross-cultural evaluation, comparing two models trained on Carnatic and Western music respectively, across Carnatic, Hindustani, and Western test sets. We show that the model trained on the SCMS is able to obtain state-of-the-art vocal pitch extraction results for Carnatic Music. We provide proof and discussion of the importance of the SCMS dataset by running melodic pattern discovery experiments using the improved vocal pitch tracks. The results show that our newly extracted pitch tracks boost the performance on discovering expert annotated melodic patterns, while Melodia is a viable approach only if separated vocal recordings are available. We also note that FTA-Net trained on the available datasets for pitch extraction prior to this work performs very badly and reduces the discovery of Carnatic melodic patterns. From this, we observe there is a need for repertoire-specific data to break the glass-ceiling for the task of vocal melody extraction and subsequent musicologically-relevant computational analysis across a wider range of musical styles from different cultural contexts. In future work we aim at updating the data generation method with latest repertoire-specific technologies, targeting a cleaner version of the SCMS. We are also interested in properly extending the proposed methodology to the Hindustani tradition and if possible, to other repertoires.
7 Reproducibility
We publish the SCMS in Zenodo (DOI: 10.5281/zenodo.5553925). The implementations for (1) data generation, (2) training FTA-Net with the SCMS, in addition to the pre-trained models for Carnatic Music, are available here: https://github.com/MTG/carnatic-pitch-patterns. Also, we include code to run the experiments and visualizations in the paper. The expert pattern annotations are made available in the repository. Both SCMS and FTA-Carnatic have been integrated into compIAM to be used out-of-the-box.
Notes
[2] In this work we use multi-track to refer to completely separated instrument recordings, and close-microphone for a multi-track scenario with leakage (typically recorded live or in the same room).
Acknowledgements
We gratefully acknowledge the significant contribution to this paper made by the professional Carnatic vocalist and musicologist Brindha Manickavasakan who created the sañcāra annotations used in one of the evaluation procedures.
Funding Information
This work is funded by the Spanish Ministerio de Ciencia, Innovación y Universidades (MCIU) and the Agencia Estatal de Investigación (AEI) within the Musical AI Project – PID2019-111403GB-I00/AEI/10.13039/501100011033.
Competing interests
The authors have no competing interests to declare.