
(1) Needs for Web Archive Data in Research
Web archive initiatives across the world have archived web content for nearly three decades. These huge data repositories carry a big potential for knowledge production in academia and beyond. However, researchers have described significant problems when trying to access and make use of web archives in research. Their difficulties involve technical complexities of working directly with the Web ARChive (WARC) file format, WARC’s relatively flat and crawl-job oriented organisation of data, legal issues affecting access, and not least the lack of meaningful metadata. Consequently, leading scholars have started to advocate that WARC data must be reordered to meet the information needs of researchers and provided through dedicated research infrastructures (Schafer & Winters, 2021, 141–42; Ruest et al., 2022, 216–17; Vlassenroot et al., 2019; Milligan, 2016, 79–81; Maemura, 2023, 12; Brügger, 2021, 217–221).
As an answer to these challenges, this article describes a pilot study at the National Library of Norway (NB) investigating how text can be extracted from WARC and offered as data for digital text analysis. This resulted in the first version of a “Web News Collection”, containing 1.5 million news articles from the Norwegian Web Archive (NWA). The collection is offered as data available via an open API, allowing students, scholars and others to tailor their own corpora and study the content of web news at scale, either with computational notebooks or easy-to-use web applications.
The approach appears to be quite novel in the context of web archives. However, it is based on methods and techniques well-known from Natural Language Processing (NLP) and more than 10 years of experience developing research infrastructure for digitised collections at NB’s Laboratory for Digital Humanities (DH-lab). The solution allows for a variety of approaches associated with ‘distant reading’, aligning with the FAIR principles while also taking immaterial rights into account (Birkenes et al., 2023, 30–34).
The article will first outline how we transform WARC data into text data for digital analysis. This includes extracting natural language from WARC, curating and filtering news publications, and preparing the text for computational analysis through an open API. Next, some main results and statistics are shared, with examples of how the web apps and computational notebooks can be used to analyse the collection’s content. This includes an evaluation of how well the collection satisfy demands from a growing community promoting ‘Collections as Data’ from GLAM Labs, including recommendations on best practices for making data available (Padilla, 2017; Candela et al., 2023b). Finally, we reflect on some of the key opportunities and constraints for scholarly use of the “Web News Collection”, and the possibilities for future improvements of the warc2corpus pipeline.
(2) Reframing WARC data for Computational Text Analysis
Web archives store collected content in the WARC format. This is a container format, with each WARC file usually holding tens of thousands of individual records – the basic items in web archives. These are transcripts of HTTP transactions between the harvesting client and various web servers (International Organisation for Standardisation, 2017; International Internet Preservation Consortium, 2022). Consequently, we can regard WARC collections as “transcripts of computer dialogues” (Tønnessen, 2024a, 4–5).
There are several strengths to this design, especially for purposes of automated recording and preservation. Nonetheless, WARC poses serious challenges for human scholars with desires to study their content. First, stored in a binary format, it is hard to directly inspect and analyse their content, as one first needs specialised tools to parse it into human-readable formats. Second, WARC’s relatively flat organisation, with a chronological and crawl-job oriented order, makes it difficult to scope data based on specific websites or other attributes. And third, the metadata contained in the WARC header is highly machine-centric, with almost no metadata relating to its content (Tønnessen, 2024a, 3–4). As information scientist scholar Emily Maemura precisely concluded in her study of the WARC format’s design: “WARC data alone does not meet the information needs of researchers — knowledge production requires re-ordering WARC data through additional labour, resources, and conceptual reframing” (Maemura, 2023, 12). Accordingly, the rest of this chapter describes our methodical approach to reordering and reframing WARC data for the purpose of digital text analysis.
(2.1) Extracting natural language from WARC
Before WARC data can be used for text analysis with NLP techniques, it is necessary to prepare it in several steps. We have therefore developed a pipeline called warc2corpus, with three main phases: (a) extraction of natural language from WARC, (b) curation and filtering, and (c) tokenisation and segmentation (Figure 1).
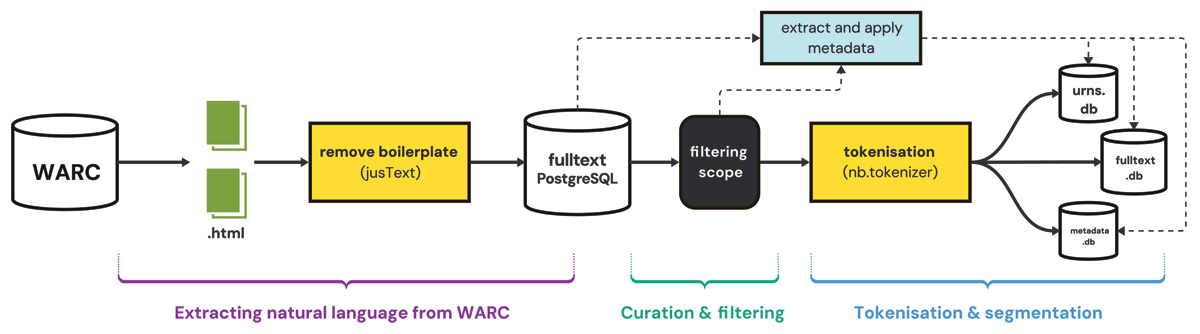
Figure 1
The key steps of the warc2corpus pipeline.
Conceptualising the first phase as “Extracting natural language” implies several aspects. First, it involves parsing WARC data into text objects. For this, we use the warcio library for Python which appears to be the most common tool for parsing from WARC, filtering all records with ‘content-type: text/html’ and status code 200. Second, we need to do more than stripping the HTML for markup. These pages typically contain a lot of boilerplate content, like navigation elements, menus, footers, link lists and more. While search engine indexes would often keep such information to maintain a high recall, computational text analysis that seeks to evaluate use of language requires us to prioritise precision, cleaning everything that is not actual content (Sanderson et al., 2010; Manning et al., 2009). Our tool to remove boilerplate from HTML is jusText (Pomikálek 2011) which does this job quite well. The result of jusText is a list of text blocks containing natural language, such as headings and paragraphs. These text blocks form the base for the following web news collection. jusText further does a very good job with filtering languages, including Norwegian Bokmål and Nynorsk and the Sami languages (for which we added models), meaning that we simultaneously generate metadata that are valuable to many researchers (Vogels et al., 2018).
Performing boilerplate removal across the different NWA subcollections fulfils another important aspect: reordering WARC data to escape web archives’ common segmentation of data into crawl jobs. In general, the crawl job-oriented bucketing of data mainly serves to document archival provenance, but consequently, resources from specific sites are spread all across the archive. For studies concerning specific actors or publications, this is a big disadvantage, because it is hard to identify and include all resources from a specific domain at scale. By building a giant database of natural language full-texts, we make it a lot easier to find all texts from a specific domain across the NWA collection (Tønnessen, 2024a, 4–6).
(2.2) Curating and Filtering News Websites
Curating a collection of news texts from the full-text database involves important choices around scope, temporal range, and selection criteria. Such decisions will fundamentally shape the dataset and its potential as a resource for research. For news content, which typically interacts with and represents various political discourses, there is a significant risk of producing collections with biases favouring certain viewpoints, inherently discriminating others (Beelen et al., 2023).
One methodical approach to reduce such biases is to perform an Environmental Scan, contextualising the news publications in their ‘ecology’ (Beelen et al., 2023, 2). Inspired by this, we collected archived versions of six different websites that over the last 20 years have offered comprehensive lists of links to news websites. From these, we extracted publication titles and associated domain names, combining them into a dataset of 382 news publications online called NorWebNews. This approach both enabled semi-automated curation and ensured a large degree of representativeness, with regard of which titles has been widely shared and promoted in the web ‘ecology’ (Tønnessen, 2022).
Another key consideration in curation has been legal restrictions, which is very common for collections from Legal Deposit libraries (Bingham & Byrne, 2021; Cadavid, 2014). Legislative preparations of the June 2015 Norwegian Legal Deposit Act made an important distinction between publications with editors declaring legal responsibility for their content and publications without such. If an editor has declared such responsibility, the publication title is regarded as part of edited public debate and its content considered as widely known, with privacy matters already being considered by the responsible editor. This content can be made available to library users within the limitations of immaterial property rights (Familie- og kulturkomiteen, 2015, 4–9; NOU 2022). Aligning with the NWA’s access categories, the main selection criterion for this collection is that its content has been published by an editor declaring legal responsibility. In practice, this specifies the collection scope to “edited journalistic media” (NOU 2022, 239).
Information about responsible editors is by no means present in WARC metadata. Neither is it structurally declared in the HTML headers or metadata of such websites. However, inspecting the content from front pages of various news sites, we recognised patterns of semantic information and links that enabled a rule-based approach to classify this automatically. Based on regular expressions and link targets, we developed a tool we call autoCat2.1 Running front pages from websites in the NorWebNews dataset through this tool resulted in a data set with 268 publication titles, from which we could use domain names to filter texts from the NWA full-text database (Tønnessen, 2024b; Tønnessen & Langvann, 2024).
(2.3) Preparing Text Data for Computational Analysis
After having extracted natural language from HTML using jusText, we fingerprint each resulting document using a hashing algorithm (in our case: sha1, which is fast and fairly collision resistant). In this way, we can identify exact duplicates across collections. Note that texts that are almost identical are not captured in this way. Fuzzy deduplication approaches like Simhash or Minhash (cf. Schäfer & Bildhauer 2013, 61–63 for an accessible introduction to near duplicate detection in web corpora), where similar hashes correspond to similar texts, are fruitful for this purpose and fairly easy to implement, but such methods were not used for this pilot study. Thus, the collection still presumably contains a certain number of texts that are near duplicates. Each unique text document according to this definition is assigned a persistent ID.
For each unique document, we used language detection to establish the language in which the document was written. We used the well proven TextCat algorithm (Cavnar & Trenkle, 1994), utilising rank differences in n-grams, as implemented in the pytextcat package, originally developed at the Arctic University of Norway (UiT), and packaged by the National Library of Norway.2
For each duplicate text with the same domain and URL path, we keep the first occurrence of a given text entity, excluding later crawls of the exact same text and URL. Thus, if the exact same text is found on a different path on the very same domain, this text will currently be kept. The same applies to a copy of the same text on another news domain. For cases where the researcher only wants to study unique texts, one needs to establish heuristics for handling this. However, by not excluding such texts, we maintain the possibility to study various forms of republishing.
For each unique document, we segment the text string into tokens using a Norwegian tokeniser (nb_tokenizer).3 In this way, e.g. punctuation is separated from words and abbreviations and numbers with spatial thousand separators are treated as one item (Figure 2):
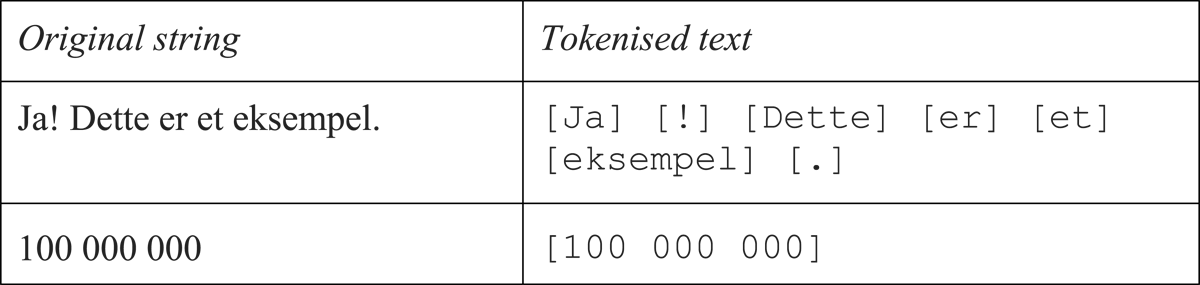
Figure 2
Comparison of text before and after tokenisation. Text within square brackets [] indicating separate tokens.
In the pilot study, we used this tokeniser for all texts in the collection. In a final version, the choice of tokeniser should depend on the language used.
Finally, the resulting documents and metadata are inserted into an SQLite database, similar to the other documents at NB DH-lab. We use both a row-oriented table where each token of a text is stored on a separate row (and indexed using a traditional B-tree index) and a NoSQL-oriented approach where each document is stored in a blob and typically retrieved using an inverted index. In this way, we strike a balance between performance and precision.
A description of the collection and data has been published to a dedicated web page (National Library of Norway, 2024a). This includes key statistics about size, languages and titles, references to the API with a table of the different properties, descriptions and example values, as well as links to different tools for utilisation: the dhlab Python package, a Jupyter notebook and web apps. From the landing page, one can also find links to downloadable metadata in both Dublin Core and D-CAT formats, citation examples and downloadable files (RIS and XML) for the most common reference management systems.
(2.4) Indigenous languages and CARE principles
As Norway’s legal deposit library, NB carries a responsibility to preserve not only Norwegian Bokmål and Norwegian Nynorsk, but also Norway’s indigenous languages (Northern Sámi, Lule Sámi, Southern Sámi) and Kven. By including news texts in all these languages, on the same terms as for Norwegian Bokmål and Norwegian Nynorsk, we highlight that Sámi and Kven news content has an intrinsic value and are also part of Norway’s cultural heritage. The automatic identification of these languages was made with the already mentioned language technology delivered by UiT’s Research Group for Sámi Language Technology: Giellatekno. These efforts aim to facilitate research on indigenous and minority languages, in line with the CARE principles (Carroll et al., 2020, 1–12).
(3) Collection Description
The ‘Web News Collection’ is a curated collection of text data from edited journalistic web publications, extracted from the Norwegian Web Archive. Its first version includes more than 1.5 million texts from 268 online publication titles, harvested by the National Library of Norway between 2019 and 2022.4
Repository location
Repository name
DH-lab
Object name
“Web News Collection” (retrieved with doctype:“nettavis”)
Format names
SQLite, JSONL
Creation dates
Start: 2022-09-15 End: 2024-09-02
Dataset creators
Magnus Breder Birkenes, Jon Carlstedt Tønnessen, Trym Bremnes (National Library of Norway).
Languages
Mainly Norwegian Bokmål (nob), Norwegian Nynorsk (nno) and Northern Sámi (sme), plus some Danish (dan) and English (eng).
Publication date
2024-09-02
(4) Implementation and Results
The collection is part of the NB DH-lab research infrastructure, accessible via dh.nb.no. The infrastructure is built around the portable database system SQLite where each database holds a certain number of documents, making it easy to scale horizontally, i.e. we can easily add new documents without having to re-index complete collections.
NB is the legal deposit library in Norway, mandated by the Norwegian Legal Deposit Act to preserve cultural heritage and offer it for research and documentation. To ensure long-term preservation and access, and to prevent accidental loss of data, we make regular backups of both the DH-lab databases and the source code for the API. Further, each text derivative is versioned, enabling both NB and end users to track potential changes over time. The same applies for the API source code, which is versioned every time a change is made in source code (National Library of Norway, 2024b).
(4.1) Key Statistics for the Collection
The collection of web news consists of totally 1.57 million documents, comprising 785 million tokens in 268 publication titles. Each unique text has an average length of 500 tokens. It is at present the second largest publicly available web-corpus of online news in Norwegian, after the Norwegian Newspaper Corpus.5 The distribution of languages in the collection is as follows:
| Norwegian Bokmål: | 1 437 768 documents |
| Norwegian Nynorsk: | 111 892 documents |
| Northern Sámi: | 11 416 documents |
| Kven: | 302 documents |
| Southern Sámi: | 101 documents |
| Lule Sámi: | 78 documents |
We notice that Norwegian Nynorsk has a share of approximately 7.2% of all Norwegian documents in the collection. In addition, there is a relatively fair amount of Sámi content, especially in Northern Sámi, where avvir.no is the most notable publication.
Regarding publication titles, the collection has an overweight of national news publications. This is obvious when we list the number of unique texts per publication title:
| NRK: | 130 162 |
| VG: | 66 800 |
| Forskning.no: | 65 469 |
| TV2: | 55 367 |
| Dagens næringsliv: | 50 005 |
| Dagbladet: | 46 333 |
| Finansavisen: | 38 514 |
| Adresseavisen: | 33 640 |
| Aftenposten: | 31 075 |
| Khrono: | 29 794 |
However, there is also a significant amount of local news content in the collection. This opens up for slightly niched but highly interesting research questions, such as how local history is represented in web news.
(4.2) Open Access via API
The collection is made available through a the REST API at DH-lab of the National Library of Norway.6 Due to the data being in copyright, we cannot distribute complete documents for download, but the API provides a way to explore the collection quantitatively without exposing the texts and challenging copyright law.
Through the API, users can get frequency lists for unigrams and bigrams, concordances and collocations for all texts in a given corpus. The concordance window has a hard limit of 25 words and never span across paragraphs. The API itself is mainly used by programmers. Below you will find examples utilising the API in various settings.
(4.3) Examples of Use
(4.3.1) Notebooks with dhlab for Python
To facilitate utilisation, DH-lab has developed a Python package dedicated for analysing data provided through the API. To make advanced computational methods more accessible for scholars and students, we also developed a Jupyter notebook based on the Python package with detailed examples of how one can analyse content from the news collection. This includes tailoring your own text corpora, getting keywords in context, listing words collocated with a keyword and calculating the relative frequency of these collocates (Tønnessen, 2024c). The notebook also has functionality for visualising some main aspects of the corpus that is built, showing the distribution of publication titles, languages and timestamps (Figure 4).
Users can build corpora using different types of metadata, as well as keywords or phrases. They will then get a data frame in return with metadata about the individual text objects in their corpus. This data frame has basic information that is important for FAIR and reproducibility, such as the texts’ unique identifiers, the original objects’ URNs in the web archive. Further, it has several fields of meaningful metadata, like information about each text’s publication title, the domain name and URL from where it was harvested, harvesting date, the text’s language and the place name of the editorial board’s location (Figure 3). The information in the data frame can be exported to file (CSV, Excel or JSONL) to maintain further use and reproducibility, especially addressing the FAIR requirements for Findability and Reusability, as well as facilitating Accessibility and Interoperability.
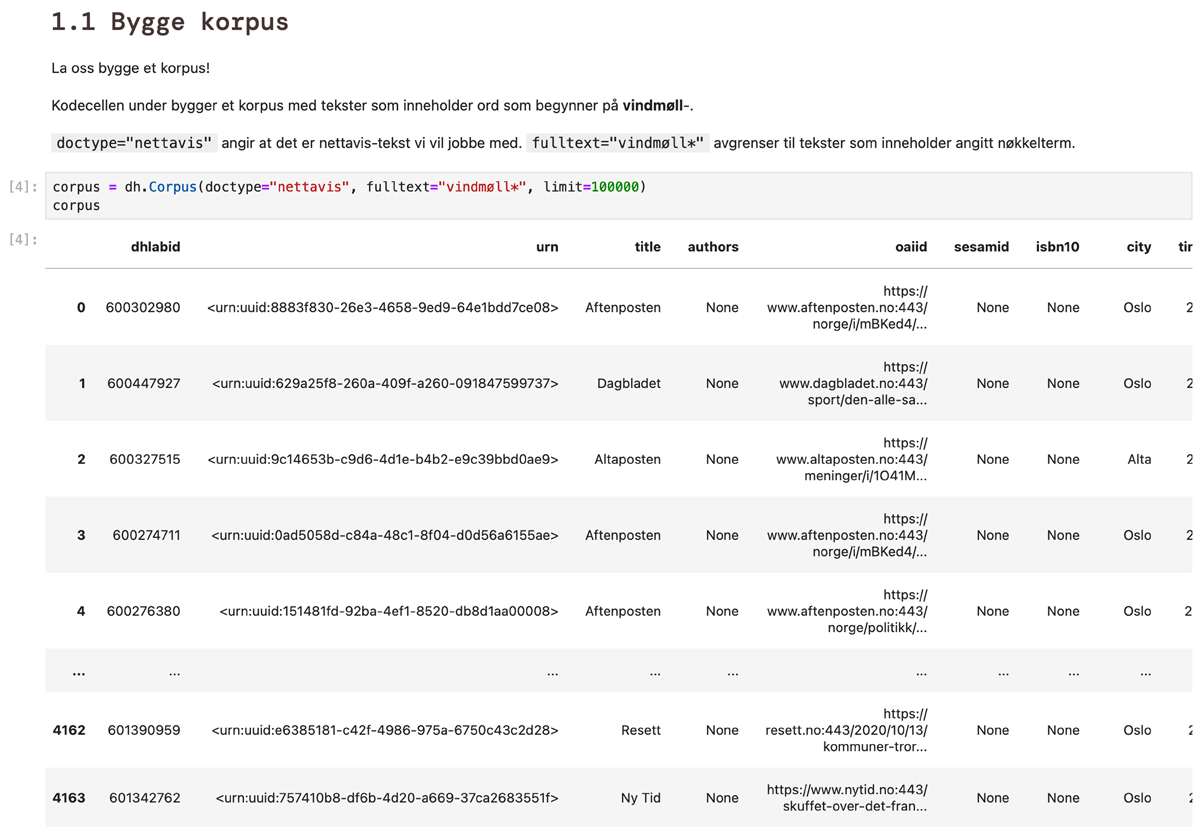
Figure 3
Displaying the dhlab data frame in a notebook.
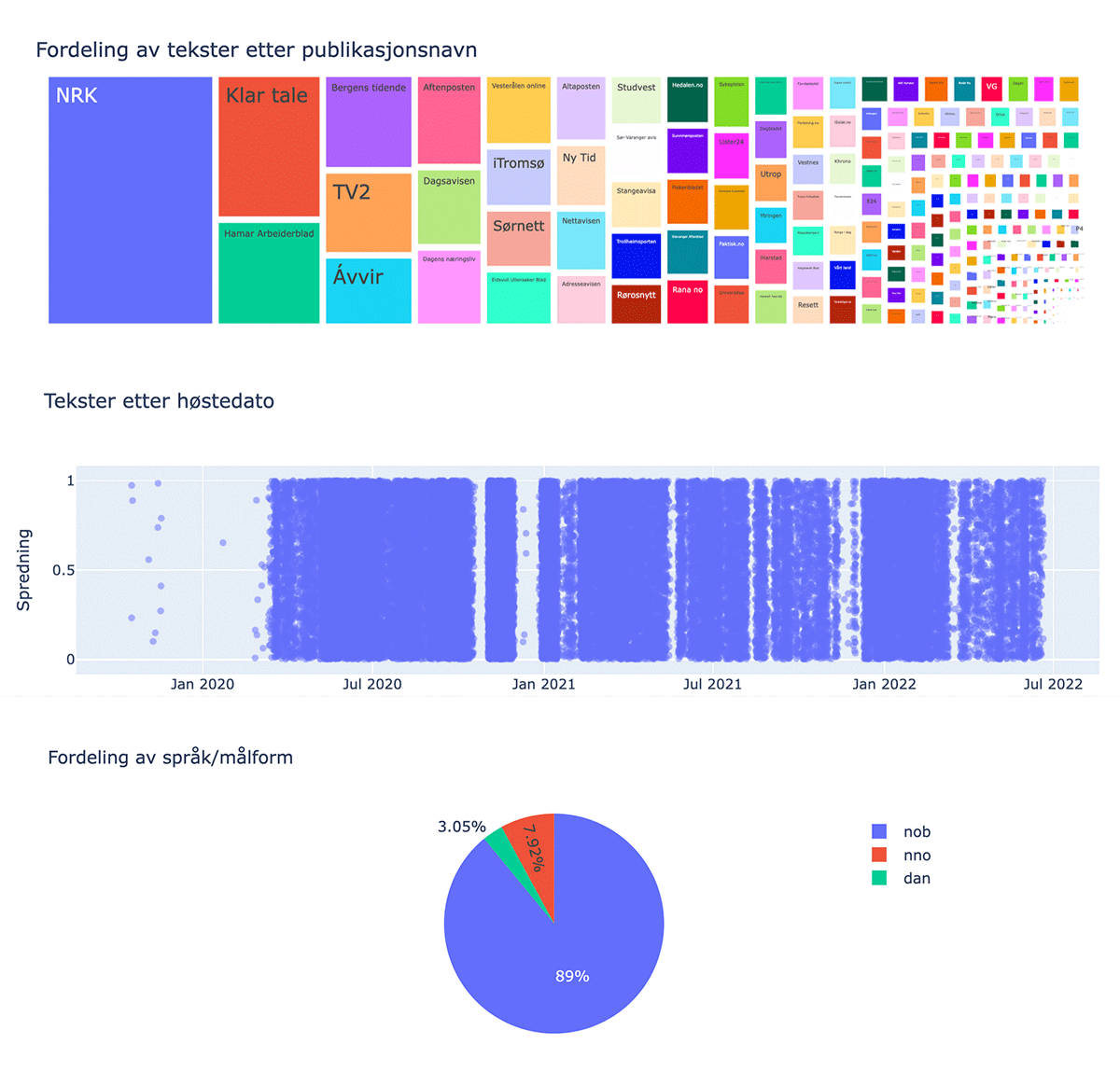
Figure 4
Visualising a corpus’ distribution of titles, harvesting dates and language.
(4.3.2) User-Friendly Webapps
Many scholars in the Humanities and Social Sciences are uncomfortable using notebooks and scripting. DH-lab has therefore developed various web applications with a point-and-click interface, providing access to computational analysis and ‘distant reading’ for researchers without scripting skills (DH-lab, 2024). Nonetheless, the main functionality and computational processing beneath are in principle the same as in the notebooks.
To demonstrate and test the functionality, we involved a researcher studying web discourses on the covid-19 pandemic. The researcher first built a corpus of 20,000 randomly sampled texts containing “korona” or “covid-19” from 2020–2021. After uploading the corpus’ metadata file in the web app for collocation analysis, the researcher searched for words collocated with “press conference” and got returned a list of its most frequent collocated words. Weighed against a reference corpus to calculate relative frequency, a variety of words related to health authorities appeared as highly frequent collocates, indicating that news descriptions to a large extent focused on the role of health authorities when reporting on press conferences (Figure 5).
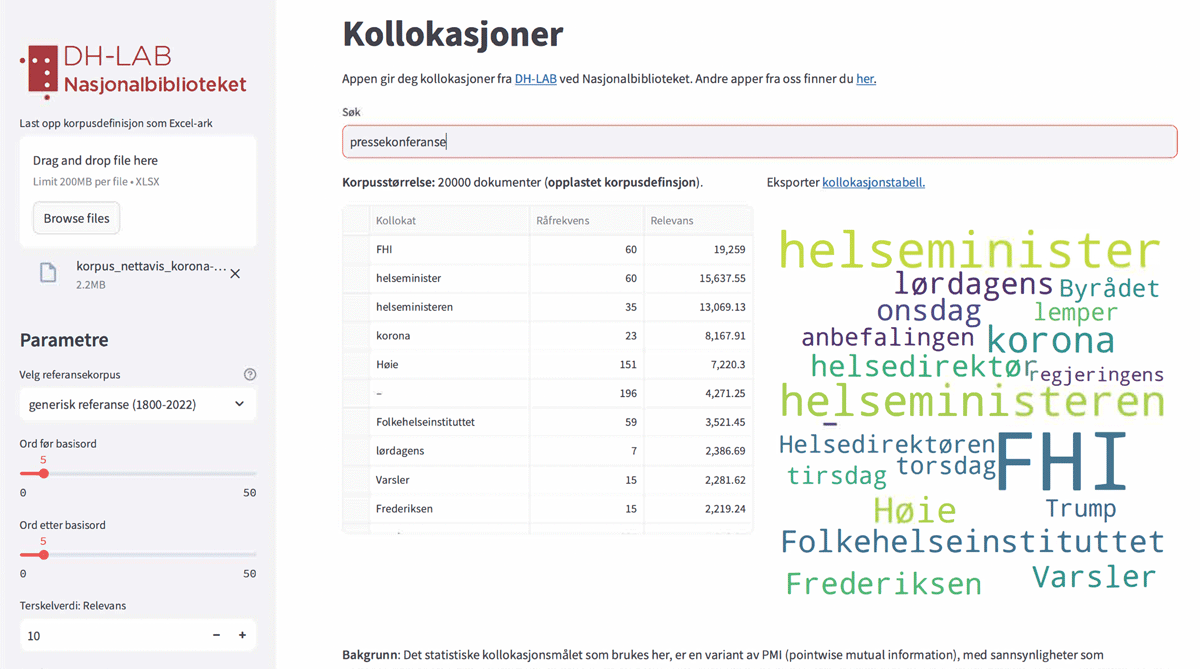
Figure 5
Interface of web application for collocation analysis. To the left, one can upload an Excel file with a corpus definition and adjust parameters. In the centre, one enters a keyword to retrieve the most frequent collocated words, before it is outputted in form of a table and a word cloud visualisation.
(4.4) Evaluation and Quality Assessment
(4.4.1) GLAM Labs’ Checklist
The International GLAM Labs Community provides a checklist for publishing collections as data. This seems to be the closest we get to a definition of best practices for sharing collections as data, and a good framework for evaluating how the Web News Collection satisfies common expectations and needs (Candela et al., 2023a, 7–14).
When evaluating this first version of the ‘Web News Collection’, we found that it satisfies nine out of eleven items on the GLAM Labs’ checklist. For example, we are providing:
– documentation about the collection and its creation,
– API access and a portal page.
– examples of use in computational notebooks, as well as user-friendly web-apps,
– suggestions for citation, with downloadable .ris and .xml files for the most common reference managing systems,
– machine-readable metadata, both as .xml for Dublin Core and .jsonl for DCAT,
Scoring 10 out of 11 appears to be a relatively good result for a legal deposit library, compared to a recent case study from the GLAM Labs community, indicating that the Web News Collection are very close to best practices in the field (Candela et al., 2023a, 13).
Using the GLAM Labs’ checklist for evaluation, we found that it is currently designed for cultural heritage collections where content is in the public domain. However, most of the records in web archive collections – even if published openly and free of charge – will be covered by copyright. Even if the data are provided with an objective to not violate immaterial rights, the checklist’s requirement of a licence that allow for reuse without any restriction are currently hard to satisfy (Candela et al., 2023a, 13). This implies that also best practice recommendations can be improved and maybe developed in close dialogue with practical applications like our own.
(4.4.2) Assessing the Quality of Jupyter notebook
The same community has published a framework to assess the quality of Jupyter projects, including computational notebooks like the one developed for the “Web News Collection”. Based on specific evaluations criteria for five different dimensions, one can evaluate the quality of such notebooks by calculating a quality score (Candela et al., 2023a, 1554–1558). When assessing the quality of the current version of the notebook (v0.4.1-alpha), it scores 11,70 out of possible 13, which is far above the average results of GLAM institutions’ notebooks from a recent examination by Candela et al. (2023a, 1559). To improve the score any further, two measures would need to be taken: (a) providing the notebook in multi-lingual versions and, (b) providing information on when the notebook was last used.
(5) Implications and Future Development
(5.1) Opportunities and Benefits
Even if NB has gathered web content for more than 25 years, access has until recently been non-existing. Leading web archive researchers have actually described former restrictions on access to the Norwegian Web Archive as “very restrictive” (Brügger & Schroeder, 2017, 10). The “Web News Collection” and its accompanied tools for analysis radically changes this situation, enhancing accessibility not only for scholars, but also for students and others, independent of their location.
Improved access opens for several new approaches to research and education. First, it will provide new possibilities to research discourses in the Norwegian public sphere online. With the collection spanning from 2019–22, it includes news about several major events, such as the covid-19 pandemic, the 2021 Parliamentary elections, and the 2022 Russian invasion of Ukraine. Second – by providing access to this data for anyone and anywhere – opportunities for students and lecturers to make use of web archives in education are largely increased. The Web News Collection together with its associated tools aims to support use in students’ theses as well as University seminar rooms, especially relevant for courses that engages with Digital Humanities or Computational Social Sciences, as well as flipped-classroom pedagogics.
(5.2) Challenges and CONSTRAINT
There are several challenges and constraint associated with this collection. One core aspect is well-known to its creators, but not necessarily intuitive to researchers without experience of web archives: timestamps are not necessarily the date of publication. Derived from the WARC-Date field, the timestamp represents the date for harvesting. This is typical for content in web archives that are subject to passive depositing, rather than older forms of active depositing from the publisher (Tønnessen, 2024a). From random samples, it seems that harvesting timestamps is at average one day after publishing date, important for researchers and others to be aware of. There are also packages like htmldate (cf. Barbaresi 2020) that can be used for finding the publication date of websites using HTML headers and content parsing.
Another constraint is that texts are currently only available in the form of data derivatives. Users who want to inspect a specific text in its original context – using a replay service like Wayback Machine – would need to wait until NB has indexed its content for replay. Such functionality exists for NB’s collections of digitised books and newspapers and are appreciated by scholars, especially those who combines distant reading with more qualitative approaches.
Further, there are no metadata about characteristics that are typical for web content. With information about outgoing links, or metadata about image elements, one could enable a variety of approaches to analysing these texts in their contexts, including multimodal aspects. For news content, this would be very valuable, as they are indeed multimodal when published on the web. Nonetheless, this collection only allows for certain types of text analysis.
(5.3) Future Research and Development
The current collection comes with several uncertainties that deserves closer examination. For example, what is the ratio of articles vs front pages? It is possible for a web archive to harvest front pages very often and, more rarely, dive deeper to get the articles of these publications. Knowing more about the ratio of articles vs front pages would be valuable for researchers using the collection for analysis. Another matter to examine would be text similarity. While we have deduplicated identical texts from the same domain, we expect there to be identical texts across publication titles and domain names. We further anticipate that there are texts in the collection with the same URL or from the same domain name that are close to identical but that, because of insignificant edits, still result in different hash values and are kept as different versions.
For a second version of this collection, expanding its chronological scope to include news texts from as early as 2005, would significantly increase its value for research. A great deal of this content is long gone from the live web. Curating such a collection would benefit from the establishment of a historical database with a record of Norwegian news publications online, tracking their continually changing domain names and titles, and other associated metadata.
Notes
[1] The autoCat2 tool iterates over a set of front pages, looking for regular expressions (variations of “Responsible editor: [name]”) and links to the Ethical Code of Practice. When tested on a data set with 300 front pages to determine if a site declared a responsible editor, the tool produced 0% false positives and 3% false negatives. Fourteen percent of pages were flagged as uncertain (0.3 ≤ conf_score ≤ 0.7), requiring manual classification.
[4] The limited chronological scope of this first iteration, including only texts harvested between 2019-01-01 and 2022-06-01, is caused by a desire to develop the warc2corpus pipeline iteratively and incrementally. This reduces the cost of computation and labour, when discovering needs for refinement and reconfiguration, and makes it easier to establish good practices for quality assessments, ensuring data and metadata quality. In a future where all news content back to 2005 are included, the ‘Web News Collection’ are guesstimated to include 10–20 times the number of texts.
[5] Accessible from the Norwegian Language Bank Resource Catalogue. See https://hdl.handle.net/21.11146/4.
Competing Interests
Both authors are affiliated with the National Library of Norway which owns and controls the data used in the pilot study.
Author Contributions
Jon Carlstedt Tønnessen: Conceptualisation, Methodology, Software, Visualisation, Validation, Writing.
Magnus Breder Birkenes: Conceptualisation, Methodology, Software, Validation, Writing.