
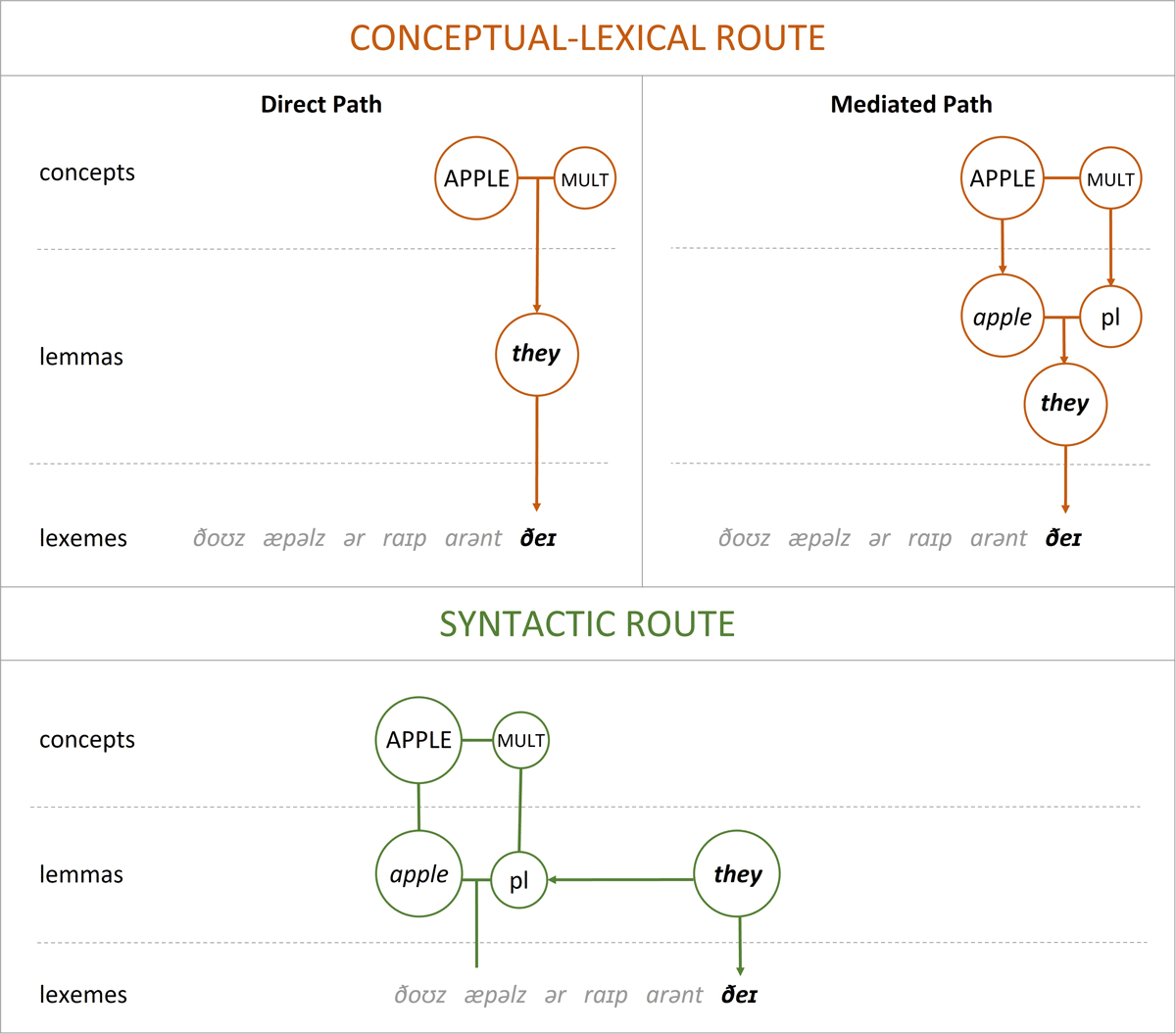
Figure 1
Summary of the two routes to determine pronoun form in production.
Note. The figure demonstrates the two routes for selecting the pronoun they in the sentence Those apples are ripe, aren’t they?. Abbreviations: “MULT” denotes the concept of multiplicity, and “pl” denotes a grammatical plural feature. In the conceptual-lexical route, the concepts APPLE and MULT provide the features for the pronoun “they”, either directly (Direct Path) or through activating the corresponding representations at the lemma level (Mediated Path). In the syntactic route, the features for the pronoun “they” are accessed from the lemma-level representations corresponding to the linguistic antecedent “apples”.
Table 1
Example target sentences in Experiment 1.
| CONDITION | TARGET SENTENCE |
|---|---|
| SS – match | El chaleco ha pipeado el candado (de) debajo de él The vest has pipped the lock below it |
| SP – mismatch | El chaleco ha pipeado los candados (de) debajo de él The vest has pipped the locks below it |
| PP – match | Los chalecos han pipeado los candados (de) debajo de ellos The vests have pipped the locks below them |
| PS – mismatch | Los chalecos han pipeado el candado (de) debajo de ellos The vests have pipped the lock below them |
[i] Note. The antecedent and coreferential pronoun are bolded, while the attractor is underlined. The preposition “de” before the adverb “debajo” is shown between parentheses to reflect its optional status: In pilot testing, some Spanish speakers prefered to produce it, while others didn’t (Supplemental file 1). Therefore, both utterances with and without the preposition were accepted as target responses in Experiment 1. Abbreviations: SS = singular antecedent, singular attractor, SP = singular antecedent, plural attractor, PP = plural antecedent, plural attractor, PS = plural antecedent, singular attractor.
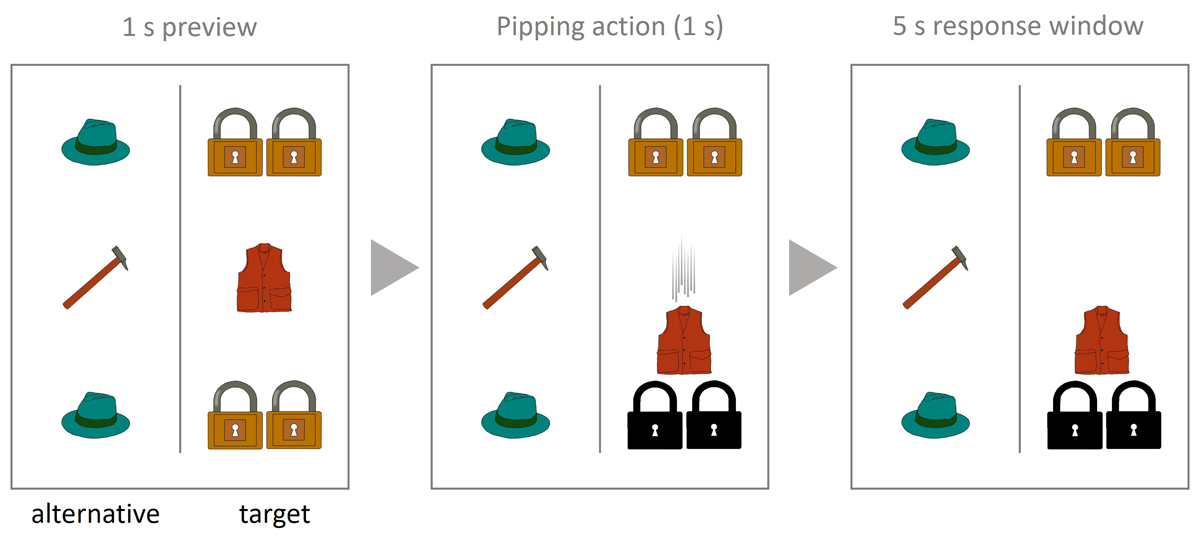
Figure 2
Example of a visual display in Experiment 1.
Note. The display corresponds to the target sentence “El chaleco ha pipeado los candados debajo de él” (‘The vest has pipped the locks below it’). A trial consisted of a 1 second preview, the pipping action, and then a 5 second response window in which participants had to describe the action.

Figure 3
Example of a target response with its division into segments.
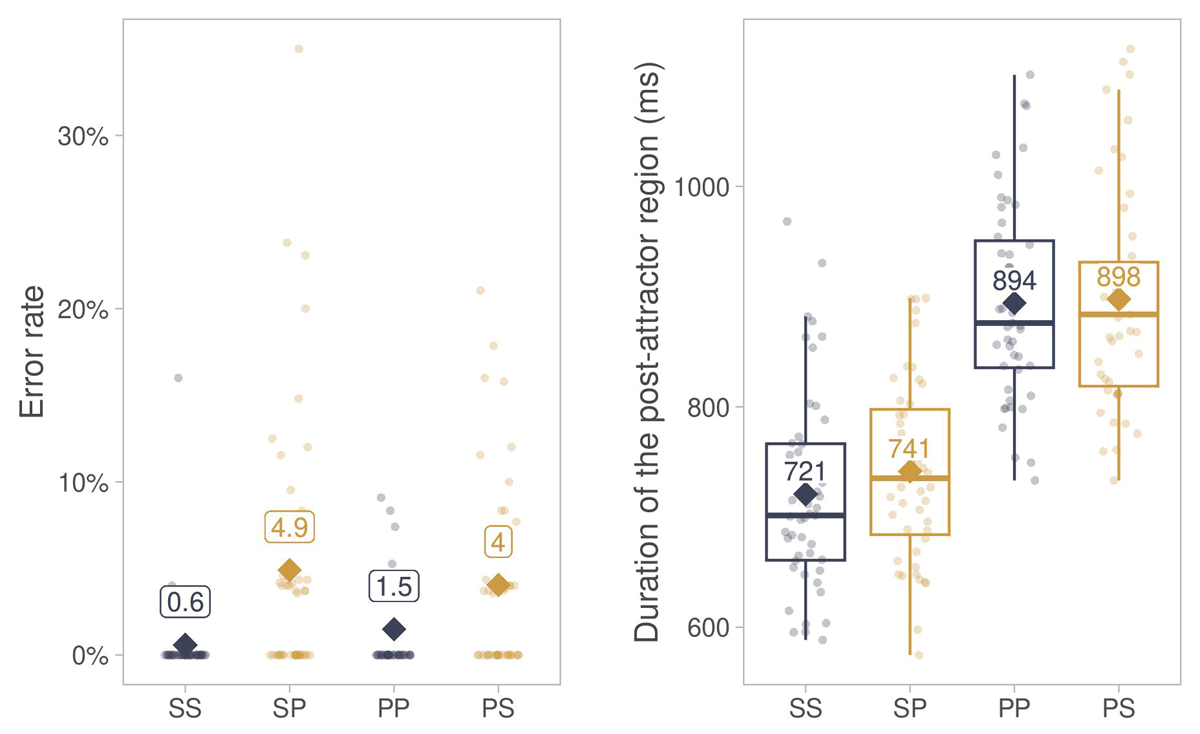
Figure 4
Descriptive summary of error rates and durations of the post-attractor segment in Experiment 1.
Note. Diamonds show averages across participants in match (SS, PP) and mismatch (SP, PS) conditions. Points show by-participant averages. Abbreviations: SS = singular antecedent, singular attractor, SP = singular antecedent, plural attractor, PP = plural antecedent, plural attractor, PS = plural antecedent, singular attractor.
Table 2
Output of the Experiment 1 error analysis model.
| COEFFICIENT | ESTIMATE | STANDARD ERROR | z-value | p-value |
|---|---|---|---|---|
| Intercept (grand mean) | –4.430 | 0.234 | –18.939 | < 0.001 |
| Trial Order | –0.004 | 0.003 | –1.368 | 0.171 |
| Antecedent Number | 0.487 | 0.309 | 1.577 | 0.115 |
| Match | 1.651 | 0.260 | 6.350 | < 0.001 |
| Antecedent Number × Match | –1.158 | 0.512 | –2.259 | 0.024 |
[i] Note. Model formula: Number Error ~ Trial Order + Antecedent Number * Match + (1 + Antecedent Number * Match || Participant) + (1 + Match || Item). A positive coefficient for Antecedent Number reflects more number errors with plural than singular antecedents. A positive coefficient for Match reflects a greater likelihood of number errors for mismatch than match conditions. The double bars in the model formula represent the removal of the correlation between random slopes and intercepts.
Table 3
Output of the Experiment 1 latency analysis model.
| COEFFICIENT | ESTIMATE | STANDARD ERROR | t-value | p-value |
|---|---|---|---|---|
| Intercept (grand mean) | 6.684 | 0.013 | 527.406 | < 0.001 |
| Trial Order | –0.000 | 0.000 | –2.654 | 0.008 |
| Syllable Count | 0.096 | 0.004 | 25.513 | < 0.001 |
| Antecedent Number | 0.158 | 0.006 | 25.98 | < 0.001 |
| Match | 0.015 | 0.004 | 3.941 | < 0.001 |
| Antecedent Number × Match | –0.020 | 0.013 | –1.489 | 0.143 |
[i] Note. Model formula: log(Duration) ~ Trial Order + Syllable Count + Antecedent Number * Match + (1 + Antecedent Number * Match | Participant) + (1 + Antecedent Number * Match | Item). A positive coefficient for Antecedent Number reflects longer durations for post-attractor segments with plural than singular antecedents. A positive coefficient for Match reflects longer durations for mismatch than match conditions.
Table 4
Example target sentences in Experiment 2.
| CONDITION | TARGET SENTENCE |
|---|---|
| MM – match | El chaleco ha pipeado el candado (de) debajo de él The vestMASCULINE has pipped the lockMASCULINE below it |
| MF – mismatch | El chaleco ha pipeado la medalla (de) debajo de él The vestMASCULINE has pipped the medalFEMININE below it |
| FF – match | La medalla ha pipeado la lámpara (de) debajo de ella The medalFEMININE has pipped the lampFEMININE below it |
| FM – mismatch | La medalla ha pipeado el candado (de) debajo de ella The medalFEMININE has pipped the lockMASCULINE below it |
[i] Note. The antecedent and coreferential pronoun are bolded, while the attractor is underlined. Abbreviations: MM = masculine antecedent, masculine attractor, MF = masculine antecedent, feminine attractor, FF = feminine antecedent, feminine attractor, FM = feminine antecedent, masculine attractor.
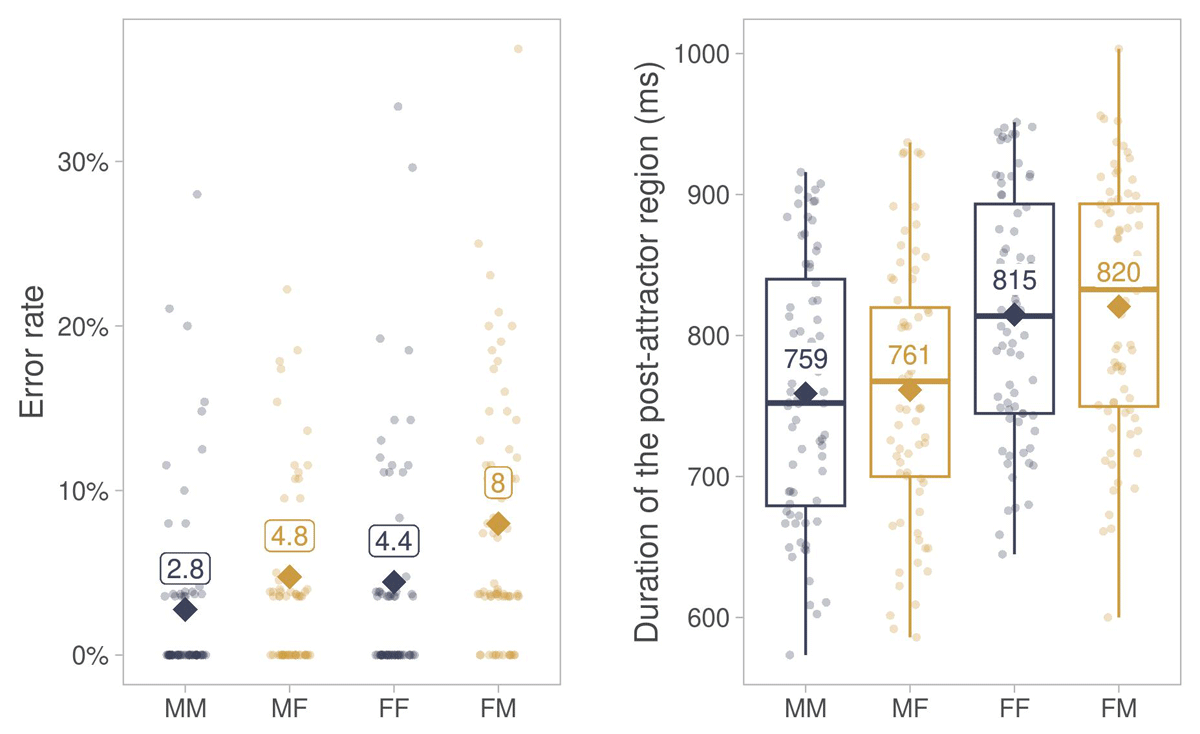
Figure 5
Descriptive summary of error rates and durations of the post-attractor segment in Experiment 2.
Note. Diamonds show averages across participants in match (MM, FF) and mismatch (MF, FM) conditions. Points show by-participant averages. Abbreviations: MM = masculine antecedent, masculine attractor, MF = masculine antecedent, feminine attractor, FF = feminine antecedent, feminine attractor, FM = feminine antecedent, masculine attractor.
Table 5
Output of the Experiment 2 error analysis model.
| COEFFICIENT | ESTIMATE | STANDARD ERROR | z-value | p-value |
|---|---|---|---|---|
| Intercept (grand mean) | –3.437 | 0.149 | –23.003 | < 0.001 |
| Trial Order | 0.001 | 0.002 | 0.768 | 0.443 |
| Antecedent Gender | 0.567 | 0.236 | 2.406 | 0.016 |
| Match | 0.730 | 0.144 | 5.068 | < 0.001 |
| Antecedent Gender × Match | 0.051 | 0.229 | 0.222 | 0.824 |
[i] Note. Model formula: Gender Error ~ Trial Order + Antecedent Gender * Match + (1 + Antecedent Gender * Match || Participant) + (1 + Match || Item). A positive coefficient for Antecedent Gender reflects a greater likelihood of gender errors with feminine than masculine antecedents. A positive coefficient for Match reflects a greater likelihood of gender errors for mismatch than match conditions. The double bars in the model formula represent the removal of the correlation between random slopes and intercepts.
Table 6
Output of the Experiment 2 error analysis model.
| COEFFICIENT | ESTIMATE | STANDARD ERROR | t-value | p-value |
|---|---|---|---|---|
| Intercept (grand mean) | 6.658 | 0.010 | 670.802 | < 0.001 |
| Order | –0.000 | 0.000 | –4.275 | < 0.001 |
| Syllable Count | 0.132 | 0.006 | 22.250 | < 0.001 |
| Antecedent Gender | –0.055 | 0.009 | –6.449 | < 0.001 |
| Match | 0.002 | 0.004 | 0.676 | 0.501 |
| Antecedent Gender × Match | 0.003 | 0.006 | 0.446 | 0.657 |
[i] Note. Model formula: log(Duration) ~ Trial Order + Syllable Count + Antecedent Gender * Match + (1 + Antecedent Gender * Match || Participant) + (1 + Match || Item). A negative coefficient for Antecedent Gender reflects shorter durations of the post-attractor segment in feminine than masculine conditions. A positive coefficient for Match reflects longer durations in mismatch than match conditions. The double bars in the model formula represent the removal of the correlation between random slopes and intercepts.