
Publisher’s Note: A correction article relating to this paper has been published and can be found at https://datascience.codata.org/articles/10.5334/dsj-2026-019.
Introduction
In the evolving landscape of data-centric research, effective data skills development is paramount for ensuring data integrity, accessibility, and compliance with the FAIR principles (Findable, Accessible, Interoperable, and Reusable) (Wilkinson et al., 2016). The Carpentries, beginning with Software Carpentry in 1998, pioneered global data skills training through hands-on workshops, evidence-based teaching methods, and openly licensed materials. This community-driven approach to teaching foundational coding and computational skills established influential practices that shaped data education worldwide.
The Schools of Research Data Science (SoRDS) builds directly on The Carpentries’ (Software Carpentry, Data Carpentry, and Library Carpentry—hereafter referred to as ‘The Carpentries’) materials and methods while extending this foundation in critical ways (Jordan, Michonneau and Weaver, 2018). SoRDS integrates technical skills training with research data management (RDM) principles, open science practices, and contextualized approaches designed specifically for early-career researchers (ECRs) in low- and middle-income countries (LMICs). This combination of proven pedagogical methods with expanded scope and targeted context has proven instrumental in equipping researchers with essential data skills while building sustainable capacity in underserved research communities.
The Venn diagram in Figure 1 illustrates the intersection of four foundational domains in data skills education: Open Science, Research Data Management, Data Science, and Research Integrity. At the core of this intersection is the SoRDS, which functions as a central integrative hub combining principles, practices, and training methods from all four areas.
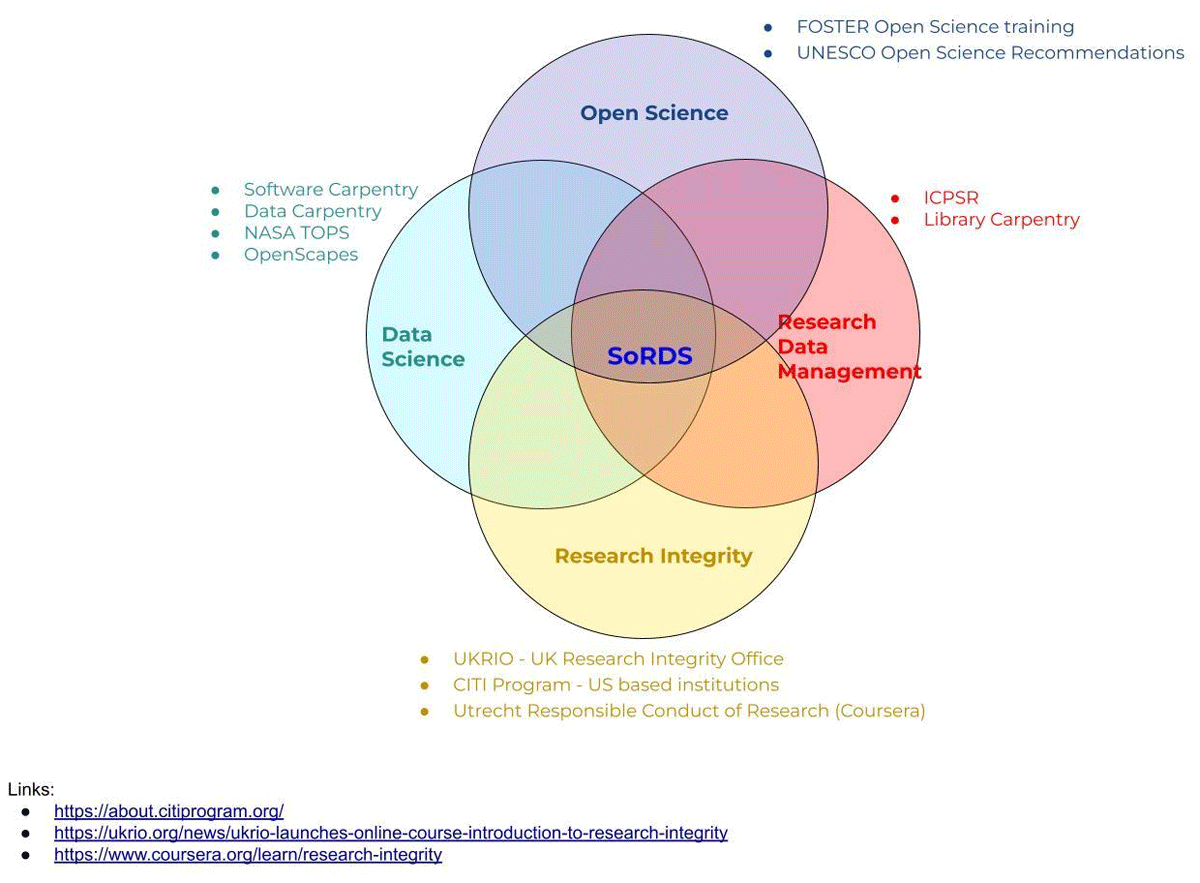
Figure 1
Curriculum design of SoRDS.
This paper adopts a descriptive and reflective methodology that synthesizes a decade of SoRDS programme documentation, internal planning materials, openly available instructional resources, annual reports, alumni newsletters, and publicly accessible GitHub repositories that track the curriculum’s evolution. The historical timeline, curriculum changes, and examples of alumni impact are drawn exclusively from verifiable, publicly documented SoRDS activities.
Overview of Schools of Research Data Science (SoRDS)
SoRDS is an initiative by the Committee on Data (CODATA) of the International Science Council (ISC) and the Research Data Alliance (RDA), established to provide ECRs from LMICs with foundational data science skills essential for 21st-century research. The curriculum is developed entirely based on open source tools and materials. As a structured and comprehensive programme, SoRDS incorporates foundational Carpentries-style skills while also extending into deeper FAIR-aligned RDM concepts and advanced computational topics (Shanahan, Hoebelheinrich and Whyte, 2021). Central to the SoRDS curriculum are Open and Responsible Research Principles for promoting transparency and accessibility in research. It also emphasizes that data should be appropriately managed, preserved, and annotated for future use. This includes analysis techniques that cover statistical methods, machine learning, and data visualization.
The central concept of covering a broad but shallow range of topics in Data Science, RDM, Open Science, and Research Integrity was built in from the first instances of SoRDS. Initially, the schools covered core Carpentries material (Shell, Git, R, and SQL), Data Visualization, Machine Learning, and Computational Infrastructures. Author Carpentry was taught as an optional module in the evenings. In 2017, there was a substantial readjustment of the Research Integrity and RDM materials for better alignment. Based on participant feedback and needs assessment, the curriculum team replaced SQL with Author Carpentry as a core module, recognizing its greater relevance for ECRs.
Ethics exercises for each module were introduced to ensure that the modules always had a reflective component on Research Ethics (Bezuidenhout, Quick and Shanahan, 2020). In 2019, an applied RDM Lab, with a hands-on module in which participants practice core RDM tasks such as metadata creation, data documentation, FAIR assessment, and repository preparation, was introduced alongside an Information Security module. Beginning in 2024, SoRDS also launched a Python-based version of its computational modules, offered in parallel to the original R-focused track. This allowed participants to choose the programming language most relevant to their research context.
Each annual iteration of the school is jointly designed through a structured planning cycle involving curriculum review, participant needs assessment, and evaluation of previous years’ feedback collected through International Centre for Theoretical Physics (ICTP) post-event surveys. Major shifts, such as the integration of ethics exercises in 2017, the launch of the RDM Lab in 2019, and the Python version in 2024, were implemented in response to documented participant feedback and instructor debrief reports.
Participants apply SoRDS-acquired skills in academic instruction, research design, institutional data policy, and regional training. Many advance to leadership roles, acting as multipliers by embedding RDM in curricula, promoting FAIR data, and organizing workshops modeled on SoRDS (Cobe et al., 2023). Institutions have launched certificate programmes or integrated data skills into academic offerings as direct outcomes. For example, University College Cork has developed a standalone module in Data Stewardship that was developed by the team who attended the Data Stewardship course developed by SoRDS (University College Cork, n.d.). These curricula often take the form of multi-module certificate programmes or part-time courses, such as the University of Vienna’s two-semester Data Steward certificate (University of Vienna, 2022), and include competency frameworks recommended by the European Open Science Cloud (EOSC) to professionalize data steward roles (Basalti et al., 2024; Demchenko et al., 2021). Early initiatives highlighted the importance of teaching data science and computational skills in low- and middle-income countries (Shanahan et al., 2015). Also initiatives have explored integrating data literacy and research data management competencies directly into disciplinary curricula, particularly within physics laboratory education (Bode, Jaeger & Schneidewind, 2023a, 2023b). Two-tiered training models have also been proposed to improve researchers’ data management practices (Read et al., 2019). The programme’s adaptable content and delivery suit varied linguistic, infrastructural, and disciplinary contexts, ensuring ongoing relevance. This scalability strengthens individual competencies while building institutional and national capacity for responsible RDM.
Figure 2 illustrates the chronological progression of the SoRDS from its inception in 2016 through to its 10th anniversary in 2025. Each year marked in the timeline represents continued efforts to deliver foundational and increasingly advanced data science training to ECRs. From as early as 2017, SoRDS curricula began integrating advanced topics such as machine learning, computational workflows, data visualization, and reproducible research practices. Based on the programme’s internal archives and the annual planning documents maintained by CODATA and ICTP, which record each year’s curricular updates and structural changes. These topics were taught using real-world datasets and hands-on exercises to ensure deep, practical understanding. Evidence of this progression can be found in the openly available course materials on the CODATA-RDA GitHub repository (CODATA-RDA-DataScienceSchools, 2025), which documents the evolving scope and sophistication of the training content over the years (Quick, Córdoba, Cobe et al., 2023).
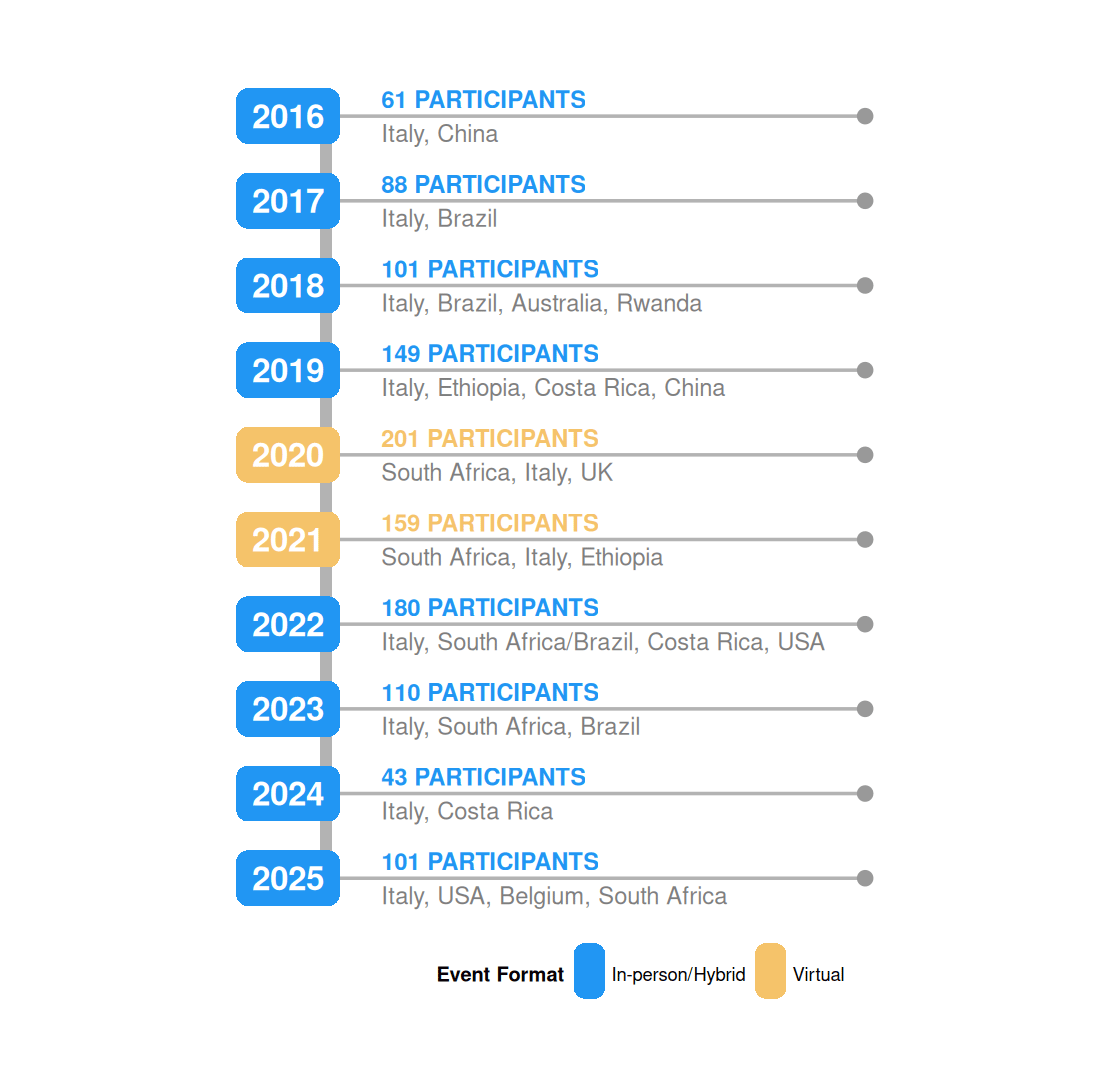
Figure 2
Timeline for SoRDS.
The timeline in Figure 2 underscores number of participants trained each year and the geographic locations where the schools were delivered. It also reflects the programme’s adaptation during the COVID-19 period, when delivery shifted temporarily to virtual formats before returning to in-person and hybrid events. By 2021, over 400 participants from 40 countries had been trained across 10 annual schools (Bezuidenhout et al., 2021). By 2023, this number of participants had grown to over 1,000 ECRs trained in 24 events held in 10 countries worldwide (Quick, Córdoba, Diggs et al., 2023), reflecting both the programme’s expansion and diversification into regional and domain-focused events. Notably, the COVID-era events were more heavily attended due to remote participation, as shown in Figure 2.
The map in Figure 3 highlights SoRDS’ global engagement across Africa, Asia, Latin America, Oceania, Europe, and North America. Countries shown have hosted training, sent participants, or provided instructors, reflecting a commitment to inclusion. Africa’s involvement spans the western (Ghana, Nigeria), eastern (Kenya, Ethiopia, Tanzania), and southern regions (South Africa, Botswana). Asia features India, Bangladesh, China, Indonesia, and the Philippines, meeting the demand for data science and RDM training. In Latin America, Brazil and Colombia are active hosts, with Costa Rica as a key coordination hub, enhancing accessibility. Europe’s Italy and Belgium lead in organization and expertise, frequently hosting in-person schools and contributing experienced trainers.
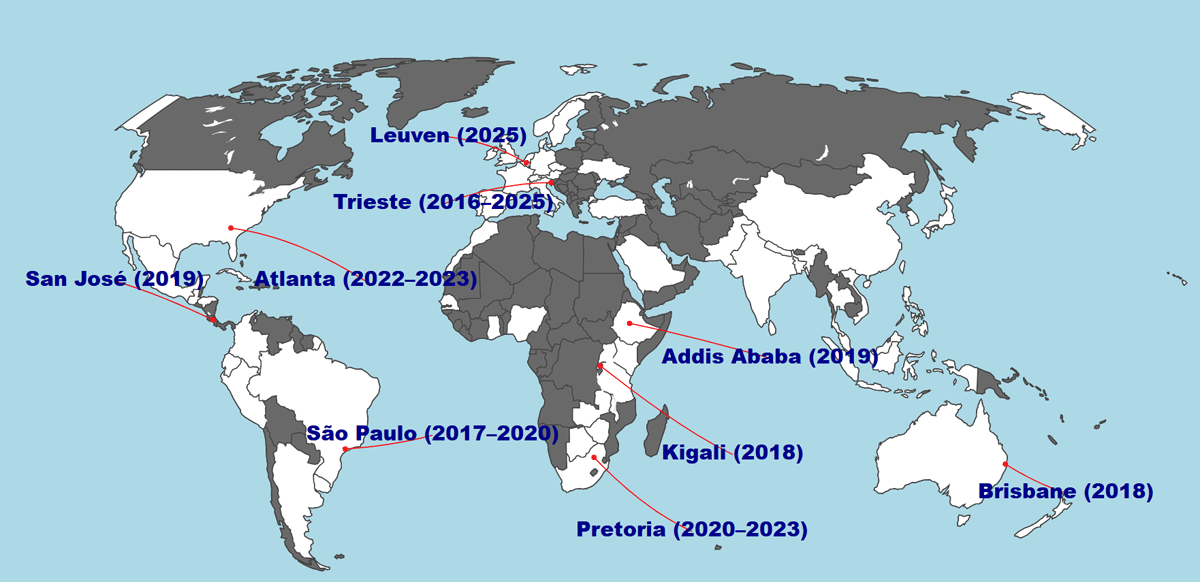
Figure 3
Global Footprint of Schools of Research Data Science (SoRDS): countries in white are countries where SoRDS has held events or whose early-career researchers have participated.
RDM Training Context and Its Influence on SoRDS
As data-driven research continues to grow, robust RDM practices are essential for maintaining data integrity, enhancing accessibility, and aligning with FAIR principles. While SoRDS incorporates several foundational Carpentries-style technical skills (e.g., shell, version control, R/Python basics), it extends beyond them by integrating broader FAIR-aligned RDM concepts, data ethics, research integrity, and contextualized training tailored for LMIC settings (Jordan, 2018; Shanahan, Hoebelheinrich and Whyte, 2021).
Despite the growing recognition of RDM as essential to good scientific practice and increasingly mandated by funders and publishers (Biernacka, Helbig and Buchholz, 2021; Kanza and Knight, 2022; He et al., 2023; Majid et al., 2018; Wilkinson et al., 2016; ), RDM training remains challenging to deliver effectively. The inherent complexity of RDM, shaped by diverse data practices, multiple stakeholders, and rapidly evolving standards and technologies (Oo et al., 2021), has resulted in persistent skills gaps, particularly among ECRs, many of whom continue to rely on ad hoc solutions due to limited formal training (Goben and Griffin, 2019; Krahe et al., 2020; Maienschein, MacCord and Elliott, 2019; Wiley and Kerby, 2018). These challenges were SoRDS’ emphasis on broad-but-shallow coverage, integrated ethics, and applied, hands-on learning.
SoRDS Curriculum
While SoRDS is designed primarily for ECRs, a separate and more specialized set of professional data-steward curricula has emerged to support librarians, data stewards, and research support staff. The curriculum covers policy interpretation, infrastructure design, and teaching techniques.
RDM Curriculum Characteristics as Reflected in SoRDS
Compliance and best practices
Throughout its development, SoRDS placed a strong emphasis on adherence to the FAIR principles and other relevant policies, legal and ethical requirements, licensing, documentation, and metadata practices (Rantasaari, 2022; Kanza & Knight, 2021; LIBER RDM Working Group, 2020). These elements became increasingly prominent across successive programme iterations as external mandates and community standards evolved.
Data Stewardship and Governance: SoRDS consistently framed RDM as a component of long-term stewardship, emphasizing data integrity, reliability, transparency, and reproducibility to support discovery and reuse (Wilkinson et al., 2016; Rantasaari, 2022). This perspective informed both curriculum content and the practical exercises used across multiple cohorts.
Customization and Contextualization: In response to the diversity of disciplinary practices and participant backgrounds, SoRDS progressively incorporated contextualized and discipline-aware training approaches, reflecting broader trends toward user-centered RDM education (Oo et al., 2021). This was particularly important for supporting ECRs working in heterogeneous and resource-constrained research environments.
Practical and Interactive Learning: Hands-on, practice-based learning has been a core component of SoRDS since its early iterations, linking RDM principles to real research workflows through applied exercises such as Data Management Plan development (Yu, Deuble and Morgan, 2017; Rantasaari, 2022). Over time, interactive and participatory teaching approaches using red and green sticky notes and having alumni as helpers in the class were further refined to enhance engagement.
Data Engineering Shift: More recently, SoRDS has adapted to emerging shifts in RDM practice that move beyond bibliographic descriptions of datasets toward data engineering approaches requiring richer, machine-actionable metadata (CODATA & RDA, 2024). This shift influenced later curriculum updates, ensuring that SoRDS remained aligned with evolving expectations for data interoperability and reuse.
Taken together, these curriculum characteristics illustrate how SoRDS evolved in principle with global RDM training priorities over a decade of delivery, demonstrating a sustained process of adaptation rather than a static curriculum model.
SoRDS in a Global Training Landscape
In contrast to the broad data lifecycle approach curricula, The Carpentries focus on developing technical skills for data analysis and software development through practical hands-on tool-based instruction, often delivered in short, self-contained workshops (Biernacka, Helbig and Buchholz, 2021). The Carpentries’ emphasis on data literacy, reproducible research, hands-on tool-based instruction, open and collaborative curriculum development, and Train-the-Trainer models (Biernacka et al., 2020; Doehle, Bjornen and Chartier, 2019; Kanza and Knight, 2022; Diggs, 2025) informed several pedagogical elements later adapted within the SoRDS programme.
How RDM Training Literature Informed SoRDS Development: Key Distinctions and Synergies
RDM curricula are generally broader in scope, encompassing the full data lifecycle, compliance, governance, and policy considerations with domain-specific and multi-stakeholder perspectives. The Carpentries emphasize the acquisition of hands-on, technical skills for data handling, analysis, and reproducible workflows. These two educational approaches, although distinct in focus, are highly complementary and reinforce each other in practice.
Within this training landscape, SoRDS was intentionally designed to bridge these approaches by ensuring that the acquisition of ‘technical and complementary non-technical skills’ centered around the theory behind best practices in RDM, Open Science, and Open and Responsible Research is coupled with the ‘hard-skills’ acquired through practical application.
Crucially, the SoRDS programme is designed to make these competencies usable and useful in low-resourced settings as we spend significant time discussing context, common challenges, and adaptive strategies to ensure relevance and applicability. Moreover, this approach enables the development of transferable skills and the potential to expand research beyond traditional domains into new interdisciplinary areas, as well as repurpose data from one domain into another, potentially a completely different one.
This comparison demonstrates why SoRDS occupies a unique middle ground: it leverages the strengths of technical training traditions (e.g., Carpentries pedagogy) while expanding them into a holistic RDM-focused capacity-building programme tailored for LMIC contexts.
Unique contributions of SoRDS
Foundational skills for RDM implementation
The Carpentries teach essential skills like scripting, version control, and data cleaning, which provide a foundation for RDM. SoRDS builds on this foundation taking a holistic approach, combining technical and theoretical RDM competencies for ECRs, ideal for passing on knowledge to drive change. Building on The Carpentries’ live coding, peer instruction, and volunteer-led teaching, SoRDS adds RDM principles, open research, security, ethics, and policy. Through practical exercises, it helps ECRs master both tools and values underpinning responsible data science.
Integration with artificial intelligence (AI) and data engineering
Emerging AI-assisted approaches to metadata management and data quality assessment highlight new directions for RDM training that SoRDS focuses on to engage with in the future. AI technologies can automate the detection of data quality issues, while foundational technical training provides the context needed to understand and resolve these outputs (Diggs, 2025).
Adaptability to policy shifts
SoRDS responds to evolving data-sharing mandates by integrating policy awareness, compliance, and practical implementation strategies within its curriculum. While RDM curricula are often theoretical and technical training programmes mostly focus on tools, SoRDS integrates these perspectives to foster a data-literate, resilient research culture, advancing a sustainable, inclusive ecosystem grounded in best practices, reproducibility, and openness.
Train-the-Trainer model
The Train-the-Trainer approach at SoRDS builds institutional capacity by training librarians, data stewards, and research support staff in RDM skills and pedagogy. SoRDS has run a pilot in collaboration with KU Leuven and a consortium of Ecuadorian Universities to formalize its on-boarding of instructors, using a variant of the principle of ‘observe one, do one, teach one’ (Kotsis and Chung, 2013), where trainee instructors shadow and assist teaching at one training event, then train others at the next event. It promotes cascading knowledge through programmes, combining technical content and instructional design (Schmidt et al., 2017).
Complementarity and integration
In summary, the SoRDS model integrates technical skill development, theoretical RDM foundations, and capacity-building approaches into a cohesive training programme. This comparison is presented to contextualize the pedagogical choices underpinning SoRDS, which integrates and adapts several of these elements into a comprehensive, LMIC-responsive model.
Trieste’s 10-Year Celebration
Over the past decade, the annual SoRDS schools in Trieste, Italy, in collaboration with the ICTP, have played a pivotal role in data science education, contributing significantly to the advancement of data practices. Since its inception, SoRDS has expanded globally, by conducting regional programmes in multiple countries and tailoring content to local needs. This global growth directly supports the programme’s goal of enhancing data skills among researchers worldwide, as documented in the SoRDS newsletters (Cobe et al., 2023). These events have facilitated collaborations, knowledge exchange, and the development of advanced schools focusing on domain-specific areas, thereby strengthening the global data community.
For instance, the Urban Data Science summer school hosted in India in 2018 and 2019 was a result of collaborations initiated at the foundational school in Trieste in July 2017 (Gandhi and Anyiam, 2022). Several peer-reviewed publications highlight this alumni-driven impact. Tachie et al. (2024) report that Alberta Aryee and Nii Adjetey Tawiah, students at the 2022 Atlanta school, co-authored a study with former student Christabel Tachie on classifying oils and margarines using FTIR spectroscopy and machine learning. Bezuidenhout et al. (2019) include Ola Karrar, a Trieste 2018 alumna, among the authors of a PLOS One article examining the overlooked effects of economic sanctions on academia. Quick, Córdoba, Diggs et al. (2023) feature co-chairs and alumni of SoRDS in an IEEE conference paper detailing a SoRDS event for health equity researchers at Minority Serving Institutions. Bezuidenhout, Quick and Shanahan (2020) have designed modular data ethics instruction, reflecting collaborative curriculum development across alumni and hosts. Alzate-Cardona et al. (2018) describe Oscar Arbeláez-Echeverri’s alumni of SoRDS work on the ‘Vegas’ Monte Carlo simulation software for magnetic materials; Oscar acknowledges Quick’s mentorship from the 2017 Trieste school in utilizing OpenGrid. These examples underscore a thriving ecosystem where SoRDS alumni transition into contributors by publishing collaboratively, leading new events, and enriching the data skill landscape through sustained engagement. These alumni continue to contribute actively to the SoRDS network, frequently returning as organizers and support staff at later events.
In August 2025, SoRDS celebrated its 10th anniversary at the ICTP in Trieste. This milestone event celebrated a decade of SoRDS’ commitment to advancing RDM and data science education globally (CODATA, 2025; ICTP, 2025a). Over the past 10 years, SoRDS has played an instrumental role in building the capacity of ECRs, particularly from LMICs, with essential skills in data stewardship, open science, and computational methods. Bezuidenhout et al. (2021) report, ‘the results of the survey strongly support the SoRDS’ long-term goals of facilitating data science training/capacity building within LMICs, and to foster communities of ECRs conducting responsible and open data science research,’ with 90% of alumni continuing to apply these skills in their work. The anniversary highlighted the programme’s impact on fostering international collaboration, enhancing data literacy, and promoting equitable access to data science training. By bringing together alumni, instructors, and stakeholders, the celebration aimed to reflect on SoRDS’ achievements and chart a course for its future contributions to the global community.
In 2025, the advanced workshops at SoRDS were uniquely curated by its alumni, celebrating a decade of impact and growth. As part of the school’s 10th anniversary, these workshops showcased how past participants applied their data expertise to their fields, returning to lead domain-specific sessions. The three parallel workshops, ranging from Big-Data Analytics, Computational Infrastructures, and Urban Data Science, demonstrated the diverse application of data skills at the (ICTP, 2025b). This approach not only highlighted the practical impact of the school’s training but also reinforced the ongoing contribution of its alumni to the global research community. These alumni continue to contribute actively to the SoRDS network, frequently returning as organizers and support staff at later events. The planning for the 10th anniversary followed the established SoRDS multi-stage design cycle, including instructor nomination, curriculum mapping, and alumni-contributed workshop proposals.
Artificial Intelligence in Research Data Management (RDM)
Artificial intelligence (AI) is emerging as a transformative contributor to RDM. Automated machine learning (AutoML) approaches now support end-to-end data pipeline tasks, such as cleaning, missing-value imputation, feature generation, and preprocessing. AI helps in reducing manual burden and accelerating the preparation of large, complex datasets (Mumuni and Mumuni, 2024).
AI-driven tools can also be used to automate data quality validation, detecting anomalies and inconsistencies by learning from historical patterns to proactively flag potential errors (Tamm and Nikiforova, 2025). On the metadata front, emerging AI-assisted metadata management frameworks can facilitate automated metadata generation and curation, improving data discoverability and supporting FAIR data practices (Davenport & Redman, 2022; Yang et al., 2025). While AI-based security mechanisms are still evolving in RDM, analogous applications in cybersecurity, where AI models detect unusual access behaviors, suggest promising potential for safeguarding sensitive research data.
As the SoRDS curriculum continues to evolve, integrating AI skills has been identified as an important area for future development. In the context of SoRDS, AI-related content is beginning to be incorporated into both foundational and advanced modules. Discussions during the 2023 and 2025 planning cycles identified AI-assisted metadata generation, automated data quality validation, and reproducible machine-learning workflows as priority skill areas for future SoRDS iterations. Concepts of Machine learning and Artificial Neural Networks were introduced early on from 2017 in the basic schools. Several alumni-led advanced workshops, like Urban Data Science in 2025 and Research Data Management lab in 2024 and 2025, have already piloted introductory materials on AI-enabled data analysis, and SoRDS intends to formalize these components as part of its evolving curriculum which will be implemented in 2026 schools. This integration aligns with the programme’s long-term strategy to ensure that ECRs are prepared to navigate emerging technologies that directly affect RDM practice.
In the longer term, the planned updated curriculum for AI will develop a workflow, namely cleaning and annotating data using best RDM practices, followed by analysis using Machine Learning methods and ensuring that this is done in an ethical fashion. This workflow will then inform the detailed updates to the curriculum.
Conclusion
Integrating the broad range of competencies that SoRDS has identified into educational programmes is essential for preparing researchers to navigate data-intensive research. Initiatives like SoRDS play pivotal roles in enhancing data literacy and promoting best practices in data management. The Train-the-Trainer model effectively scales data skills education, fostering communities of practice. Trieste’s contributions over the past decade of Data Schools have been instrumental in advancing data skill enhancement globally. Furthermore, the incorporation of AI into RDM processes offers promising avenues for automating routine tasks, improving data quality, and enabling sophisticated analyses. Ultimately, while the wider landscape of RDM and data literacy initiatives continues to evolve, the decade-long experience of SoRDS offers a distinctive, empirically grounded model for scalable, context-sensitive capacity building. The programme’s history, alumni-driven growth, and integration of ethics, stewardship, and emerging technologies represent a coherent contribution to the field and a practical framework for future global RDM training efforts.
Looking ahead, SoRDS plans to expand its regional implementations, increase the number of alumni-led advanced schools, formalize its Train-the-Trainer certification, and integrate additional modules addressing emerging topics such as AI-assisted metadata generation and reproducible computational workflows. These next steps reflect SoRDS’ commitment to continued evolution based on documented community needs.
Reproducibility
Materials from the first workshop are available online (Quick, 2016). Beginning in Kigali in 2018, a GitHub repository was created to gather materials for workshops, which includes presentations and exercises. Occasional snapshots of these repositories were extracted and assigned persistent identifiers to supplement publication submissions. The most recent snapshot of materials was created after Trieste in 2023 (Quick, Córdoba, Cobe et al., 2023).
SoRDS encourages the adoption and reuse of all materials and methods used during events, and publishes all materials openly with CC-by license on the GitHub Repository (CODATA-RDA-DataScienceSchools, 2025).
Supplementary Files
Due to the volunteer-driven nature of the initiative over the past 10 years, all reported figures are estimates. The primary focus has been on operations and event execution rather than formal bookkeeping. As the schools have relied heavily on volunteer support, maintaining detailed attendance records has not been a priority.
Ethics and Consent
All the data quoted in this paper is publicly available via the SoRDS website and newsletter.
Acknowledgements
We acknowledge the support, collaboration, and contributions from SoRDS, CODATA, RDA, and ICTP. Their continued partnership has been invaluable in advancing our work.
Competing Interests
The authors have no competing interests to declare.