
1. Context and Need
The Asia-Oceania region is largely characterised by islands; island archipelagos or solitary islands, large (such as Australia) or small. French Polynesia, for example, has 118 islands concentrated in five archipelagos (Van Wynsberge et al., 2015), while Indonesia has 13,558 islands of which 8844 have been named and 922 support a permanent population (Andréfouët et al., 2022). Some, however, are more continental, fringing the main Asian landmass. Vietnam and Malaysia are examples of this.
From a data management perspective, some countries, such as Australia and New Zealand, have sophisticated organisation of much of their knowledge and data, and their e-infrastructures are well advanced. In Indonesia, science and education institutions have been consolidated into one ‘super-entity’, the Indonesian National Research and Innovation Agency (BRIN). This provides Indonesia with the potential to lead participation in Open Science and scientific innovation in Southeast Asia. Yet, there is an acknowledged deficit in digital literacy (Stewart, 2023). Although Indonesia’s new science law mandates that researchers deposit their data on the National Scientific Repository, it is yet to be a common practice for two reasons; firstly, the formulation of technical regulation is still ongoing, and secondarily, data sharing has yet to become a norm. Other countries are geographically and economically smaller, with greatly varying levels of technological capability. In previous centuries, many of these smaller countries have been heavily economically influenced by international interests, with international aid a common feature. Even today the attraction of promised investment and financial reward for local communities is strong and can result in poor long-term decisions (Nicholas and Lyons, 2021) and they can be vulnerable to exploitation (Jutel, 2021).
Many of the smaller countries in the Asia-Oceania region face significant challenges to improve livelihoods and overcome poverty, particularly due to increases in food and fuel prices, the effects of various global economic crises, natural disasters, difficulties maintaining infrastructure, and the negative effects of climate change (Underhill et al., 2011). Consistent with the Sustainable Development Goals (United Nations, n.d.), the Pacific Community (n.d. (a)), the scientific and technical organisation supporting development in the Pacific region established in 1947 (under the Canberra Agreement), has pledged to progress development and has actively supported aggregation of data across the region (Pacific Community, 2022).
There is a recognised lack of basic, longitudinal evidence about environmental ‘assets’ on which countries can base decisions and report on environmental indicators (Straza T, 2021). Derived databases can assist, but as noted by Visconti et al. (2013), Moudry and Devillers (2020), and Brewer et al. (2022), internationally aggregated databases can be coarse and unreliable. The sheer number of required reports for the many bilateral agreements to which each country is signatory is considerable. These include reports on environmental indicators, such as those for climate change and biodiversity, the status of protected areas, waste management, and pollution. Readily available data to help respond to these reports will be most advantageous. The Pacific Regional Environment Program (SPREP) (n.d. (a)) has advocated for data and information sharing between countries and have proposed that centralised data services could assist with data and indicators for environmental information (Straza T, 2021).
In 2023, a Pacific Academy of Sciences and Humanities (International Science Council, 2024) was declared at a meeting in Samoa. This is evidence of a general recognition in the region of the value of organised conversations and the need for a strong knowledgeable voice for the countries of the Pacific. Academic and researcher representatives from Samoa, the Cook Islands, Fiji, Papua New Guinea, the Solomon Islands, Vanuatu, Kiribati, New Caledonia, and New Zealand have been involved in its planning. The Australian Academy of Science is a partner.
1.1. Engaging communities
Bottom-up design is arguably the optimal way to ensure a sense of ownership of a project and can increase community capacity. The creation of a robust and authoritative set of data by the community about entities in their world needs engagement, and it needs guidelines to ensure standardisation if the data are to be shared. Community engagement in knowledge creation can be accomplished in several ways. The three governance structures considered by Conrad and Hilchey (2011) can provide a basis for community-based data gathering. These are (1) government-led, community run; (2) collaborative, often in a non-politically demarcated area; and (3) community led, run, and funded. Databases such as iNaturalist (Martinez-Sagarra et al., 2022; Meeus et al., 2023) and eBirds (Sullivan et al., 2009; 2014) are examples where an infrastructure has been developed dependent on the contributions of individual community members with rewards and credits for participation. Tools such as the Great Lakes Fish Finder App (Happel et al., 2020) can help make participation easy and rewarding, and participatory design has provided benefits for the community (Durish et al., 2021). Kitamura et al. (2023) considered that for a successful outcome for a community-led interactive database designed for asset-based community development the intended audience (data providers, the end users and the facilitators), the type of information to be included, and plans for sustainability needed to be considered.
Many of the Asia-Oceania countries are occupied by original communities. As such, they may be termed to be ‘indigenous’ and there have been a few initiatives in recent years to facilitate the participation of such communities in collating and storing their data and information for their own use and benefit and to share. In addition to information gathered using scientific methods, traditional knowledge has long been recognised, for example, as of great advantage to properly understand environmental processes (Huntington, 2000; Ens et al., 2015). Having good protocols and support for sharing information will greatly assist communities to control their information and expand initiatives already in place.
The CARE principles (Collective Benefit, Authority to Control, Responsibility, and Ethics) provide guidance around Indigenous Data (Carroll et al., 2020 and 2021; Hudson et al., 2020). The principles are couched around the need for assurance that there will be collective benefit from data collection and sharing, an authority to control the information gained and shared, a responsibility for those data to ensure positive relationships, expanding capability and capacity, and the assurance of ethical behaviour and standards. Aligning these principles to a repository remains a work in progress (O’Brien et al., 2024).
The labelling proposed by the Local Contexts (n.d.) initiative provides communities with tools that can assert cultural authority in heritage collections and properly identify data ownership. These labels can facilitate how data is collected, managed, displayed, accessed, and used by others and provide assurance that data are properly handled and shared sensitively. Incorporating such labelling at data source could alleviate concerns for data providers.
The Te Kāhui Raraunga Charitable Trust (TKR) (n.d.), an independent body in New Zealand established in 2019, leads the action required to realise the advocacy of the Data Iwi Leaders Group (Data ILG). TKR’s aim is to enhance the social, cultural, environmental, and economic well-being of Māori; to enable iwi, hapū and whānau Māori to access, collect and use Māori data. The planned data storage network has layers of safety, security, functionality, and protection structurally informed by kawa and tikanga, which will ensure that hapū and iwi can make their own calls about the access and sharing of their own information in ways that honour their kawa and tikanga at place. They will do this in large part by employing Local Context labels.
1.2. Data organisation in the Oceania region
We shall review an example of data organisations in the region of concern. As part of an emerging ‘Pacific Data Ecosystem’, the Secretariat of the SPREP together with the Pacific Island Countries, the Pacific Community (n.d.(a)), and the UN Environment Programme initiated the creation of a Pacific Environment Portal (SPREP, n.d. (b)) to promote greater coordination in data management, dissemination, and uptake initiatives across national data repositories. A Pacific Data Hub (Pacific Community, n.d. (b)) was created by the Pacific Community in 2018 with a similar aim. It is important SPREP shares data with SPC, and that is where the Pacific Data Hub open-source solution sits.
In order to support this process, the Inform Project—Building National and Regional Capacity to Implement Multilateral Environmental Agreements by Strengthening Planning and the State of Environmental Assessment and Reporting in the Pacific—was created and ran from 2018–2021 (SPREP, n.d. (c)). One of the main tasks of Inform was to collate all the data and legacy information stored in paper and various databases and put them into a form that is easily discoverable, standardised, and able to be used for multiple things. In addition, Inform provides tools, guidance, and a checklist for dataset creation and uploading data to the central portal. It uses a GitHub-linked Drupal portal, the DKAN Open Data Portal (SPREP, n.d. (d)), to host the unique portals of fourteen participating countries. Ambitions to provide opportunities to store raw data in the SPREP databases are yet to be realised, but great advances have been made in making secondary data about the region openly available.
These initiatives illustrate that there is strong regional intent, and go a long way to develop a secure, supported approach to conserve and discover information about the Pacific Island Nations.
1.3. The reason for this paper
Consistent with the UNESCO recommendations on Open Science (2021), confidence in the results of studies is best achieved if the data used to produce the work is open to scrutiny. This may range from the statistics behind economic models, to real-time climate data (not interpretations from a third party), to the measurements of fish populations. If a temporal aspect is included, more than one instance may need to be available to establish trust in the findings. If a comparison is made across geographic space, data from each locale used for the comparison should be available to view. Interpretations are thus more easily defensible and also contestable. Once the data are available, they become valuable in themselves. Historically, paper copies of data have sometimes been carefully curated in museums, laboratories, or in government departments, but modern technology and internet connectivity allow data to be digitally accessible, greatly increasing the value of the data (e.g., Ahl et al., 2023). No longer do the data remain only with a study team, but they can form a legacy for others. No longer will each new researcher or study coordinator have to re-find data from previous studies, but the data will be available for re-use. Enabling this requires organisation and commitment.
Active participation in conserving data in a temporal and spatially relevant manner is desirable. This can be for international reporting reasons (state of the environment, achievement of Sustainable Development goals, conservation objectives), for research reasons (exploration of international phylogenetics, development of new pharmaceuticals), or for economic reasons (tracking the status of fish stocks, timber trade, and other food products). In a systematic review of community-engaged knowledge hubs, Brar et al. (2023) concluded that the benefits of knowledge hubs included better knowledge mobilisation and dissemination, and increased community benefits through the capacity building of community partners and their greater involvement in knowledge production and mobilisation activities. Difficulties in sustaining a hub included differences in priorities across the network, limited capacity, resistance to change, and lack of funding. The development of the knowledge hub sponsored by the SPREP, for example, is an excellent start. Making resources available for the community means ensuring that data (and related materials) are findable and accessible on the Web, and that they comply with adopted international standards making them interoperable and reusable by others (David et al., 2020).
In the next section, we consider what data architecture would be optimal to best ensure a collaborative data network is able to comply with (a) FAIR principles (F, Findable; A, Accessible; I, Interoperable; R, Reproducible) (Wilkinson et al., 2016), to establish criteria to ensure (b) CARE principles are followed (C, Collective benefit; A, Authority to control; R, Responsibility; E, Ethics) (Carroll et al. 2020), while (c) ensuring the information is held in repositories that are robust, namely following the TRUST principles (T, Transparency; R, Responsibility; U, User Focus; S, Sustainability; T, Technology) (Lin et al., 2020).
2. A Data Network for Communities and Regions
The structure we suggest for a Collaborative Regional Data Access Network (CREDAN) combines a suite of country-level centralised databases/repositories connected in a distributed network, with a collaborative coordinating authority to ensure sound governance, help establish common standards for data types collected, data set descriptions (metadata), and open descriptions of vocabularies used. Several emerging technologies would be employed to ensure the fidelity of provenance, licensing, and protocols are maintained throughout the network, and in the interface with the wider community. Each of these components is introduced in this section.
2.1. Country or sub-country level
Each country or sub-country entity–hereafter referred to as (sub)country–would hold their own data in a central location where the data are curated, managed, and made available following a centralised model (Figure 1). These models are coordinated by a central authority (in this instance a data hub), and in this way data linkage, harmonisation, and interoperability can be facilitated (Rujano et al., 2024). In a centralised system, data can be uniformly managed, stored, and processed, allowing for streamlined operations, enhanced data security, and easier compliance with relevant regulations. The hub, which could be a traditional database, distributed file system, or cloud service, needs to be adopted and driven by the community, as it would fail without that the effort (Bailey et al., 2024).
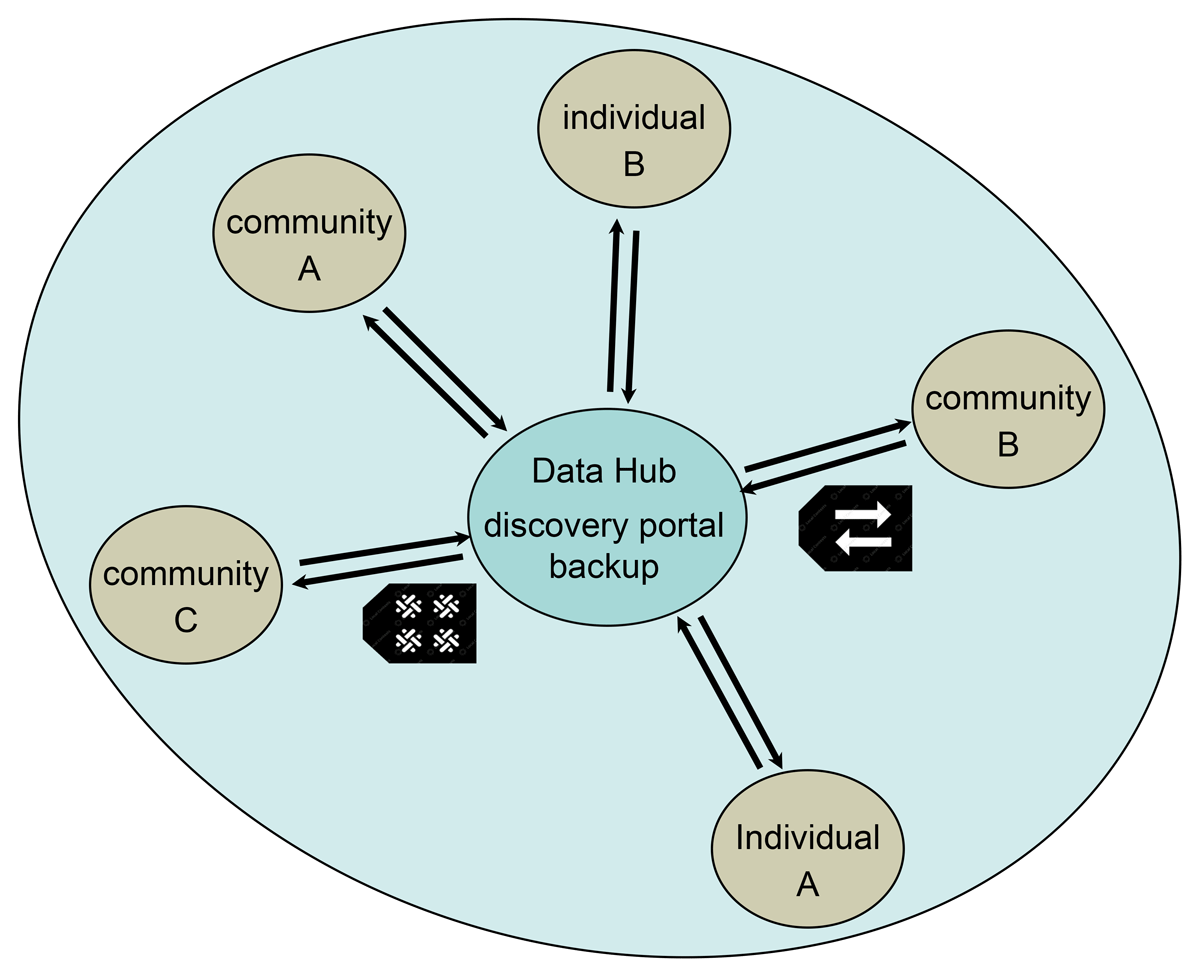
Figure 1
Depiction of a centralised data hub within a locally defined area (e.g., island, group of islands or country). Communities or individuals would assemble their data and metadata, applying local knowledge-type rules to each dataset. Examples of two traditional knowledge labels are shown for ‘attributions’, which need to be set at the community level, and the ‘multiple communities’ label, which indicates knowledge is shared across more than one community (see https://localcontexts.org).
This level of the architecture is critical to the success of our proposed solution, as these hubs provide the data for the whole network, as well as determining the permissions for access to those data. The data stored in these hubs would presumably focus on data about the geographical area in question collected by communities or individuals. These individuals or communities would have the responsibility to properly describe the items to be stored on the hub, such as provide metadata, use common vocabularies (or define new ones so others can understand), and attach sharing rights according to, for example, Traditional Knowledge criteria following the Local Contexts categorisations (Local Contexts, n.d.). These rights and permissions would be validated by the relevant communities (O’Brien et al., 2024). Data ownership would be according to these sharing agreements.
In all situations the provenance of the information being shared needs to be carefully documented, so attribution can be correctly applied. The system should provide for changing needs and ‘community informality’ (Bryceson and Ross, 2020; Bhusal, 2023), ensuring dialogue is in place so any changes in sharing agreements are adjustable. The design should allow periodic update by the providers of the data held and the tools used for and manner of discovery (maps, downloads, reports, etc). There will be additional opportunistic additions both past and present, if they are spatially consistent. The individual communities would not need to have computing capability but would need to understand any country standards to smooth aggregation and sharing.
Each hub would need to be equipped with data storage capacity and take on some of the responsibility of a TRUSTed repository (Lin et al., 2020). The hubs would need to ensure metadata are systematically applied to each digital object, and standard vocabularies are used where possible, or defined openly (see Specht et al., 2024). Equipping these hubs with the technology, the internet security, and the skill sets required in the staff is not a trivial matter, but has been explored thoroughly in setting up a climate data management system in the western Pacific islands states (Martin et al., 2015) and of course by the SPREP, to name two examples. The hub staff would take responsibility for dialogue with each individual and community to ensure their data and information aligns with the FAIR and CARE criteria as much as possible.
One of the first tasks for the community groups and individuals will be the creation of a dictionary of the terms used for their data. Optimally for sharing purposes, terminology will be common across all data contributors, and follow international standards, but most likely some of the names of things and their meanings will be different. The hub will be responsible for facilitating the dictionary process, compiling the different dictionaries, and assisting data creators (owners) where necessary to develop their own definitions in a standard way (Specht et al., 2024). These should be harmonised and published, preferably using a web interface associated with the digital objects held. At no point should any original data and terminology be lost.
The international significance of particular objects described in the datasets may be recorded at this level (e.g., listed rare species) and any sharing propositions or material already shared should be examined in the light of the Nagoya Protocol (Secretariat of the Convention on Biological Diversity, 2011). Depending on capability, the hub may have an ability to enable the contributing communities to refer to the data and information as and when they want according to their sharing protocols.
2.2. Regional level
Country and sub-country data hubs will be linked through a distributed network (Figure 2). This facilitates data querying and accessibility to information from any point. The data itself remains at the (sub)country hub, where the manner of data sharing (permissions and licensing) is established and controlled. This structure is ideal when data sovereignty and privacy are crucial, yet collaborative data access and sharing remain necessary. The separate hubs connect to each other using purpose-built links. The envisaged network could be supported by an overarching cloud computer storage facility allowing backup and coordination across the network. Traditionally, distributed networks have depended on each hub being of the same configuration and standard, while in reality, the hubs in our scenario will no doubt vary in size and type. Various technologies, however, can be employed to overcome this (e.g., Tebbi et al., 2019). Sharing across the network, and for reporting against international targets, would require some level of data interoperability. Governance of a distributed network can be a challenge, as data protection and security across a network of variable hubs requires focussed and maintained vigilance, making strong collaboration among hubs essential.
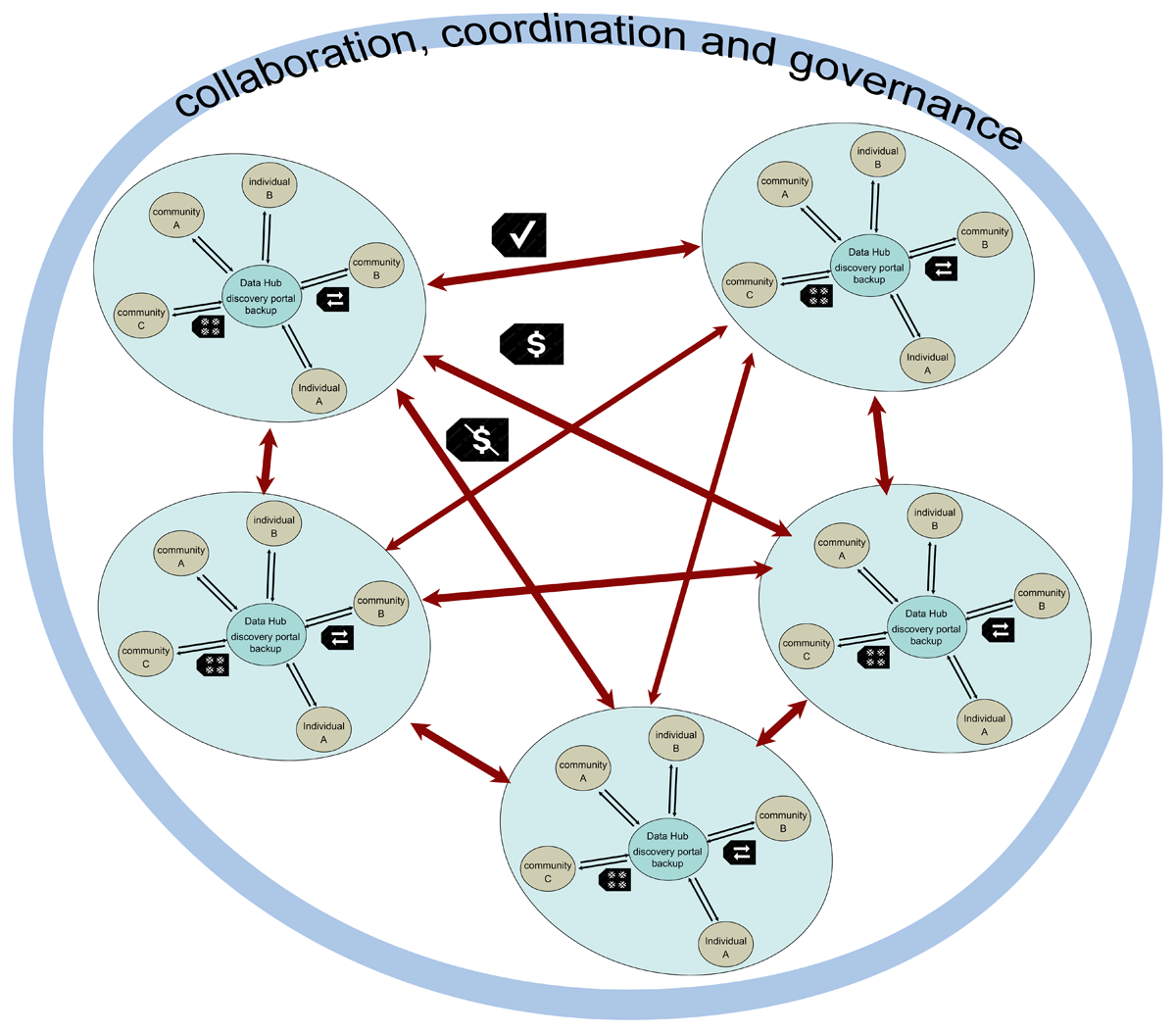
Figure 2
A depiction of collaboration across a suite of organisational units, where information flows between each determined by permissions. The network as a whole takes shared responsibility for setting standards, training, and communication, with a separate set of staff established in a neutral space, financially supported by all the member countries.
To enable this architecture to support discoverability, connectivity, and sharing, and ensure good governance throughout, collaborative coordination is advisable (Figure 2). This will include representatives from all network members and will facilitate hub function and alignment (Berdej and Armitage, 2016; Specht et al., 2021). Governance and coordination committees should take responsibility for establishing principles for the entire network and its members, assist with maintaining common standards, communication and collaboration, and if necessary, advise an overall back-up facility. These committees will have oversight of hub compliance with FAIR and CARE criteria. Outside sources of technology, such as the DKAN open data portal used by the SPREP, and storage facilities such as that available through the National Computational Infrastructure in Australia could be deployed (Cannon et al., 2024).
The sharing conditions for digital objects are determined at local hub level. The labels shown in Figure 2 as illustration are the TK ‘Open to Commercialisation’ and ‘Non-Commercial’ for research and the Verified label, which affirms that the representation and presentation of the material is in keeping with community expectations and cultural protocols (see https://localcontexts.org). The illustrated labels are not exhaustive and are used as examples.
2.3. Enabling technologies
2.3.1. Blockchain technology
Blockchain technology, with its features of immutability, security, and transparency (Cao et al., 2023; Lewis et al., 2023) is ideally configured to support the flow of information and data through a network. It is distributed by design, and the data are shared across network members, meaning no central entity can control stored data. It suits scenarios where trust and data provenance are crucial to data sharing and exchange. The modularity and simplified governance of blockchain means underlying protocols can be flexible. Blockchain can be tasked to maintain a distributed record of standardised, informative, and machine-readable metadata (Lewis et al., 2023).
Blockchain does not ‘store’ the data itself. A hash (often called a ‘hashtag’) ensures a trustworthy record of data provenance by enabling a verifiable audit trail, strengthening data integrity and accountability (Werder et al., 2022). Any tampering with the data stored in each (sub)country’s centralised database(s) can be easily detected by comparing the hash values, making blockchain a practical approach to balance integrity, security, efficiency, and scalability. Operations can be streamlined, and self-executing contracts can reduce costs with terms directly written into code. Blockchain can act as a bridge between different systems, facilitating interoperability and enhancing overall efficiency. Some of the key features of blockchain technology are shown in Table 1.
Table 1
Key features of blockchain technology.
| BLOCKCHAIN FACILITY | |
|---|---|
| Data Anchoring Critical pieces of data can be linked into a blockchain to ensure their immutability, integrity, and traceability. | The data hashes need only be stored on the blockchain, while the actual data is kept off-chain in centralised databases or distributed storage systems like IPFS (InterPlanetary File System). The hash acts as a unique fingerprint, allowing verification of the data’s integrity without storing it on the blockchain. In doing so, organisations can reduce the costs associated with blockchain’s storage and transaction fees while still benefiting from its security and immutability features (Cao et al., 2021). |
| Proof of data availability Blockchain can be used to timestamp and verify the availability of data at a certain point in time. | Useful for applications like research data, intellectual property, and legal documentation, where proving the existence and availability of a document or work is crucial. |
| Data Access Control Blockchain-based access control mechanisms can be implemented. | With access permissions and logs on the blockchain, organisations can control who can access their data and what it can be used for based on policies/agreements (Lomotey et al., 2022). This can enhance data security and ensure that only authorised parties can access sensitive data. |
| Auditing and Compliance Blockchain’s immutable ledger can be used for auditing purposes. | An immutable audit trail can be maintained on the blockchain. This can be used to track data history, verify data provenance, and ensure compliance with local and international regulatory requirements. |
2.3.2. Decentralised identifiers (DID)
Decentralised Identifiers (DIDs) (World Wide Web Consortium, 2024) provide a robust and versatile framework for decentralised identity management across multiple platforms. They are globally unique persistent identifiers that do not require a centralised registration authority and are generated and/or registered cryptographically. They provide a way to uniquely identify the individuals involved in creating, modifying, and transmitting data. They can therefore play a significant role in ensuring data provenance is recorded properly by enhancing the traceability, security, and accountability of data. Using DIDs, each party in a transformation or movement of data can be recorded on a distributed ledger, such as a blockchain. This creates an auditable trail of data provenance that is transparent and tamper-proof, allowing for easy tracing of data back to its origin. DIDs are designed to be interoperable across different systems and platforms. They follow standards set by the World Wide Web Consortium (W3C), ensuring that provenance information can be consistently understood and utilised across various contexts. Each DID provides a unique and cryptographically secure identity that can be used to verify the legitimacy and ownership of the data, enhancing trust in the data’s provenance and integrity.
2.3.3. Smart contracts
Smart contracts are digital agreements coded on a blockchain network that are executed automatically upon fulfilling predefined terms and conditions. They can automate and enforce the establishment of common standards for data types, metadata requirements, and vocabulary descriptions, promoting consistency, transparency, and ease of discovery in data management. They are often used to automate the execution of an agreement among participants without the involvement of trusted intermediaries (Lewis et al., 2023). They can be used to enable access permissions to a person or entity, record a data request, and communicate transactions to the primary data owner.
3. The Proposed Data Network Architecture
To enable trust-based data sharing across countries, data provenance, ownership, and accessibility need to be properly and securely implemented. A cyberinfrastructure that supports an immutable and transparent record of data, while enabling control and stewardship of that data to the owner is an attractive prospect. The proposed Collaborative Regional Data Access Network (CREDAN) draws upon various network architectures and emerging technologies to achieve these goals.
By themselves, centralised and distributed data networks each have inherent advantages and disadvantages. Centralised data networks are advantageous for efficient management, security, and regulatory compliance within a single unit, but face challenges with scalability and redundancy and are slow to respond to changing temporal and cultural circumstances. Distributed systems are designed to provide integrity and accessibility to information from any point. They offer enhanced resilience and collaboration, but they come with higher complexity, costs, and regulatory challenges than centralised (Marstein et al., 2024). At a regional level, a distributed data network has considerable strengths, however, as it can deliver significant benefits, including improved data redundancy, increased resilience against local disruptions, and facilitated cross-border data sharing and collaboration. Distributed networks are scalable, as additional hubs can be added or subtracted, and can provide backup or support to others in the network when required. They offer interoperability and flexibility and can improve discoverability across the networked hubs.
A combination of centralised and distributed data networks benefits from and offsets the qualities of each network type. A model wherein each organisational unit maintains its centralised data infrastructure while participating in a broader distributed network at a regional level enables the optimisation of data governance and resource allocation. By leveraging the strengths of centralised systems—such as uniform policy enforcement, simplified data management, and enhanced operational efficiency—groups such as countries can ensure that their data sovereignty and local data needs are met comprehensively. At the same time, a distributed regional network that connects all participating organisations allows for the pooling of resources, improved data discovery and analytics capabilities through discoverable datasets, and fostering innovation through cooperation.
Integrating blockchain into this model provides a pragmatic approach to achieving cost-effective and efficient data management. The CREDAN will leverage the strengths of both blockchain (transparency, traceability, immutability security) and off-chain databases (efficient storage and access) to provide a balanced solution suitable for various applications requiring secure and scalable data management. Blockchain-enabled databases, such as Paxos, Raft, Zebra, and Google HDFS (Kalajdjieski et al., 2023; Mothukuri et al., 2021), all use a decentralised network of hubs (nodes in blockchain parlance) to efficiently store and process large datasets ranging in size from gigabytes to petabytes of data. The use of blockchain supports the decentralised governance model at the regional level that allows all participants in the Asia Oceania region to have control of data localisation and jurisdictional compliance, ensuring inclusivity and self-autonomy in a distributed data network.
The integrated architecture to enable this network consists of three components: (i) the management of the data and metadata (off-chain), (ii) data management (on-chain), and (iii) user access and verification (bridging). These are all within a strong governance structure, ensuring best practices against international criteria and those set by the component communities (Figure 3).
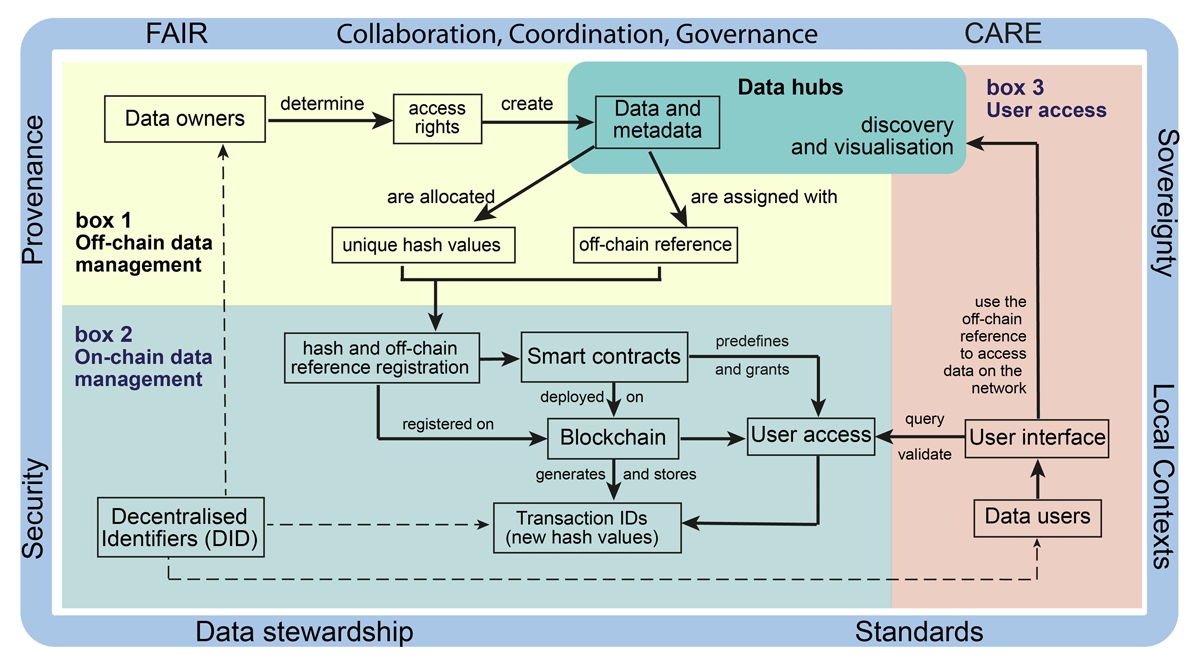
Figure 3
Visualisation of the CREDAN operational architecture.
As discussed in section 2, the data owners collect and structure their data and metadata and apply access rights, such as local context labels, at the (sub)country level (Figure 3, box 1). The data package (data, metadata, provenance, and access permissions) is stored in the (off-chain) data hubs, from which they can be exposed for discovery. A hash value, unique to each dataset, is generated using a cryptographic hash function (e.g. SHA-256), as a digital fingerprint of the original data and metadata (Figure 3 boxes 1 and 2). Off-chain references are also allocated to enable linkage to the stored data.
The computed hash values and corresponding off-chain references are paired and registered on a blockchain network (Figure 3 boxes 1 and 2). New hash values (transaction IDs) are generated to represent these pairings, ensuring a secure and trackable link between the on-chain data and off-chain references. This is executed by smart contracts. The potential use of decentralised identifiers (DIDs) could add an additional layer of authentication and accountability by linking the data to the data authors and data users. Any change in the input data will generate a new hash, which can be shown as versions of an original dataset and its metadata (Figure 3, box 2).
Data users can access the data through a user interface direct to the blockchain. This will activate the creation of transaction IDs (hash values) to retrieve the off-chain references and provide access to the off-chain database (Figure 3, boxes 2 and 3). User access is governed by smart contracts to ensure secure, automated, and transparent management of permissions and interactions within the network. Once the user has the off-chain reference, they can access the data through the Data Hubs (Figure 3, box 3). Both data owners and data users would be assigned a unique DID and will establish a clear and immutable record of who created, modified, or interacted with the data. The data access transaction information provides complete provenance of what data was accessed and by whom (Figure 3, box 3). This facilitates trust in the environment.
This configuration can ensure enhanced community or country-level data sovereignty and control while improving regional data access and verification. This process aligns with the data governance principles of FAIR (Findable, Accessible, Interoperable, Reusable) and CARE (Collective Benefit, Authority to Control, Responsibility, Ethics) to ensure secure and responsible data management (Table 2).
Table 2
Criteria matching for the proposed network enabled by emerging technologies, including a possible alignment to the FAIR and CARE principles. FAIR acronym codes: Findable, Accessible, Interoperable, Reusable; CARE acronym codes: Collective benefit, Authority to control, Responsibility, Ethics.
| CRITERIA | WHAT CAN THE COLLABORATIVE DATA NETWORK ENABLED BY EMERGING TECHNOLOGIES DELIVER? | FAIR | CARE | ||||||
|---|---|---|---|---|---|---|---|---|---|
| F | A | I | R | C | A | R | E | ||
| Sovereignty | Offers flexible levels of sovereignty. | x | x | x | |||||
| Provenance | Created in the (sub)country hub, gathered by the coordinating group, comparable across network. | x | x | x | |||||
| Governance | The (sub)country hubs will manage their data holdings and permissions, the coordinating group ensuring that the necessary provenance, metadata, and vocabularies are maintained for each data object. | x | x | x | x | x | |||
| Innovation | Each (sub)country hub will remain autonomous but will be linked to others in the network, offering opportunities for regional data-driven innovations. | x | x | ||||||
| Collaboration | This model depends and builds on collaboration at hub level, and through discovery through the distributed network will demonstrate the values of collaboration. The governance group will maintain regular communications with all member hubs. | x | |||||||
| Access and Availability | A combination of controlled and open access allows for fine-tuned usage rules. | x | x | x | x | ||||
| Integrity and accountability | Combines centralised validation and distributed consensus processes. | x | x | x | |||||
| Security | The combination of centralised controls and distributed hubs enhances security. | x | x | ||||||
| Scalability | The distributed network built with on-chain and off-chain capabilities allows enhanced scalability. | x | |||||||
| Interoperability | Interoperability will be enhanced through the establishment of common standards across the network facilitated by the coordinating group(s). | x | x | ||||||
| Cost | Initial setup costs will be at the (sub)country and coordinating group levels, but a shared codebase will reduce development costs. Personnel will be an ongoing cost covered by each hub, and the cost of the coordinating group shared by all members of the network. Countries would be expected to need infrastructure funding, such as for computing hardware or enhanced bandwidth and energy capacity. Using a similar data hosting approach will streamline those requests, e.g., by offering proposal templates. | x | x | ||||||
| Energy Consumption | Data being held off-chain minimises energy consumption. | x | |||||||
3.2. Future opportunities
The integration of Large Language Models (LLMs) into the data exploration architecture could significantly improve the process by automating queries and analysis intents, allowing users to interact with data product information through natural language. This approach will simplify data search tasks for specific analyses and facilitate scientific discovery. The ability of LLMs to process and generate text with human fluency makes them ideal for this purpose, although there are challenges, such as the need to ensure transparency and accuracy.
The integration of generative computing for data exploration is incorporated into the data portal architecture (Figure 3, box 1) as a module for discovering and recommending data products. The data exploration module could offer a user interface in the form of a chatbot, which allows the construction of an integrated system with the APIs of LLM models, such as GPT-3, GPT-4, Llama, and Gemini, among others. These models can be used in specific versions according to the requirements, and, finally, a knowledge base will be used for training the LLMs.
4. Conclusions and Possible Implementation Pathway
This paper is concerned with presenting a scenario for individuals, communities, local entities, countries, and regions to assemble and record primary data about their lands in a safe, secure, and transparent manner. We recognise that there are many barriers to sharing data, including the fear that the information will not be treated with proper respect, and we have designed the CREDAN (Collaborative Regional Data Access Network) with the purpose of minimising this fear. The inclusion of blockchain technology is directed at ensuring this is achieved. We hope that, with the emerging categories under the CARE principles defined by the Local Context labels at local hub level (Figure 1), some of these challenges will be overcome. This will require time and sustained focus, and the governance provided by the coordination group (Figures 2 and 3) will be vital to success. The coordination group must ensure standards for data and metadata quality and integration, and ensure they are collaboratively determined and upheld. Management of the eventual large volume of data should be anticipated, and partnerships may need to be considered.
An implementation pathway is suggested below which starts with establishing a common intent, without which the creation of a collaborative network would not be possible.
Step 1: Establish a collaboration between countries and sub-countries and develop a common intent and goal for collating and preserving primary (raw) digital objects in their jurisdictions.
Step 2: Establish collaborative coordinating groups which determine general standards and protocols that each (sub)country can use (e.g., applying a suite of local contexts labels of relevance, determining a minimum schema for metadata, identifying existing vocabularies, and if new words are used, requiring a definition). This is important for enabling sharing across the network and beyond.
Step 3: Each (sub)country collects and stores (primary) data related to their area of responsibility using the common standards established by the coordinating group(s).
Step 4: Each (sub)country works with its communities to ensure that metadata, provenance, and permissions are established for each digital object according to the common standards.
Step 5: Each digital object is given a blockchain hash tag and off-chain reference, which immutably records the nature, rights, and permissions of each digital object established in Step 4.
Step 6: The collaborative coordinating group or (sub)countries (depending on the governance model determined), exposes the existence of these digital objects and the hashtags set.
Step 7: Data owners and users obtain unique DIDs to enable full-circle tracking of data acquisition and use.
Acknowledgements
The authors would like to thank the SPREP team for their assistance, in particular Tavita Su’a and Lagi Reupena, as well as Jope Davetanivalu, Rafael Tavita, and Vainuupo Jungblut for their support. We also thank Dr Stuart Chape, Director of Island and Ocean Ecosystems, for making the connections happen.
Competing Interests
The authors have no competing interests to declare.