
1. Introduction
Unlike traditional software engineering, where the primary objective is to attain specific features, typical ML approaches are characterized by their iterative and explorative nature: continuously refining and adapting not only code but also ML models to optimize results and performance on new data (Schlegel and Sattler, 2023). The rapid and cost-effective development of ML systems is impressive, but their long-term maintenance poses significant challenges and expenses which accumulates over time, as elaborated in (Fowler, 1999), and referred to as a technical debt in (Sculley et al., 2015). Painstakingly, metrics have to be tracked to optimize the performance among numerous models being developed, a process that usually involves error-prone manual logging. Furthermore, the lack of proper metadata description and inadequate versioning of data and models compounds the challenges, hindering effective management and reproducibility (Ruf et al., 2021). Preserving parameter information from each iteration step allows for efficient model reconstruction. Minimizing unnecessary trials and accelerating the overall development cycle is of importance (Amershi et al., 2019). As per the report “2020 state of enterprise machine learning” (Algorithmia, 2020), developing ML capabilities presents significant hurdles, such as need to scale infrastructure, maintain rigorous version control, attain model reproducibility, and effectively aligning stakeholders.
Moreover, the contextual understanding of data becomes increasingly vulnerable, as time passes and individual and group memories fade or staff members change positions. This erosion can lead to confusion or misinterpretation when the data or models are shared with a group, broader community, or the public. Therefore, to transform data into valuable digital assets, ensuring FAIR (Wilkinson et al., 2016) of ML artifacts including datasets, experiments, and models, has become a primary motive (Wang, Göpfert and Stark, 2016; Mozgova et al., 2020; Porter, 2005). In the realm of ML, applying the FAIR principles presents challenges, driving researchers to collaborate in pursuit of the optimal approach for implementing these guiding principles on data, tools, algorithms, and workflows (Ravi et al., 2022; Katz, Psomopoulos and Castro, 2021).
To address the problems of FAIRness of ML artifacts, this article introduces a comprehensive integration of a data repository (based on the Open Source software Dataverse (Dataverse, 2023)) and an ML platform (based on the Open Source framework MLflow (Mlflow, 2023)) for experiment and model sharing as well as publishing, ensuring the FAIRness of all ML artifacts. The presented workflow and tools are further evaluated using a practical ML use case scenario with model training, hyperparameter optimization, and model sharing via the Dataverse platform.
2. Related Works
This section presents a brief overview of the most relevant concepts and solutions within the context of the paper including ML lifecycle, MLOps and ML-related metadata.
2.1. The Machine Learning lifecycle
The ML lifecycle elegantly captures the entire evolution of an Artificial Intelligence (AI) system, encompassing its journey from the concept of requirements through realization to its deployment and retirement. A typical ML lifecycle includes various stages as shown in Figure 1, and each stage can occur one or multiple times during its lifecycle (ISO-23053, 2022). As mentioned in (ISO-23053, 2022; ISO-22989, 2022), the ML pipeline can be divided into inception, data-oriented, modelling-oriented, and operation stages.
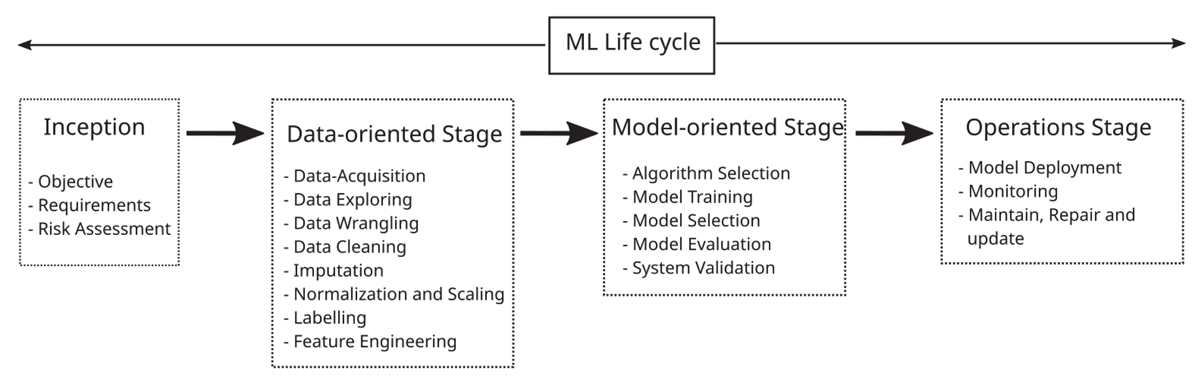
Figure 1
Typical ML lifecycle based upon ISO-23053 (ISO-23053, 2022).
During the inception stage, ideas are exchanged to formulate an ML objective, stakeholders contribute requirements, and the necessary resources for each ML lifecycle stages are determined (ISO-22989, 2022). This process meticulously evaluates and manages potential risks and benefits of AI systems, with a focus on ensuring ethically responsible deployment (ISO-23894, 2022). During this stage, neither data nor models are generated.
The data-oriented stage includes collection of raw data encompassing both internally generated or publicly available data. As data collected are seldom ready for an immediate ML training, it undergoes processes such as exploration, wrangling, cleaning, imputation, normalisation and scaling, labelling, and feature engineering (ISO-23053, 2022). It is crucial to note the impact of preprocessing on performance assessment, especially during comparative evaluations; inconsistent preprocessing, such as Human and Data based biases as explained in (ISO-24027, 2021), could unfairly favour one model over another and wrongly attribute the performance differences to downstream algorithms. In a similar way, the choice of training and validation data has its impact on performance assessment (ISO-4213, 2022). Therefore, it is essential to document datasets with raw data as well as preprocessed data. Applying different data cleaning or scaling techniques might result in a number of different datasets that are required to be preserved to further compare their performance during the model training. In this article, the term dataset(s) refers to collections of data within the context of Dataverse, encompassing any type of data—such as ML training data or ML artifacts (as explained later)—along with the metadata that describe these datasets.
The modelling-oriented stage spans from the model selection through model training and goes up to its evaluation and system validation. A model represents what the ML system has learned from the training data (Janardhanan, 2020). Selecting a suitable ML algorithm(s) is crucial, either from a library or by crafting a new one. After selection, the model is trained with the objective to generalise the production data. Depending upon the cases, overfitting (occurs due to insufficient training samples) or underfitting (when the model complexity is insufficient to properly learn on the training samples) may happen (ISO-23053, 2022). Hyperparameters are accessed and optimized based upon the validation dataset.
Then, the evaluation of the model takes place by comparing the predictions made by model on test data to actual labels in the data. During this stage, results of each viable experiment including the model, its parameters, and metrics should be preserved for a further comparison and analysis.
There might also be a case where a so-called source model is already existing and is combined using transfer learning with more specialized data to get a more specific model (Amershi et al., 2019). This approach is the state-of-the-art for computer vision in different areas, e.g., in the process industry (Khaydarov, Becker and Urbas, 2023). In such cases, the pretrained or source models must also be accessible and iteroperable to enable their seamless integration within the MLOps workflow (see section 2.2).
After training and evaluation, the ML model moves to deployment for predictions on production data. It can be deployed on servers, clusters, VMs, or Docker containers. To enhance system interoperability, packaging in open formats like Open Neural Network Exchange (ONNX) (ONNX Standard, 2023) or Neural Network Exchange Format (NNEF) (NNEF, 2023) is recommended. Once deployed, proper training and support to the AI system is important for the users to enable effective use of the product, such as guidance for appropriate deployment and limitation of the system. After the model has been deployed, it is advisable to have a monitoring of its performance. Like conventional software systems, the model needs maintenance and regular update based on new data. Over time, deployed models might become outdated due to evolving societal trends, practices, and norms, warranting decommissioning and replacement with improved AI models becomes necessary (ISO-22989, 2022; ISO-24027, 2021). Therefore, the models must be regularly monitored by evaluating their performance on actual data. The information from the evaluation should be preserved in order to be able to analyse the model performance over time.
2.2. Machine Learning Operations – MLOps
The usual ML development workflow outlines an incremental ML pipeline, characterized by a script-based, manual approach that encompasses data analysis, preparation, model training, testing, and deployment. However, it might lack an automatic feedback loop and seamless transitions between tasks, hindering the full potential of an efficient and adaptive ML workflow. MLOps aims to address this challenge by integrating Software Development and IT Operations (DevOps) practices and implementing automation throughout the ML pipeline, thus streamlining and expediting the process involved in model building, testing, and deployment (Ruf et al., 2021). As a result, the adoption of MLOps has gained momentum across diverse domains, including healthcare (Khattak et al., 2023), medical device software development (Granlund, Stirbu and Mikkonen, 2021), manufacturing processes (Faubel, Schmid and Eichelberger, 2022), drug discovery (Spjuth, Frid and Hellander, 2021) and beyond. The main advantage of applying MLOps techniques is the gained ability to automate the processes such as data preprocessing, modelling, deployment, and monitoring.
2.3. Tools for MLOps
Several types of tools have been developed for the ML lifecycle to follow the MLOps principles. For example, ModelDB is a valuable tool in the field of computational neuroscience, enabling the sharing of models through source code archiving (Mcdougal et al., 2017; ModelDB, 2023). Likewise, OpenML serves as another platform for ML model sharing, but requires manual configuration of the environment, which can be cumbersome (Rijn et al., 2013). In contrast, Acumos AI offers a user-friendly platform for model packaging in Docker images, eliminating the need for environmental restrictions (Zhao et al., 2018). An extensive comparative study of different platforms can be seen in (Schlegel and Sattler, 2023; Zhao et al., 2018; Janardhanan, 2020; Ruf et al., 2021; Schlegel and Sattler, 2023). The choice of tools depends upon the requirement of ML application as mentioned on Ruf et al., 2021.
MLflow emerges as a particularly promising solution among them for our use case, which is the classification of flow regime in bioreactors as mentioned in (Kröger, Khaydarov and Urbas, 2022). In MLflow, it’s important to understand a few key terms such as run, runID, and experiment. An MLflow run refers to a single execution of model training or evaluation within an experiment. Each run is defined by its unique runID that serves as an identifier of the run. An experiment, in turn, is a logical grouping of one or more MLflow runs. It represents a set of runs associated with training models for a specific problem, each with its own parameters and metrics. For more details, please refer to the official MLflow documentation (Mlflow Documentation, 2023).
2.4. FAIRness in the ML lifecycle
While MLflow offer numerous advantages in the realm of model training, model management, model deployment, and other general requirements (Ruf et al., 2021), like other tools aforementioned, it also falls short in certain criteria of the FAIR Principle (Wilkinson et al., 2016), such as providing comprehensive explainability (description) of projects and models, along with metadata to enable effective searchability.
In addition, it also lacks built-in users management and like other ML tools, relies on users to manage local or shared storage systems (Mlflow Documentation, 2023), posing a challenge for seamless sharing with the wider community under a unified global identifier like a Digital Object Identifier (DOI).
To tackle the challenge of better description of the ML life-cycle, in previous work we presented a solution that involves leveraging the capabilities of a Open Source data management software, Dataverse (Dataverse, 2023), which offers an added advantage of incorporating customized metadata. With an aim to effectively manage and share ML related research data in chemical process engineering, a metadata schema called Process Engineering/Industry Metadata Schema (ProMetaS) (Sherpa et al., 2023) was developed. This schema is an outcome of a research project KEEN, which focused on applying AI within the process industry, more info at (Bortz et al., 2023; KEEN Project, 2024). The ProMetaS contains schema of several categories; however, the machine learning category (as shown in Figure 2) is of interest for this purpose. The machine learning category facilitates comprehensive documentation of critical details such as model information, hyperparameter studies, training runs, and more. The Machine Learning category within ProMetaS encompasses key artifacts of the machine learning process. This includes metadata for datasets, training runs, models, predictions, model evaluations, and hyperparameter studies. For more details, see Sherpa et al., 2023. Hyperparameter studies, in particular, represent a series of training runs with varying hyperparameter values, forming the foundation of design of experiments. The primary goal of ProMetaS is to semantically link these diverse ML artifacts, creating meaningful connections between them. ProMetaS is integrated into Dataverse in accordance with the customized metadata guidelines detailed in the Dataverse admin guide (Dataverse Manual, 2023).
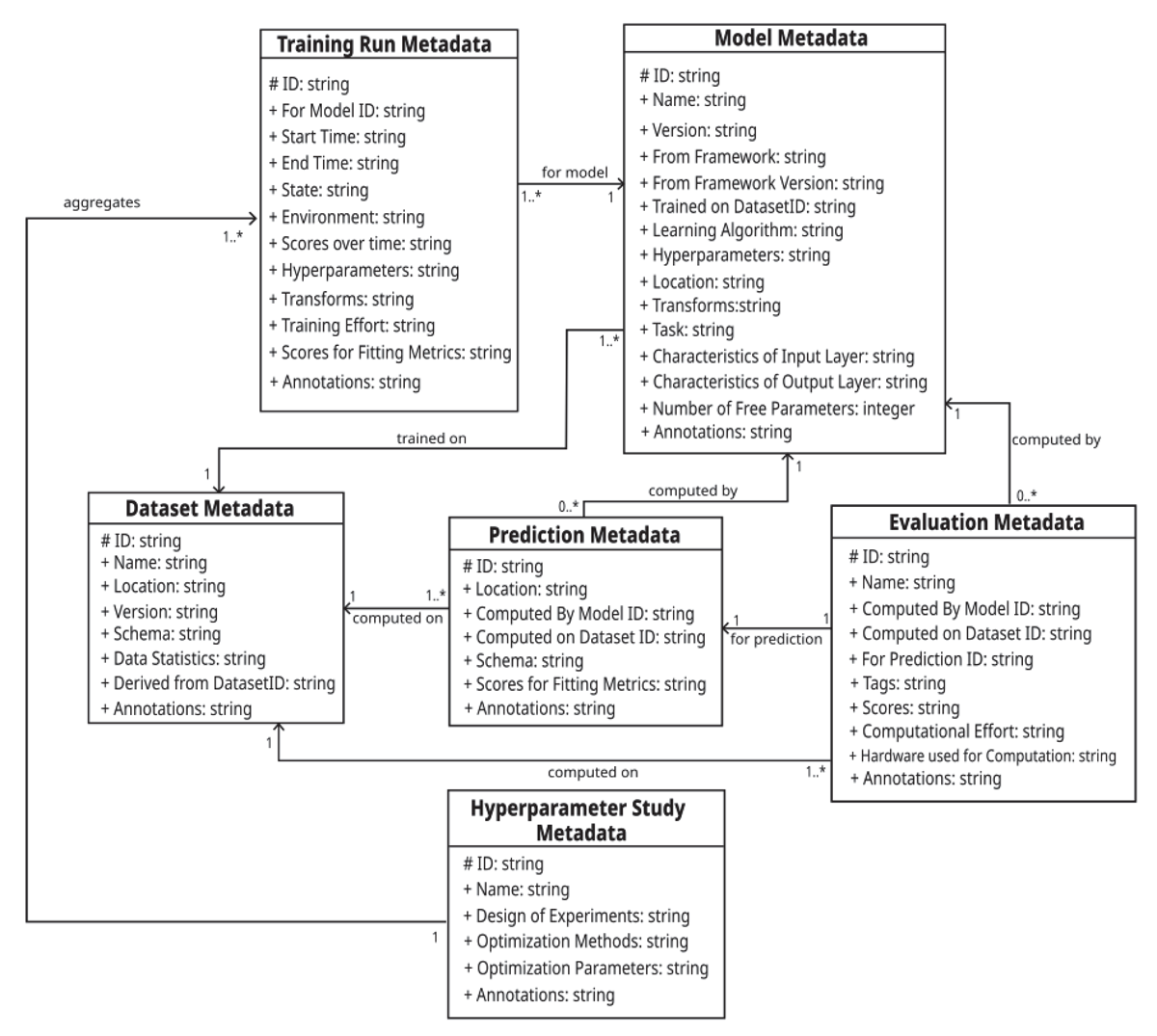
Figure 2
Enhanced Overview of Machine Learning category in ProMetaS (Sherpa et al., 2023).
3. Integrating MLOps and the FAIR Management of ML Artifacts
In this section, the enhancement of FAIRness in the ML lifecycle is illustrated by seamlessly integrating MLOps principles and FAIR data principles. The goal consists of following key facets: (i) improving the documentation of ML artifacts throughout the whole ML life-cycle with metadata; (ii) managing the ML artifacts and their metadata by incorporating a data management system; and (iii) providing automation of this process to eliminate error-prone manual work.
Although attaining these objectives posses challenges, a viable solution involves formulation of a comprehensive system that incorporates both FAIRness principles and MLOps practices. A promising approach is to integrate a robust data management system, addressing the FAIRness aspects of the data, with MLOps tools dedicated to efficient machine learning lifecycle management. For our specific use case, Dataverse and MLflow has been selected leveraging their combined capabilities and as described in section 2.3 and 2.4.
3.1. An infrastructure for FAIR MLOps
Due to our preliminary work and our use case (see section 4.1), we chose the following three tools for our integrated FAIR MLOps infrastructure:
MLflow to support MLOps
Dataverse as data repository for data management
ProMetaS metadata schema for ML artifact documentation.
As mentioned in chapter 2.4, ProMetaS– including the machine learning metadata category–has been already incorporated into Dataverse, making it available for use. In Sherpa et al., 2023, we have shown how we used it to automate the data documentation process to FAIRify the data set used in the training.
Now, we want to focus on the FAIRification of two other ML artifacts: (i) sharing of ML models (as MLflow models) and (ii) sharing of the ML code (as MLflow projects) that was used for the generation of the model. We created a python library Dataverse MLflow Integration Library (DMIL) for the integration of and interaction between MLflow and Dataverse–both for MLflow models and MLflow projects. For the communication between these two tools we used the Representational State Transfer (REST)-Application Programming Interface (API) of Dataverse. The primary objective of this modular library is to enable effortless sharing of models and projects accompanied by automatic metadata extraction for convenient reuse.
3.2. Sharing MLflow model
With the help of MLflow, several models can be generated by tweaking its hyperparameters. The generated models can be compared based upon predefined metrics. Once the best model has been selected, it can be shared via Dataverse by utilizing the DMIL model module.
Figure 3 illustrates the sharing of models with our tool set. If user 2 wants to upload his model to Dataverse, the following process has to be gone through utilizing our library.
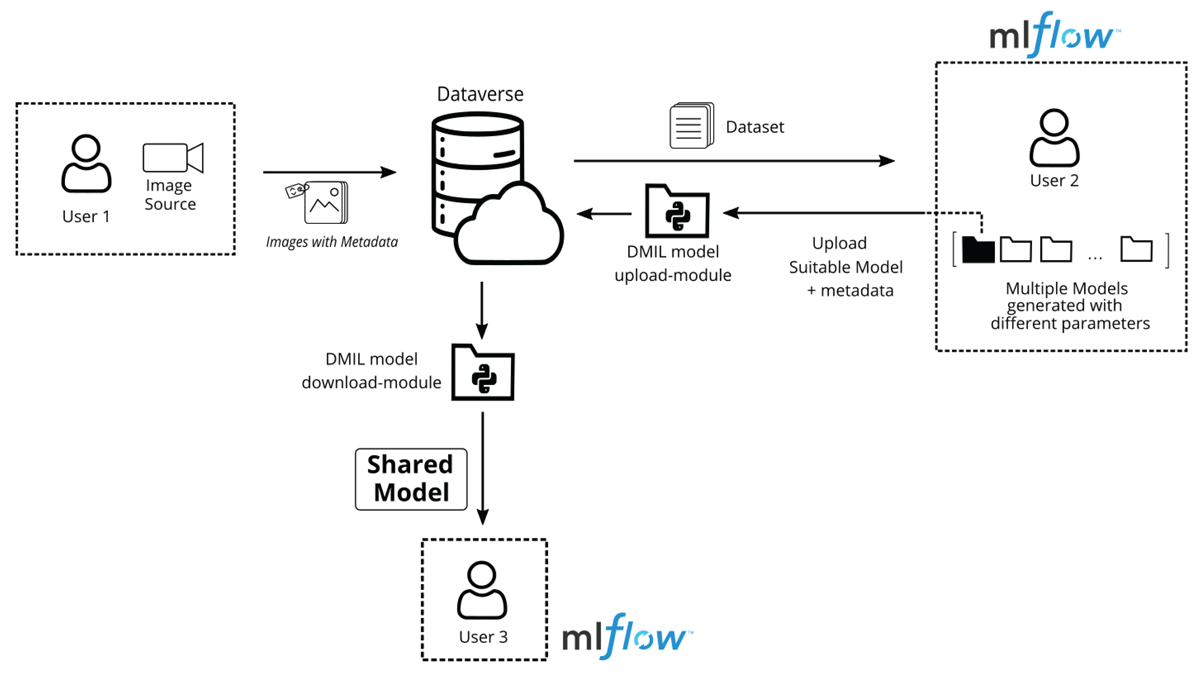
Figure 3
Sketch of Dataverse-MLflow integration of models.
A connection is established with Dataverse via REST API, using the credentials of a user. The credentials include Dataverse instance URL, API keys and Dataverse Collection ID as mentioned in (Dataverse Manual, 2023).
The primary location where the MLflow models are being generated in local machine, is provided, refer (Mlflow Documentation, 2023). The runID of the model using MLflow UI is also provided.
Using the DMIL model upload-module, a dataset with a DOI is created. All the contents of the model runID are uploaded into Dataverse along with the metadata. The extracted metadata are mapped with ProMetaS ML category and saved.
The dataset will be created initially as a draft which is visible only to the user. The user can therefore use a private URL- function provided by Dataverse to share the created dataset with individuals or publish it among larger community.
To download and reuse models, our library provides an automated workflow as well:
A connection is established with Dataverse via REST API using users’ credentials as mentioned above.
Dataverse provides a search function from which the dataset of interest can be selected by the help of metadata. Then, the DOI of the dataset is provided.
Using the python-library, the whole model folder is downloaded from Dataverse and stored in a temporary folder. MLflow offers multiple ways of loading a model. We use the python_function model, which allows interoperability across diverse environments (Mlflow Documentation, 2023) for our usecase as described in section 4.
The downloaded model can be tested with new datasets for validation and beyond, or could be directly deployed as local REST API or Docker images which are already provided by MLflow.
3.3. Sharing MLflow project
In a similar fashion, the user might want to share the code, so others could generate improved models from their own datasets or improve the algorithms. With the aid of MLflow projects, reproducible software runs are effortlessly achieved with the standard packaging format ONNX (Schlegel and Sattler, 2023; ONNX Standard, 2023), encapsulating the entire data science codes for optimal reusability and reproducibility. The DMIL project module for the upload and download of MLflow project provides a seamless interaction with Dataverse. The processes (see Figure 5) are similar to the ones of the model sharing.
Upload of an MLflow project:
The user has to provide the MLflow project folder containing essential components as described in (Mlflow Documentation, 2023), such as MLproject file, configuration file, and main Python file(s), all of which are initially zipped.
A connection is established from the user’s computer to Dataverse via the REST API using the user’s credentials.
The DMIL project upload module creates a dataset with DOI and the contents of zip along with its metadata are added on the dataset with original folder structure.
The metadata to be filled is customizable and can be modified to extract further metadata/information from the files inside the project.
Download of MLflow project:
A connection is established from the user via the REST API, using the user’s credentials.
The user searches for the project to download using the search function of Dataverse.
The project folder is downloaded from into a temporary folder on the user’s computer, where MLflow can run the program.
MLflow supports several environments; however, a conda environment is taken for this case. The conda environment installs necessary packages/environment variables required for the project and then executes the code. The executed code creates an ML model and then saves it on the local machine.
In addition, as the models generated are sensitive to the hyperparameters, several models could be generated using this module shared from Dataverse, and comparison of the models could be done on the Graphical User Interface (GUI) interface of MLflow.
3.4. Automated metadata extraction in MLflow
MLflow provides a two-layer structure to organise the runs (each run corresponds a single training routine). The higher level is called experiments. An experiment aggregate a set of runs that are related to one task and, therefore, have the same metadata attributes. On the run level, MLflow organizes its metadata into five major groups: experiment metadata, parameters, metrics, model-related and environment related metadata, and tags. Experiment metadata contains general information about runs, including start and end time, the current status of the run, and so on. Parameters are considered as values that impacts the model. Apart from the model and training hyperparameters, they also include dataset-related information such as which dataset was used for training. If parameters might be considered as the inputs of the training routine, metrics represent the outputs and usually contain the model performance metrics. Further, MLflow provides its own format for packaging machine learning models. The format includes model and environment-related metadata such as the creation time of the model, run id, model input, output, and parameter signatures. Besides the pre-defined metadata attributes, MLflow also offers a customizable metadata field name tags. Each tag has its name and value. Tags might be created as to the experiments well as to the runs.
All metadata on both levels are available via Python API of MLflow or parsed directly from the MLflow project files if stored locally.
4. Evaluation
4.1. Use case
The approach proposed in this paper was validated using a real-world use case of flow regime classification in bioreactors as extensively described by Kröger, Khaydarov, and Urbas (2022) and Khaydarov, Becker, and Urbas (2023). The main aim of the use case is to classify flow regimes in a bioreactor. Images of visually identifiable patterns of gas bubbles in the liquid phase are analysed using neural networks. The process is sketched in Figure 6. The overall workflow from data collection to model monitoring is depicted in Figure 7.
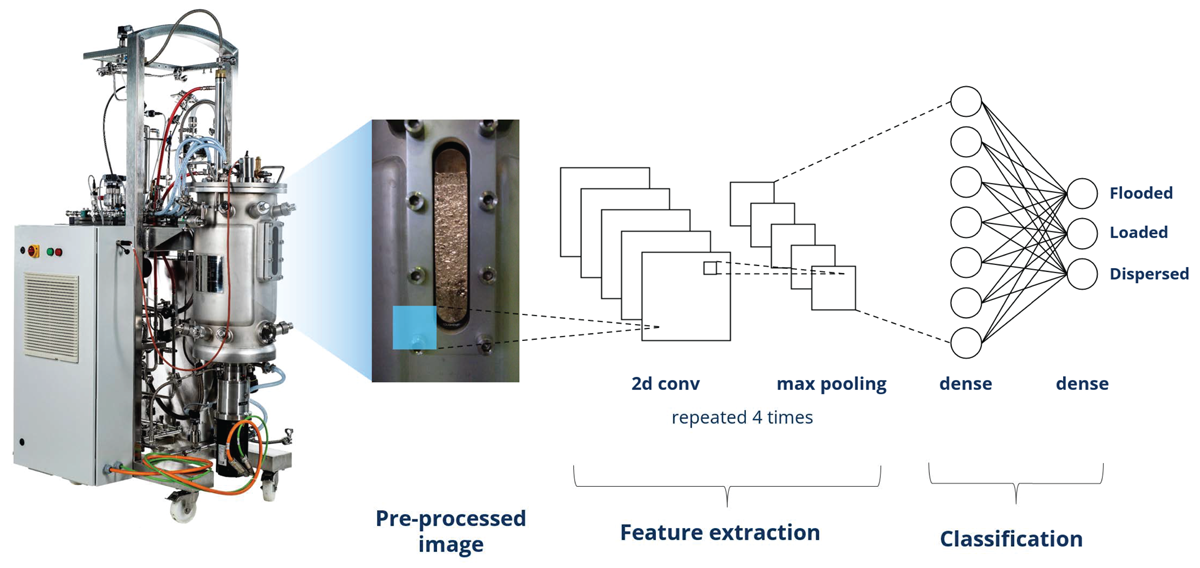
Figure 6
Flow regime classification using image data.
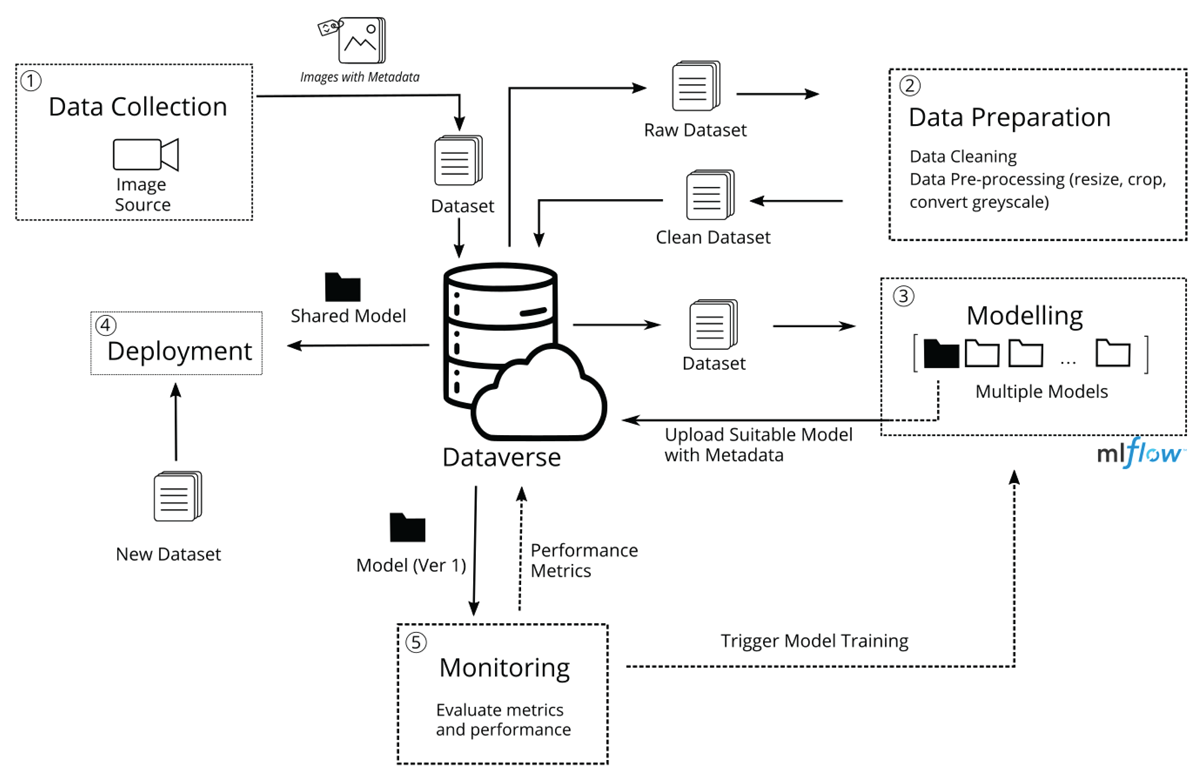
Figure 7
Workflow Demonstration of Dataverse-MLflow. (1) Image data is collected and uploaded to Dataverse along with metadata. (2) The dataset is cleaned and preprocessed. (3) A suitable model is selected from a collection and uploaded to Dataverse. (4) The shared model is deployed. (5) The performance of the ML model is monitored using predefined metrics.
4.2. Data collection and preprocessing
Several datasets under different lighting conditions, camera position, and camera settings were initially collected. Then, various image preprocessing techniques such as edge detection, smoothing filters, etc., were applied. Apart from that, different image sizes were tried. This resulted in a large number of datasets with preprocessed data. Due to the overall complexity of working with a large number of datasets, the Dataverse platform was chosen to store datasets with their metadata. To automate the work and exclude manual error-prone steps, several stand alone software components (modules) for data managing were developed that can be used independently from each other to address concrete tasks such as direct upload of raw image data with its metadata from the camera to the Dataverse plattform, accessing images from Dataverse directly in Python as a generator that returns numpy arrays, and upload of numpy arrays as preprocessed images to Dataverse. Since image data is directly accessed in Python without an intermediate storage on the local disk according to the Data-as-code concept, there is no risk of using a false dataset or a modified one by mistake (ISO-24368, 2022) due to the necessity of copying. Thus, the data integrity is ensured between all data sources and sinks, let it be a workstation or a High Performance Computing (HPC) used for model training. The approach proposed in this work has made the collected data findable, accessible, and highly reusable. The datasets are published in Dataverse with clear, descriptive metadata, and they can be programmatically switched between for training.
4.3. Model training
During the model training, we used the Pytorch Data API to access the data directly from Dataverse as a generator. Because the model training was carried out on a HPC with a GPU, we avoided the step of copying data from the workstation to the HPC.
The model parameters were logged using the MLflow framework each time a model training was started, and the metrics and the model itself were updated as the training process was finished.
As design of the experiments, we used a three dimensional design space with four types of deep learning models (AlexNet, VGG16, ResNet50, and DenseNet121), three transfer learning techniques, and seven various dataset sizes as showed in (Khaydarov, Becker and Urbas, 2023).
However, the parameters, metrics, and models were only accessible locally and could not be shared with the scientific community or linked in a publication with DOI to make them FAIR. Thus, we used DMIL to automate the export of the experiments (models and code) to our Dataverse platform simplifying the process of sharing and increasing their accessibility and reusability.
Everyone who has the access can review the model using the metadata stored and use the DMIL download to import the MLflow experiments stored on Dataverse directly into their MLflow instance, including all artifacts, parameters, metrics, and metadata information, as depicted in Figure 4.
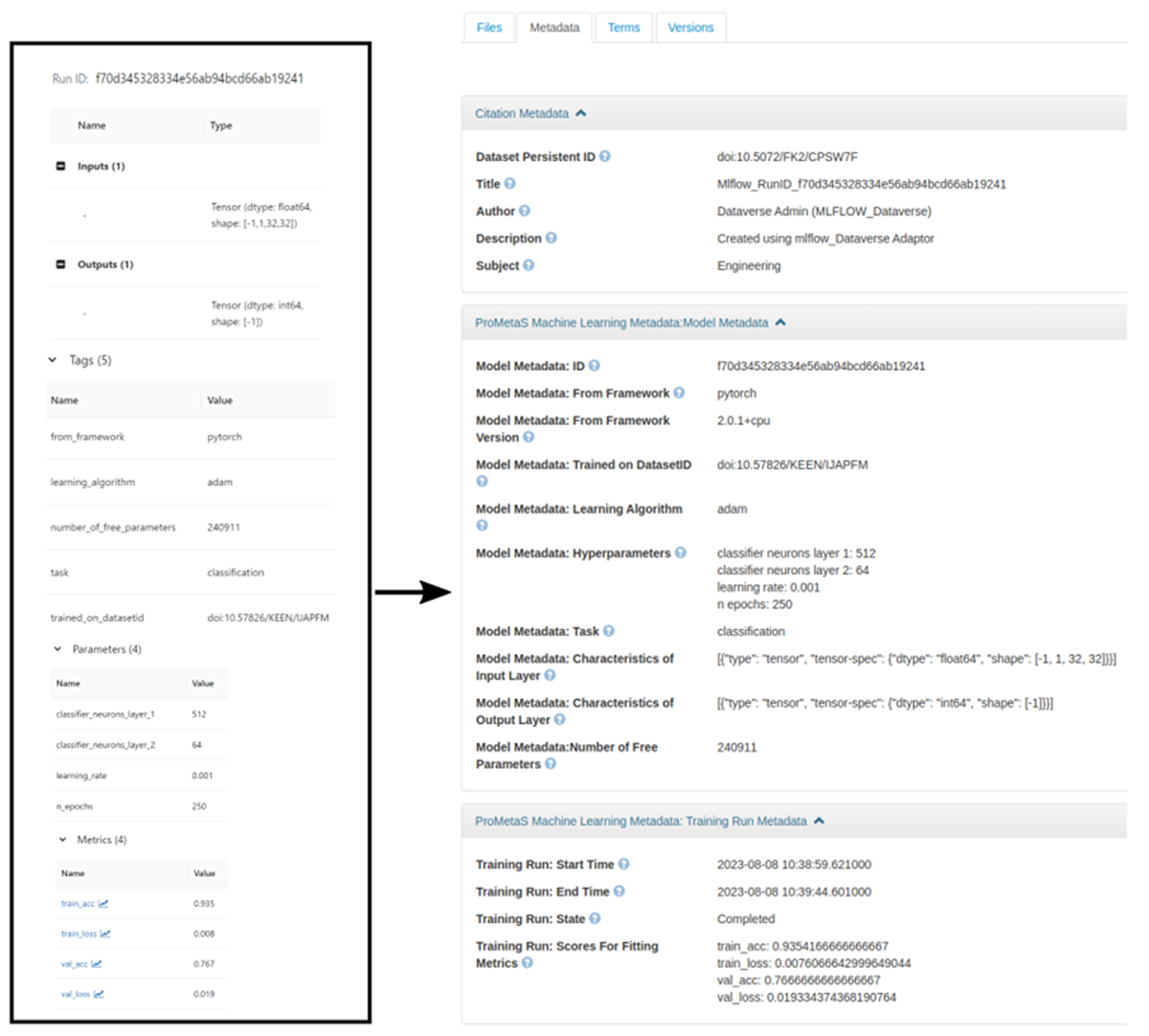
Figure 4
Incorporation of Metadata from MLflow (left) to Dataverse with ProMetaS schema(right) using DMIL model module.
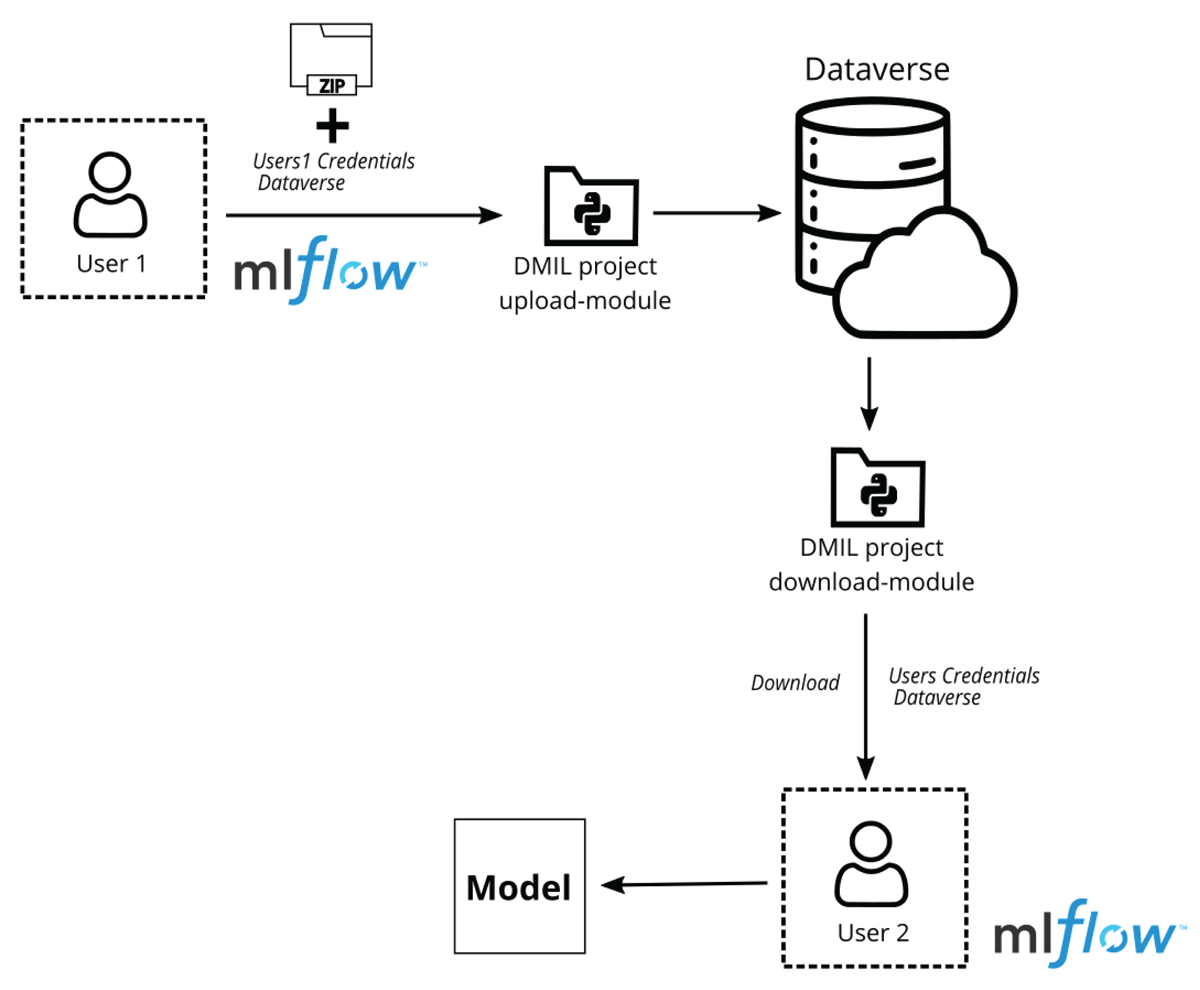
Figure 5
Sketch of Dataverse-MLflow integration of projects.
4.4. Using DMIL for model deployment
The integrated infrastructure can be used not only for experiments, but also for the deployment of models for production. Because the model is accessible via Dataverse, it can be imported, for instance, on an edge device in an automated manner. In our use case, the model was imported and deployed using locally on a smart camera Baumer VAX-50C.I.NVX. It was done by running a code that downloads the model from the Dataverse platform and deploys it using MLflow. Due to the unified format for model deployment, our approach achieved high interoperability during the deployment stage.
4.5. Limitations
Despite the benefits of the proposed solution, a current limitation is its slow performance. Data (images, models, etc.) and metadata are accessed via the REST API. Since we implemented the access to single files only, it gives a relatively high performance overhead of forming a request and processing its answer. Accessing a single data instance with one image and a metadata yaml file, takes on average 0.35 seconds. For comparison, loading a data instance locally requires only 0.01 seconds. The data are from a conduced benchmark with a dataset with 1000 instances, each data instance presents an png 250 × 1040 pixels image and a json file with around 250 attributes each. In total, a data instance is around 120 KB of data. For model training, where we need to access many files, this resulted in a situation where the overall duration of the training process was negatively impacted. One possible solution is to implement a file cache for downloaded files or use the functionality to download multiple files as a single zip file. Alternatively, data caching techniques, as referenced in Tyson et al. (1995) and Shuja et al. (2021), could also be applied.
5. Conclusion
Due to its experimental nature, the development of an ML application is a longer process. Without a proper experiment tracking that stores metadata of each experiment and trained model data, it is not easy to review and share models or code of the various stages of the development process. Considering the re-use, reproducibility, or evaluation of an ML application, the FAIRness of the experiments, models, and dataset plays a major role for trust in the ML approach. Although MLOps tools, like MLflow, provide means to track ML experiments and trained models, they lack some aspects of FAIRness.
This paper presented an approach to integrate an MLOps tool (MLflow) with a data repository (Dataverse). With our library DMIL, we showed how a tight and automated integration helps researchers to improve the documentation of their ML experiments and to better support the FAIR management of ML artifacts like ML models and projects. The proposed idea is not limited to this use case; it could also be extended to areas such as healthcare, finance, and autonomous systems, where it could offer significant benefits. As a future work, a comprehensive performance benchmarking could be conducted to highlight the benefits and limitations of this approach. This would include comparisons with traditional methods in terms of processing time, accuracy, efficiency, and performance across varying data sizes and complexities.
Funding Information
We are grateful to BMWK (German Federal Ministry of Economic Affairs and Climate Action) for their financial support (Support code 01MK20014T).
Competing Interests
The authors have no competing interests to declare.