
Introduction
For proponents of open data and open science in the United States, the 2013 release of the White House Office of Science and Technology Policy (OSTP) memo, Increasing Access to the Results of Federally Funded Scientific Research (often referred to as the Holdren memo), was a monumental event that recognized and propelled the trend toward research data sharing and associated standards development. The memo directed certain federal agencies to develop plans for public access to the results of funded research, including data. Since then, the expansion and implementation of nascent standards and infrastructures, such as the FAIR principles (Wilkinson et al., 2016) and ORCID identifiers, have been energized to facilitate effective data sharing (Young, 2022). Concurrently, academic libraries and research institutions have grappled with how to support researchers in meeting these requirements.
Now, over 10 years since the release of the Holdren memo, we seek insight into the role institutional repositories play in the knowledge infrastructure ecosystem for research data sharing and stewardship. This inquiry is occasioned by two federal requirements, the OSTP memo Ensuring Free, Immediate, and Equitable Access to Federally Funded Research, and the guidance document from the National Science and Technology Council, Desirable Characteristics of Data Repositories for Federally Funded Research’ report, both released in 2022. Another move that underscored the commitment to open science was NASA’s declaration that 2023 was the year of Open Science, a milestone initiative that many federal agencies joined (Gentemann, 2023). Concomitantly, the last decade has seen an increase in data sharing requirements from publishers and non-profit scientific research organizations (e.g., Herndon & O’Reilly, 2016). Non-federal funders have also implemented open information and data sharing requirements without being compelled by federal compliance regulations. As such, one premise of our paper is that the OSTP memo of 2013 played a crucial role in pressuring the adoption of research data sharing requirements and therefore data sharing by funded researchers, and that these 2022 communications will have a similar impact.
This paper examines current practices and future trends in research data management infrastructure at universities and colleges. We make the distinction between institutional repositories (IRs), which are typically developed and implemented to collect and steward the teaching, scholarly, and creative outputs of their home institutions, and institutional data repositories (IDRs), which are focused more narrowly on publishing the research data outputs of the institution. As data sharing requirements became more common and elaborate, many university-based libraries began to build data repositories to complement their IRs. Both IRs and IDRs are part of a larger ecology of knowledge infrastructures, which are described by Edwards et al. as ‘ecologies or complex adaptive systems’ that ‘consist of numerous systems, each with unique origins and goals, which are made to interoperate by means of standards, socket layers, social practices, norms, and individual behaviors that smooth out the connections among them’ (2013, p. 13). To understand institutional repositories as knowledge infrastructures, and thus composed of interoperating systems in this sense, we situate them in their typical institutional homes: research libraries. As Borgman & Bourne (2022) explain:
Libraries have a long history of stewarding the scholarly record, whether in analog or digital media…. They have the necessary expertise in preservation, data curation, data management, data governance, archiving, records management, and conformance to standards. Libraries also have taken a central role in training researchers how to develop data management plans for the NIH, NSF, and other funders. (p. 7)
After briefly contextualizing this research in the broad landscape of IR and federal policy development, we take a mixed-methods approach to investigating the status of institutional data solutions. First, we quantify trends in the adoption and use of IRs and IDRs by the higher education members of the Association of Research Libraries (ARL) since 2017, aggregating data from two prior studies to which we add new data collected for this study in 2023. This integrative approach (Pasquetto et al., 2019) allows us to leverage previously collected data to generate an analysis over time and to project trends. We find that researchers continue to deposit data locally, are doing so at an increasing rate, and that research libraries are adopting (or sometimes enhancing) purpose-built IDR platforms to support this stewardship.
Then, having established that both universities and researchers continue to invest in these infrastructures, we provide a qualitative analysis of IRs and IDRs in light of the 2022 Desirable Characteristics of Data Repositories for Federally Funded Research report. We treat IRs and IDRs as knowledge infrastructures, as described by Edwards et al. (2013), with attendant standards, practices, and behaviors that make them function, and offer an ‘infrastructural inversion’ (Bowker & Star, 1999) that elevates the affordances provided by data repositories that are institutionally managed (both IRs and IDRs), including and exceeding those characteristics described in the report. This allows us to use the conceptual lenses of the robust ‘installed base,’ with its attendant inertia, and ‘articulation work’ (Bowker & Star, 1999) to describe how institutional repositories (including librarians in their roles as data stewards) function as established infrastructure and how, through local interoperability processes, they advance authority, control, credibility, and compliance.
Background: Institutional Repositories, Institutional Data Repositories and the Federal Policy Context
Development of institutional repositories and data repositories
Institutional repositories, typically hosted at and maintained by libraries, have been understood as an essential scholarly communication infrastructure since the early 2000s (e.g., Crow, 2002; Lynch, 2003). At academic institutions, generalist IRs came into use throughout the 2000s and 2010s as individual institutions and consortia sought avenues to support researchers in disseminating scholarly works and to bolster the burgeoning open access movement (e.g., Whitehead, 2023; Branin, 2005). These generalist IRs were designed to accept or support the research and teaching outputs of members of the institution itself across all disciplines, in many formats and resource types, including manuscripts, theses, datasets, digital art, and other materials with no obvious outlet for publication.
As they began filling a digital infrastructure gap, institutional repositories initially struggled with a variety of socio-technical issues that limited adoption. For example, Salo (2007) argued that institutional repository proponents struggled to capitalize on the open access movement because of a lack of incentive for researchers, limited technical connections between institutional infrastructure and the IR, and general usability limitations of repository technology. Later, Joo et al. (2019) surveyed academic librarians to better understand these challenges across six categories: data, metadata, technology, patrons, data ethics and ownership, and internal administration. Specific data sharing challenges emerged from Joo et al.’s (2019) study, including: data size; the requirement that data be ‘finalized’ before deposit; data quality assurance; managing diverse data formats; and coping with the constant deluge of data submissions (Joo et al., 2019).
Despite imperfections, IRs provide crucial benefits for scholarly communication. Due to their function as discipline and format agnostic platforms, IRs seem to increase citation count (Demetres et al., 2020) and the discoverability of the research and scholarly outputs they contain. Importantly, the generalist nature of IRs can also be critical for providing online access to niche or cutting-edge research that does not have a clear place for sharing or publication (Stone & Lowe, 2014). Maintained by institutions of higher education, IRs benefit from relatively stable funding and typically have a commitment to long-term preservation and persistent access, enhancing their sustainability over non-institution based repositories (e.g., Strecker et al., 2023).
Since their development, many IRs have accepted deposits of different formats, including datasets. However, as data sharing continued to increase in demand, some institutions experienced the challenges of fitting data into a workflow meant for a different type of scholarly output, primarily publications. For this reason, many institutions began to build data repositories to complement their IRs. We refer to these as institutional data repositories (IDR) to indicate their similarity with IRs in terms of institutional purpose, management, staffing, and technologies. Dataset stewardship requires specific considerations, such as curation, versioning, licensing, and distinct metadata schemas. While IRs can and do store research data and make it available for sharing, IDRs are purpose-built to host and share research data, and enable the stewardship, including curation, sharing, and preservation, of deposited data over the long term. For the purposes of this research, we make the distinction between IRs and IDRs to discuss the adoption and development of data-specific infrastructure.
Institutionally managed repositories, by which we mean both IRs and IDRs, constitute just one aspect of infrastructure within a larger and increasingly complex ecosystem of repositories. Data sharing efforts in the United States, and globally, have been supported for decades through other disciplinary or generalist repositories, many of which pre-date IRs and IDRs by decades. For example, ICPSR, the Inter-university Consortium for Political and Social Research, was founded in 1962 with the Survey Data Archive. Similarly, LTER, the Long Term Ecological Research Network, has been supporting ecological researchers around the world in managing and sharing research data since the 1980s. These venerable data archives are abiding examples of research data support. Since then, the number of disciplinary and generalist repositories have proliferated. However, while some of these repositories have established funding mechanisms and organizational sustainability, many other self-described disciplinary and specialist repositories are at risk of deprecation, with or without a sunset process (e.g., Strecker et al., 2023). For these reasons, among others discussed below, institutional repositories and institutional data repositories have filled an essential role in scholarly communication.
Federal policy developments in data sharing
The 2013 OSTP memo, Increasing Access to the Results of Federally Funded Scientific Research (hereafter referred to as the Holdren memo), indicated an attention shift toward infrastructure for data stewardship. The Holdren memo directed federal agencies with over $100 million in research and development (R&D) expenditures to develop policies requiring grant recipients to share research outputs (Holdren, 2013). This requirement was expanded in August 2022 with the release of the follow-on memo, Ensuring Free, Immediate, and Equitable Access to Federally Funded Research (hereafter referred to as the Nelson memo). The Nelson memo directed all federal agencies, regardless of their R&D expenditures, to require public sharing of funded research data and scholarly outputs (Nelson, 2022). The release of the Nelson memo reinvigorated discussions about the tensions between facilitating sharing research outputs in line with accepted standards such as the FAIR Data Principles (Wilkinson et al., 2016) and the TRUST Principles for Data Repositories (Lin et al., 2020), and the constraints of resources and technologies available to the institutions charged with this facilitation.
A key federal policy communication central to our discussion was released a few months prior to the August 2022 release of the OSTP Nelson memo: the National Science and Technology Council Subcommittee on Open Science released the report, drafted and finalized after public comment, titled Desirable Characteristics of Data Repositories For Federally Funded Research (hereafter referred to Desirable Characteristics) (White House OSTP 2022). This report outlines ideal features (and potential future requirements) for the repositories used to store and make funded research data publicly accessible. In turn, the Desirable Characteristics report was referenced explicitly in the Nelson memo: ‘[f]ederal agencies should also provide guidance to researchers that ensures the digital repositories used align, to the extent practicable’ with these features (Nelson, p. 4). These policy statements send a clear message: not only must funded research outputs, including those considered data, be made publicly available, but also the infrastructure to host this data should increasingly conform to a set of requirements that make data findable, accessible, interoperable, and reusable. These statements allow wide latitude for researchers to follow disciplinary norms, which may have slowed adoption of recognized standards and practices for sharing and preserving data.
The Desirable Characteristics report addresses this disconnect, and identifies a ‘consistent set of desirable characteristics for data repositories that all agencies could incorporate into the instructions they provide to the research community for selecting data repositories’ (White House OSTP 2022, p. 1). The document is intended to guide researchers and institutions as they evaluate and select from existing repositories to deposit data. However, as the authors acknowledge, ‘the desirable characteristics provided by this guidance document are not intended to be an exhaustive set of features for data repositories; rather they represent general capabilities for researchers, agencies, and institutions to prioritize when selecting repositories to share research data’ (p. 3). Though there have been other efforts to coalesce consensus on a minimum feature set for data repositories (e.g., Lin et al., 2020; CoreTrustSeal Standards and Certification Board, 2022), they lacked the persuasive momentum of a big industry or policy player. For this reason, the document marks a watershed moment for evaluating, envisioning, and advocating for institutional repository development to align with the FAIR Data Principles (Wilkinson et al., 2016) for reliable, long-term stewardship of data.1 We turn to an examination of Desirable Characteristics and IRs and IDRs later in the paper.
Data Stewardship Growth in Institutional Infrastructure
Study methodology
In this first part of our mixed-methods study, we provide a quantitative analysis of the adoption and use of IRs and IDRs for data sharing and stewardship. Our analysis integrates data we collected in 2023 with data from two previous studies: the Association of Research Libraries (ARL) Spec Kit 354: Data Curation (Hudson Vitale et al., 2017) and Data Sharing Readiness in Academic Institutions (Johnston & Coburn, 2020). This approach allowed us to leverage previously collected data in conjunction with newly collected data, enabling a comprehensive view of data stewardship trends over time, 2017–2023.
All data are based on studies from the same library group and recorded key variables: institutional and data repository presence, and the quantity of datasets managed within these systems. In 2017, Hudson Vitale et al. surveyed the 124 research libraries that were ARL members at that time. Survey respondents (n = 79) were asked to self-assess and report on their curation services, including the number of datasets they were stewarding (Hudson Vitale et al., 2017).
Johnston and Coburn’s 2020 study also examined research data support at ARL member libraries, but reviewed websites for key variables instead of using a survey to gather data.2 In 2023, we employed the same website review data collection method utilized by Johnston and Coburn (2020). Specifically, IRs and IDRs housed in libraries were identified, as well as the number of datasets stewarded. Our study was similarly restricted to ARL academic institutions, reviewing library websites to collect the data. This method was preferred over the survey approach by Hudson Vitale et al. (2017) to avoid limitations such as low response rates and self-reporting biases. Library websites, on the other hand, were deemed to likely provide more accurate and current details about services and infrastructures.
To collect data in 2023, we navigated to each university’s online IR and/or IDR using URLs documented during the 2020 study. When URLs were not known, we performed web searches and reviewed library websites to identify repositories. For institutions using Dryad in lieu of a local data repository, we recorded the institution-specific Dryad URL. When institutions had a standalone data repository, the number of datasets in Dryad were not counted. For example, the University of Minnesota has an institutional repository, a data repository, and a membership to Dryad; however, only the URLs for the first two repositories were recorded. In contrast, the University of California systems use Dryad as their primary data repositories, so only those Dryad URLs were captured. Figure 1 provides a distilled view of the relationships between the two previous studies and ours.
Figure 1
Method and timeline of data collection and aggregation.
At each repository’s landing page, we searched for options to view all datasets or records. If direct options to select datasets were not available, we selected the option to filter by item type. Some repositories did not allow for filtering or faceting of all records, instead requiring a search. When this occurred, we would search for ‘dataset’ or ‘data set’ and attempt to filter further. This process was repeated for both IRs and IDRs, when necessary, at each institution.
This approach has several limitations which affected our ability to count datasets with absolute accuracy. We further discuss the impact this variability had on our analysis in the ‘Limitations and Challenges’’ section below, after our results are presented. Despite these limitations, we are confident that the data are accurate enough to analyze trends in data stewardship in academic research libraries.
Results: Growth trends for institutional data solutions
In this section, we present results of our 2023 research separately and then in combination with data from the previous two studies for a longitudinal analysis covering 2017–2023. Our 2023 count revealed minor fluctuations in the numbers of repositories and datasets, primarily due to limitations inherent in the repository search interfaces. During our analysis of the119 ARL academic member repositories, we flagged repositories where dataset counts were unclear. These repositories were excluded from parts of our analysis, such as in Figure 4, which does not include repositories with unclear counts.
Every institution in our 2023 study had library-based infrastructure for data deposit, sharing, and stewardship (n = 119). Of these 119 libraries, 54% (n = 65) had an IDR, while the remaining 46% (n = 54) had both an IR and an IDR for data deposit, sharing, and stewardship. Figure 2 illustrates the growth in the number of IRs and IDRs from 2017 to 2023. Notably, every institution in the study had an IR; Figure 2 highlights the number of institutions with either IRs alone or a combination of IRs and IDRs.
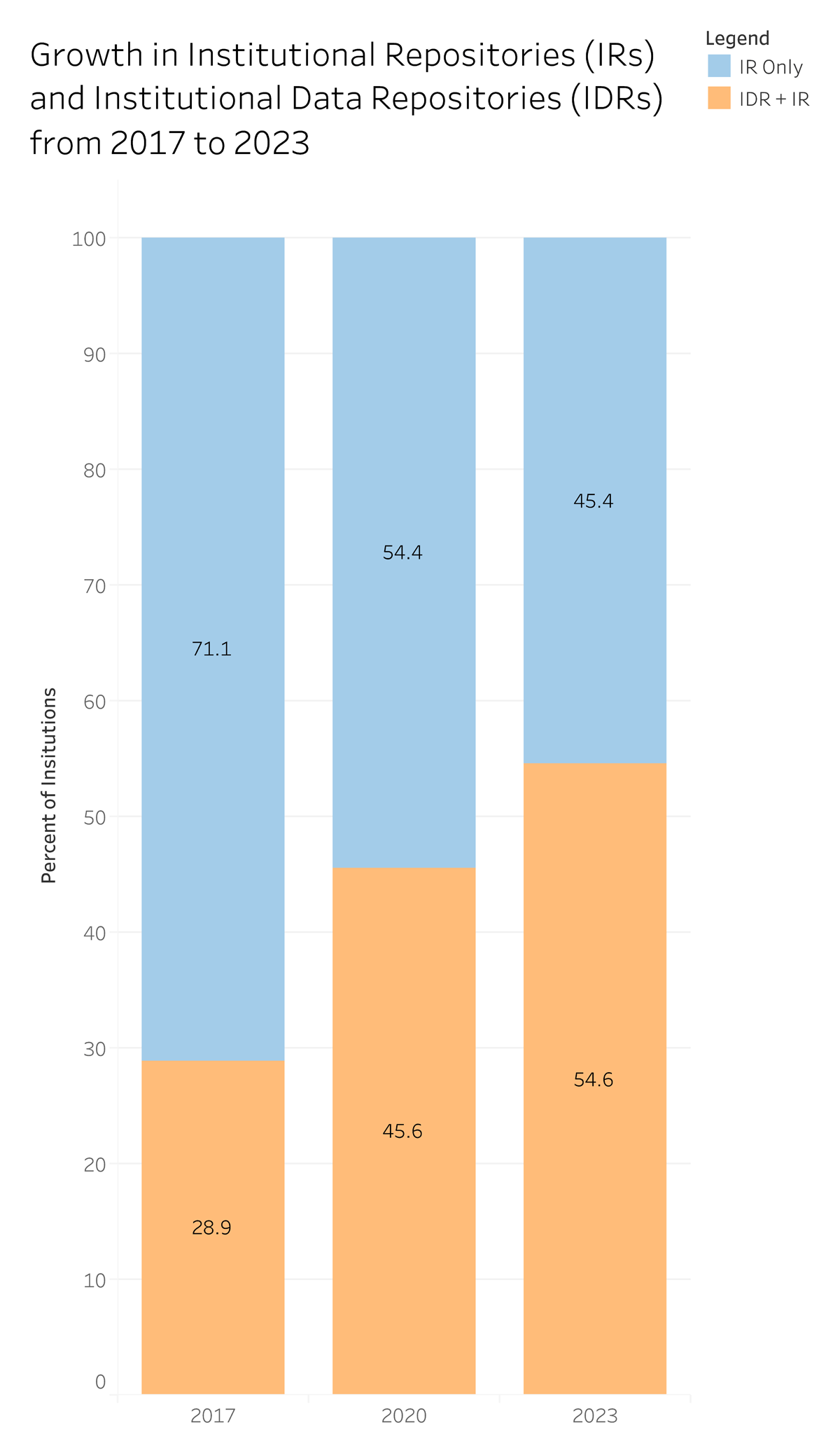
Figure 2
Growth in institutional repositories (IRs) and institutional data repositories (IDRs), from 2017 to 2023, reported as percentages.
In 2017, a smaller sample size was noted due to self-reporting. At that time, the data indicated that 28.9% (n = 13/45) of institutions had an IDR or were in the process of implementing one, as an addition to their established IR. By 2020, this number grew substantially, with 45.6% of institutions (n = 52/114) having established an IDR. Between 2020 and 2023, 13 more institutions established IDRs, bringing the total to 54.6% (n = 65/119) of institutions with a separate IDR. This marks a milestone in research data stewardship, as more ARL libraries now have IDRs than those that do not.
While identifying which institutions had an IR and/or IDR, we also assessed the number of datasets stewarded that could be publicly identified. Figure 3 depicts the number of repositories reviewed for datasets and whether a specific count could be determined. From 2020 (total n = 114) to 2023 (total n = 119), the number of repositories where it was possible to clearly identify and count datasets decreased from 93 repositories to 91 (Figure 3).
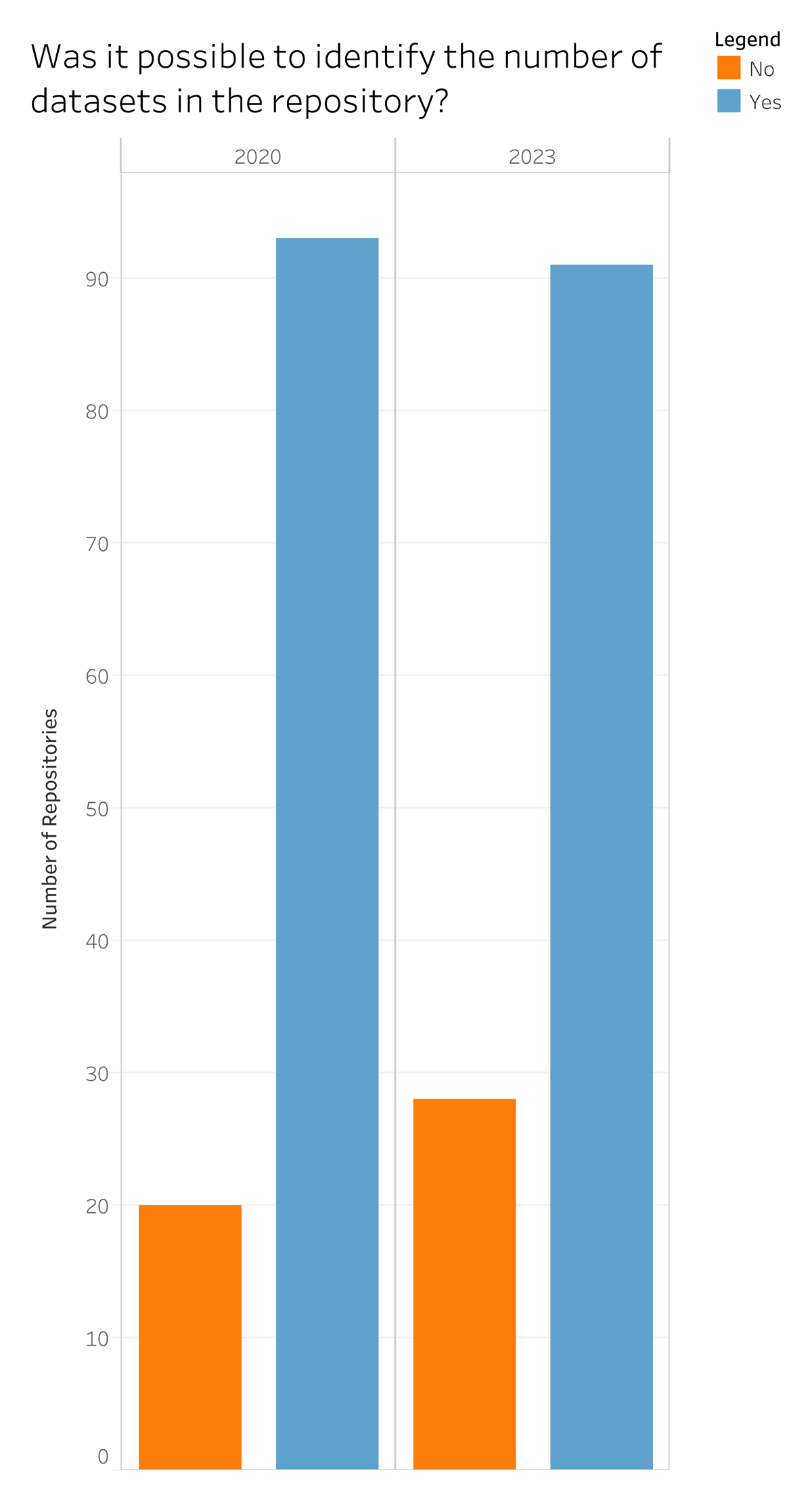
Figure 3
Count of whether it was possible to identify the number of datasets in a given repository.
After identifying the repositories with quantifiable datasets (n = 91), we analyzed the number of datasets within both IRs and IDRs. Figure 4 compares the number of datasets hosted in IRs and IDRs in 2023 only, with the data categorized in 250-unit increments. Repositories for which datasets could not be unambiguously counted were omitted from this figure.
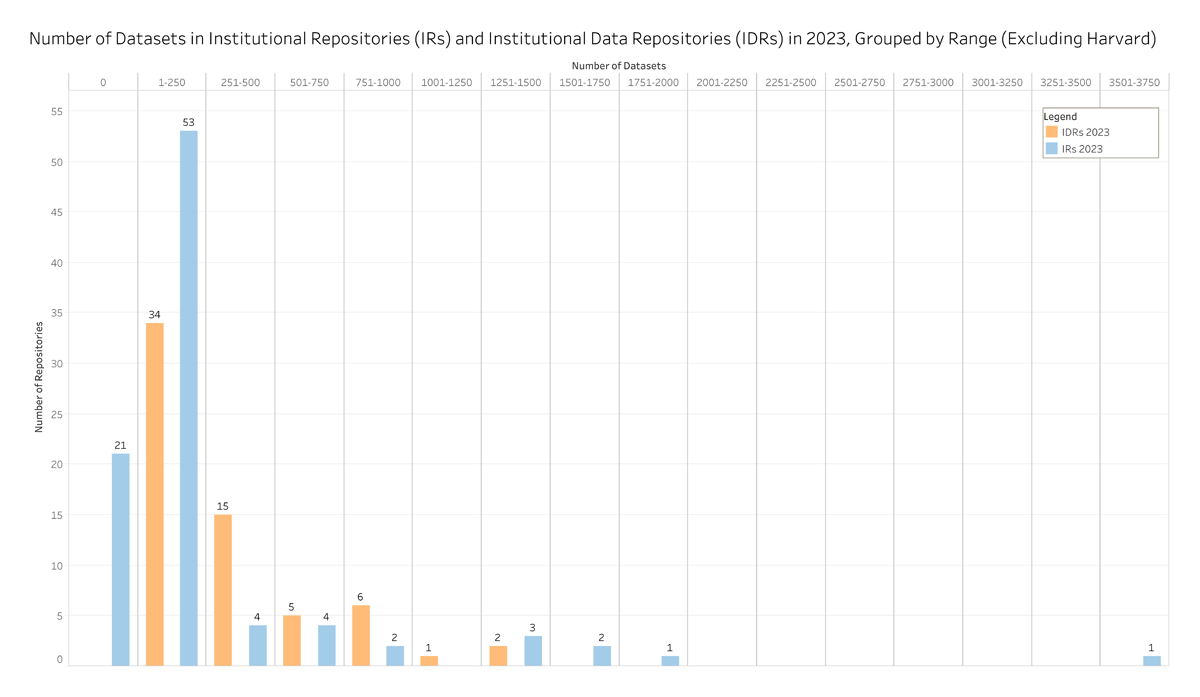
Figure 4
Number of datasets in institutional repositories (IRs) and institutional data repositories (IDRs) in 2023, grouped by range (excluding Harvard Dataverse).
As depicted in Figure 4, we found that 21 IRs hosted 0 datasets in 2023, while no IDRs hosted 0 datasets. For those IRs hosting 0 datasets (n = 21), each institution had a corresponding IDR, suggesting that datasets may have been migrated from the institution’s IR to its IDR.
The majority of institutions hosted between 1 and 250 datasets; specifically, 58% (n = 53/91) of IRs and 54% (n = 34/63) of IDRs. Figure 4 shows a distribution of 0 to 3,750 datasets per repository, excluding data from the outlier case, Harvard Dataverse, which is discussed below.
Finally, utilizing data from all three studies, we chart the growth of data sharing in IRs and IDRs since 2017. Figure 5 depicts the growth in datasets housed within IRs, IDRs, the combination of both, as well as Harvard’s local instance of Dataverse. In 2017, datasets were reported without distinguishing between datasets shared in IRs and those in IDRs. In 2020 and 2023, the type of repository hosting the datasets was also observed, allowing a delineation between types. Harvard’s local instance of Dataverse is also shown in Figure 5 to highlight their dataset count as an outlier.
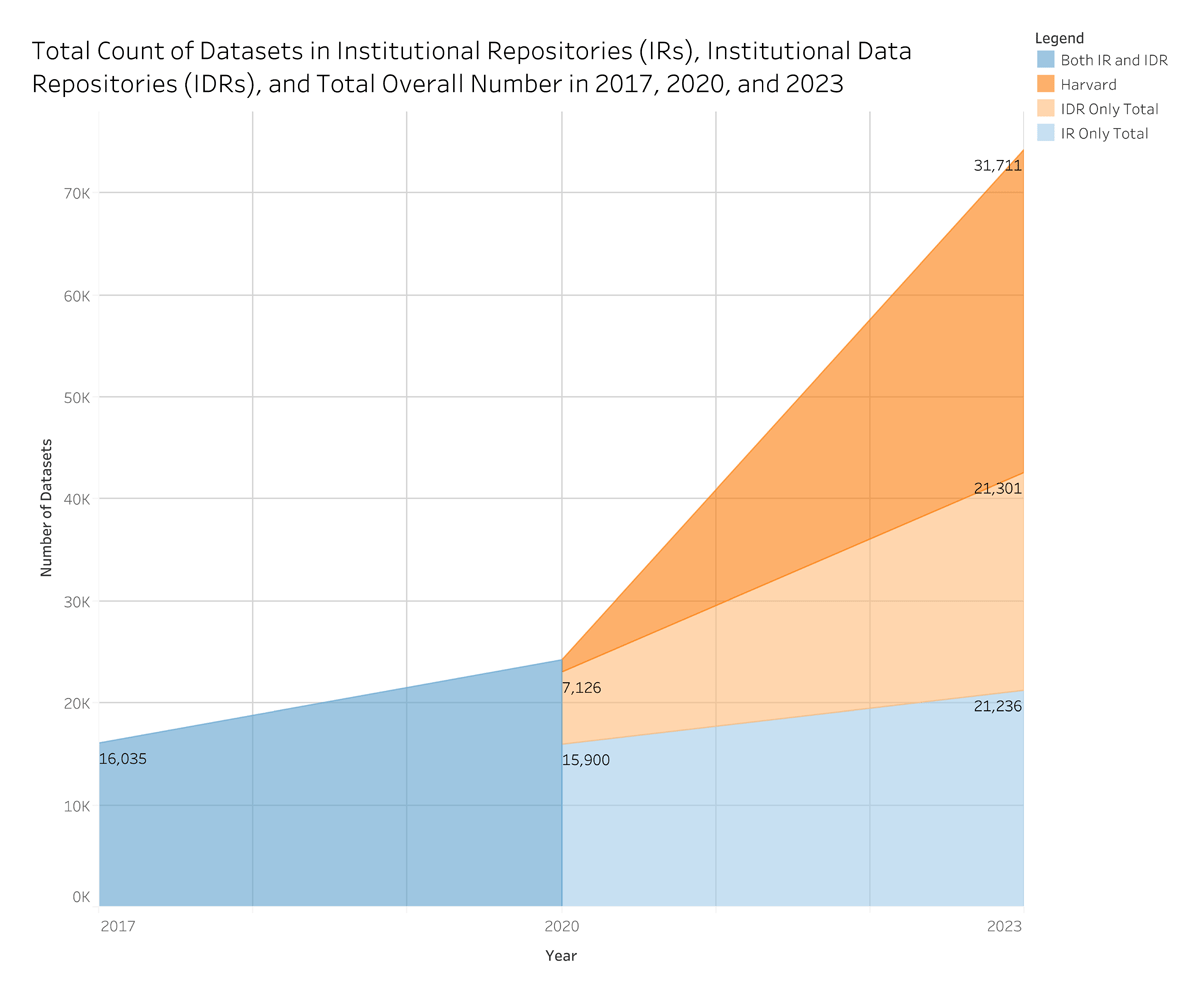
Figure 5
The total count of datasets in institutional repositories (IRs) and institutional data repositories (IDRs), and the total overall number in 2017, 2020, and 2023.
In 2017, ARL survey respondents reported a total of 16,035 datasets hosted in IRs and IDRs. In 2020, a different methodology was used, with researchers directly counting datasets using discovery layer filters. From this method, a total of 23,026 datasets hosted in IRs and IDRs were identified, with the local instance of Harvard Dataverse hosting an additional 1,167 datasets. In 2023, the distribution of datasets in IRs and IDRs was nearly even, with IRs hosting 21,236 datasets and IDRs hosting 21,301 datasets, totaling 42,537 datasets, excluding Harvard. From 2020 to 2023, the number of datasets in Harvard’s IDR increased drastically from 1,167 to 31,711.
As mentioned, Harvard’s dataset count is an extreme outlier. Excluding Harvard, the total number of datasets across both types of repositories in 2023 is 43,537, with roughly half in IRs and half in IDRs. Of those, datasets in IDRs grew significantly, increasing 199% from 7,126 in 2020 to 21,301 in 2023. IRs also saw consistent growth, with deposits rising from 15,900 datasets in 2020 to 21,236 in 2023, a 34% increase.
Data sharing trends in IRs and IDRs
The data for our 2023 study reveals a trend toward establishing purpose-built data repositories hosted alongside existing institutional repositories. Further, our data shows net growth in the number of datasets housed in IRs and IDRs. This increase in the number of datasets can be attributed to several factors.
In 2017, out of 79 responding academic institutions, all of which had IRs, only 10 had implemented IDRs and three were in implementation. By 2020, the number of IDRs increased drastically, with 50 institutions having IDRs and two institutions actively implementing one. By 2023, 64 institutions had an IDR and one institution was in the implementation phase. This shows that research libraries are increasingly establishing dedicated repositories for data sharing, no longer relying only on general-purpose IR platforms to support data stewardship.3
While we see a significant increase in data sharing through IRs and IDRs, there were a few peculiarities in the data worth noting. First, some institutions experienced a decrease in the number of datasets in their repositories over time (eight institutions from 2020 to 2023). This decrease could be due to several factors, including retraction, retention policies, changing access permissions (e.g., public versus institution only), removing duplicates, or removing licensed data. Additionally, in 2023, we observed that 21 IRs dropped to zero datasets; however, as noted previously, each of these institutions launched a separate IDR. Notably, we saw overall growth of datasets in complementary IDRs, consistent with the trend toward increased data sharing and stewardship.
As noted above, Harvard’s institutional Dataverse is an extreme outlier regarding the number of datasets per institution. After filtering to limit datasets to those deposited by Harvard affiliates, 31,711 datasets were listed in the repository, compared to an average of 338 datasets in the other IDRs. Several factors may explain this discrepancy. First, only a few authors appear to be associated with the majority of these datasets (n = 28,167). This number is extraordinarily high – too high to represent a corresponding number of research projects and too high for a single author to publish in a lifetime. Instead, we infer that Harvard data curators may assign DOIs at different levels of granularity than other institutions, or that granular DOI assignment may be a discipline-specific practice. While the number of datasets at Harvard is an outlier in our analysis, documenting this data will be crucial for future studies, as we expect the detailed granularity in DOI assignment observed here to emerge as a significant trend worth monitoring.
Limitations and challenges in collecting repository and dataset data
Here we discuss limitations that may have impacted our results. First, the 2017 survey data collected by Hudson Vitale et al. has its own set of limitations, such as self-reporting biases and limitations in extrapolating from the sample to broader trends. It is possible that respondents who provided IRs and/or curation services were more inclined to participate than those who did not.
Another limitation is that the 2023 data collection was predominantly conducted by a single author, which might have led to incomplete data and unaccounted biases. Thus, it is possible that some repositories were not identified because they were not promoted high enough in search engine results, or because we did not identify some repositories due to customized, unique names or branding that were not easily recognizable (e.g., Gillis, 2017; Hepburn & Lewis, 2008; Kupersmith, 2012). Additionally, the presence of multiple repositories within some academic institutions (e.g., digital collections, disciplinary, researcher-driven, etc.) complicates the accurate quantification of datasets an institution manages.
Another limitation is the difficulty in accurately quantifying the number of datasets hosted within a repository. This limitation arises from several factors. First, in any given repository interface item types may not be mutually exclusive; for instance, images may be data but categorized as an “image” item type. Like Johnston and Coburn (2020), we encountered uncertainty about what constitutes a dataset in a repository and found that datasets, as a unit, are not clearly defined by any institution. For instance, while one organization might count a single submission with hundreds of files as one dataset, another might count each of the files as a dataset (and may issue a DOI for each file).
One set of limitations relates to the findability of data. Our counts include only publicly listed datasets; the true number of datasets housed in these repositories may be higher, as repositories may store embargoed or restricted access datasets. Some platforms made it difficult or impossible to filter and browse by item type or by using wildcards. Also some IRs listed item types with minor variations (e.g., dataset v. data set v. Dataset v. Data set), making it difficult to be sure we counted all datasets.
Our data is exclusively from IRs and IDRs within research libraries, which may be considered a limitation as this sample does not fully represent data stewardship activities at non-research libraries. Despite these limitations, our results demonstrate growth in the adoption of IDRs and in the number of datasets stewarded in both IRs and IDRs.
Understanding the ‘Desirable Characteristics’ of Institutional Data Repositories
We now turn to the second part of our analysis to conduct an ‘infrastructural inversion’ of research data repositories through the framework of the Desirable Characteristics report. The report identifies 14 characteristics across three categories: Organizational Infrastructure, Digital Object Management, and Technology. However, the qualities described in this guidance are not merely technical features of repository software and hardware. Rather, they are almost entirely related to data repositories as knowledge infrastructures as described by Edwards et al. (2013): composed of standards, policies, norms, and individual behaviors that together comprise a functional system.
Infrastructural inversion is one of a set of strategies developed by Susan Leigh Star and Geoffrey Bowker and their collaborators to aid in the ‘ethnography of infrastructure.’ Infrastructural inversion lends itself not just to identifying what qualities make a repository ‘desirable,’ but also what characteristics make a repository a repository. As knowledge infrastructures and complex adaptive systems, IRs and IDRs are composed not only of hardware and software layers, but are also ‘made to interoperate in part by ‘social practices, norms, and individual behaviors’ (Edwards et al., 2013) which may give them distinct advantages and at least partially explain their continued adoption and development. Among strategies for understanding these non-technical layers is what Star and Strauss terms ‘surfac[ing] invisible work’ (1999, p. 385), which is to ‘identify gaps in work processes that require real-time adjustments, or articulation work, required to complete the processes.’ A related ‘trick of the trade’ applies here especially: ‘question every apparently natural easiness in the world around us and look for the work involved in making it easy’ (Bowker and Star 1999, p. 39). Through such an inversion, it becomes impossible to continue to perceive repositories simply as technology platforms, isolated from data stewards, curators, and managers, and their university contexts.
Inverting institutional data sharing infrastructures
To begin the inversion, we share the results of an internal review of Data Curation Network (DCN) members’ institutional repositories, conducted in 2022, after the release of Desirable Characteristics. This review shows that DCN members (n = 17 at the time of review) self-reported that they were in close or full alignment with 11 out of the 14 major characteristics (see Table 1). The characteristics with which DCN members already align are indicators of the expertise and experience brought to the task by research libraries and other information management specialists, as described by Borgman and Bourne (2022).
Table 1
The number of Data Curation Network member repositories (n = 17) and degree of alignment with the characteristics described in the 2022 Desirable Characteristics Of Data Repositories For Federally Funded Research report, as assessed in October 2022. Data reported in Reiff Conell and Wright (2024).
| CHARACTERISTIC | n IN ALIGNMENT |
|---|---|
| ORGANIZATIONAL INFRASTRUCTURE | |
| Free and Easy Access | 17 yes |
| Clear Use Guidance | 14 yes; 3 partial |
| Risk Management | no data |
| Retention Policy | 12 yes; 4 partial |
| Long-term Organizational Sustainability | 12 yes; 5 partial |
| DIGITAL OBJECT MANAGEMENT | |
| Unique Persistent Identifiers | 16 yes |
| Metadata | 16 yes |
| Curation and Quality Assurance | 15 yes; 2 partial |
| Broad and Measured Reuse | 15 yes |
| Common Format | 17 yes |
| Provenance | 16 yes |
| TECHNOLOGY | |
| Authentication | 10 yes; 6 partial |
| Long-term Technical Sustainability | 15 yes; 2 partial |
| Security and Integrity | 3 yes; 9 partial |
While all DCN member IRs and IDRs were not yet fully aligned with the Desirable Characteristics at the time of assessment, they have distinct advantages by virtue of their integration into local practice, where the continuous activity of librarians and data curators bridges gaps between the technical systems that store, preserve, and make data accessible, and the application of standards and metadata that enable these systems to function. Below, we discuss the characteristics across two key examples: established infrastructure and local interoperability and control.
Established infrastructure
Research libraries are integral to research universities and function as what Bowker and Star call an ‘installed base’: existing systems or infrastructures on which new infrastructures are built (1999, p. 35). IRs and IDRs extend from the practices, policies, systems, classifications, and expertise of research libraries, and thus inherit ‘the inertia of the installed base of systems that have come before’ (p. 33) along with its attendant benefits and limitations. The inertia of research libraries provides a notable advantage over other repository platforms in fulfilling the Desirable Characteristics. First, the ‘Organizational Infrastructure’ characteristic evinces the importance of a robust installed base for each desirable feature of repositories. Next, ‘Free and Easy Access’ relies on layers of expertise and policy that would seemingly disqualify some popular generalist self-upload repositories. The ‘Clear Use Guidance,’ ‘Risk Management,’ and ‘Retention Policy’ categories can be automated or relegated to terms of services that push liability to the depositor and limit the platform’s obligation, but only when data can be legally and ethically shared without restriction or data use agreements – a determination that may require human review.
Librarians as data stewards are integral to repository infrastructure, expertly generating metadata and documentation, developing (and standardizing) custom metadata fields, and fitting global standards to meet local needs – examples of the ‘articulation work’ necessary to interoperability. What we call ‘curation’ can also be understood as the ‘human-in-the-loop’ (Johnston, 2020) labor that makes many of the Desirable Characteristics possible. This invisible work includes pre-deposit review, shared curation, data preservation, and data peer review. Curation and stewardship require a significant investment of time and resources into personnel who can develop and maintain relationships. Marsolek et al. (2023) demonstrate that curation support increases the benefit of the time invested by researchers in preparing data for sharing.
The hardware and software layers of repositories function as a substrate for the expert processes required for maximally effective sharing of research data; together they serve as a sociotechnical interface that draws researchers into campus support provided by data stewards and other offices, such as human research protection programs, sponsored projects administrators, and statistical support. These connections among institutional services are not nurtured by external data sharing providers.
Finally, research libraries are part of larger institutional networks through which practices and standards are developed, shared, adopted, and refined, promoting continued development of desirable features to support curatorial practice. Organizations such as the Data Curation Network, the Texas Data Repository, and the Digital Research Alliance of Canada serve as communities of practice for data sharing, stewardship, and long-term preservation of research data and outputs. These social infrastructures support data stewards in their roles in the complex adaptive system of institutional data sharing while sustaining community-level evolution of standards and curatorial practices.
Local interoperability and control
The second category of advantages to researchers and institutions made possible by local administration of IRs and IDRs relates to the Desirable Characteristics that require articulation work to bring processes into alignment. These affordances pertain to the data itself, or loosely, what Desirable Characteristics refers to as ‘Digital Object Management.’ The characteristics in this category encourage alignment with the FAIR Data Principles (Wilkinson et al., 2016) via application of standardized metadata and persistent identifiers (PIDs). Implementing the FAIR principles requires local administration, however, to facilitate local interoperability.
Persistent identifiers like DOIs are vital to the interoperability of data and data infrastructure, and are a key element of ‘Broad and Measured Reuse,’ but their persistence is ‘purely a matter of service’ (Kunze et al., 2017, p. 1) as they can break (Briney, 2024). The maintenance of PIDs assigned or administered through IRs and IDRs may be incentivized by the need for research metrics and through local integrations that require functioning PIDs.
ORCID, a persistent identifier for researchers that can be administered by institutions, also enables ‘Authentication,’ the 12th Desirable Characteristic. IRs and IDRs, by virtue of their integration in the university context, have an advantage in validating the authentic identity of their depositors. When combined with ORCID, institutions are well prepared for compliance with the National Security Presidential Memorandum – 33 (NPSM-33) (ORCID US Community, 2024). By ensuring custodial control and the chain of provenance (the 11th characteristic in Desirable Characteristics), not only do institutional infrastructures avoid the loss of data, they ensure both the authenticity of the data and the affiliation of the researcher who produced the data, protecting the credibility of the institution and discouraging fraud.
A growing number of institutional repository platforms can be configured to interoperate, via metadata standards and APIs, with library systems, enabling users to discover and access data and other research outputs through the library catalog. This promotes broad reuse by facilitating the discovery of research conducted at the institution and by leveraging infrastructure built for traditional research outputs (e.g., monographs, edited volumes, and peer-reviewed research articles). Other potentials exist for interoperability when the repository is locally administered, including: controlled access to sensitive data; transitioning data from active to archive; simplifying large data transfers, preventing data loss, and protecting research integrity (e.g., Holtz, 2021; Cowles & Hillegas, 2022).
Furthermore, many of the repositories in our study provide the curatorial expertise to produce ‘Free and Easy Access’ that is, as described in the Desirable Characteristics, ‘consistent with legal and policy requirements to maintaining privacy and confidentiality, Tribal and national data sovereignty, and the protection of sensitive data’ (p. 4). Integrations of IRs and IDRs with local research administration systems encourages the sharing of data that has been reviewed and curated, protecting human participants and the institutional reputation and preventing risky sharing.
Currently, data stewards perform the articulation work required to connect data management plans with local resources and integrate researchers into whole research lifecycle support. Integration of the IR or IDR into campus systems can facilitate the provisioning of campus resources and anticipate the development of machine-actionable data management plans (Miksa et al., 2019; Riley & O’Brien Uhlmansiek, 2024). Such an integration could benefit all involved in the research data sharing process by facilitating critical human-in-the-loop connections with project personnel early in the research lifecycle. Interoperability between institutional repositories and grant management systems could automate notification to data stewards when an award is made, prompt researchers to share data at the end of the project, or pre-populate descriptive metadata from the data management plan into institutional repositories. Such an integration could facilitate tracking and reporting on the impact of the university’s research outputs, and ensure data have been shared in compliance with data management and sharing requirements.
Conclusion
The landmark policy releases of 2022, Desirable Characteristics of Data Repositories for Federally Funded Research and the Nelson memo, bolster the U.S. federal government’s commitment to the effective sharing of data and other research products. In this policy context, we asked how widely institutional data sharing solutions have been adopted, given the growing range of options for data stewardship. We integrated data from two prior studies (Hudson Vitale et al., 2017; Johnston & Coburn, 2020) with data collected in 2023 to measure growth in use of these repositories. We found an increase in both the number of institutionally-managed data repositories among ARL member libraries, and in the number of datasets that they hold, suggesting that these institutional data solutions are here to stay.
The Desirable Characteristics report assumes – usually tacitly – that human expertise is a feature of the desirable ‘data repository.’ By situating the data repository in the research library, we can understand IRs and IDRs as knowledge infrastructures and identify, through an infrastructural inversion (Bowker & Star 1999), the articulation work intrinsic to a desirable data repository that would otherwise remain invisible. This is important because, despite the development of free, robust, self-upload generalist repositories like Zenodo, Harvard Dataverse, and Open ICPSR in the last decade, interest in institutionally managed repositories for scholarly outputs and research data continues to increase. Since the 2013 Holdren memo, repository infrastructure continues to evolve, and many research libraries with institutional repositories either accept research datasets into these repositories or now have purpose-built complementary institutional data repositories. We contend that this is due in large part to important advantages that institutional repositories provide to researchers, including the human layers that articulate the work of effective data sharing through local support for curation and deposit and connections to other institutional services.
It is clear that data repositories with the needed qualities to satisfy federal funder requirements will need to be complex adaptive systems composed of experts, policies, standards, norms, behaviors, and other features identified by Edwards et al. (2013), all of which are necessary to make each component of the repository infrastructure interoperate with the others. Thus, one argument we make is obvious: institutional repositories, understood as ecosystems in this sense, have what is necessary to manifest desirable characteristics, and to “encourage and facilitate” the sharing of research results by institutions as required by funding agencies (National Science Foundation, 2023, XI-18). We also make a less obvious argument: these repositories for data are part of larger institutional ecologies that give them the potential to provide additional benefits to researchers and to their institutions that are otherwise difficult or impossible to achieve when data is shared using other mechanisms.
Despite the advantages inherent in IRs and IDRs in exemplifying the desired features of research data repositories, as well as those provided to their institutions, there is room for development and improvement. It is possible that some other system for sharing research data will gain primacy and displace IRs and IDRs, or that they will evolve into another type of knowledge infrastructure. Nor are IRs and IDRs the ideal solution for all institutions where data is produced for many reasons, including the lack of local expert labor.
Nevertheless, as federal agencies raise the bar for sharing data and other research outputs, the need for reliable, trustworthy infrastructure intensifies. In the wake of the 2022 policy documents, we demonstrate that IDRs have crucial advantages not just in expressing those qualities called for in Desirable Characteristics, but also advantages to the institution itself. Institutional repositories that are optimized for data can go a step further and specifically support the capacity for data to be FAIR (Wilkinson et al., 2016) and CAREful (Carroll et al., 2020). Finally, institutional data repositories have advantages for their universities that could drive additional development, including integration into campus research systems. These local sharing solutions should not be overlooked or neglected.
Data Accessibility Statement
The full dataset for this research is available through the Data Repository for the University of Minnesota (DRUM), https://doi.org/10.13020/w8nk-d131.
Narlock, M., Priesman Marquez, R., Herrmann, H., & Ibrahim, M. (2023). Data for “Knowledge Infrastructures Are Growing Up: The Case for Institutional (Data) Repositories 10 Years After the Holdren Memo”. Retrieved from the Data Repository for the University of Minnesota, https://doi.org/10.13020/w8nk-d131.
Notes
[1] The Desirable Characteristics report does not reference the CARE (Collective Benefit, Authority to Control, Responsibility, Ethics) Principles for Indigenous Data Governance directly (Carroll et al., 2020). Further examination is needed to determine how to maximize application of the CARE Principles through the characteristics identified in the report.
[2] Association of Research Libraries (ARL) members include federal, public, and academic research libraries in the United States and Canada. This paper uses data from the academic members only for the years 2017 and 2020. Our 2023 website review did not include the non-academic ARL members.
[3] It is also of note that this study did not capture IRs that are being further developed to support data sharing and curation. For example, Cornell University and Penn State University both use their institutional repository to manage and store research data, and have built or are currently building functions to support research data within the IR platform.
Acknowledgements
The authors would like to thank Alicia Hofelich Mohr, Research Support Coordinator in the Liberal Arts Technologies and Innovation Services (LATIS) at the University of Minnesota (UMN) for her guidance in this project, as well as Heather Herrmann and Maisarah Ibrahim in LATIS at UMN for their assistance in counting datasets in institutional repositories. Also at UMN, we thank Melinda Kernik for her support in curating the dataset for publication. We further thank Jake Carlson, Associate University Librarian for Research, Collections and Outreach, University at Buffalo, for his insightful comments on the value of institutional repositories locally. We also extend our gratitude to the National Center for Data Services (NCDS) for selecting the Data Curation Network as site hosts for their annual Data Internship program; ideas for this paper were initially fostered during the internship period in 2022.
Competing Interests
All authors are current or former individual members of the Data Curation Network. Lead author, Mikala Narlock, is the Director of the Data Curation Network.
Author contributions
MRN, SC, and ST were responsible for conceptualization, investigation, methodology, data curation, project administration, writing – original draft, and writing – review and editing.
RPM was responsible for data visualization and writing – original draft.
AP was responsible for conceptualization, investigation, and writing – review and editing.