
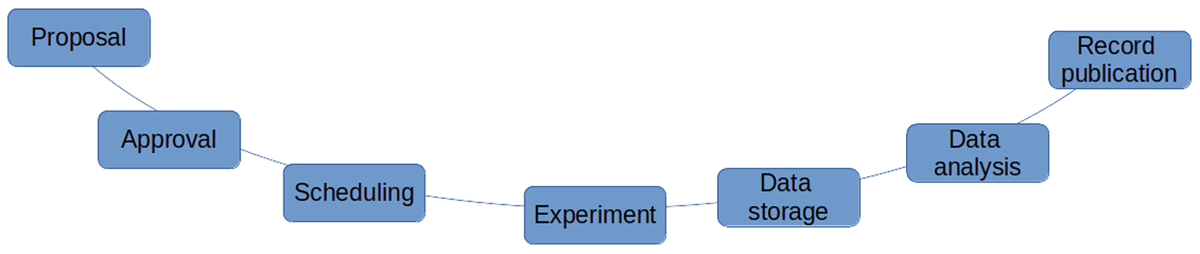
Figure 1
An idealized facility research lifecycle, simplified (Matthews et al. 2012).
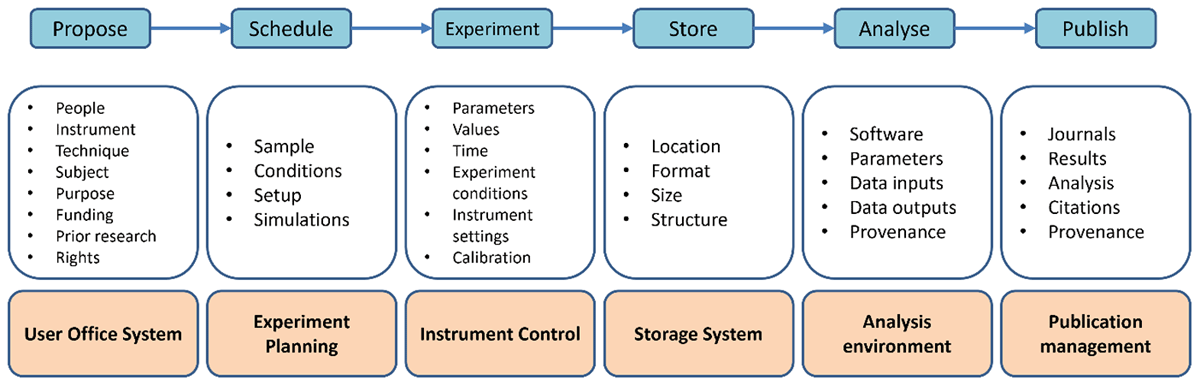
Figure 2
Metadata collected and information systems supporting the stages of the Experimental lifecycle.
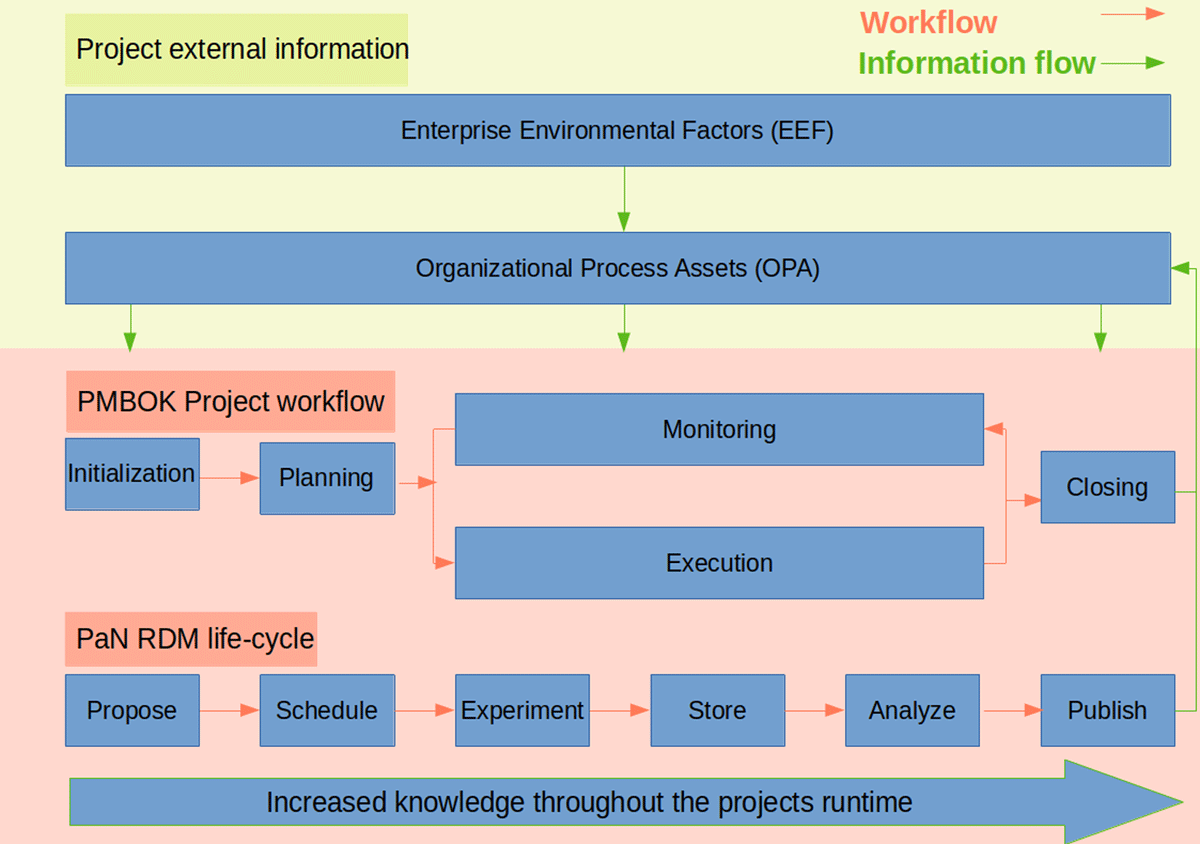
Figure 3
Increasing knowledge throughout projects’ runtime and information flow.
Table 1
DMP Phases.
| DMP PHASE | ACTOR PROVIDING INFORMATION FOR THE DMP |
|---|---|
| 0 Before proposal submission | Typically, knowledge of instrument from scientist or RDM team (static parameter). |
| 1 Proposal submission | Typically, knowledge of the researcher, with support from the facility administration and RDM team. |
| 2 Accepted experiment planning | Typically, knowledge of the researcher, with support from the facility administration and instrument scientist. |
| 3 Data Collection/Data processing/analysis | Typically, knowledge of the user, with support from the instrument scientist. |
Table 2
PMBOK®’s phases and roles in RDM information collection.
| ROLE | BEFORE PROJECT/OPA/EEF | PROJECT INITIATION | PROJECT PLANNING | PROJECT EXECUTION | PROJECT FINALISATION | AFTER PROJECT/PA |
|---|---|---|---|---|---|---|
| Instrument scientist | Instrument/software description, selection of applicable metadata standards, general dataset description | Required project specific software, used instrumentations and their configurations, and standards | Adding/actualisation of instruments and software information | |||
| Data manager | Controlled vocabularies and standards administration, mapping metadata to standards, general data policies, policy execution | Automatic metadata extraction and validation | Open access of research data, validation of policy execution; actualization of standards and policies | |||
| User office | Proposal information, instrument to be used, (co-) proposers | |||||
| Experimental team(research) | Concrete dataset description, references to additional information, metadata schema selection, estimated amount of datasets produced, dataset usage, special (own) software infrastructure requirements | Experiment execution: parameter and configurations | Dataset selection, metadata completion, and validation | |||
| Experimental team (administration) | Specific policies and DMP requirements for project, funding, participating researchers | DMP actualization | DMP actualization after experiments | DMP actualization |
Table 3
Facility wide metadata.
| FACILITY INFORMATION | |
|---|---|
| repository | The repository information comprises the name and access URL where the data is made accessible. |
| licence | The license usually applied to the data in the repository. |
| security | Information about e.g., backups and replicas of the data and other special security information. |
| pid_system | The default PID system applied in the repository e.g., handles or Digital Object Identifiers (DOIs). |
| personal_data | In case personal information in research data is treated on a facility level, e.g., no personal information is allowed in research data more than required for provenance. |
| min_storage_period | The minimum period research data has to be available for good scientific practice. |
| archive | Data archive used. If it is the same as the repository, then no URL needs be provided, as the access procedures have to be described. |
| certificate | If the repository is certified and with which certificate e.g., CoreTrustSeal. |
| arrangements | For the data produced in a research project, an arrangement with the data repository that will receive the research data has to be made. In case a proposal in PaN facilities is approved, it normally includes the usage of the repository. |
| embargo_period | In the data policy of the PaN facilities, there is also an embargo period defined. |
| access_control | How the access to the data repository is controlled. |
| costs | In case a proposal in PaN facilities is approved, it also normally includes the costs for research data management. |
Table 4
Metadata for scientific techniques related to metadata schema and file format.
| technique | Describes a scientific technique. |
| name | A name or label of the technique. |
| PID | E.g., the IRI in the PaNET Ontology (Collins et al. 2021). |
| metadata schema | Related to the technique are the requirements on metadata. There can be more than one metadata schema and format used in practice. |
| structure | |
| format | |
| tools | |
| reading | Software for possible usage. |
| writing | Possible software for writing the format. |
| validation | Tools for validating the data against e.g., NeXus application definitions.1 |
| validation schema | Schema complies with metadata schema above, used for validation with a tool. |
Table 5
Metadata for datasets.
| DATASET | |
|---|---|
| name | a default name |
| description | a project independent description of the dataset that can be adapted in projects |
| contributor | contributing persons, typically identified via ORCIDs |
| reproducible | if the dataset is reproducible and under which efforts |
| interested_community | might be derived from disciplines |
| usage | there might be some default usage scenarios, like calibration; otherwise the data sets’ intended usage in the project |
| archival | DMP question; moment, selection_criteria, and long_term_archival_reason might be used for automated execution and validation |
| data_security | measurements and responsible person |
| techniques | scientific techniques used to create the dataset |
| filecollections | a collection of files created by one software instance; a dataset can contain more than one filecollection |
| name | a default name |
| resource | instrument or laboratory used to create the filecollection; preferable identified by PID |
| storage | location and access to experimental storage |
| backup | location and access to experimental storage |
| quality_assurance | description and pointers of e.g., validation workflows |
| hardware | description of hardware components used to create the dataset; used for data curation |
| writing_software | description of software and its components used to create the dataset; used for data curation |
| files | files |
| name | can be a regular expression definition of default file names |
| format | the format of the file (could be related to a format registry and relates to the technique table above) |
| metadata_schema | the metadata schema applied in the file (could be related to a metadata schema registry and relates to the technique table above) |
| size | expected minimum and maximum size of the file; average size |
| amount | quantity of files; can be used together with size for estimating overall size and validation |
| processing_requirements | hardware and software requirements for processing the data |
| hardware_requirements | |
| type | type of hardware requirements like storage or processors of a certain type of computer; manufacturer and model are required |
| reading_software | possible software to use the data, including access and documentation, as well as required plugins |
| name | |
| PID | |
| type | |
| documentation | |
| URL | |
| plugins | |
| name | |
| type | |
| URL |
Table 6
Metadata for operations.
| POLICY | |
|---|---|
| name | The name of the policy. |
| constraint | When the operation should be executed. |
| type | Event trigger or scheduled. |
| value | Triggering event e.g. onCreation or date and time. |
| parameters | Array of required parameters like path to a file or metadata schema for validation. The parameters are divided in input and output parameters. |
| operation | Policy related operation or workflow (referencing an executable workflow). |
| categories | For finding the operation, e.g., validation, integrity, format, extraction, interoperability. |
| description | A textual description about what the operation does. |
Table 7
Metadata for projects.
| PROJECT: | |
|---|---|
| name | name of the project |
| description | project description |
| funding reference | the usage of a PID is advisable for later curation and integration into a graph model |
| members | here as well the usage of ORCIDs is advisable |
| start_date | start of the project |
| end_date | end of the project |
| disciplines/keywords | to retrieve RDM requirements and improve findability of the data |
| jurisdictions | to retrieve policy requirements; jurisdictions can be funders, national, institutional, or a laboratory/instrument |
| resource | instrument or laboratory used to create data; used to retrieve possible dataset types created by the resource |
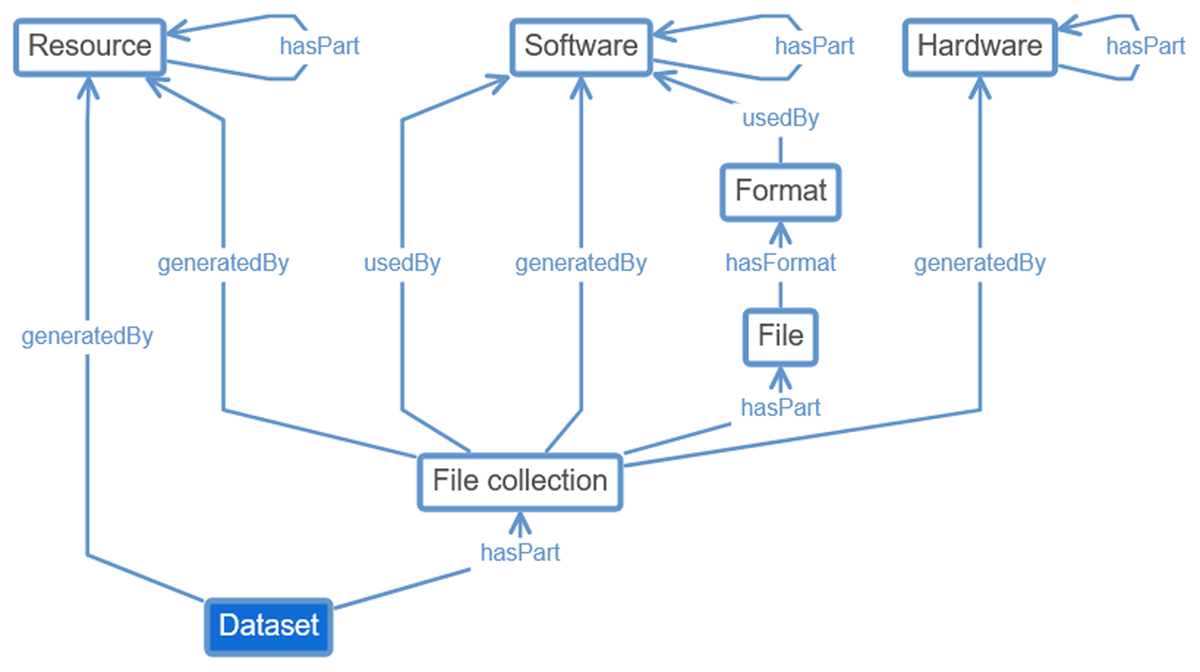
Figure 4
Relations of the Dataset class.
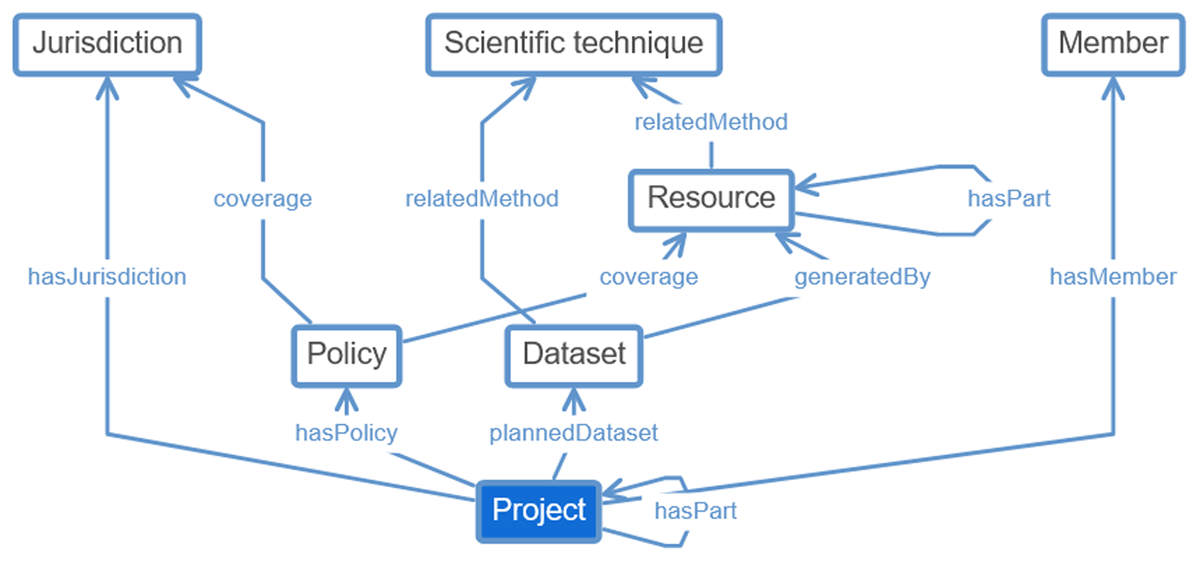
Figure 5
Relations of the Project class.
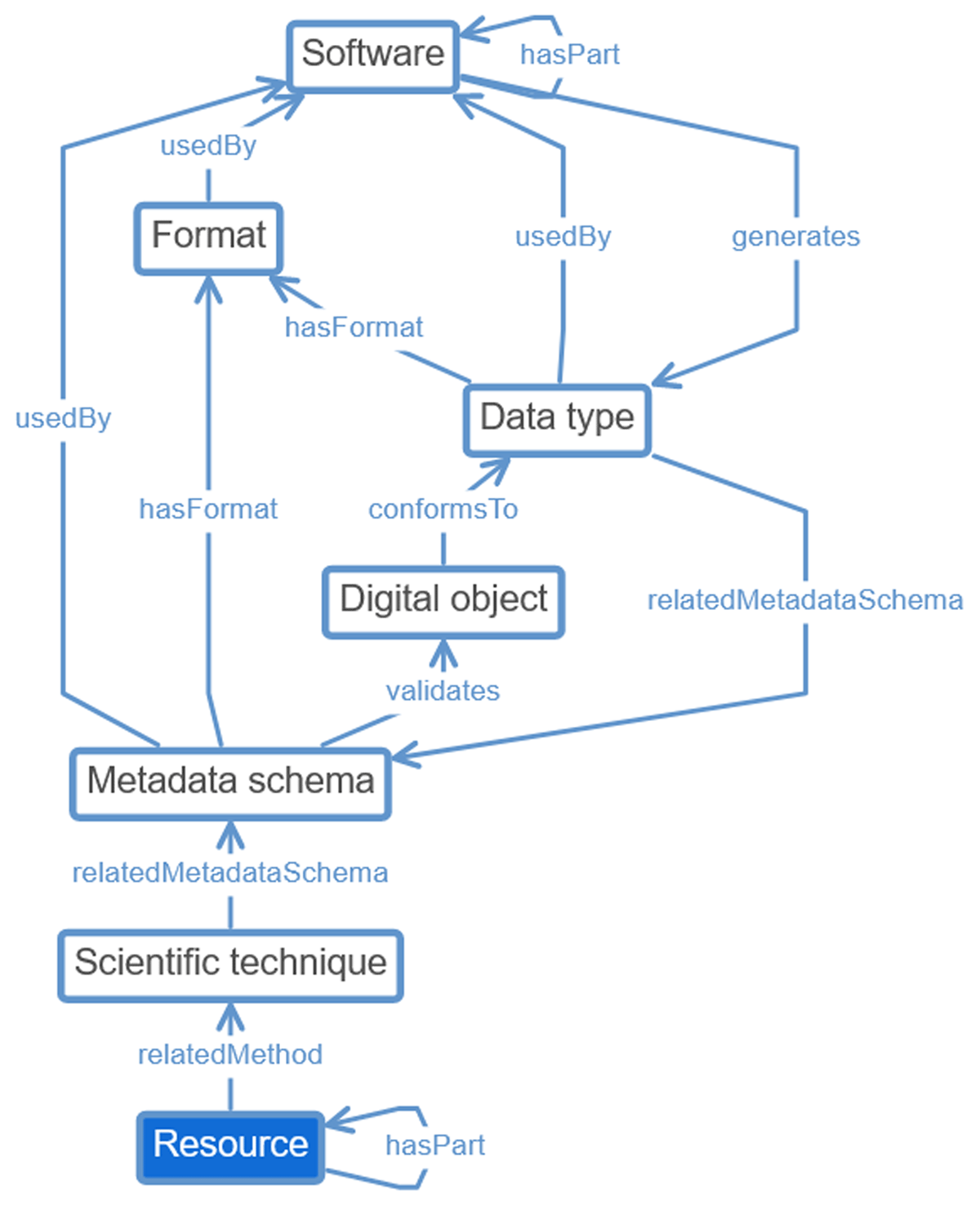
Figure 6
Relationships associated with the Resource class and its associated technique.
Table 8
Pre-existing information lifecycle phases and related activities.
| LIFECYCLE PHASE | ACTIVITIES |
|---|---|
| Before project (OPA/EEF) | Retrieve initial information for central knowledge base about Datasets of Resource from repository. General update/insert knowledge base:
|
| Project initiation | Insert new project Relate to resource |
| Project planning | Specify projects datasets:
|
Create DMP:
Create concrete policy execution environment:
| |
| Project execution | Update DMP
Execute operations on datasets |
| Project finalization | Update DMP Execute operations Select datasets for archival Update concrete dataset descriptions |
| After project (OPA) | Validate pre-existing information against projects datasets in the repository:
|
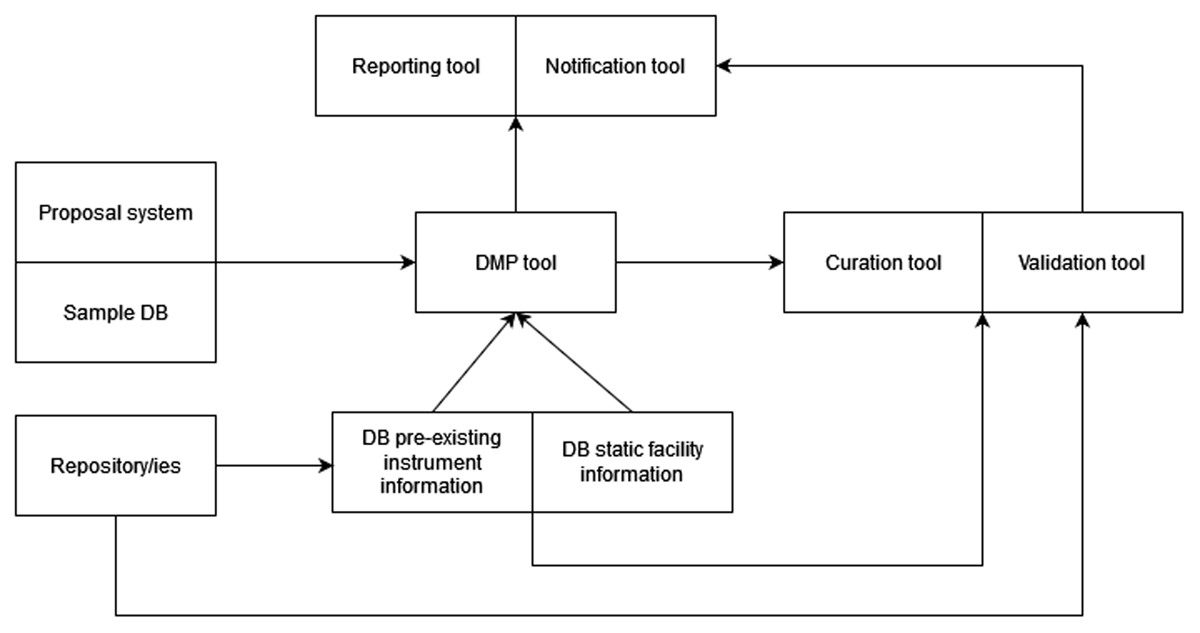
Figure 7
Components for aDMP system (Görzig et al. 2022).
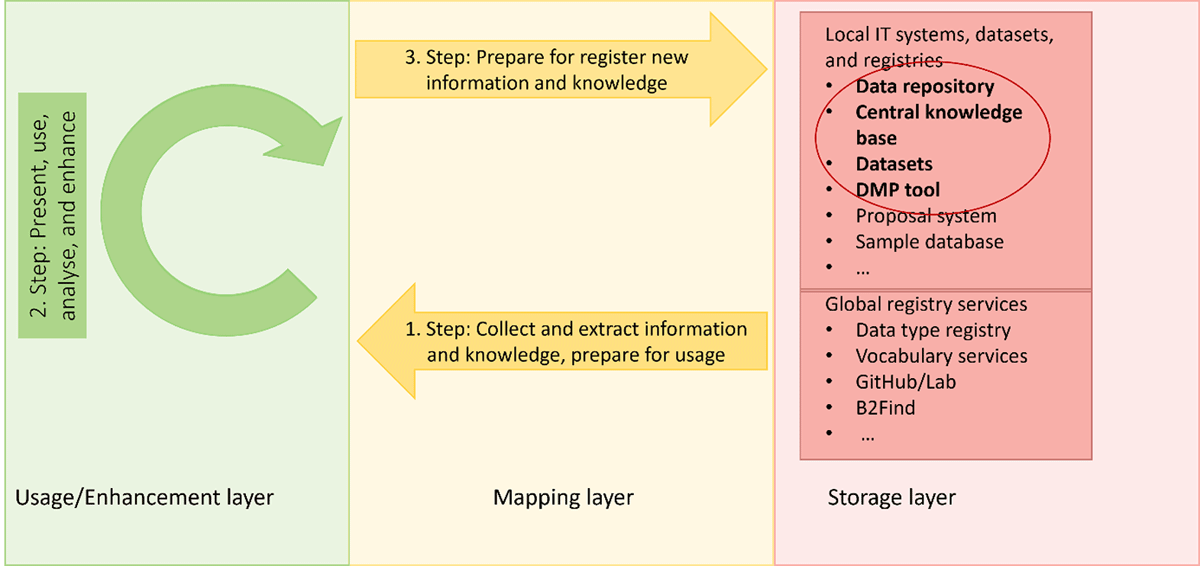
Figure 8
Pre-existing information enhance and use.