
1. Introduction
Data science, namely the science of data and science facilitated by data, has significantly changed how we work, study, and live. Over the recent two decades, statistics show a growing interest in data science (see Figure 1) that remained relatively steady early in the new millennium before a constant increase in the most recent decade. Moreover, the incredible power embedded in data science ignites the worldwide digital revolution in which everyone enters the unprecedented big data era (Science International 2015).
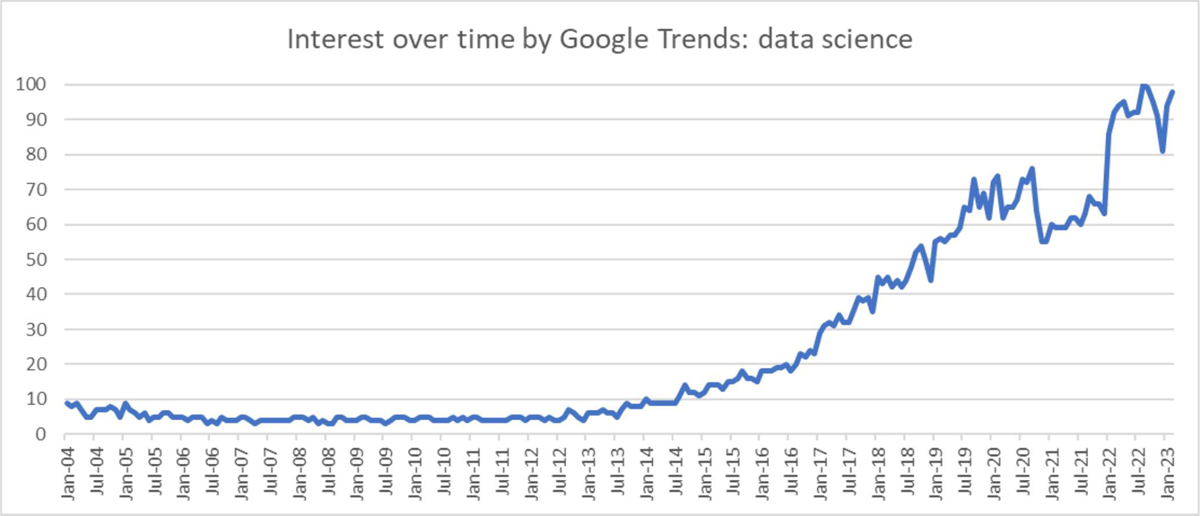
Figure 1
Interest over time by Google Trends: data science around the world (23 Feb. 2023).
This paper carries out a lightweight literature review to unveil data science in the last 20 years. It employs scientometric methods to identify data science essentials and introduces examples illustrating multidimensional challenges. It also includes an analysis of future trends and proactive actions. Hopefully, this paper will help reflect on data science work and support its future development under open science guidance (UNESCO 2021).
2. Exploring the Full Potential of the Big Data Era
From no data and little data to big data (Borgman 2015), the new era brings the most significant advances to data science. According to Google Trends, the most relevant data science topics searched fall into different categories, such as data, technology, infrastructure, and education (see Table 1). Another word frequency analysis of the data science publications on the Web of Science platform shows similar results (see Figure 2). Therefore, we employ the four essential components (see Figure 3), namely data resources, technologies, data infrastructures, and data education, to depict data science trends.
Table 1
Relevant data science topics searched on Google.
| CATEGORIES | TOP 25 MOST POPULAR TOPICS RELATED TO DATA SCIENCE (GOOGLE TRENDS, 23 Feb. 2023) |
|---|---|
| Data | data; big data |
| Technology | Python; analytics; learning; data analysis; machine learning; analysis; artificial intelligence |
| Infrastructure | computer; machine; project; engineering |
| Education | data science; course; university; job; master’s degree; master of science; bachelor’s degree; salary |
| Others | science; computer science; statistics; business |
[i] Note: Data are captured from Google Trends and manually cleaned.
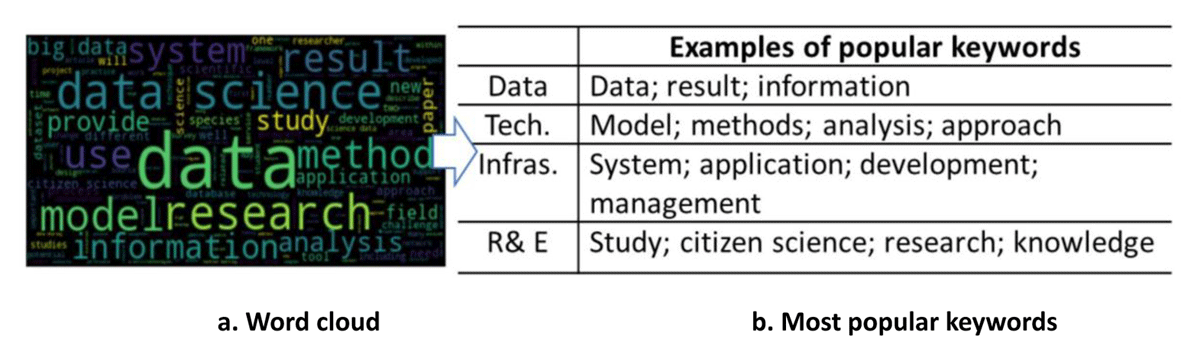
Figure 2
Relevant data science topics in Web of Science publications.
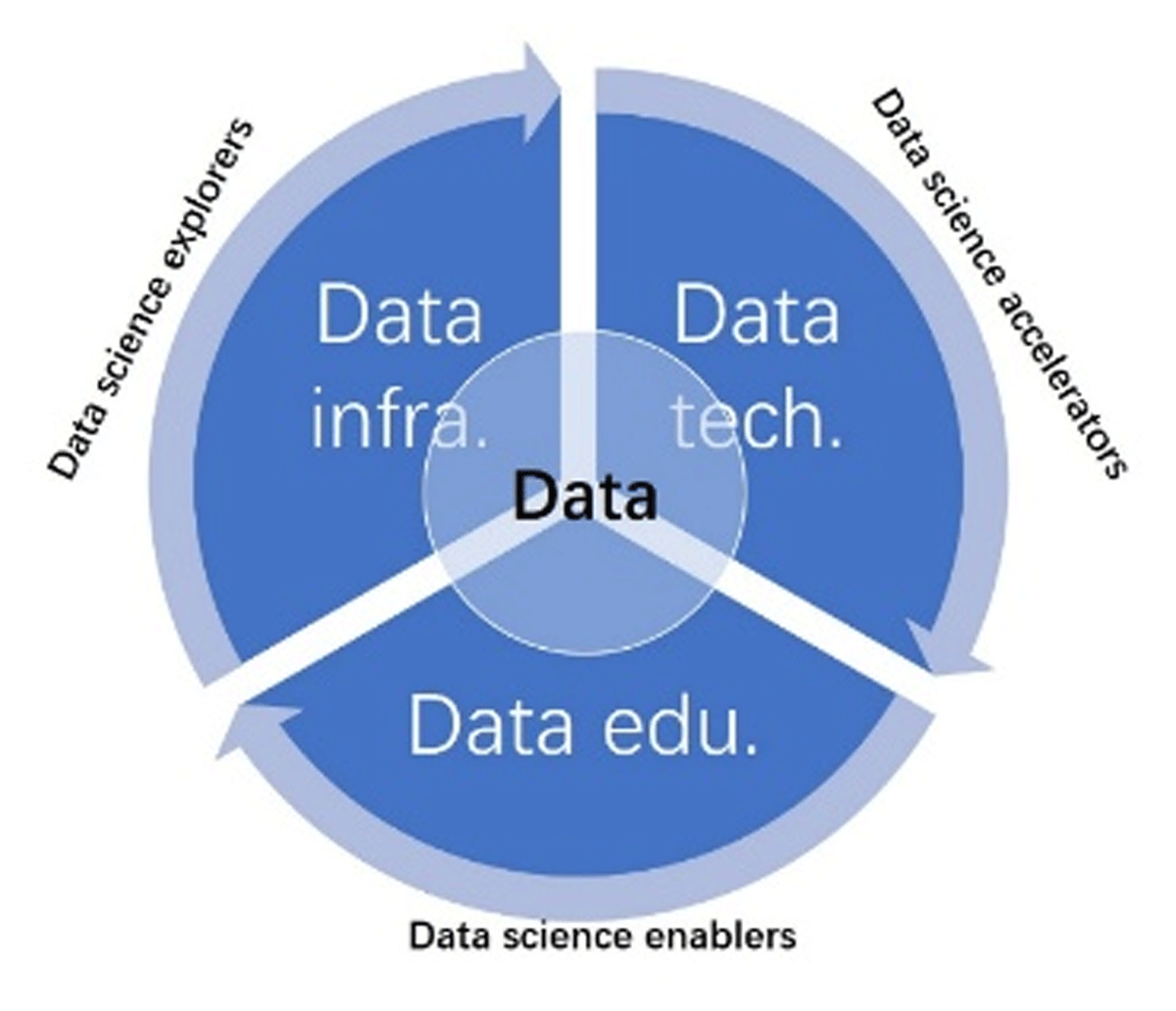
Figure 3
Four essential components of data science.
As the new underpinning of the digital revolution, data have become hot spots in different areas. Many types of research, far away in the luminous galaxies (Combes 2021) or up close in the micro-ecosystems (ISC 2021), are driven by data-related research resources. Data-centric research drives paradigm shifts to address transparency and openness throughout the data life cycle. Data improve the performance of global governance by steadily aggregating social capital (Malgonde & Bhattacherjee 2014) and proliferate the digital economy by reducing costs and facilitating value appreciation of data-relevant assets.
Nevertheless, data are not alone. The supporting information and communication technologies (ICT) provide opportunities to facilitate the full exploitation of data value. From analysis to analytics (Cao 2017), technologies transfer data from facts to insights. From data mining to artificial intelligence, technical development drives data to understand the past and envisage the future (Provost & Fawcett 2013). From centralized data control to cloud solutions, technologies support better data management for scalable research. Thus, as catalysts and boosters, technologies improve data performance by adding value to data within the whole life cycle and every workflow.
Further, data infrastructures facilitate the deployment of technologies, thus supporting data use and reuse. Technical infrastructures provide connectivity for data exchange, capacities for data storage, computing for data processing, algorithms and software for data analysis, portals and technical support for the accessibility and reusability of data services. Thus, data and technologies evolve together with the supporting data infrastructures. Take the Scientific Data Program of the Chinese Academy of Sciences (CAS SDP), for example (Figure 4) (Zhang et al. 2021): initiated in the 1980s and sustained for over 30 years, the CAS SDP has established data infrastructures to support disciplinary research. The data infrastructures have been growing from early databases to the data grid, data engineering, data cloud, and an open data system of systems, as well as leading the exploration of co-building a Global Open Science Cloud (CODATA 2021; CSTCloud 2021). The evolving construction of the supporting e-infrastructures reflects the iteration of data and technologies that has adapted to the dynamic research scenarios of different research periods.
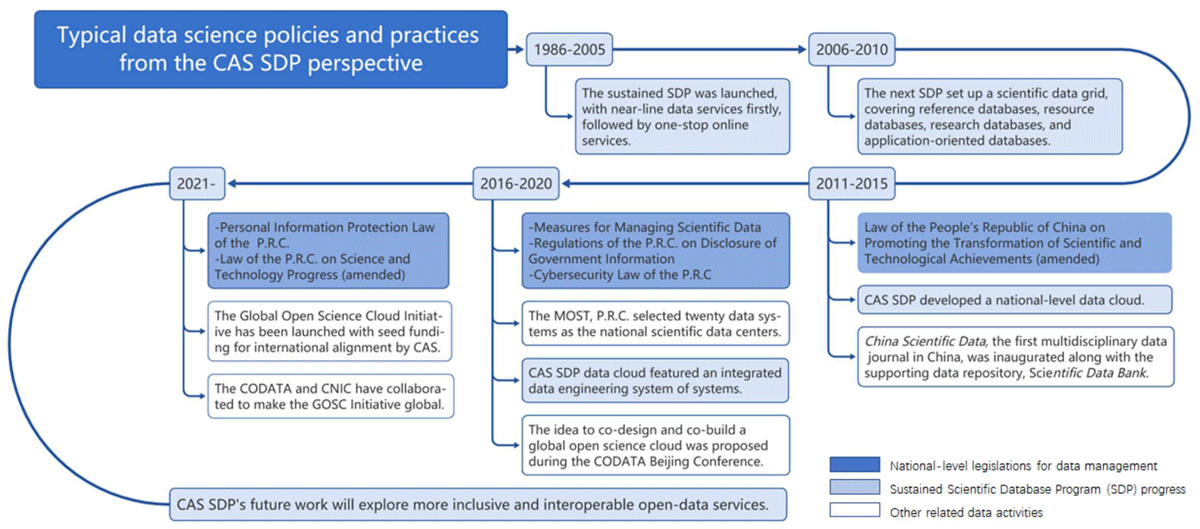
Figure 4
Typical data science policies and practices from the CAS SDP perspective.
Moreover, data science education includes popular colleague programs, such as the iSchool applied data science master program and the data science training for citizens, such as the CODATA-RDA summer school and online training on the MOOC, Coursera, and EdX platforms, etc. Building data capacities throughout different programs has enabled better use of data, technologies, and data infrastructures. In China, for example, the Ministry of Education issued the Action Plan for Promoting the Development of Big Data (2015), followed by a steadily increasing number of university data science majors and a boom in data-relevant careers nationwide. Data science also helps create new types of professionals, such as data scientists (Dhar 2013), data engineers, data architects, and others. Therefore, data education sustains data science careers and helps cultivate citizens with better literacy to surf the wave of the digital revolution.
Above all, these essential data science components work together, contributing to the scientific research, societal development, digital economy, and better alignment within and across communities, domains, and regions.
3. Data Science Challenges and Priorities
In addition to the remarkable contributions to the digital revolution, data science also raises grand challenges in social and cultural, epistemological, scientific and technical, economic, legal, and ethical dimensions.
First, several data factors contribute to the challenging barriers, such as the multiple sources, the enormous scale, the diversified formats, the intrinsic nature, the uncertain value behind them, and the way of communication. Social and cultural contexts complicate data interpretation (Shanks & Corbitt 1999), making data abuse a potential threat to data reuse. Furthermore, data address rights protection, such as privacy, security, ownership, and intellectual property (Taylor 2017; Calzada & Almirall 2020). Thus, necessary closeness and default openness should clarify their boundaries to explore the full potentials of open data. Moreover, nourished culture, evolving governing rules, and data ethics (Floridi & Taddeo 2016; Gundersen 2017; Vydra et al. 2021) should work together to bridge digital gaps, promote research integrity, and support future envisions vigorously.
Second, as the essential game-changers for science, promising and robust technologies support cutting-edge data exploration by combining certain data into tailored scenarios. For example, long-tailed value exploration for massive data, lack of data, and sensitive data coexist in scenarios. Thus, any data curation should be set in the lifelong data cycle to save chaos, such as real-time massive data integration in Earth Sciences for Sustainable Development Goals (SDGs) research (Guo et al. 2021). Moreover, epistemological thinking (Kempeneer 2021) should be involved in the technical design, pulling data results out of the black box of technologies. Other important concerns also include technology neutrality, algorithm ethics, legislation redesigns, and global alignments (George & Walsh 2022) to better serve the public interests, like in the case of ChatGPT (van Dis et al. 2023).
Third, sustained governance models with social, cultural, and economic considerations are critical for successful data science, especially for data infrastructures. Infrastructures are comprehensive systems that combine data, technologies, hardware, software, and others (Mayernik et al. 2017) for service delivery. Potential players in a data infrastructure ecosystem may include the infrastructures (service providers), resource suppliers (both for data and technologies), users, and funding agencies. Therefore, data infrastructures rely on robust business models to balance all possible stakeholders’ interests and ensure data science components running systematically and healthily. Considering the ‘Matthew effect’ (Merton 1968; Merton 1988; Bol, de Vaan & van de Rijt 2018), chances of future opportunities may be amplified by accumulative advantages, such as current construction scale, prestige, and popularity. Thus, vulnerabilities may lie in the future opportunities to raise funding as newly established infrastructures, to share data as sovereign resources suppliers, and to access data services as niche-demand users. Technical concerns may include exploring systematical design for flexible and extensible services, effective functionality deployment for efficient data curation, and environmentally friendly development.
Fourth, data education (NASEM et al. 2018; Wise 2020) should build capacities for specialists and citizens. Data science overlaps with computer science and statistics and focuses on real-world problem solving. Thus, data professionals’ challenges may include establishing proper social identity, connecting with other relevant societal roles, and mapping real problems into tailored curricula, such as ‘precision education and individualized learning’ (Luan et al. 2020). Cultivating citizens may also be popular, such as coding for data cleaning, analysis, and visualization, but that is not enough. Data science education, both professional and amateur training, should aim bigger, covering the whole life cycle of data in an open-science manner to embrace inclusive and responsible data science in the future.
Specifically, no data challenges come alone, and no data science essentials can break the silos independently. Instead, data challenges require collaborative support from technologies. Moreover, infrastructures will facilitate data sharing and technology implementation. Educating data professionals and the social community will empower data fully by “leaving no one behind” (UN Sustainable Development Group 2022). Therefore, solutions should consider the four data science essentials together, not segregated ones.
4. Future Visions and Next Steps
Challenges also bring opportunities. Considering data as the global public good (CODATA et al. 2019), data science may assume many future responsibilities, with inevitable trends toward datafication, data technicity, infrastructuralism, literacy empowerment, and others. The following subsections elaborate on each of these issues.
From data to datafication (Mayer-Schönberger & Cukier 2013; Van Es & Schäfer 2017; Mejias & Couldry 2019), quantitated data activities prevail in the big data world. Datafication pulls data from traditional statistics to big data analytics with facts, knowledge, and wisdom. Deeply rooted in the digital revolution, datafication contributes to the booming digital economy while encountering societal and cultural conflicts. To better harness the power of datafication, we should embrace open science (UNESCO 2021) more than ever. A series of guidelines should be followed, such as the FAIR principles (Wilkinson et al. 2016), the CARE principles (Carroll et al. 2020), and the TRUST principles (Lin et al. 2020), as well as others. Open data involves sharing for reuse and closing for protection, commercial and noncommercial models, scientific and pragmatic explorations, and close connections among the research community, social enterprises, and citizens. To open or to close may not be contradictory, but there are inevitably frictions and gaps. For the sake of good science, rules should clarify data boundaries, especially highlighting ways for grey data reuse (Borgman 2018). Research integrity and data ethics are also necessary for responsible open science. For example, Indigenous data sovereignty (Carroll, Rodriguez-Lonebear & Martinez 2019), democratic accountability (Gurumurthy, Chami, & Bharthur 2016), and other moral aspects of data are to balance the interests of potential stakeholders for sustained lifelong data curation.
Furthermore, constitutive technicity (Gallope 2011; Ash 2012; Ducassé & Lee 2014; Wiktionary 2022) dramatically tightens data and technologies. ‘Technicity’ depicts the prevalence of technology deployments in data management. ‘Constitutive’ emphasizes that these technologies transit from outsiders to those closely engaged with lifelong data management intrinsically. Data technicity fastens the pace of value extraction from data and even exceeds human visions in many cases (Silver et al. 2017). The evolving technical design should be interoperable across machines and inclusive to humans. Enhanced collaborative research models and international alignment are to follow, affirming the transparency, flexibility, robustness, and intelligibility in technical development to face the ever-growing data deluge locally and globally. And the FAIR use of technologies should follow the open science paradigm, such as the cases in tackling natural hazards, health crises, and climate change and achieving the UN SDGs.
Data infrastructuralism tends to merge data and technology into streaming and scalable services. ‘Infrastructuralism’ (Breu & Leo 2022; Brehm 2022), adopted here as a neutral concept, refers to the centrality and materiality of data infrastructures. Future data infrastructures will be incredibly important in integrating multiple-sourced data and complex technologies for user-friendly services. Furthermore, infrastructuralism highlights the predominant roles of data infrastructures in coordinating data science essentials. Guided by open science, data infrastructuralism will overturn the traditional business models, and provide a reciprocal environment for research and innovation with everyone involved. To better serve as the engines of global research, future facilities should fit into the growing need for enhanced and open data infrastructures, assembling cutting-edge technologies and optimized data resources. Furthermore, these infrastructures should follow interest-balanced and cost-effective models to leverage the responsibilities and rights of all potential stakeholders. Future data infrastructures should also pinpoint collaboration, openness, interconnection, and inclusiveness to reshape trustworthy and reliable worldwide science and technology.
In addition, data education extends literacy empowerment to proliferate data science and cultivate the whole society. Skills training (such as knowledge of programming, algorithms, and systems) is useful to capture the exponentially increasing value of data. At the same time, data literacy (Wolff et al. 2016; Gummer & Mandinach 2015) may also consider epidemiology, policies, participants, impacts, and sustainability to serve particular training objectives. Possible courses should be diversified, covering data culture, rights, and ethics for decent data reuse; data epidemiology, critical thinking, and data skills for efficient data reuse; and data accountability, metrics, and data audits for reliable data reuse. Different training pieces should educate data professionals and citizens, thus establishing shared values on data science. Data education will also endure interactive processes to help everyone get ready for the changing world.
Meanwhile, besides the four essentials, future data science also calls for a full data picture at the macro level. Accordingly, the data ecosystem should be established based on mutual trust. Under the umbrella of open science, future data science will work efficiently and systematically as an ecosystem, with data, technology, education, and others integrated through infrastructures. Thus, key actions may include establishing and maintaining an open science environment for the data ecosystem, involving potential stakeholders under sound management strategies (i.e., interest-balanced models) and sustained models (i.e., fair and efficient reward systems), opening dialogues between communities, and collaborating on open science and data initiatives. In addition, future data ecosystems should encourage the data-sharing culture and enhance the global alignment between physical and virtual facilities to support the data flow of enormous research scopes across domains and regions. Surely, based on a harmonized data ecosystem, data science and the essentials will help us prepare deeply and widely for the adventurous data journey forward.
5. Conclusions
The recent two decades of data science have been long and exciting, full of difficulties and boundless potential. Looking back into the human history of thousands of years, two decades of data science is extremely short. However, it is of great significance. The transit to the fourth paradigm of scientific research, the global wave of the digital economy accompanied by the rapid rise of many developing economies, the dramatic development of the global village, and the polarization of digital integration and the digital divide are just a few examples. Nevertheless, the great charm of data science lies in the science and permeates the social lives of everyone every day. The power to master the double-edged data sword will advance data science explosively.
As this paper elaborates, data, technology, infrastructure, and education contribute jointly to the four-wheeled wagon of data science. The four essentials will together effectively consolidate and enhance the construction and development of future data science. Meanwhile, the call for open science provides rich soil for the healthy development of the whole data ecosystem. Therefore, looking into the future, we will embrace a better world driven by open data resources, responsible technologies, open infrastructures, and inclusive data education.
Data Accessibility Statement
Data are captured from the Web of Science with selected articles entitled ‘data science.’ There are no strict constraints on publication times to trace the theme evenly. As a result, 4,131 pieces of records are returned, including 88 records earlier than 2000. Among them, 3,490 non-null-value publication abstracts are taken as valid textual results for word frequency analysis and word cloud visualization by Python. Data are available at www.webofscience.com [Last accessed 24 February 2023].Refined data and python code are available at: https://doi.org/10.57760/sciencedb.07847.
Acknowledgements
This work is based on the talk during the International Data Week 2022 session entitled ‘20 Years of Data Science—An Assessment’ and is supported by the National Natural Science Foundation of China (No. 72104229), the Chinese Academy of Sciences (No.241711KYSB20200023), and CNIC, CAS (No. CNIC20220101). Many thanks to Paul Uhlir, Xueting Li, and Yandi Li for their insightful comments, and I also thank all of the anonymous reviewers and editors for their valuable suggestions. Special thanks to my mom for taking me back to those exciting daily moments brought by data science over the past two decades.
Competing Interests
The author has no competing interests to declare.