
Hotel revenue management (RM) has its roots in the concept of yield management. Early definitions of RM focused on setting different prices for different customers receiving the same service, while also managing the balance between occupancy and average rate (Weatherford & Bodily, 1992). Over time, hotel RM has grown into a more advanced and multi-faceted discipline. Gregory (2012) notes that hotel RM has shifted from being a unit-level tactic to a broader strategy aimed at optimising total revenue or profit across the entire organisation. Modern hotel RM now adopts a more integrated approach, factoring in internal dynamics—like inventory and distribution channels—alongside external elements such as market trends, competitors, and consumer behaviour (Helmold, 2020).
Given the omnipresence of hotel RM throughout the organisation, it is imperative that hotel management develop and implement an RM system capable of routinely and accurately forecasting future outcomes (Huang & Zheng, 2021). Given that a hotel room has a shelf life of a single day, hotel demand forecasting has become a key area of scholarly inquiry (Pan & Yang, 2017). Numerous authors assert that demand forecasting is central to any hotel RM system (Fiig et al., 2019; Schwartz et al., 2016), and even claim that the success of an RM system is largely dependent on its accuracy in demand prediction (Koupriouchina et al., 2014). Demand forecasting in the context of hotel RM refers to the prediction of demand for hotel rooms, using proxy measures such as booking curves or hotel occupancy (Schwartz et al., 2016). The booking curve models the accumulation of reservations for a specific future date, whereas hotel occupancy denotes the historical occupancy pattern based on recorded observations. The prediction of hotel occupancy has become particularly significant because of its simplicity, accuracy, and cost-effectiveness, making it popular and practical for hotel operators and academics (Caicedo-Torres & Payares, 2016; Tang et al., 2017).
While there has been much research surrounding methodologies for hotel room demand forecasting, most studies use traditional forecasting methods (Huang & Zheng, 2023). But with the advent of smart technology, artificial intelligence, robotics, and algorithms (STARA) (Brougham & Haar, 2018), it has become of particular interest to scholars and practitioners to study and employ machine learning (ML) models for RM. Researchers implementing ML methodologies have found that these methods outperform traditional forecasting methods (Lee et al., 2020; Pereira & Cerqueira, 2022; Schwartz et al., 2021). As ML continues to grow within the field of hospitality RM, it is critical to have a comprehensive understanding of the current state of evidence if the field wishes to keep pace with technological advances in the industry, harness the power of ML, and identify knowledge gaps to inform future research directions. Accordingly, the goal of this study was to systematically review the literature on ML as a method to predict hotel occupancy.
The primary objectives of this systematic review were to: (1) identify and assess the uses of ML to forecast hotel occupancy, (2) identify the current trends in the literature, and (3) introduce future areas of research. This review also aimed to identify the study types and methodologies, the ML model inputs, the methods for model performance evaluation, and the quality of the studies. The specific research questions were: (a) What are the ML models that are used for hotel occupancy forecasting? (b) What are the input variables used for modelling hotel occupancy? (c) What pre-processing techniques are used? (d) What training and cross-validation techniques are used? (e) What performance metrics are used for model evaluation? (f) What software is most used for ML?
While this is the first systematic review of ML applications specifically for hotel RM demand forecasting, considerable research has been conducted in other disciplines and related areas within hospitality and tourism. Demand forecasting using ML is not unique to hospitality; reviews have been conducted in supply chain management, energy management, and emergency management. In hospitality, reviews have covered general ML applications, big data, AI, RM, and demand forecasting.
Reviews of AI and ML in hospitality and tourism often take a broad perspective. Alotaibi (2020) critically reviewed ML applications in hotels, covering areas of application, techniques, and countries of prominence. Nannelli et al. (2023) identified research strands and future directions in AI in hospitality and tourism, while Knani et al. (2022) adopted a bibliometric approach, outlining the evolution of themes and key authors. Guerra-Montenegro et al. (2021) reviewed computational intelligence (CI) in hospitality, categorising research areas by ML application. Doborjeh et al. (2022) focused on AI methods and their adaptation in hospitality and tourism. These reviews highlight demand forecasting but lack a focused investigation into ML for this specific purpose.
Related research includes big data and analytics. Lv et al. (2022) reviewed AI and big data in hospitality, identifying applications, trends, and future implications. Mariani and Baggio (2022) reviewed big data and analytics in hospitality, identifying ML as an important application but without in-depth focus. Reviews of hotel RM specifically include Binesh et al. (2021), which conducted a meta-analysis of the hotel RM literature, identified demand forecasting as a key topic, and suggested ML as an under-researched method. Other reviews (Denizci Guillet & Mohammed, 2015; Erdem & Jiang, 2016; Ivanov & Zhechev, 2011) predate the increase in ML-related publications since 2019.
Zhang et al. (2020) and Choi et al. (2022) focused on demand forecasting. Zhang et al. (2020) developed a knowledge map of tourism demand forecasting, but did not specifically consider hotels. Choi et al. (2022) reviewed hotel forecasting studies, focusing on methodologies and trends. Huang and Zhang (2023) and Dowlut and Gobin-Rahimbux (2023) also made significant contributions. Huang and Zhang analysed the evolution of hotel demand forecasting, while Dowlut and Gobin-Rahimbux focused on deep learning approaches. Despite these contributions, a focused review on ML for hotel RM demand forecasting remains needed.
While systematic reviews used various methodologies, only Doborjeh et al. (2022) and Mariani and Baggio (2022) used an established review framework like PRISMA. Pahlevan Sharif et al. (2019) note the lack of specific protocols and clear processes in hospitality and tourism literature, emphasising the need for comprehensive review methodologies.
This study addresses the research gap in various ways. First, it provides a rigorous review following the PRISMA guidelines, a practice that is currently underutilised in the hospitality and tourism field. Second, this study identifies common practices and the current state of ML in hotel occupancy forecasting literature. This is essential, as hotel occupancy forecasting is the most basic method for forecasting hotel demand, which underpins many revenue management decisions (Fiig et al., 2019; Koupriouchina et al., 2014). Third, this review addresses limitations and outlines areas of future research in the literature. Finally, this study provides guidelines and suggestions for future demand forecasting research that utilises ML methods.
To identify these gaps, this study conducted a rigorous selection process, selecting fourteen articles that applied machine learning to hotel occupancy forecasting. Because hotel occupancy is the primary proxy for demand used by hotel revenue managers (Schwartz et al., 2016), we limit our scope to papers that examine hotel occupancy forecasting (as opposed to tourism arrivals or other demand proxies). Similarly, because we were interested only in the application of machine learning models, we only considered studies that employed machine learning for the forecasting problem, as opposed to traditional forecasting models like Holt-Winters or simple exponential smoothing (SES).
We utilised the Preferred Reporting Items of Systematic Reviews and Meta-Analyses (PRISMA) (Page et al., 2020). PRISMA provides a standardised framework for identifying, screening, and reporting studies in systematic reviews, enhancing both the reproducibility and reliability of the review process. By adhering to this protocol, this study minimises bias in study selection and data extraction, improving the clarity of reporting and strengthening the validity and credibility of the findings (Moher et al., 2009).
The following criteria were used to select relevant studies according to the review’s objectives. To be included in the review, studies must (1) predict hotel occupancy (i.e., the number of rooms occupied in a hotel on a given night), (2) use an ML methodology (see Jordan & Mitchell (2015), (3) be published in the last five years, (4) be published in English, (5) be a peer-reviewed publication, and (6) employ a model evaluation metric such as MAPE, RMSE, etc. Hotel occupancy was selected as the target metric of interest because it is one of the fundamental proxies for hotel demand (Schwartz et al., 2016) and because it is accessible to even small, independent hotels (Ampountolas & Legg, 2023). This study included papers written in the last five years. This is for three reasons: (1) reviews have already been conducted for the literature up to 2019 in RM (Binesh et al., 2021), up to 2021 in AI methods in hospitality and tourism (Doborjeh et al., 2022; Guerra-Montenegro et al., 2021), and up to 2022 in demand forecasting (Huang & Zheng, 2023), (2) hotel demand forecasting literature reached new heights in terms of publication rates in 2019, where the average number of publications per year almost doubled in the period between 2019 and 2021 (Huang & Zheng, 2023), and (3) the exponential growth rate of artificial intelligence innovation means that methodologies may become obsolete after a very short time (Tang et al., 2020).
Papers were excluded if they modelled booking curves instead of hotel occupancy, if the target variable was a macro-level occupancy rate (for example, of a city or nation), or if they compared methodologies that were not ML methodologies.
Guided by the Context, Intervention, Mechanisms, Outcomes (CIMO) framework for systematic reviews (Booth et al., 2021), Boolean search term conditions were created and separated for the four criteria of this review. Terms, vernacular, abbreviations, synonyms, and various conditions of the context (hotel), intervention (machine learning), mechanism (demand forecasting), and outcome (occupancy) were used for querying ten information sources. To identify relevant keywords, the research team consulted experts in ML and hospitality RM. The final search strategy consisted of four components connected by an “AND” operator. The first component captured the hotel context, the second captured the application of ML, the third captured the demand forecasting function, and the final component captured the outcome, the occupancy rate. See Appendix 1 for the list of words used in the search.
Candidate articles were uploaded to Rayyan (Ouzzani et al., 2016), where duplicates were removed using the software’s duplication detection function. Rayyan is a literature review. Two members of the research team independently screened the title and abstract of each citation for their eligibility, resolving conflicts through discussion. Following the title and abstract screening, the same authors assessed the full-text papers for inclusion, where conflicts were resolved by consulting a third reviewer and consensus.
The research team developed a data extraction form to collect pertinent information from each study ultimately included in the study. Each member of the research team collected the data independently by thoroughly analyzing each of the articles that met the inclusion criteria. Once the data extraction form was populated, the research team conducted both bibliographic and content analyses. The bibliographic analysis consists of analyses of the journals that most frequently published the papers that met the inclusion criteria, the authors who published in the area, and the number of publications per year. The content analysis discusses methodological factors found within the literature, including the booking horizons, the input variables that were found to be significant, the validation processes, and the types of data used in the analyses. It also discusses other factors, such as the type of studies, the general aims of the studies, the use of theory in the articles, feature engineering, hyperparameter tuning, cross-validation, pre-processing, algorithm selection, the interpretability of the ML models, model evaluation criteria, and areas of future research.
A wide variety of data items were extracted from the final papers. First, bibliometric variables were extracted, such as title, year, author, and journal. General study-related variables were also extracted, including the type, aims, theoretical foundation, results/conclusions, and summary of the article. Data-related variables were extracted, including data type, data frequency, and the input variables used in the model. Additionally, information related to the ML pipeline was also extracted, such as hyperparameter optimisation method, data preprocessing, interpretability integration, software used, accuracy metrics, cross-validation method, ML method(s) used, and the best-performing model.
The study type was coded as either an empirical study, where a model was developed for forecasting, or a comparison study, where multiple models were compared in terms of their forecasting results. The use of theory was a binary variable, which indicated whether a theory was used or not in the study. Regarding forecasting horizons, three main variables were extracted: whether multiple horizons were used in the study, the horizon lengths (short, medium, or long), and, specifically, the number of days ahead. In terms of the data, we also collected three variables: the frequency of the data (daily, monthly, etc.), the type of data that was collected (historical, booking, or pricing), and the nature of the data (quantitative, qualitative, mixed). The data gathered in relation to the machine learning pipeline included the ML models used (non-linear, deep learning, tree-based, etc.), the validation technique (split-sample, rolling-window, etc.), the accuracy metrics used (MAPE, RMSE, etc.), and the interpretable ML method used (if any).
Each member of the research team independently extracted data from each article. Any discrepancies in extracted data points were resolved through discussion. The extracted data was then aggregated into an Excel spreadsheet, which was loaded into the R software. Once we pulled the data into R, we cross-tabulated and visualised the data in different ways to conduct the descriptive bibliographic, content, and methodological analyses.
In addition to data extraction, each article was critically appraised using a checklist adapted from the Checklist for Artificial Intelligence in Medical Imaging (CLAIM; Mongan et al., 2020), which was developed to assess publications that employ AI techniques in medical imaging. The adapted version of this checklist that we used for this study contained some additional items that were specific to forecasting, such as the use of forecasting horizons, the frequency of the data, and the evaluation of performance across different forecasting horizons. We also omitted certain irrelevant items from the CLAIM checklist that were specific to a medical setting, such as the clinical background, the intended use and clinical role of the AI approach, de-identification methods, and flow of participants or cases. Lastly, we adapted some of the items, such as implications for practice, clinical role, and background, to be specific to the hospitality and tourism field. The final checklist contained 39 items that were related to each section of an academic article (introduction, methods, results, etc.). The checklist was completed independently by two reviewers, and the final quality assessment was based on consensus.
As displayed in Figure 1, 14 publications were included in the final systematic review. Four were from hospitality and tourism journals, four from information systems journals, two from the Journal of Revenue Management and Pricing, two from the Journal of Forecasting, one from Business, and one from Sustainability. Only one of the articles was published before 2020; the remaining 11 were published in 2020, 2021, 2022, 2023, or 2024.
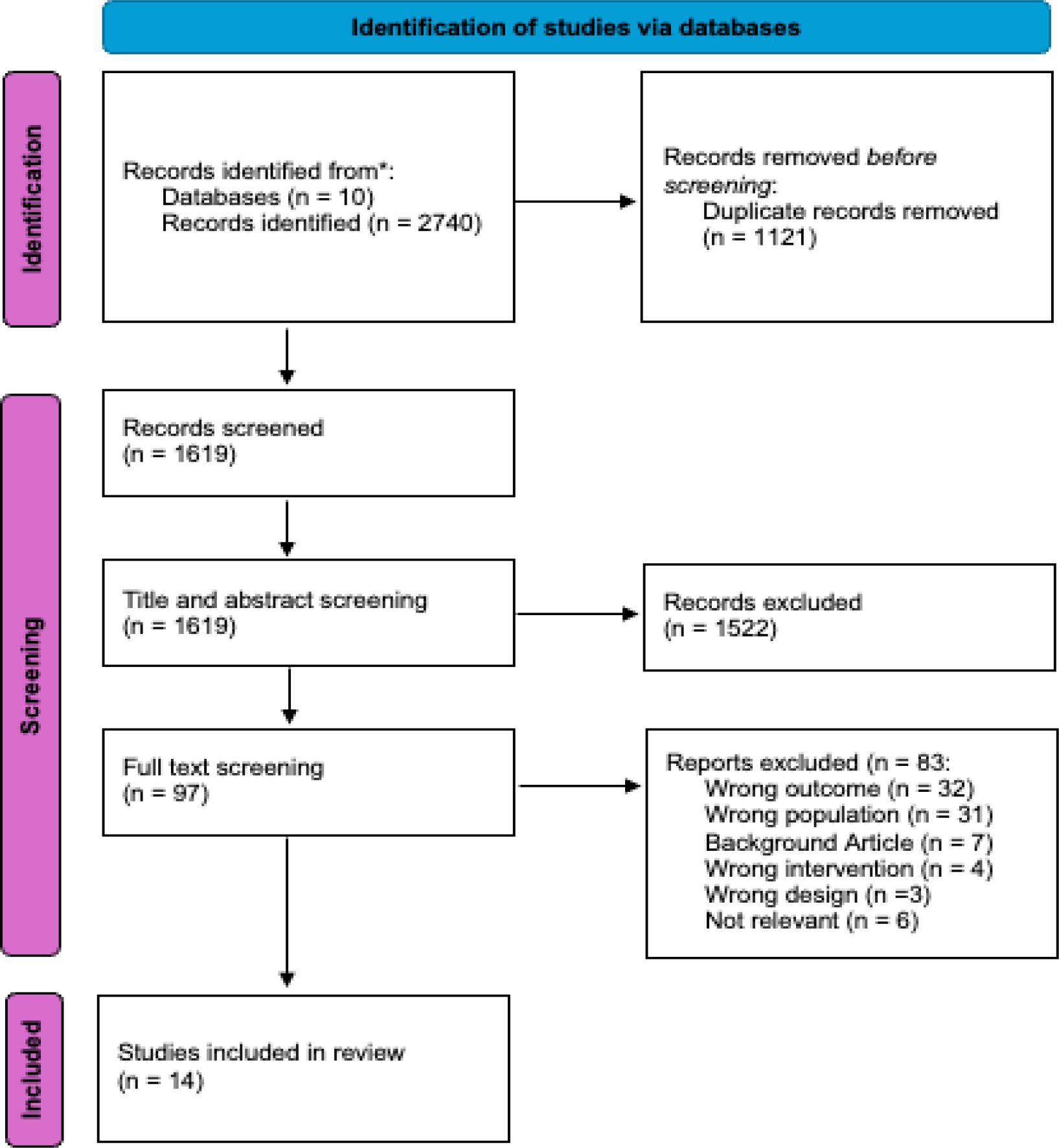
Article Screening Protocol
When considering the authors’ affiliations, several notable trends emerged, as shown in Figure 2. Of the 28 authors across the 14 studies, only two were from North American institutions. Over half of the authors were from Asian institutions (16), and over a third of the authors were from European institutions (10). Another interesting finding was that only 13 of the researchers were associated with either hospitality or business departments. Most of the authors were affiliated with mathematics or engineering-related departments. Similarly, among the authors, over three-fourths (22) held a degree in a STEM field, despite hospitality not traditionally being a mathematics-intensive field. In fact, the six authors who did not hold a STEM degree all attended either hospitality or business colleges. This reveals the importance of subject-matter expertise in mathematics, statistical modelling, and computer engineering in hotel demand forecasting.
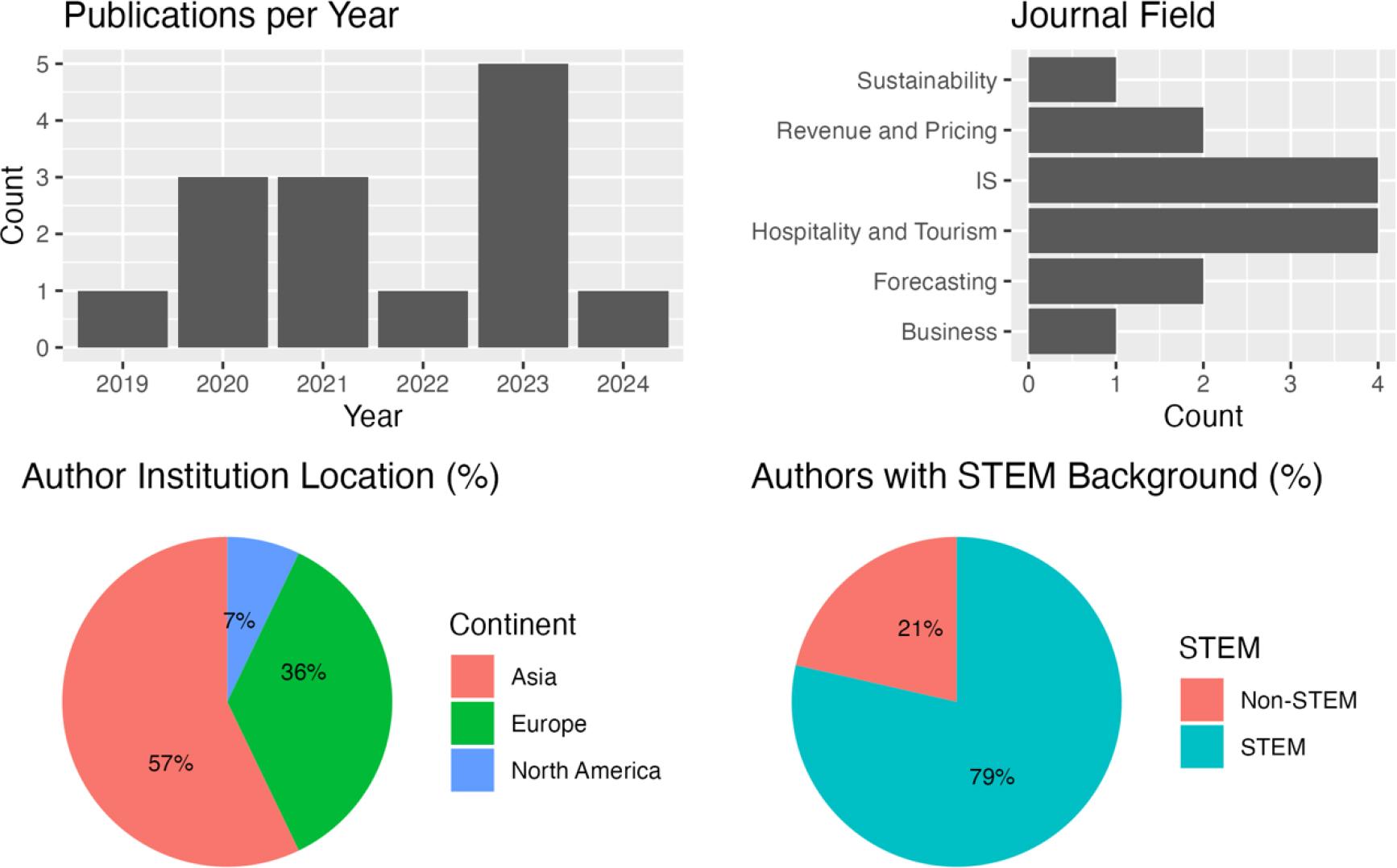
Bibliometric Characteristics
Recent literature in hotel demand forecasting can be grouped into three study types: model development, accuracy comparison, and model improvement studies. Model development introduces specific input variables or methodologies; accuracy comparison evaluates the performance of various forecasting models; and model improvement tests the same models with and without certain effects. Some studies included both model comparisons and effect comparisons. All articles were empirical, featuring mathematical derivations and explanations of ML concepts and theories. However, a general lack of a theoretical framework was noted. Accuracy comparison studies did not include theory due to their quantitative nature. Studies incorporating online reviews cited linguistic theories like systemic functional linguistics, the ESPN framework, and dual process theory.
Out of 14 articles reviewed, twelve mentioned the software used for analysis: one used Matlab, five used R, and seven used Python. Due to the complex nature of ML modelling, especially in forecasting tasks, data sciencespecific software is preferred over point-and-click software like SPSS. Reasons include open-source software like R and Python enabling open science practices, flexibility, access to new algorithms, and easy collaboration; most authors had STEM backgrounds with programming education; and these software tools provide a wide range of capabilities for the entire ML pipeline, from data cleaning to visualisation.
Recent literature on hotel occupancy prediction utilised various data types, either purely quantitative or mixed datasets. Nine studies used historical demand data alone or combined with booking, sales, pricing, and online review data. Mixed datasets included combinations of online customer reviews or social media sentiment data with historical demand, hotel sales, and/or pricing data. Given the exclusion of macro-level occupancy studies, most data were collected at the daily level. Specifically, ten studies used daily data, two used weekly data, and two used monthly data. Daily data are preferred for their granular detail, capturing nuances that aggregated weekly or monthly data may miss. Interestingly, three of the four studies incorporating hotel reviews used non-daily data, likely because longer periods are required to analyse sentiment changes.
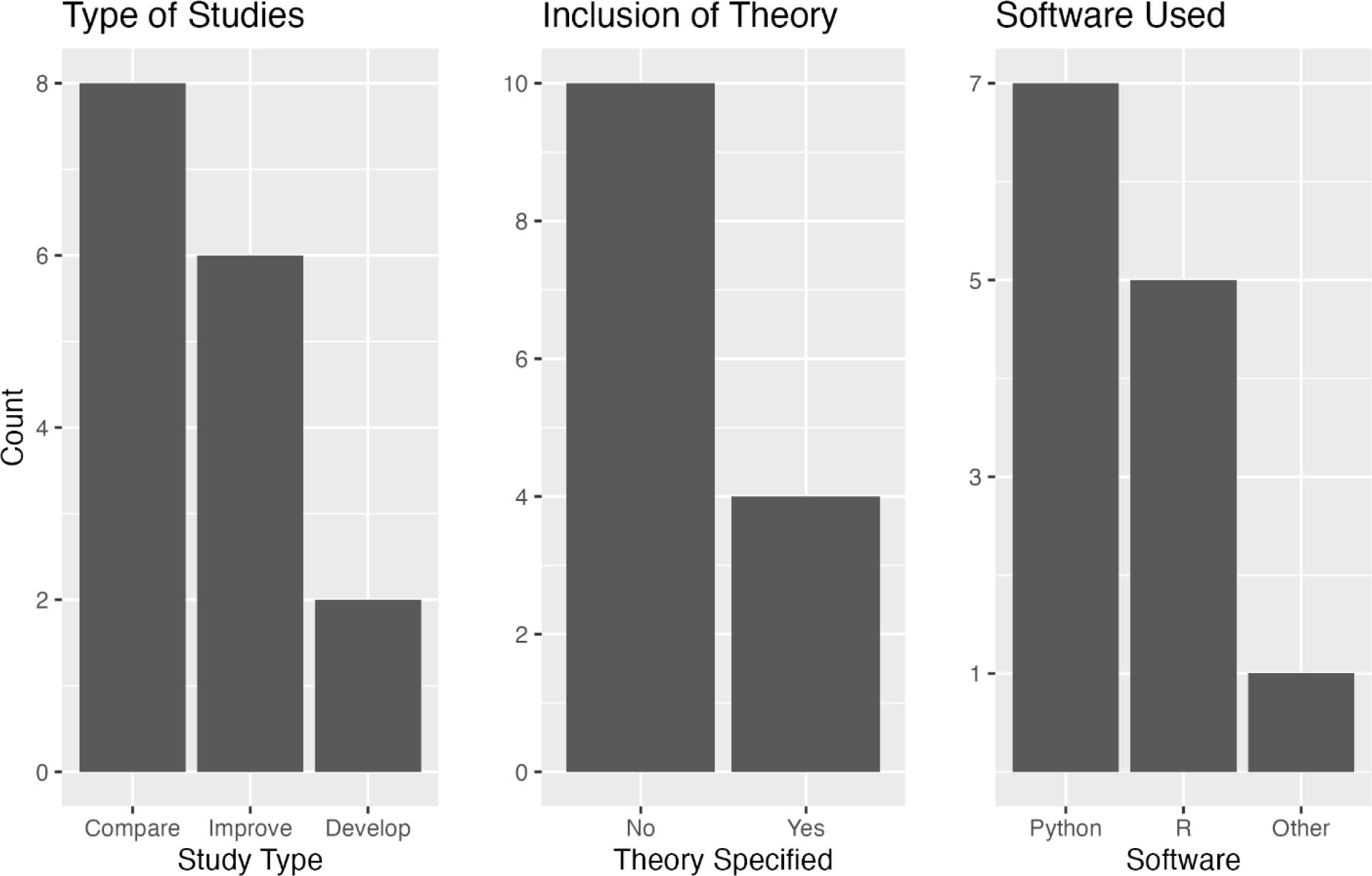
Study Characterisations
The included studies featured a wide range of input variables. Basic inputs included historical demand data, holidays, competitive set ranking, and temperature. These were expanded to include additional variables such as search indexing, bookings, events, macroeconomic factors, pricing dynamics, and spatial features. Customer reviews were also incorporated, acknowledging the importance of social reputation in demand for goods or services (Cho et al., 2024; Phillips et al., 2017). Studies used proxies for social reputation such as social media posts, online ratings, and reviews, along with related variables like review timing and customer segments. Sentiment analysis of social media posts and online reviews improved prediction metrics when integrated into ML models. Online reviews were typically analysed as text, but Chen et al. (2023) introduced a novel multi-modal method, analysing reviews with both text and images. All studies incorporating review data used Python for scraping and analysis.
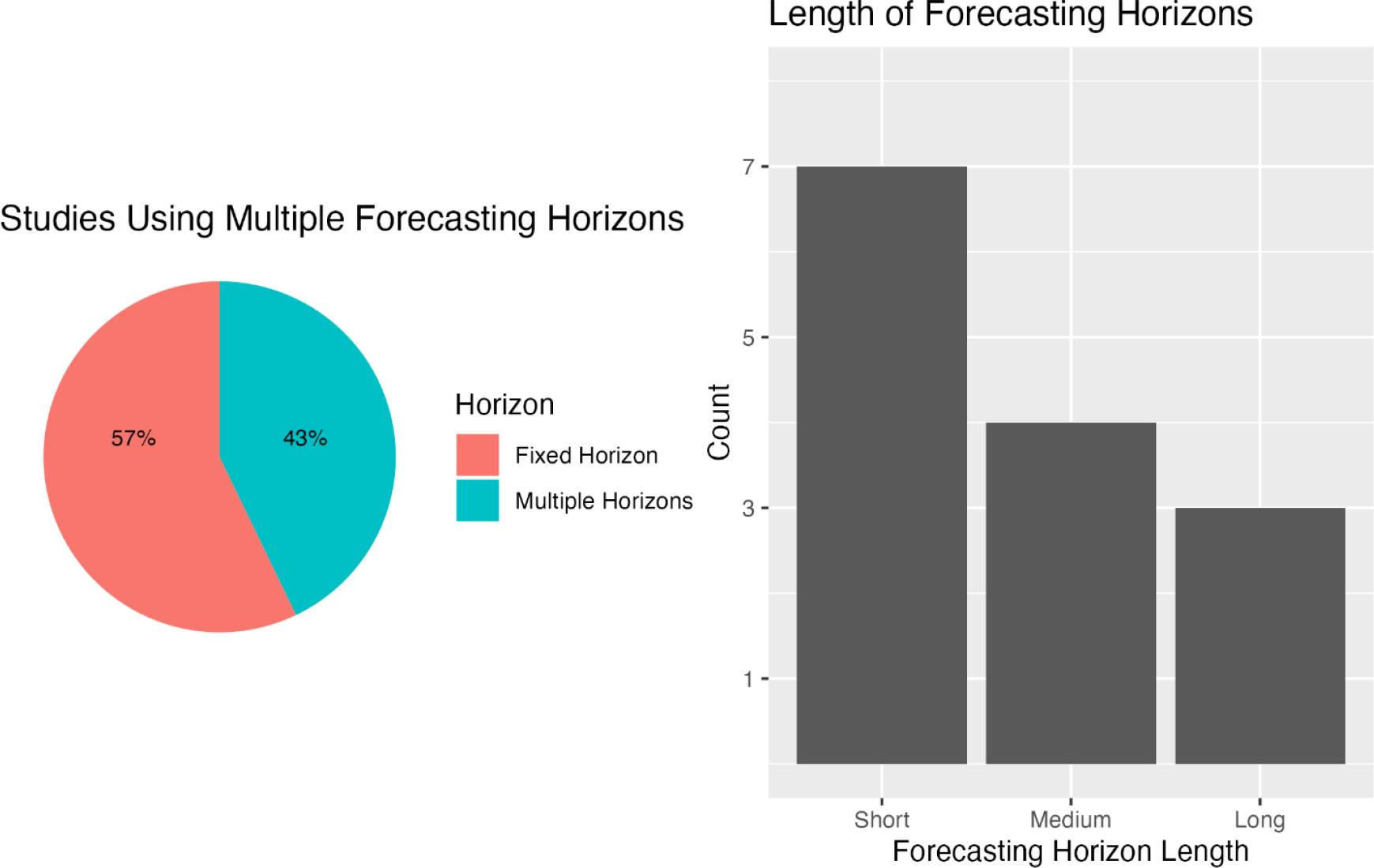
One crucial aspect of forecasting studies is considering the forecasting horizon, which refers to the time period over which future occupancy levels are predicted. The horizon can vary with the hotel’s needs; short-term forecasts may be used for operational planning, whereas longterm forecasts may be used for strategic decision-making. Forecasting studies typically evaluate predictions at different horizons.
Among the 14 reviewed articles, six predicted hotel occupancy at a single horizon, while others compared accuracy at varying horizons. Studies looking at a single horizon were divided into short-term (one month or one week out), mid-term (40 and 61 days out), and long-term (annual forecasts and periods like pre-, during, and post-COVID). These static horizon studies are important for ML advancements in hotel demand forecasting. However, they may not provide hotel operators with the insights needed for revenue management decisions based on different future demand perspectives.
To address this, the other articles compared accuracy rates across different forecasting horizons. All of these studies trained their models on daily hotel data, likely because more granular data can be more efficient with multistep-ahead forecasts (Charoenwong & Feng, 2016). They predicted horizons ranging from 90 days to 1 day out. The most common short-term prediction interval was 1 to 14 days, as reported by five studies. The next most common range was 2-4 weeks (one month). Additionally, two articles focused on mid-term forecasts, predicting hotel occupancy at different points ranging from one to three months.
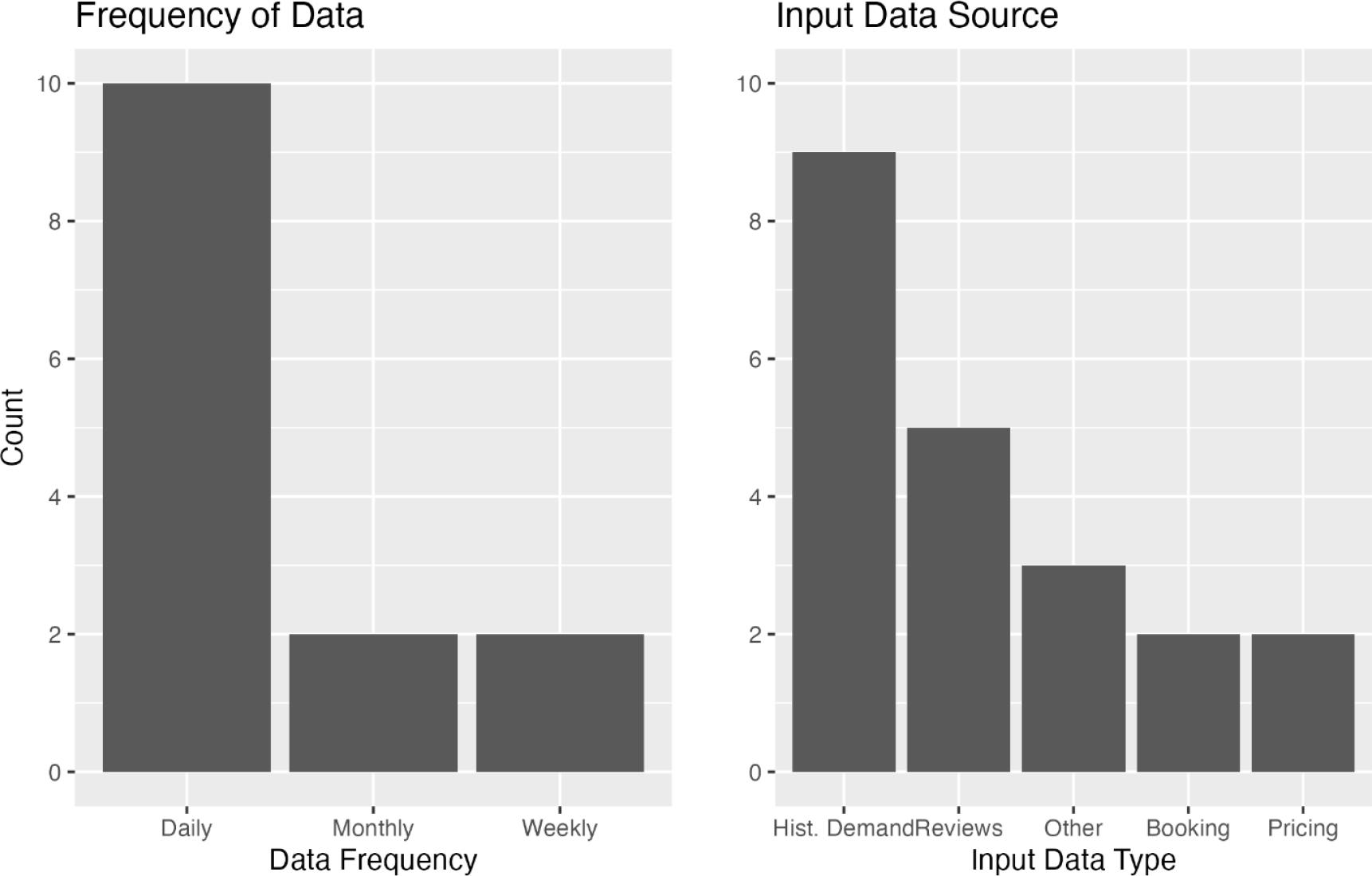
Characteristics of Input Datasets
These intervals are key for operational and strategic decisions, enabling hoteliers and revenue managers to make informed choices. They also help users understand how prediction accuracy changes as the booking horizon shortens, allowing practitioners to assess the certainty of decisions at specific times.
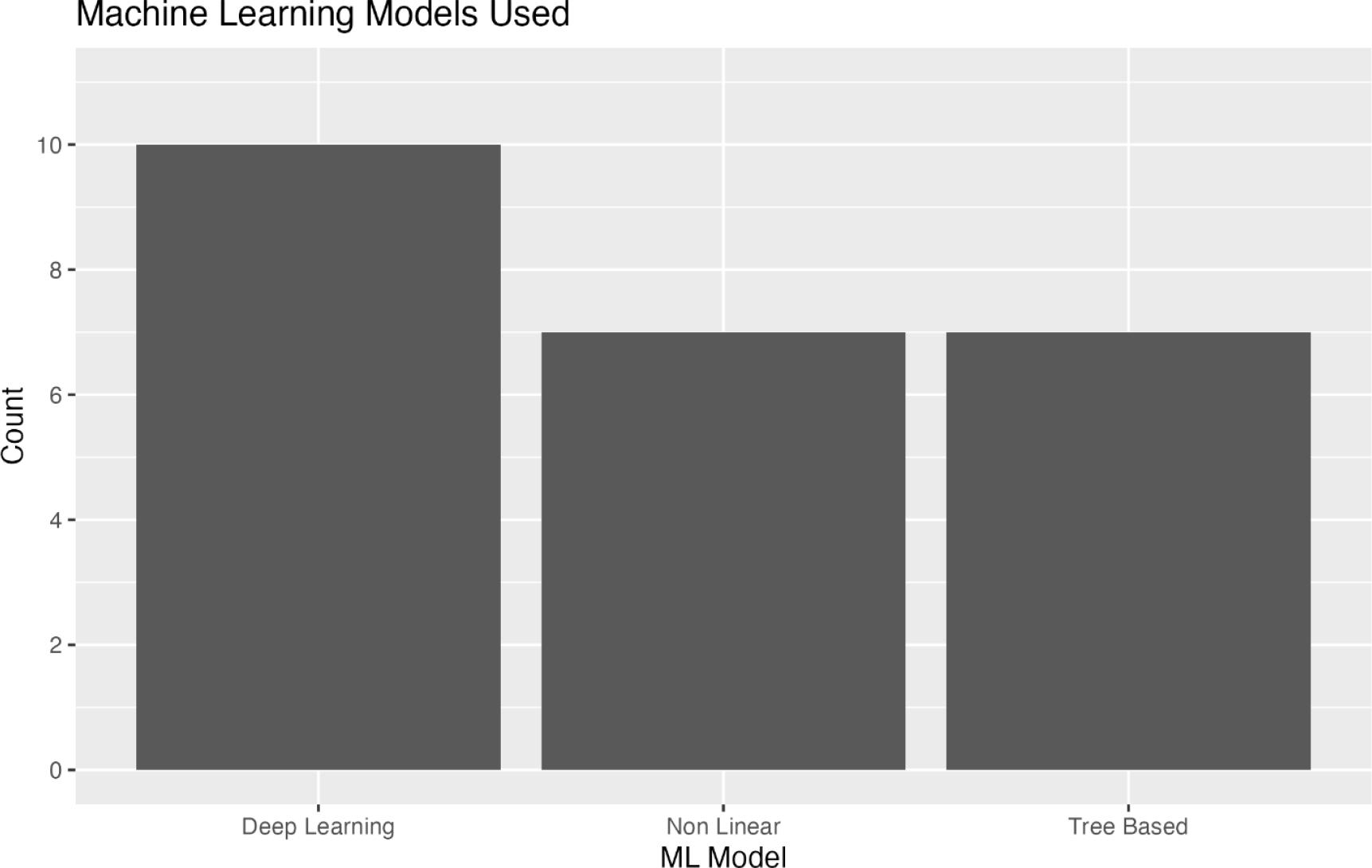
A wide range of machine learning methodologies were employed across the included studies. These models can be broadly categorised into deep learning, tree-based models, and non-linear models.
Deep learning models ranged from simple architectures such as artificial neural networks and multi-layer perceptrons (MLPs) to more complex ones, including long shortterm memory (LSTM), gated recurrent units (GRU), and graph convolutional networks (GCNs). These models were adapted in various ways to understand different effects. For instance, Huang et al. (2023) incorporated spatial and temporal correlations into their LSTM model, Chen et al. (2023) adapted their GRU model to include bimodality, and Zhang and Niu (2024) and Zhang and Wu (2023) incorporated attention mechanisms into their LSTM models. Treebased models were also frequently applied, with XGBoost being the most popular. The studies also utilised various non-linear models, such as support vector regression, fuzzy systems, Gaussian processes, and Prophet, which were used to develop novel models for predicting hotel occupancy.
Across the 10 studies that compared models, ML models outperformed baseline models in 8 studies. Ampountolas and Legg (2021) found that a SARIMAX timeseries model outperformed a multi-layer perceptron in daily forecasting across almost all horizons. Similarly, Kozlovskis et al. (2023) found that bagged tree models could not outperform the autoregressive distributed lag (ARDL) model used as a baseline. Interestingly, Ampountolas and Legg (2023) found that simple exponential smoothing (SES) performed best at longer horizons, while XGBoost performed better at shorter forecasting horizons. Studies comparing the incorporation of specific effects into models found that including spatial effects, event data, social media data, and customer reviews increased the performance of ML models.
During data extraction, cross-validation methods, interpretability methods, hyperparameter tuning, and accuracymetrics were collected for analysis to ensure the quality and rigour of ML studies (Navarro et al., 2021).
Forecasting Horizons Used
Machine Learning Methodologies Used in the Studies
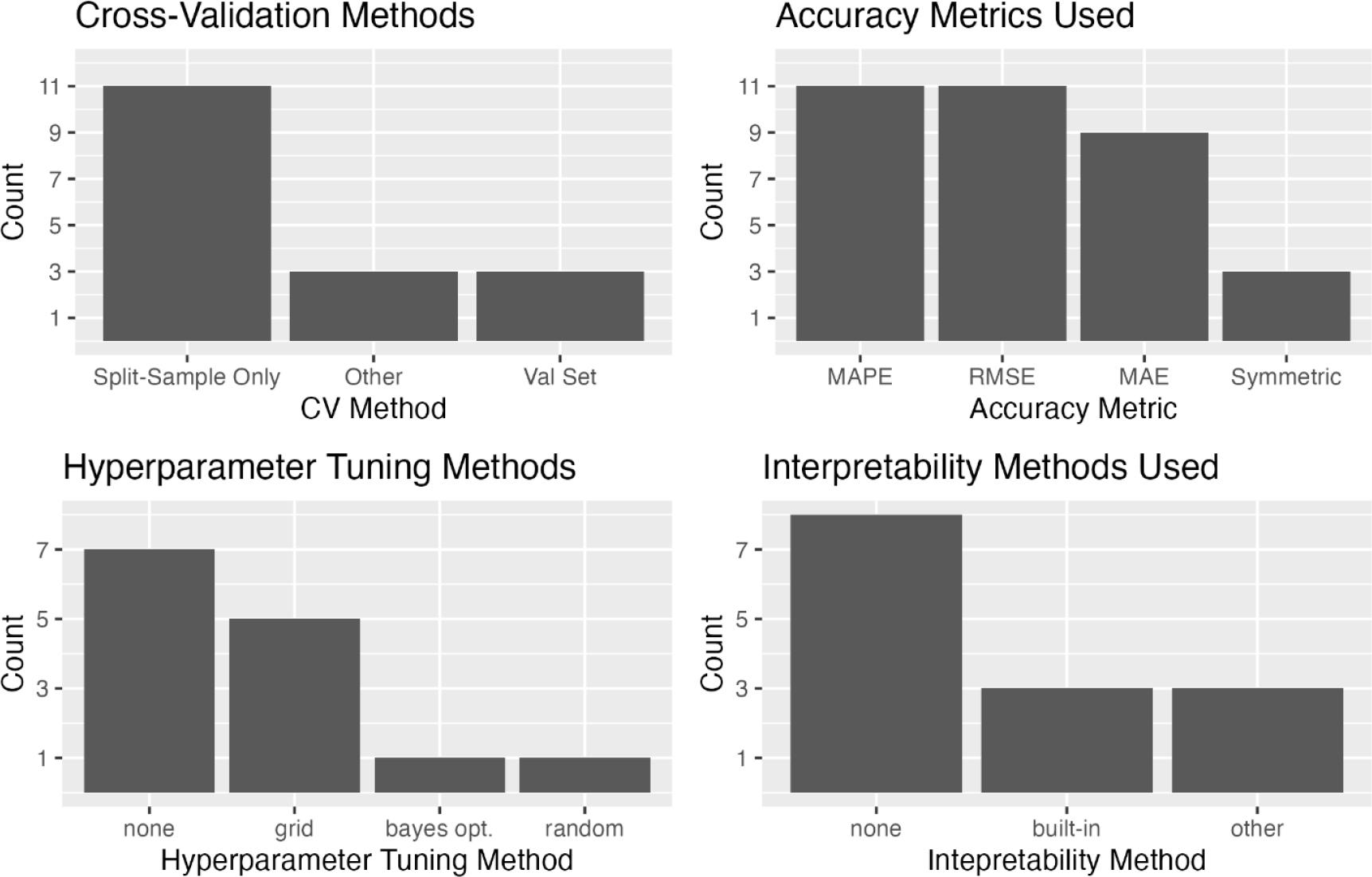
According to Figure 7, the most widely used cross-validation method was split-sample validation, which involves splitting the data into a training and a test set. This method lacks rigour compared to cross-validation during the training phase with different folds of the data. Of the 14 articles, eight used split-sample validation. Three articles added an extra degree of rigour to the split-sample validation by splitting the training dataset into a training and validation set for model development. The remaining three articles employed more complex methods, such as the walk-forward strategy, fixed-window recalibration, and custom training algorithms (Huang et al., 2023; Pereira & Cerqueira, 2022; Chen et al., 2023). These strategies represent the highest level of rigour for crossvalidation of ML models. They should be considered the gold standard, particularly because split-sample validation alone can lead to overfitting, bad generalisation, and biased results.
Machine Learning Pipeline Methodologies for Cross Validation (CV), Accuracy Metrics, Hyperparameter Tuning, and Interpretability
The accuracy metrics employed across the included studies can be categorised as either scale-dependent or scale-independent metrics. On average, four accuracy metrics were used per article, and at least one scale-dependent and one scale-independent measure was used in all but two articles, which exclusively utilised scale-dependent metrics. It is important to use scale-independent measures so that forecasting results can be compared across studies. As displayed in Figure 7, root mean squared error (RMSE) and the mean absolute error (MAE) were the two most common scale-dependent measures, while the most popular scale-independent measure was mean absolute percentage error (MAPE).
To address the asymmetry problems with MAPE, authors incorporated improved metrics like symmetric MAPE (sMAPE), the log ‘forecast to actual’ ratio (Ln Q), and the average relative MAE (AvgRelMAE). These improved metrics help in mitigating the asymmetry associated with MAPE and provide more robust means of comparing accuracy rates both between models and across studies (Schwartz et al., 2023; Tofallis, 2015; Huang & Zheng, 2021; Ampountolas & Legg, 2023).
Interpretability of predictive models in hotel demand forecasting varies significantly across studies, reflecting the balance among prediction accuracy, model complexity, and the need for understandable outcomes.
However, only six of the studies included model interpretability techniques. Among these, three articles used feature importance metrics built into the ML models (Ampountolas & Legg, 2021; Chen et al., 2023; Kozlovskis et al., 2023). The other three articles provided prediction intervals using Gaussian processes, interaction layers and SFL-based models, and attention-based weights from a deep learning model (Zhang & Niu, 2024; Tsang & Benoit, 2020; Zhang & Wu, 2023). These methods enhance interpretability by providing deeper insights into model decisions and making complex models more explainable.
The approach to hyperparameter optimisation in hotel demand forecasting research varies across studies, reflecting differing needs for model tuning and precision. Many studies did not specify their hyperparameter strategies, leaving an unclear picture regarding the optimisation processes used in their predictive models. However, several studies explicitly detailed their optimisation techniques, providing insights into the rigour and technical depth of their methodologies.
Five studies employed a grid search method to systematically explore and select the best parameters for their ML models. Huang and Zheng (2021) employed Bayesian optimisation in their study, a technique known for its efficiency in finding optimal solutions with fewer iterations. Phumchusri and Ungtrakul (2020) employed a random search approach for hyperparameter tuning, yielding a faster but less exhaustive exploration of the hyperparameter space. These techniques illustrate the diverse strategies researchers adopt to refine their predictive models.
The articles were evaluated using the adapted CLAIM checklist, which assessed 39 items related to ML studies. For the filled-out CLAIM checklist for the articles, please see the supplemental materials. Overall, the articles scored relatively well, with the lowest-scoring article containing 27 items on the checklist and the highest-scoring article containing 37 items. All articles had strong introductions, descriptions of methodologies, data, accuracy metrics, and visualisations of the results. The selected articles fell short on several other items, particularly in the following areas: specifying research questions, handling missing data, cross-validation techniques, model interpretability, and bias mitigation.
Specific research questions were not stated in over half of the studies. Several studies stated hypotheses, but four studies, in particular, did not provide hypothesis statements or specific research questions, leading to ambiguity of the study objectives. Similarly, missing data were not addressed in half of the studies. Because missing data can hinder performance, produce problems in data analysis, and lead to biased outcomes (Emmanuel et al., 2021), the presence (or absence) of missing data should be specified. Additionally, regarding the cross-validation techniques used, almost all studies described how they split the sample, yet only 20% specified how the training set was cross-validated. Another factor that hurt the quality scores of the articles was the model interpretability items; although interpretability of the ML models is often required to understand the drivers of hotel occupancy prediction, just over half of the articles included interpretability analyses. Finally, although the concept of bias is at the heart of both ML and research methods, neither the potential sources of bias nor the ways to reduce bias were addressed in any of the studies.
This study systematically reviewed fourteen articles that employed ML methodologies to forecast hotel occupancy. The PRISMA protocol for systematic reviews was particularly useful for focusing on this specific research niche, ensuring that only the most relevant studies were included and providing a structured framework for assessing the quality and rigour of each study (Moher et al., 2009; Page et al., 2021). The review yielded various significant conclusions. In terms of bibliometrics, we found that the overwhelming majority of authors lacked a hospitality background. Furthermore, we found that machine learning models generally outperformed the traditional forecasting models. We also found that many of the included papers had methodological gaps associated with the ML pipeline, especially surrounding cross-validation, hyperparameter tuning, and interpretability.
One key finding of this study was that hospitality scholars are underrepresented in this subsection of hotel forecasting research. Among all authors who participated across the 14 publications, only 20% held at least one degree in hospitality. While this result is not necessarily unusual given the advanced quantitative nature of ML and forecasting, it does raise two questions - first, whether the articles are properly understanding and addressing the needs of the hotel industry, and second, whether interdisciplinary teaching approaches and knowledge exchanges between hospitality and analytics could enrich hospitality education. Because few hospitality-specific scholars are involved in these studies, the publications may not be sufficiently attuned to the needs of the hospitality industry. Similarly, with more exposure to analytical tools and interdisciplinary perspectives, hospitality students would be more equipped to (a) advance scientific research in the field, and (b) work in a world that is increasingly reliant on data and quantitative decision-making, effectively pushing the hospitality industry forward in the midst of the fourth industrial revolution (Osei et al., 2020).
We also found that ML research in hotel occupancy forecasting almost exclusively used R and python. These tools are ideal for statistical analysis and ML, and they are both free, open-source, and flexible programming languages. This allows for greater transparency and accessibility when it comes to research, which are two important tenets of open science research practices. This aligns with the recent push in the field of hospitality for open science research practices (Capdevila-Torres et al., 2023; Font et al., 2024).
In general, we found that the ML models outperformed traditional forecasting models. However, this superiority is nuanced, as exhibited in the cases of Kozlovskis et al. (2023) and Ampountolas and Legg (2021), where traditional models outperformed ML models. This could be because ML model performance varies with hyperparameter tuning, data frequency and size, forecasting horizon, and the type of ML model used. For example, a poorly tuned XGBoost model on a small dataset may not have enough data to “learn” effectively, allowing for a simple linear regression model to pick up an underlying linear trend. Yet, if data does not exhibit a linear trend, the XGBoost model would likely outperform the OLS model, despite the lack of rigour in the model development process.
Another notable finding from the review is the absence of interpretability techniques in the articles. Consideration of the balance between prediction accuracy and interpretability is important, particularly for practitioners. A hotel manager deploying an ML model to predict hotel occupancy may benefit from accurate day-to-day operational predictions, but understanding the underlying drivers of these predictions could inform strategic decisions at the property and market levels. Therefore, the incorporation of interpretability features such as feature importance, prediction intervals, and specialised interpretative frameworks reflects a growing trend towards not only enhancing the accuracy of predictive models but also making their results more accessible and trustworthy for stakeholders in the hospitality industry. This is critical, as it allows hotel operators to (1) understand the underlying driving factors of hotel demand without sacrificing predictive accuracy, (2) increase model transparency to avoid discriminatory practices, and (3) create auditable systems for regulatory compliance (Czerwinska, 2022; Gerlings et al., 2020; Wulff & Finnestrand, 2023).
While analysing the included articles, a lack of methodological rigour and consistency throughout the ML pipeline emerged, particularly in hyperparameter tuning, crossvalidation, accuracy metrics, and forecasting horizons. Hyperparameter tuning and cross-validation are key to model development, as they enable researchers to optimise prediction accuracy while preventing overfitting. Yet, there is a lack of consistency and rigour in the methodologies used. Similarly, the accuracy metrics employed are inconsistent and outdated; most articles used MAPE to measure prediction accuracy, which has been shown to exhibit asymmetry (Schwartz et al., 2023). Additionally, there is no consistency in the accuracy metrics used, making a metaanalysis challenging, if not impossible, to conduct. Lastly, the forecasting horizons used in the studies were inconsistent, making it hard to get an accurate or comparable picture of how forecasts vary across horizons. These are important for hotel revenue managers, as (1) cross-validation techniques ensure the generalizability of the model to future data, (2) accuracy metrics serve as the foundation for forecast evaluation, and (3) the forecasting horizon defines the use case of the forecast (operational vs. strategic).
To address these points, we suggest using a checklist for building ML models, such as our adapted version of the CLAIM checklist, which was used to assess model quality. The introduction of a checklist for ML studies will ensure both methodological rigour and consistency, thereby enabling better research papers, more rigorous comparisons between studies, and clearer directions for academic and industry audiences.
This study is not without its limitations. Due to the targeted nature of a systematic review, our search yielded a sample size of 14 articles. While this allowed for the research team to pinpoint a specific vein of research, future research may want to increase the scope of the search to include more articles that deploy ML methodologies for other forecasting tasks. Conversely, future reviews could examine hotel demand-forecasting niches that remain unexplored, such as cancellation forecasting or booking-curve analysis. It would be interesting to see if these areas of demand forecasting have similar methodological shortcomings.
Additionally, to evaluate the quality of ML papers, we adapted the CLAIM checklist, previously used to assess ML studies in medical imaging. Although the checklist was relatively comprehensive, there may be some gaps that need to be addressed when applied specifically to demand forecasting. Consequently, future research could adopt the adapted version of the CLAIM checklist from this study and formally validate or redevelop it using a more rigorous methodology, such as the Delphi method. Notwithstanding, the field of hospitality would benefit from an official set of guidelines to ensure the quality of hospitality forecasting papers.
This study critically reviewed fourteen articles that employed ML methodologies to forecast hotel occupancy. The review yielded various significant conclusions. In terms of bibliometrics, we found that the overwhelming majority of authors lacked a hospitality background and that authors based at Asian institutions conducted most of the studies. We also found that many of the included papers had methodological gaps in the ML pipeline, particularly regarding cross-validation, hyperparameter tuning, and interpretability. In response to these limitations, we propose a quality assessment checklist that could be used to develop machine learning models for hospitality forecasting rigorously.