
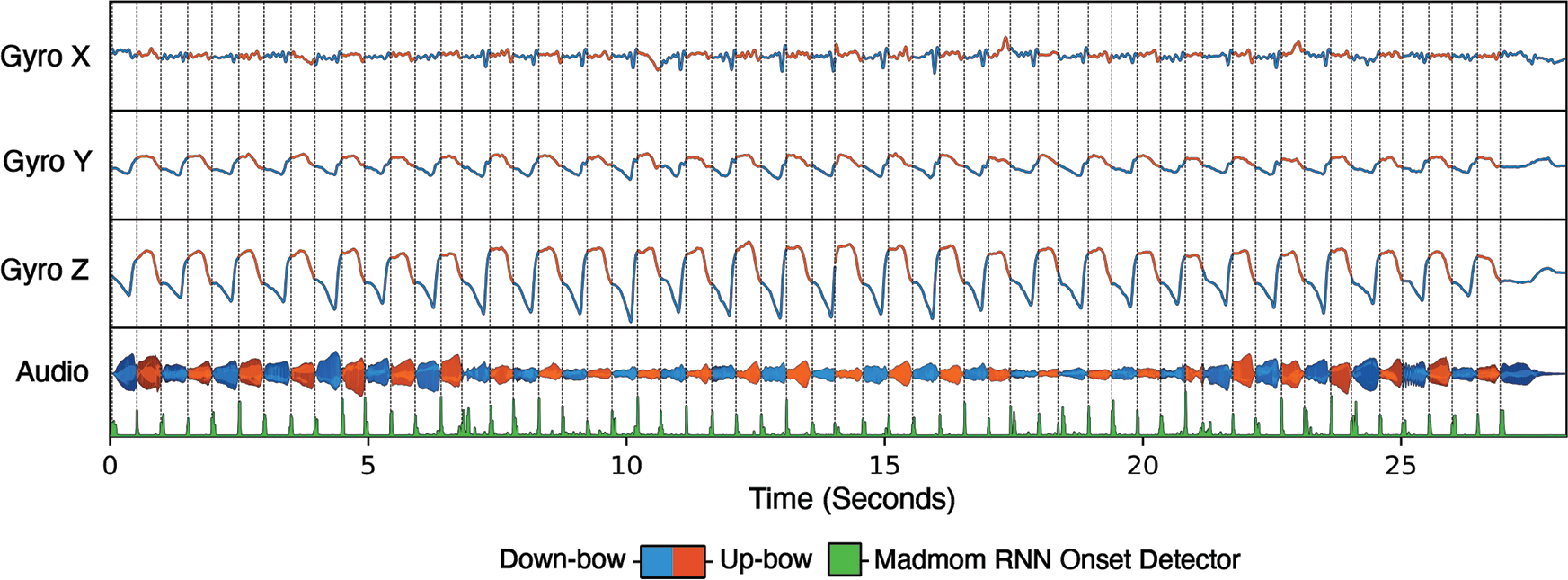
Figure 1
A Synchronous Inertial Measurement Unit–Audio dataset recording, with vertical lines denoting note onsets peak‑picked from an onset detection function calculated through use of the Madmom1 audio signal–processing library.
Table 1
Participant Recognition Network Parameters.
| Layer | Parameter | MLP | GRU | LSTM | CNN |
|---|---|---|---|---|---|
| A | Units | 128 | – | – | – |
| Activation | ReLU | – | – | – | |
| B | Units/Filters* | 128 | 128 | 128 | 50* |
| 128 | 88 | 88 | 50* | ||
| Kernel Size | – | – | – | 5 | |
| Activation | ReLU | ReLU | ReLU | ReLU | |
| C | Units | 88 | – | – | – |
| Activation | ReLU | – | – | – | |
| D | N/A | – | – | – | – |
| E | Units | 64 | – | – | – |
| F | Units | N Classes | – | – | – |
| Activation | Softmax | – | – | – |
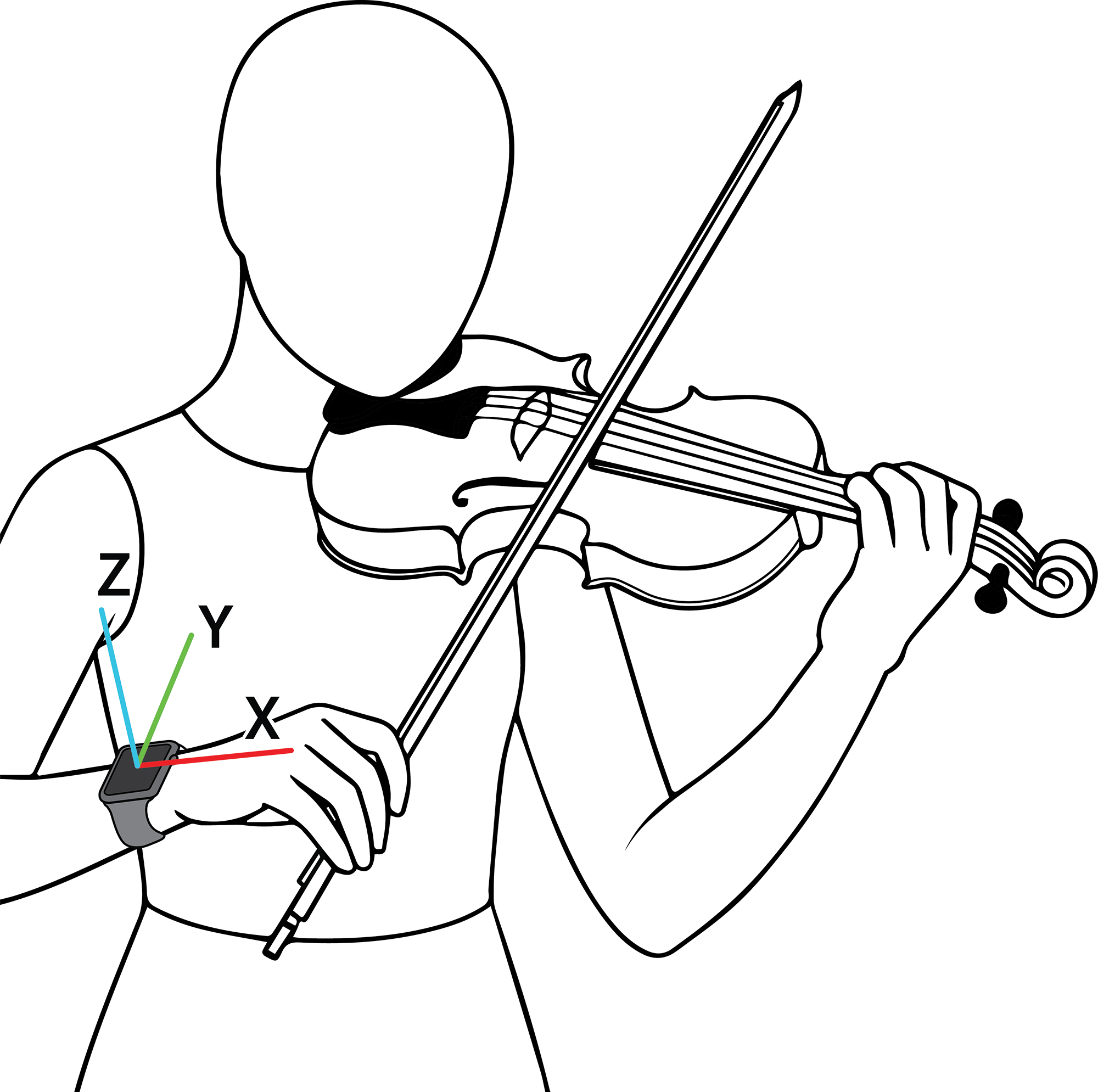
Figure 2
Apple Watch rotational axes as relative to the device.

Figure 3
Conventional deep neural network used in unimodal classification implementations, comprising an input layer (A), two variable layers (B), a dense layer (E) and an output layer (F).
Table 2
Participant recognition classification accuracy metrics, by network architecture and input data type.
| Input Data Type | Network Architecture | Participant Recognition | |||
|---|---|---|---|---|---|
| Acc (%) | AUC | F‑Score | |||
| Audio | MLP | 76.38 | 0.948 | 0.765 | |
| ” | LSTM | 82.43 | 0.967 | 0.828 | |
| ” | CNN1D | 80.75 | 0.964 | 0.812 | |
| ” | GRU | 79.39 | 0.957 | 0.796 | |
| IMU | MLP | 94.41 | 0.991 | 0.947 | |
| ” | LSTM | 96.43 | 0.996 | 0.965 | |
| ” | CNN1D | 96.00 | 0.994 | 0.961 | |
| ” | GRU | 91.83 | 0.989 | 0.918 | |
| Audio† | MLP† | MLP | 94.66 | 0.993 | 0.950 |
| + | LSTM† | LSTM | 93.85 | 0.988 | 0.938 |
| IMU | CNN1D† | CNN1D | 94.20 | 0.986 | 0.942 |
| ” | GRU† | GRU | 95.59 | 0.995 | 0.956 |
| ” | MLP† | CNN1D | 94.08 | 0.992 | 0.942 |
| ” | CNN1D† | MLP | 93.68 | 0.992 | 0.937 |
| ” | LSTM† | CNN1D | 93.79 | 0.987 | 0.936 |
| ” | CNN1D† | LSTM | 91.72 | 0.979 | 0.911 |
[i] †denotes corresponding subnetwork modality.
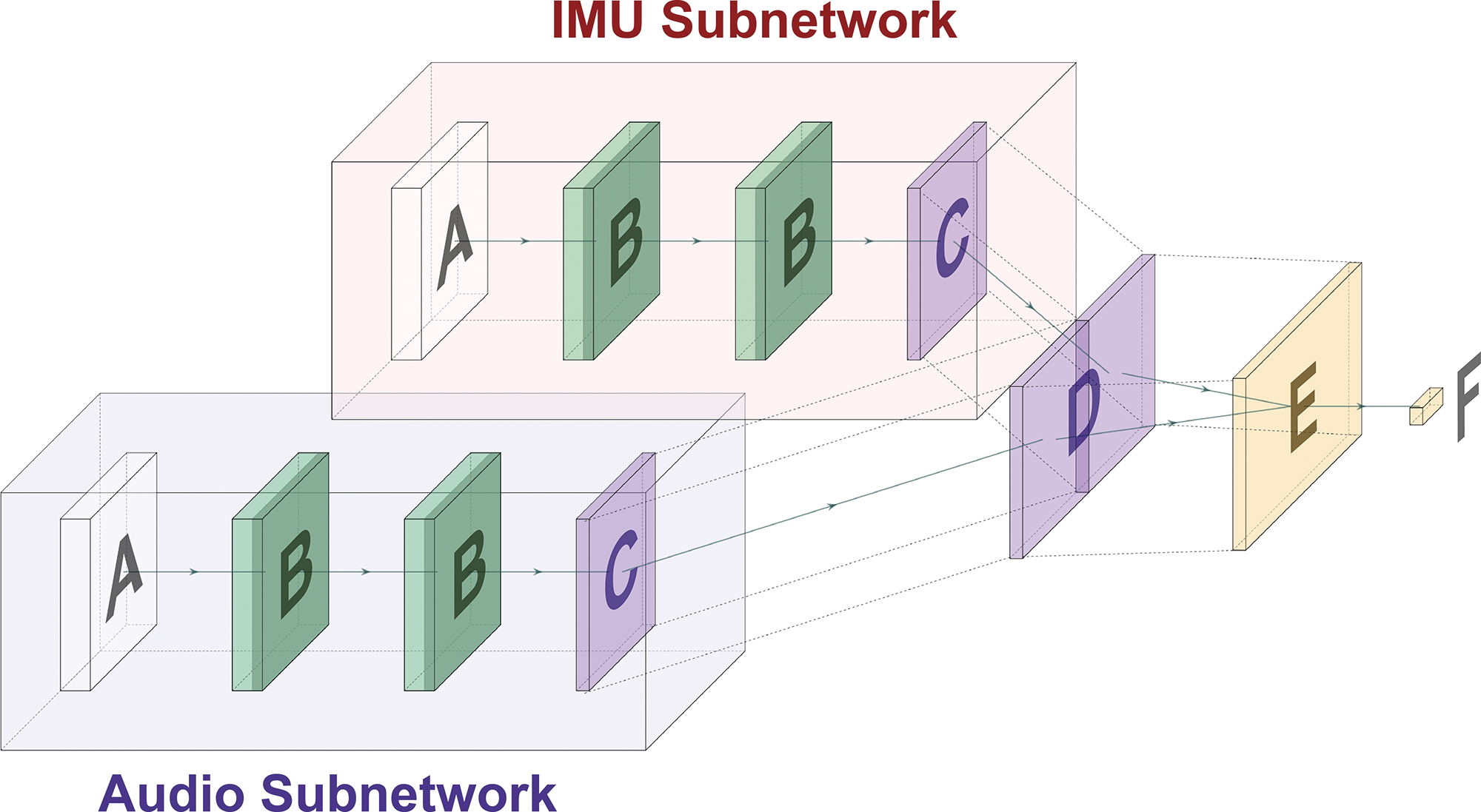
Figure 4
Multi‑input deep neural network used in multimodal classification implementations, comprising two input layers (A), four variable layers (B), two flattened layers (C), a concatenation layer (D), a dense layer (E) and an output layer (F).
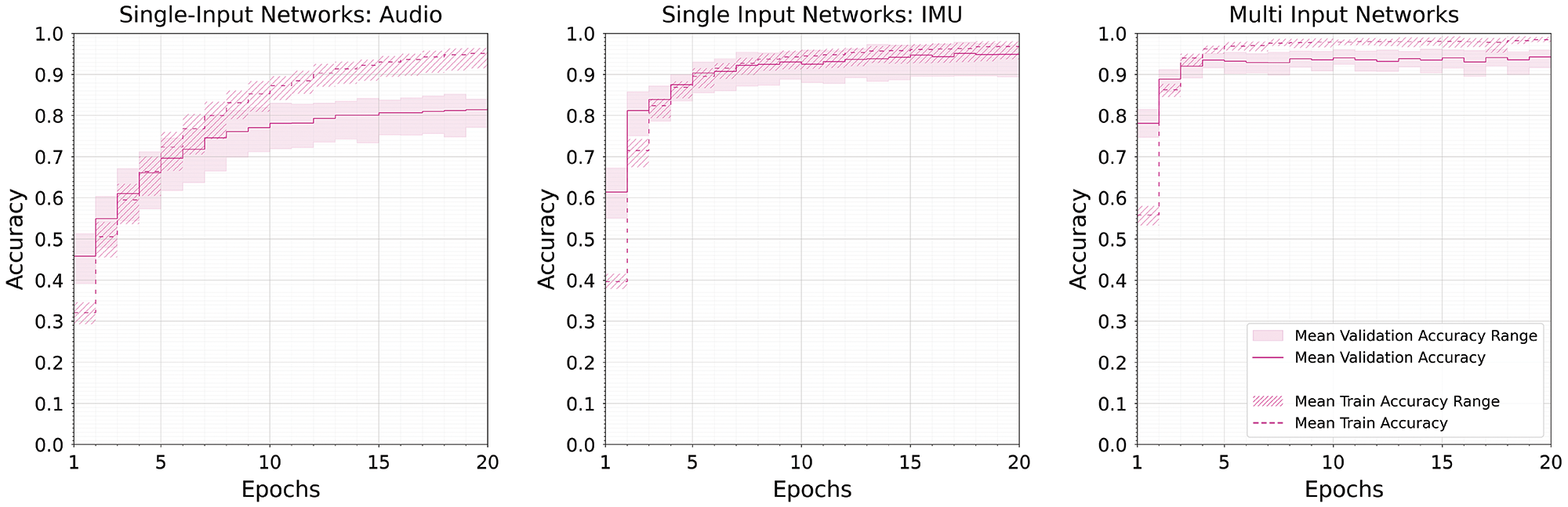
Figure 5
Participant train/validation accuracies per fold, by epoch, averaged across networks by datatype.
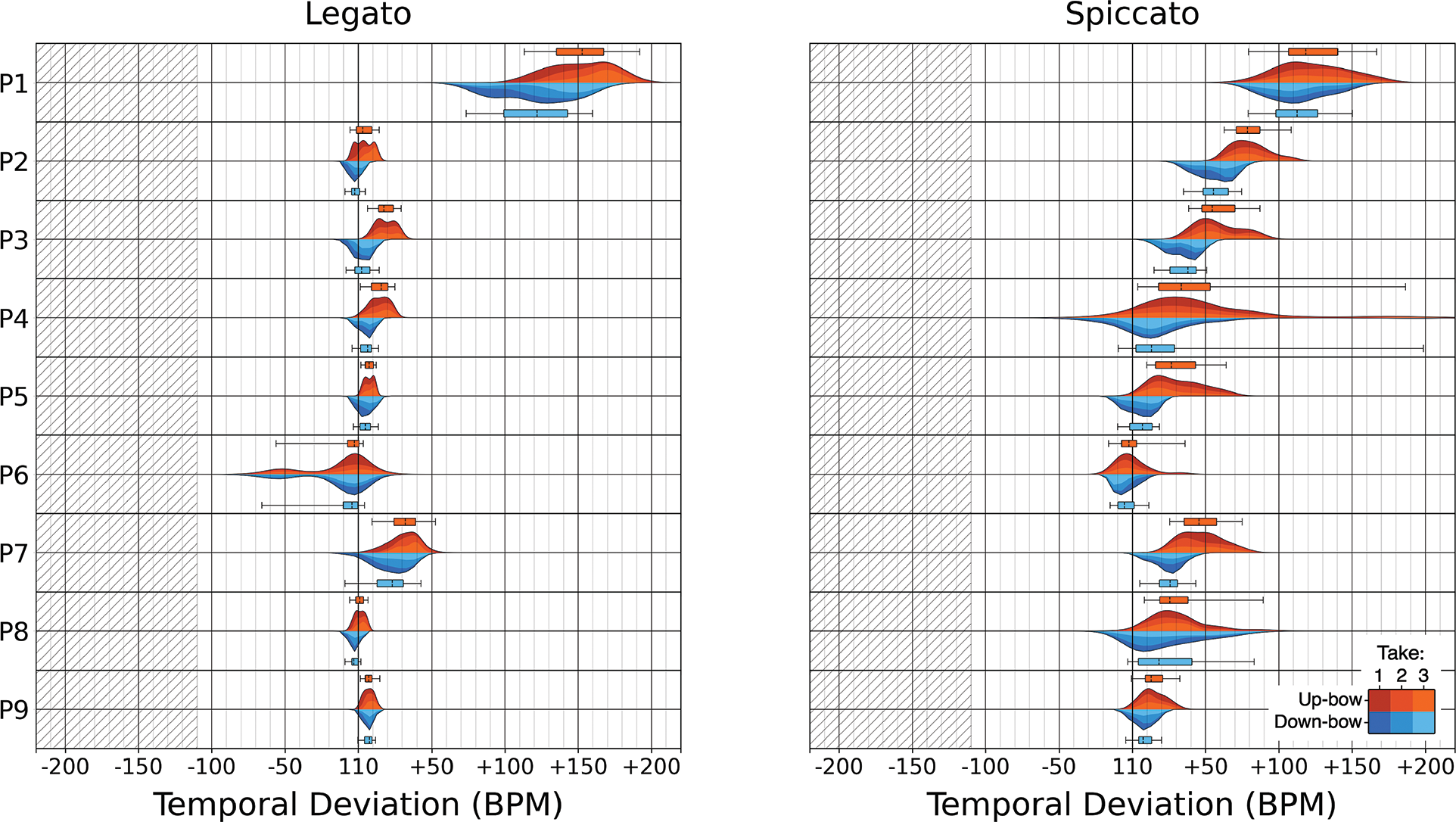
Figure 6
Distribution of participants’ G Major scale individual note tempi, by articulation.
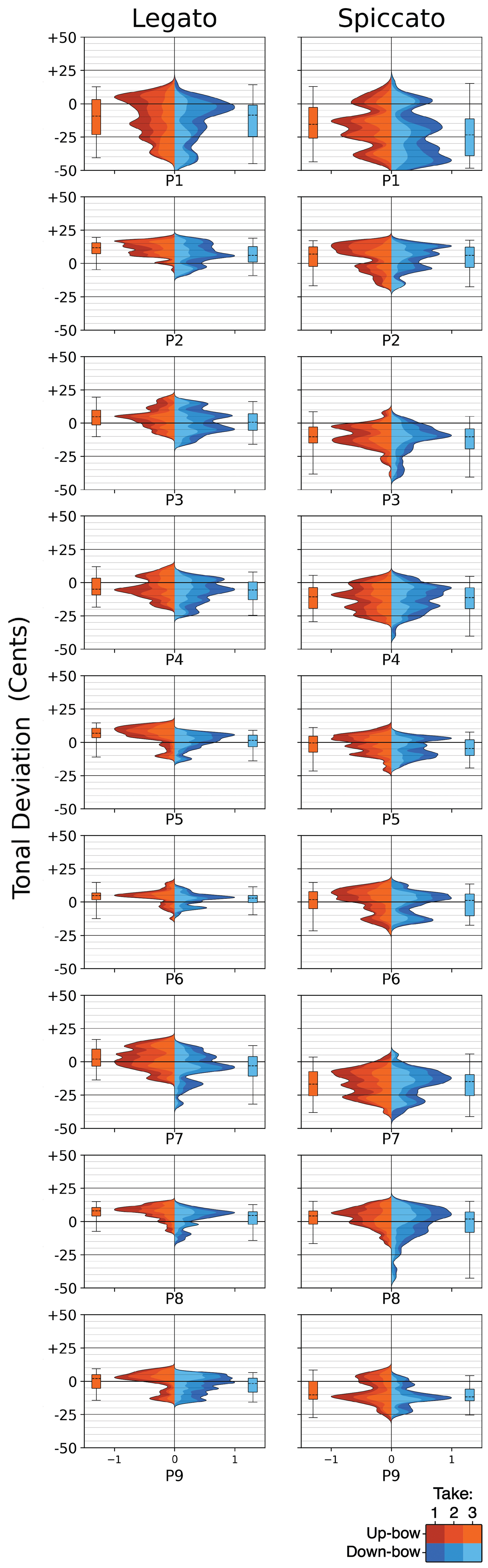
Figure 7
G Major scale tonal distributions per participant, by articulation.
Table 3
Tonal and temporal deviation descriptive statistics, by bow articulation and direction.
| Tonal Deviation (cents) | Temporal Deviation (BPM) | ||||||
|---|---|---|---|---|---|---|---|
| Bow Condition | Down | Up | Both | Down | Up | Both | |
| Legato | 0.48 | 4.40 | 2.43 | 8.97 | 15.90 | 12.42 | |
| Mean | Spiccato | −6.16 | −4.19 | −5.17 | 33.64 | 53.03 | 43.35 |
| Both | −3.04 | −0.19 | −1.62 | 22.07 | 35.72 | 28.89 | |
| Legato | 12.03 | 11.70 | 12.03 | 23.78 | 23.44 | 23.86 | |
| Std. | Spiccato | 15.03 | 14.95 | 15.20 | 52.50 | 57.08 | 55.68 |
| Both | 14.10 | 14.19 | 14.22 | 43.35 | 48.35 | 46.42 | |
| Legato | 144.8 | 136.6 | 144.5 | 565.3 | 549.3 | 569.1 | |
| Variance | Spiccato | 225.9 | 223.4 | 225.5 | 2756.2 | 3257.9 | 3100.5 |
| Both | 198.8 | 201.3 | 202.1 | 1879.6 | 2337.6 | 2154.6 | |
| Legato | 1.90 | 5.30 | 3.70 | 6.02 | 12.22 | 8.80 | |
| Median | Spiccato | −4.30 | −1.90 | −3.10 | 18.60 | 38.29 | 27.89 |
| Both | −1.40 | 2.00 | 0.60 | 9.28 | 19.64 | 14.21 | |
| Legato | 1.613 | 2.064 | 1.650 | 37.37 | 29.61 | 31.87 | |
| Kurtosis | Spiccato | 0.510 | 0.884 | 0.658 | 5.301 | 1.631 | 2.866 |
| Both | 1.080 | 1.471 | 1.199 | 10.41 | 4.743 | 6.755 | |
| Legato | −2.16 | −0.49 | −0.347 | 5.316 | 4.527 | 4.767 | |
| Skew | Spiccato | −0.50 | −.722 | −.608 | 2.305 | 1.431 | 1.777 |
| Both | −0.528 | −.770 | −.638 | 3.075 | 2.152 | 2.514 | |
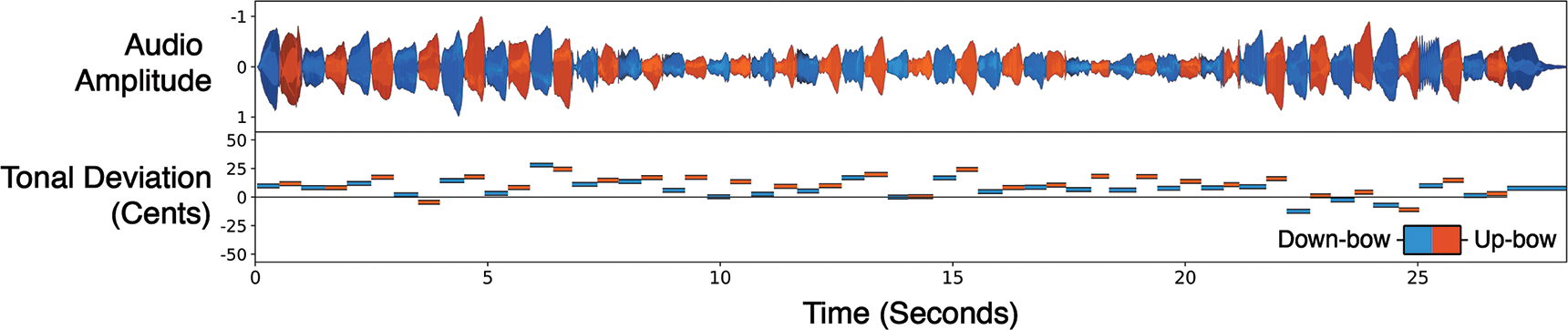
Figure 8
Note‑by‑note tunings, in cents, of a recorded D Major scale (Legato).
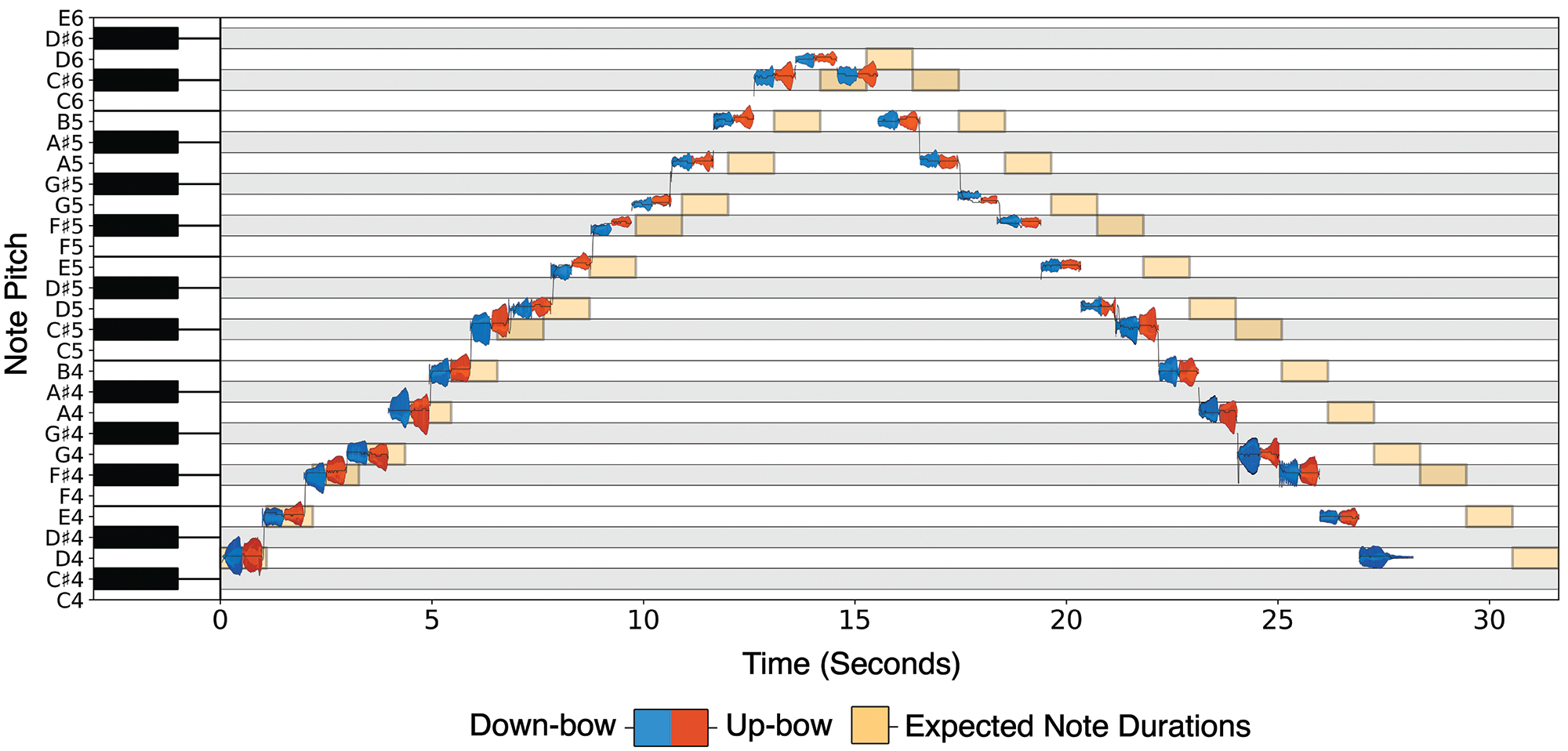
Figure 9
Piano roll graph depicting a recorded D Major scale (Legato).
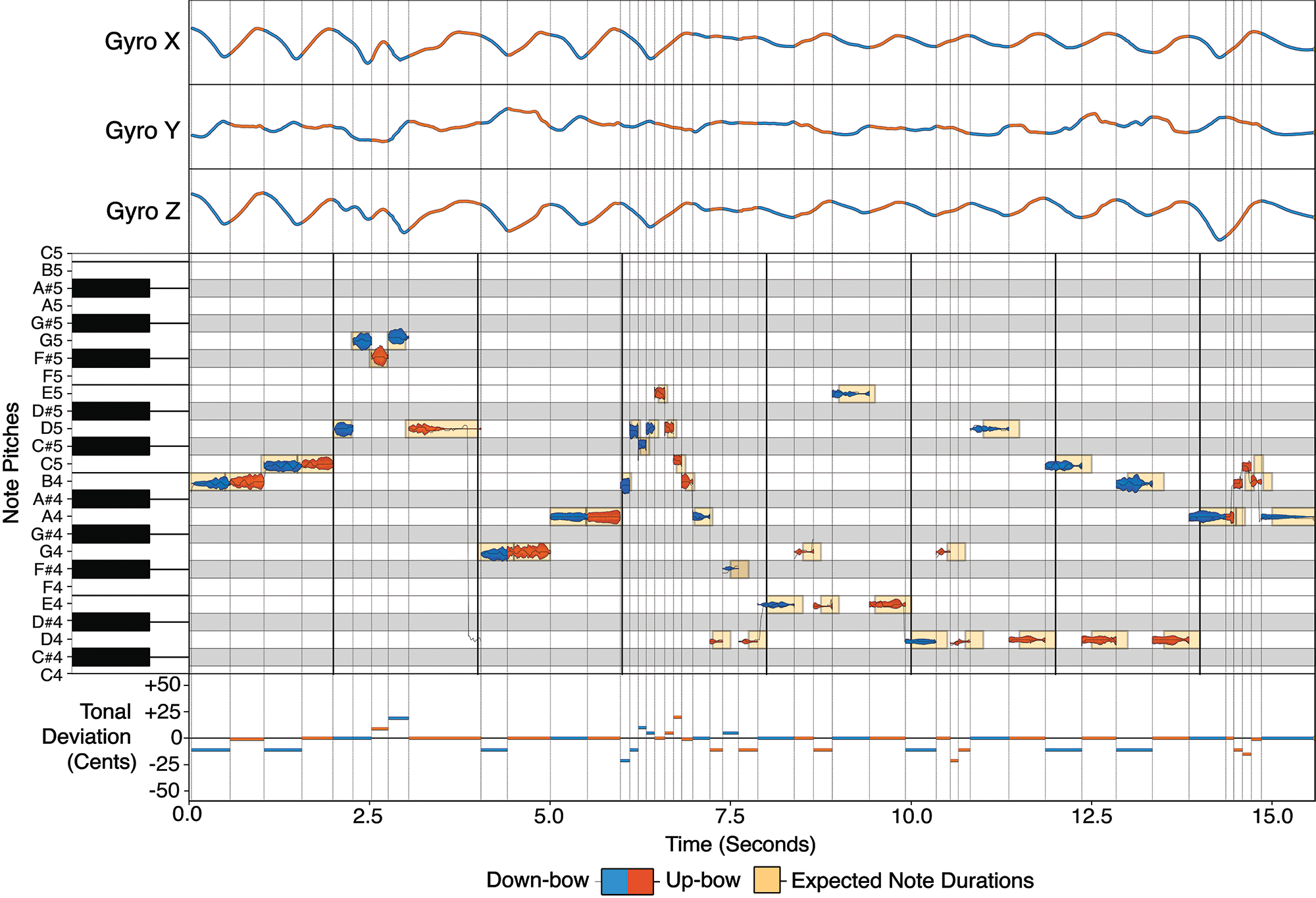
Figure 10
Piano roll graph depicting a multimodal recording of an excerpt from Gossec’s Gavotte, bars 27–34. Tempo: Allegretto (120 BPM).