
Table 1
Publicly available datasets designed for topics related to Chinese music in music technology to date.
| Dataset | Content | Task | Object |
|---|---|---|---|
| Corpus of Jingju (Caro Repetto and Serra, 2014) (2014) | Audio, editorial metadata, lyrics, and scores of Jingju | Melodic analysis | Jingju |
| SingingDatabase (Black et al., 2014) (2014) | Vocal recordings by professional, semi‑professional, and amateur singers in predominantly Chinese opera singing style | Singing voice analysis | Chinese opera |
| Unnamed (Hu and Yang, 2017) (2017) | Traditional Chinese music pieces in the spectrogram representation with information on performers and instruments | Latent space analysis | Chinese traditional music |
| GQ39 (Huang et al., 2020) (2020) | Audio recordings of prevalent Guqin solo compositions and corresponding event‑by‑event annotations | Playing technique detection, mode detection | Guqin |
| Unnamed (Nahar et al., 2020) (2020) | Musical features of Chinese, Malay, and Indian song fragments | Music classification | Chinese songs |
| JinYue Database (Shen et al., 2020) (2020) | Huqin music metadata, audio features, and annotations of emotion, scene, and imagery | Emotion, scene, and imagery recognition | Huqin |
| ChMusic (Gong et al., 2021) (2021) | Traditional Chinese music excerpts performed by 11 traditional Chinese musical instruments | Instrument recognition | Chinese instruments |
| Traditional Chinese Opera (Zhang et al., 2021) (2021) | Songs from the 14 most popular types of Chinese opera with annotations of music, song, and speech | Genre recognition | Chinese opera |
| CBFdataset (Wang et al., 2022a) (2022) | Monophonic recordings of classic Chinese bamboo flute pieces and isolated playing techniques with annotations | Playing technique detection | Zhudi |
| CCOM‑HuQin (Zhang et al., 2023) (2023) | Audiovisual recordings of 11,992 individual playing technique clips and 57 annotated musical compositions featuring classical excerpts | Playing technique detection | Huqin |
Table 2
All the datasets included in the CCMusic database (references following the name of each published dataset).
| Dataset | Main Task | Main Contents |
|---|---|---|
| Chinese Traditional Instrument Sound (Liang et al., 2019) | Instrument recognition | Audio of Chinese instruments |
| GZ IsoTech (Li et al., 2022) | Playing technique classification | Audio with playing technique annotation |
| Guzheng Tech99 (Li et al., 2023) | Playing technique detection | Audio with playing technique annotation |
| Erhu Playing Technique (Wang et al., 2019) | Playing technique classification | Audio with playing technique annotation |
| Chinese National Pentatonic Modes (Wang et al., 2022b) | Mode classification | Audio with Chinese pentatonic mode annotation |
| Bel Canto & Chinese Folk Singing (authors’ own creation) | Singing style classification | Audio with singing style annotation |
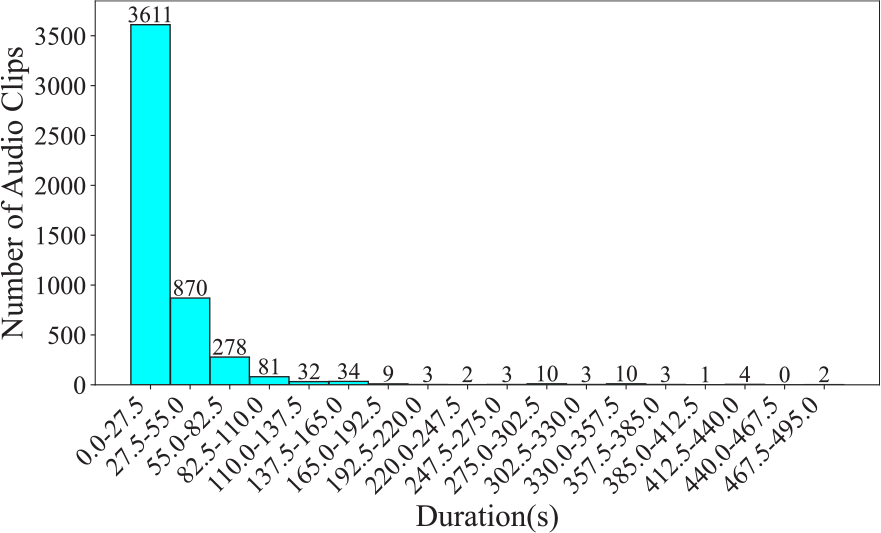
Figure 1
Number of audio clips across various durations in the CTIS dataset, segmented at 27.5 seconds.
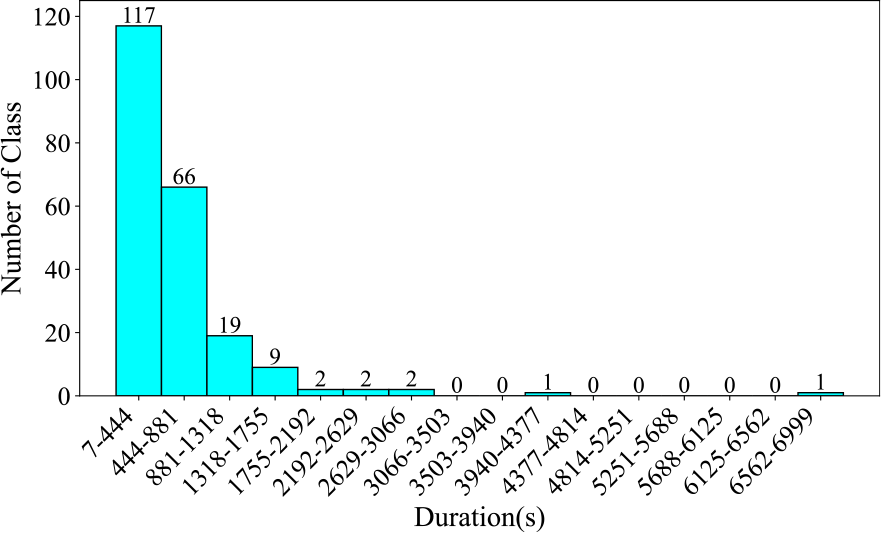
Figure 2
Number of instrument categories across various durations in the CTIS dataset, segmented at 437 seconds.
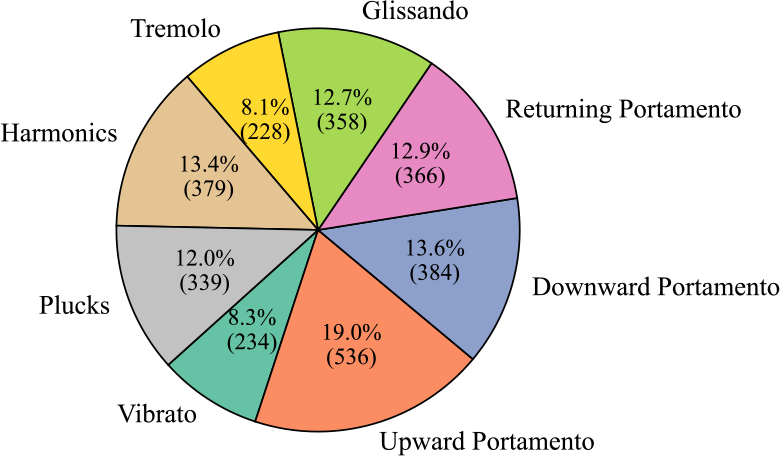
Figure 3
Clip number and proportion of each category in the GZ IsoTech dataset.
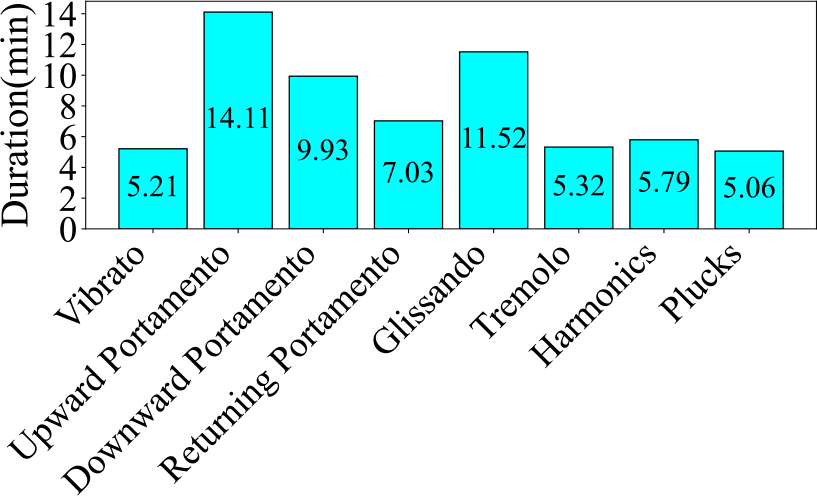
Figure 4
Audio duration of each category in the GZ IsoTech dataset.
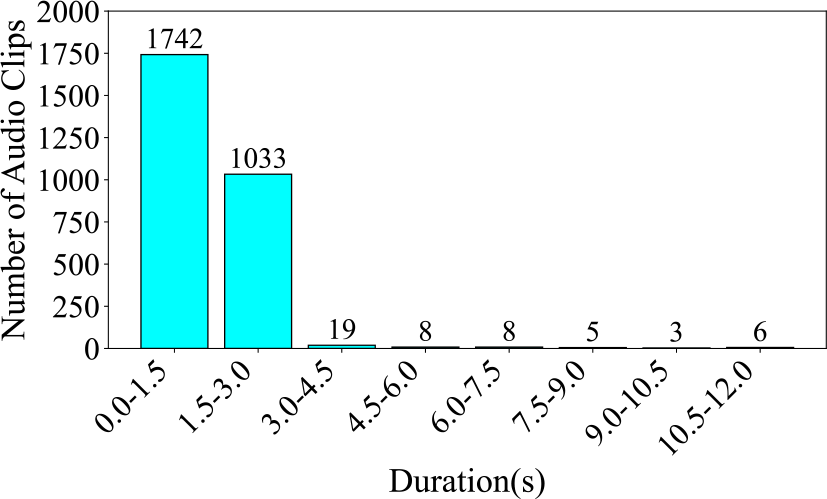
Figure 5
Number of audio clips across various durations in the GZ IsoTech dataset, segmented at 1.5 seconds.
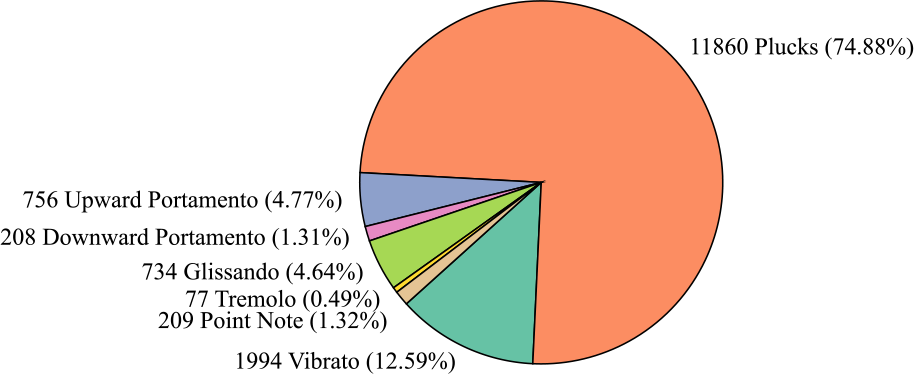
Figure 6
Clip number and proportion of each category in the Guzheng Tech99 dataset.
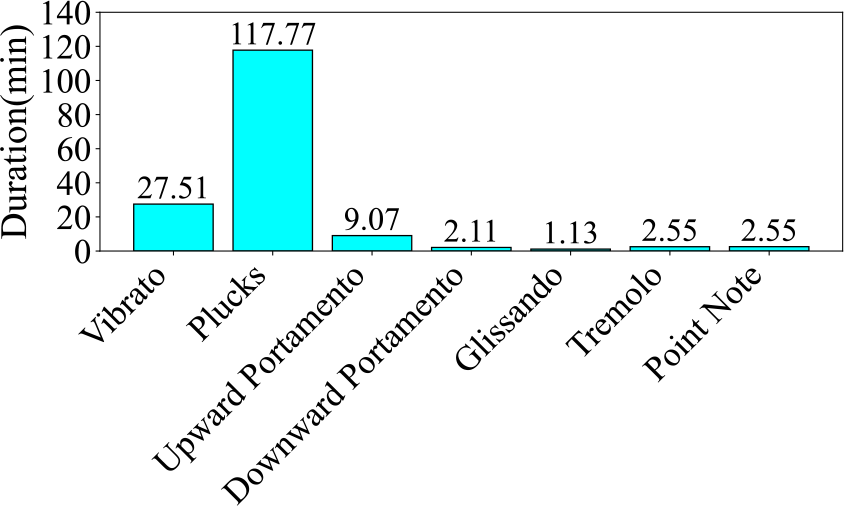
Figure 7
Audio duration of each category in the Guzheng Tech99 dataset.
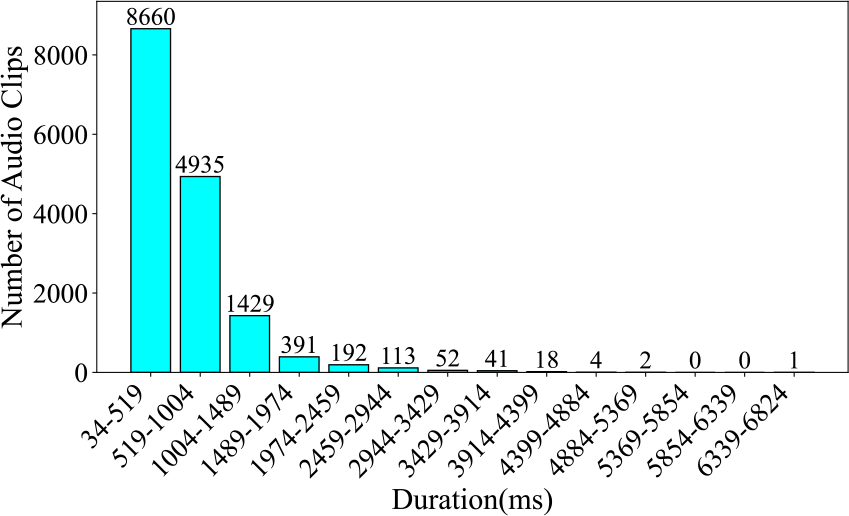
Figure 8
Number of audio clips across various durations in the Guzheng Tech99 dataset, segmented at 0.485 seconds.
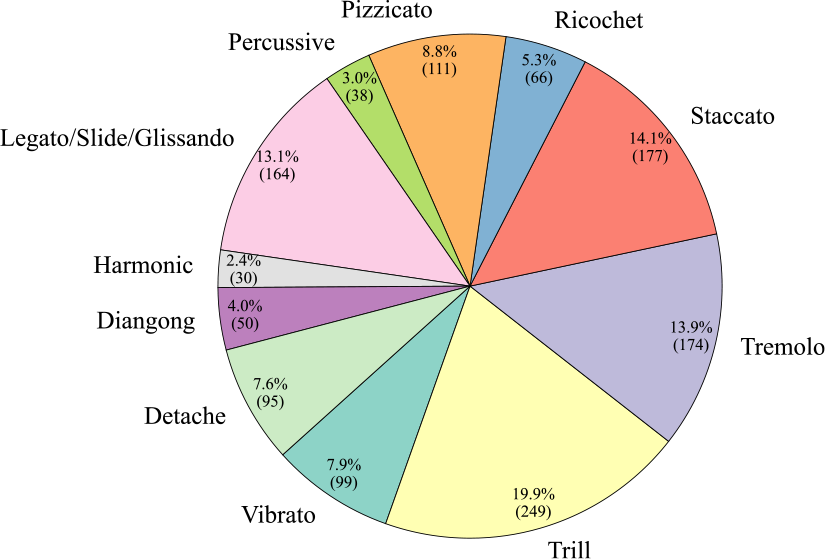
Figure 9
Clip number and proportion of each category in the ErhuPT dataset.
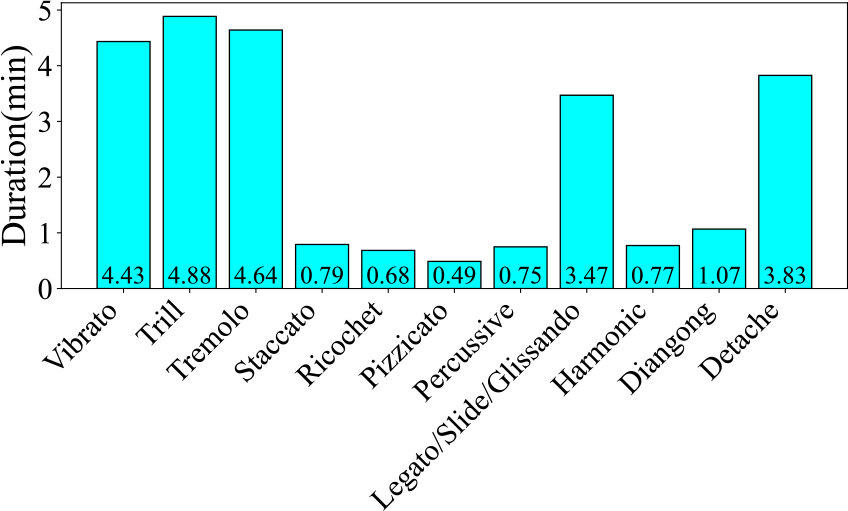
Figure 10
Audio duration of each category in the ErhuPT dataset.
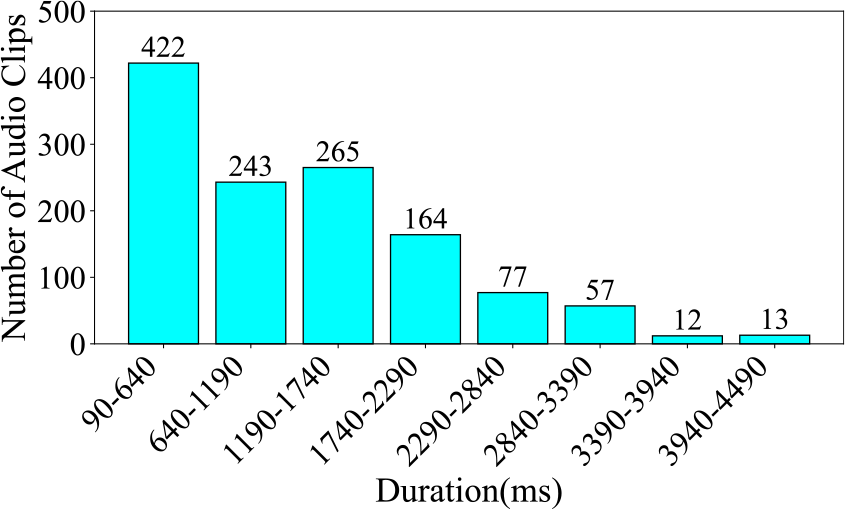
Figure 11
Number of audio clips across various durations in the ErhuPT dataset, segmented at 550 milliseconds.
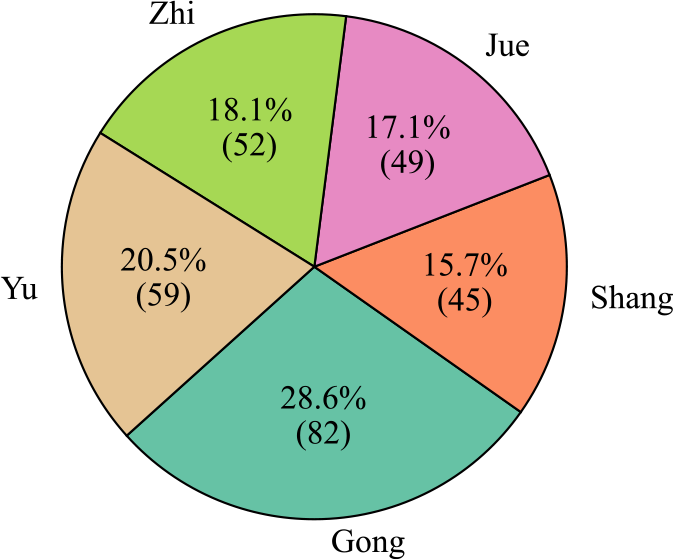
Figure 12
Clip number and proportion of each category in the CNPM dataset.
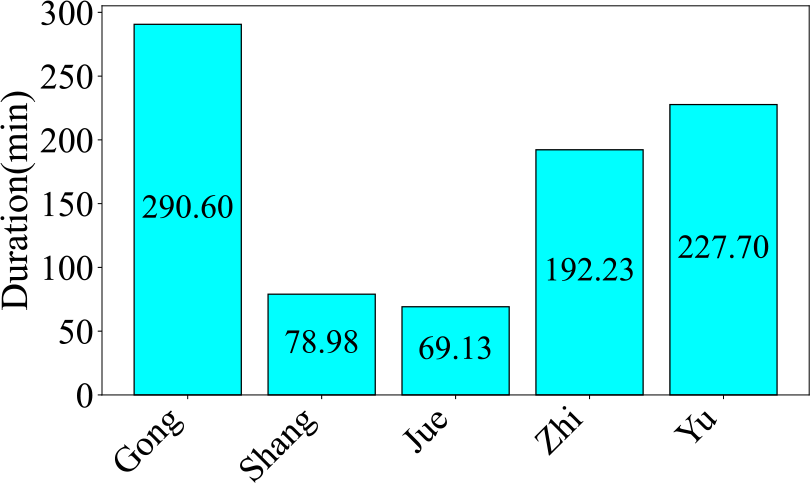
Figure 13
Audio duration of each category in the CNPM dataset.
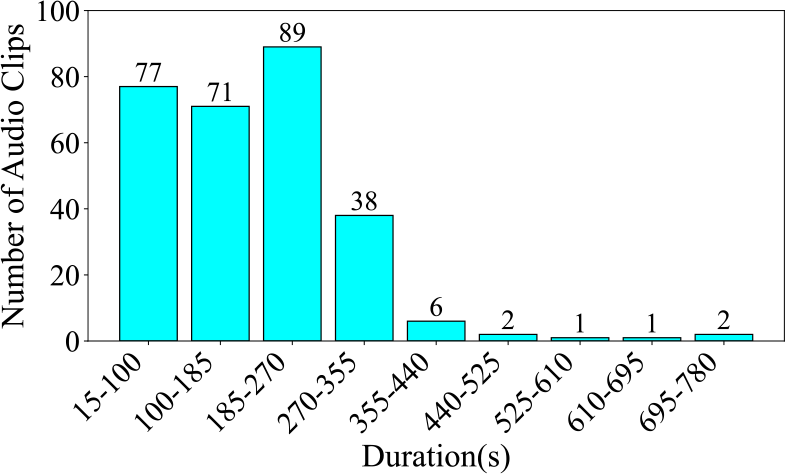
Figure 14
Number of audio clips across various durations in the CNPM dataset, segmented at 85 seconds.
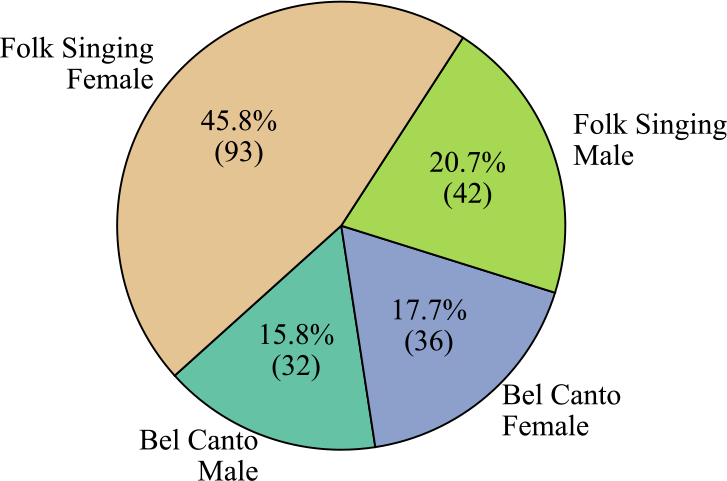
Figure 15
The clip number and proportion of each category in the Bel Canto & Chinese Folk Singing dataset.
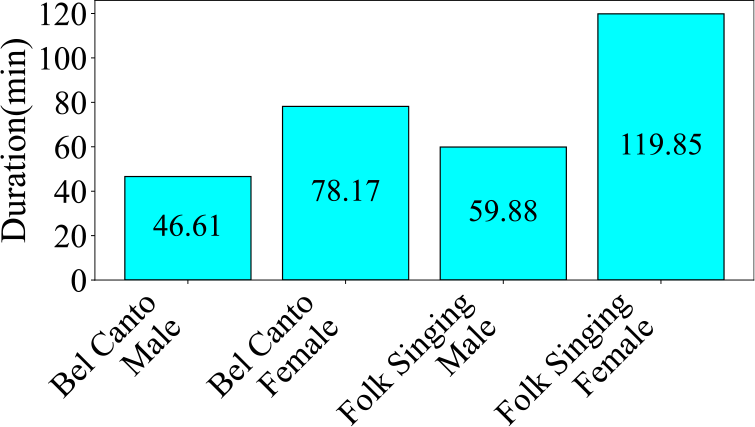
Figure 16
Audio duration of each category in the Bel Canto & Chinese Folk Singing dataset.
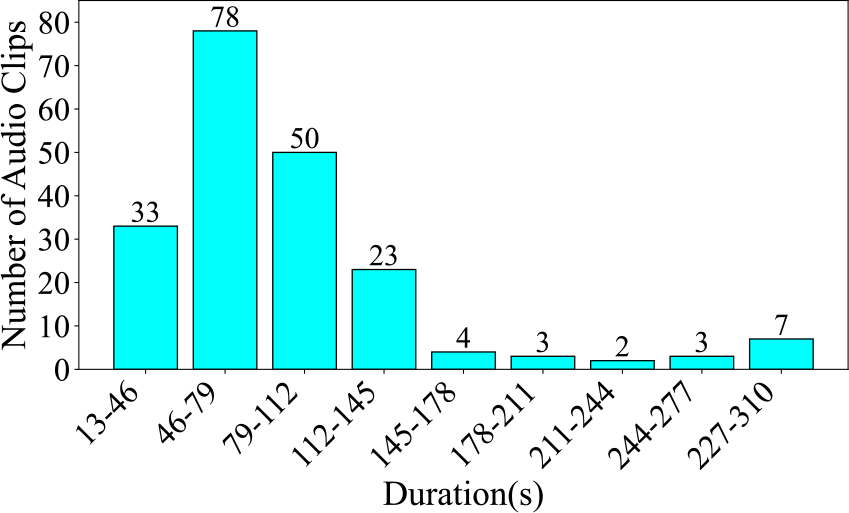
Figure 17
Number of audio clips across various durations in the Bel Canto & Chinese Folk Singing dataset, segmented at 33 seconds.
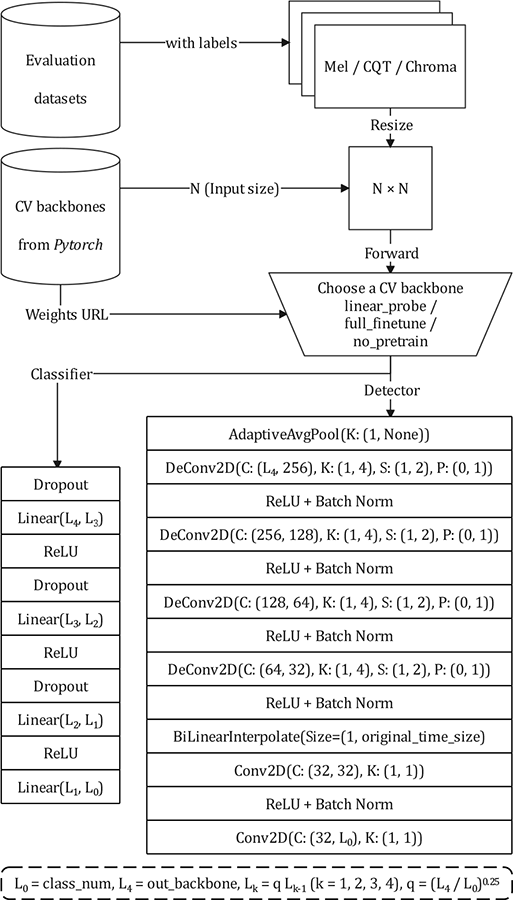
Figure 18
The evaluation framework that supports classification and detection tasks.
Table 3
F1‑scores of seven models on the CTIS dataset. The best results of the transformer group and the CNN group are indicated in bold.
| Backbone | Mel | CQT | Chroma |
|---|---|---|---|
| ViT‑L‑32 | 0.936 | 0.921 | 0.845 |
| Swin‑T | 0.956 | 0.940 | 0.759 |
| RegNet‑Y‑32GF | 0.973 | 0.980 | 0.848 |
| VGG19‑BN | 0.966 | 0.965 | 0.852 |
| AlexNet | 0.936 | 0.921 | 0.661 |
| ResNet101 | 0.953 | 0.949 | 0.782 |
| Inception‑V3 | 0.860 | 0.855 | 0.664 |
| Average | 0.940 | 0.933 | 0.773 |
Table 4
F1‑scores of seven models on the GZ IsoTech dataset. The best scores of the transformer group and the CNN group are indicated in bold.
| Backbone | Mel | CQT | Chroma |
|---|---|---|---|
| ViT‑L‑16 | 0.855 | 0.824 | 0.770 |
| MaxVit‑T | 0.763 | 0.776 | 0.642 |
| ResNeXt101‑64X4D | 0.713 | 0.765 | 0.639 |
| ResNet101 | 0.731 | 0.798 | 0.719 |
| RegNet‑Y‑8GF | 0.804 | 0.807 | 0.716 |
| ShuffleNet‑V2‑X2.0 | 0.702 | 0.799 | 0.665 |
| MobileNet‑V3‑Large | 0.806 | 0.798 | 0.657 |
| Average | 0.768 | 0.795 | 0.687 |
Table 5
F1‑scores of seven models on the Guzheng Tech99 dataset. The best scores of the transformer group and the CNN group are indicated in bold.
| Backbone | Mel | CQT | Chroma |
|---|---|---|---|
| ViT‑B‑16 | 0.705 | 0.518 | 0.508 |
| Swin‑T | 0.849 | 0.783 | 0.766 |
| VGG19 | 0.862 | 0.799 | 0.665 |
| EfficientNet‑V2‑L | 0.783 | 0.812 | 0.697 |
| ConvNeXt‑B | 0.849 | 0.849 | 0.805 |
| ResNet101 | 0.638 | 0.830 | 0.707 |
| SqueezeNet1.1 | 0.831 | 0.814 | 0.780 |
| Average | 0.788 | 0.772 | 0.704 |
Table 6
F1‑scores of seven models on the ErhuPT dataset. The best scores of the transformer group and the CNN group are indicated in bold.
| Backbone | Mel | CQT | Chroma |
|---|---|---|---|
| Swin‑S | 0.978 | 0.940 | 0.903 |
| Swin‑T | 0.994 | 0.958 | 0.957 |
| AlexNet | 0.960 | 0.970 | 0.933 |
| ConvNeXt‑T | 0.994 | 0.993 | 0.954 |
| ShuffleNet‑V2‑X2.0 | 0.990 | 0.923 | 0.887 |
| GoogleNet | 0.986 | 0.981 | 0.908 |
| SqueezeNet1.1 | 0.932 | 0.939 | 0.875 |
| Average | 0.976 | 0.958 | 0.917 |
Table 7
F1‑scores of seven models on CNPM dataset. The best scores of the transformer group and the CNN group are indicated in bold.
| Backbone | Mel | CQT | Chroma |
|---|---|---|---|
| ViT‑L‑32 | 0.680 | 0.769 | 0.399 |
| ViT‑L‑16 | 0.823 | 0.859 | 0.549 |
| VGG11‑BN | 0.807 | 0.843 | 0.609 |
| RegNet‑Y‑16GF | 0.590 | 0.832 | 0.535 |
| Wide‑ResNet50‑2 | 0.694 | 0.757 | 0.531 |
| AlexNet | 0.742 | 0.744 | 0.542 |
| ShuffleNet‑V2‑X2.0 | 0.473 | 0.720 | 0.266 |
| Average | 0.687 | 0.789 | 0.490 |
Table 8
F1‑scores of seven models on the Bel Canto & Chinese Folk Singing dataset. The best scores of the transformer group and the CNN group are indicated in bold.
| Backbone | Mel | CQT | Chroma |
|---|---|---|---|
| Swin‑S | 0.928 | 0.936 | 0.787 |
| Swin‑T | 0.906 | 0.863 | 0.731 |
| AlexNet | 0.919 | 0.920 | 0.746 |
| ConvNeXt‑T | 0.895 | 0.925 | 0.714 |
| GoogleNet | 0.948 | 0.921 | 0.739 |
| MNASNet1.3 | 0.931 | 0.931 | 0.765 |
| SqueezeNet1.1 | 0.923 | 0.914 | 0.685 |
| Average | 0.921 | 0.916 | 0.738 |