
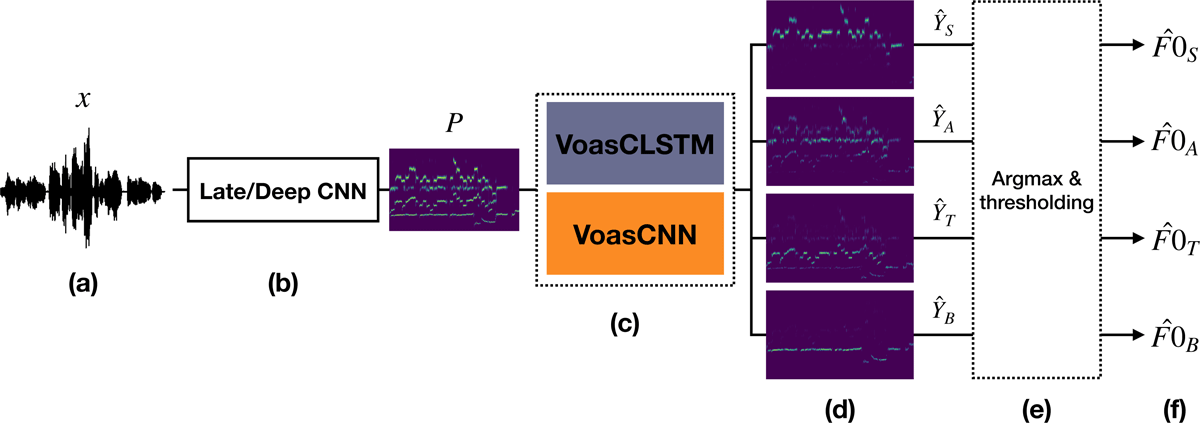
Figure 1
Overview of the proposed system for multi-pitch estimation and voice assignment based on pitch salience representations. (a) Input audio SATB mixture. (b) Multi-pitch salience estimation using the Late/Deep CNN, which produces the salience representation P. (c) Voice assignment step with one of the two proposed architectures. (d) Four output salience representations, one for each voice in the mixture, output by the VA models. (e) Post-processing step consisting of finding the maximum salience bin in and thresholding. (f) Output F0 trajectories for each singer.
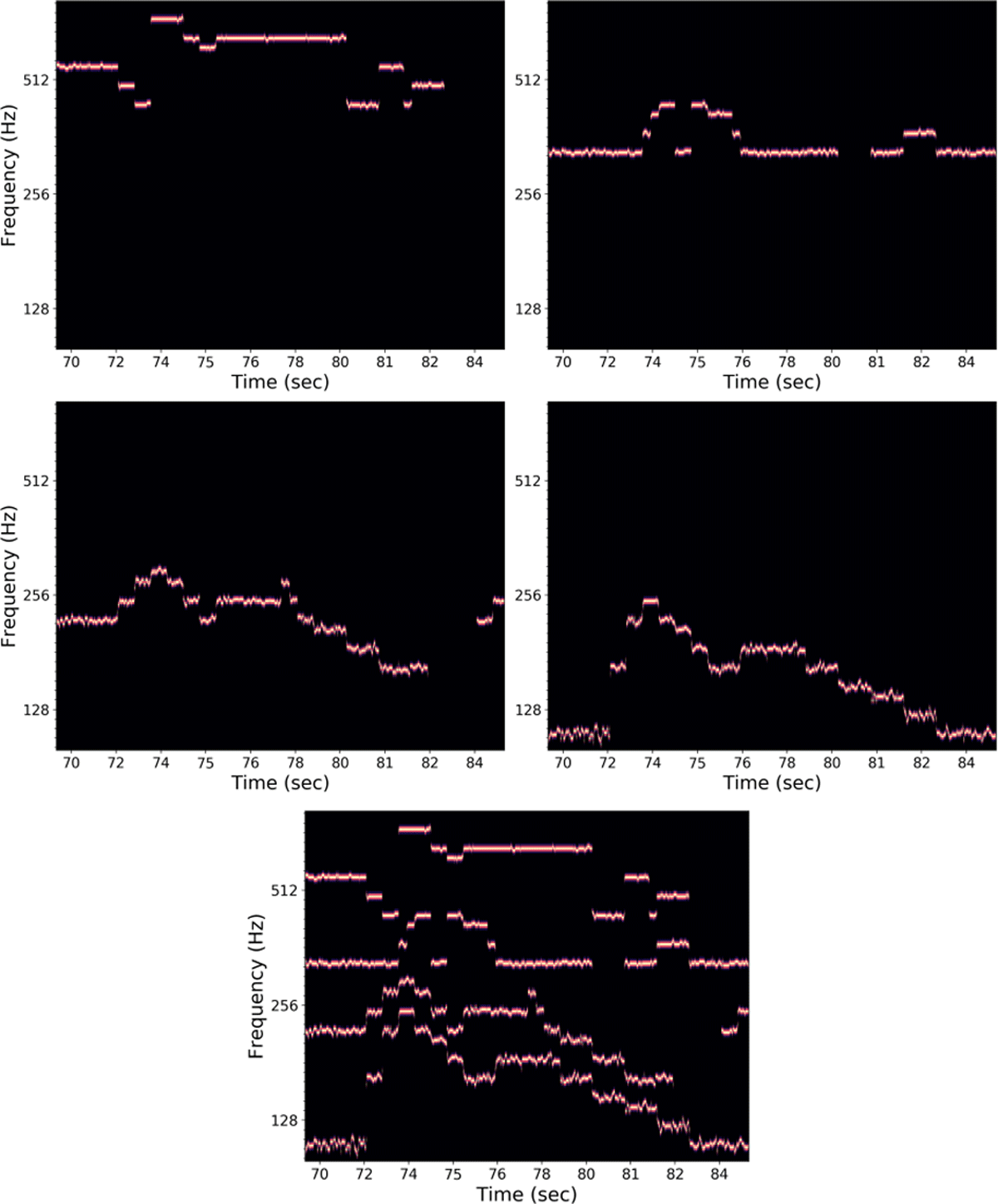
Figure 2
Example input/output data from SSCS dataset. The first four panes show an excerpt of each synthetic Yv, and the bottom pane displays the input mixture, P.
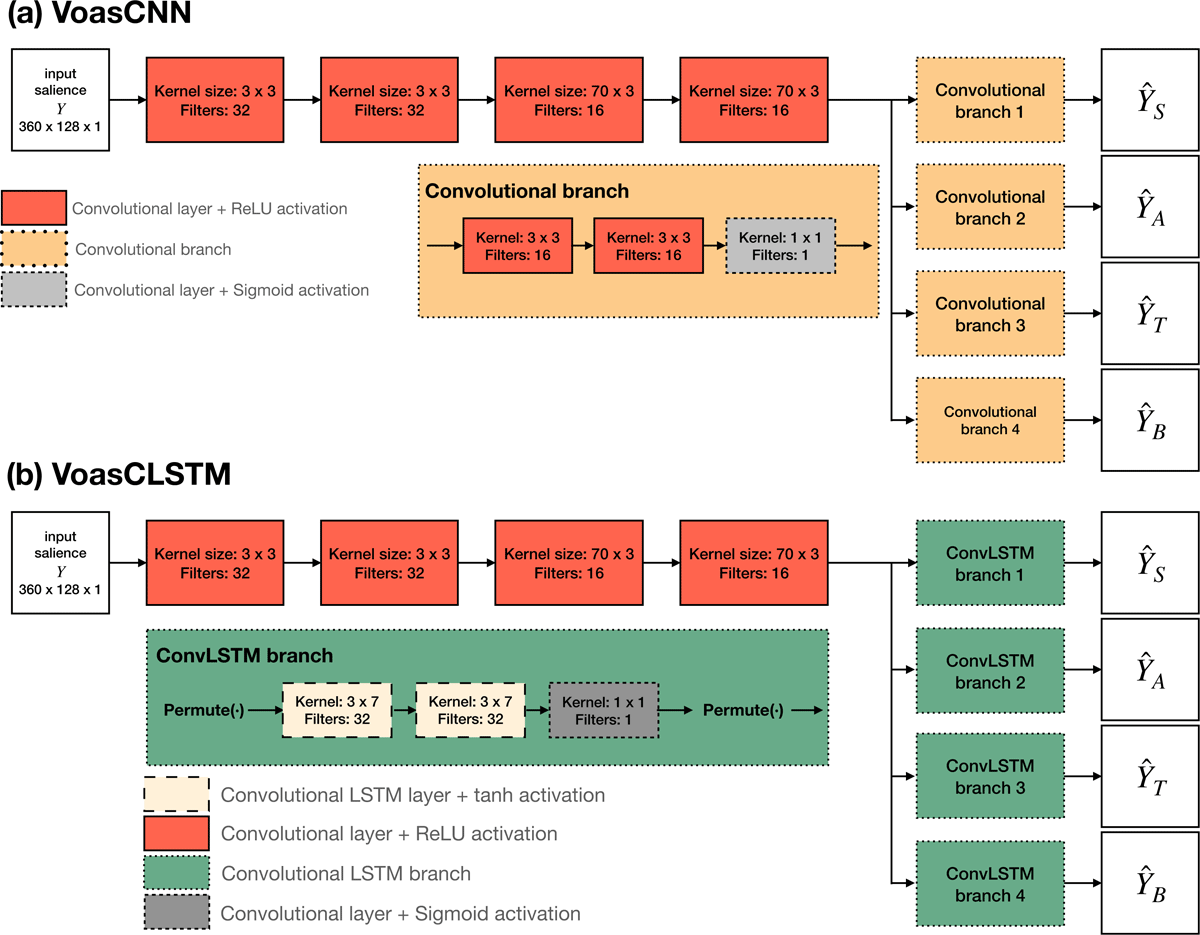
Figure 3
Proposed network architectures. (a) VoasCNN is a fully convolutional network with a shared first stage, and four separate branches in the second stage (convolutional branches). (b) VoasCLSTM is a network with a first stage of convolutional layers, followed by four separate branches in the second stage with convolutional LSTM layers (ConvLSTM branches). All convolutional layers are preceded by batch normalization.
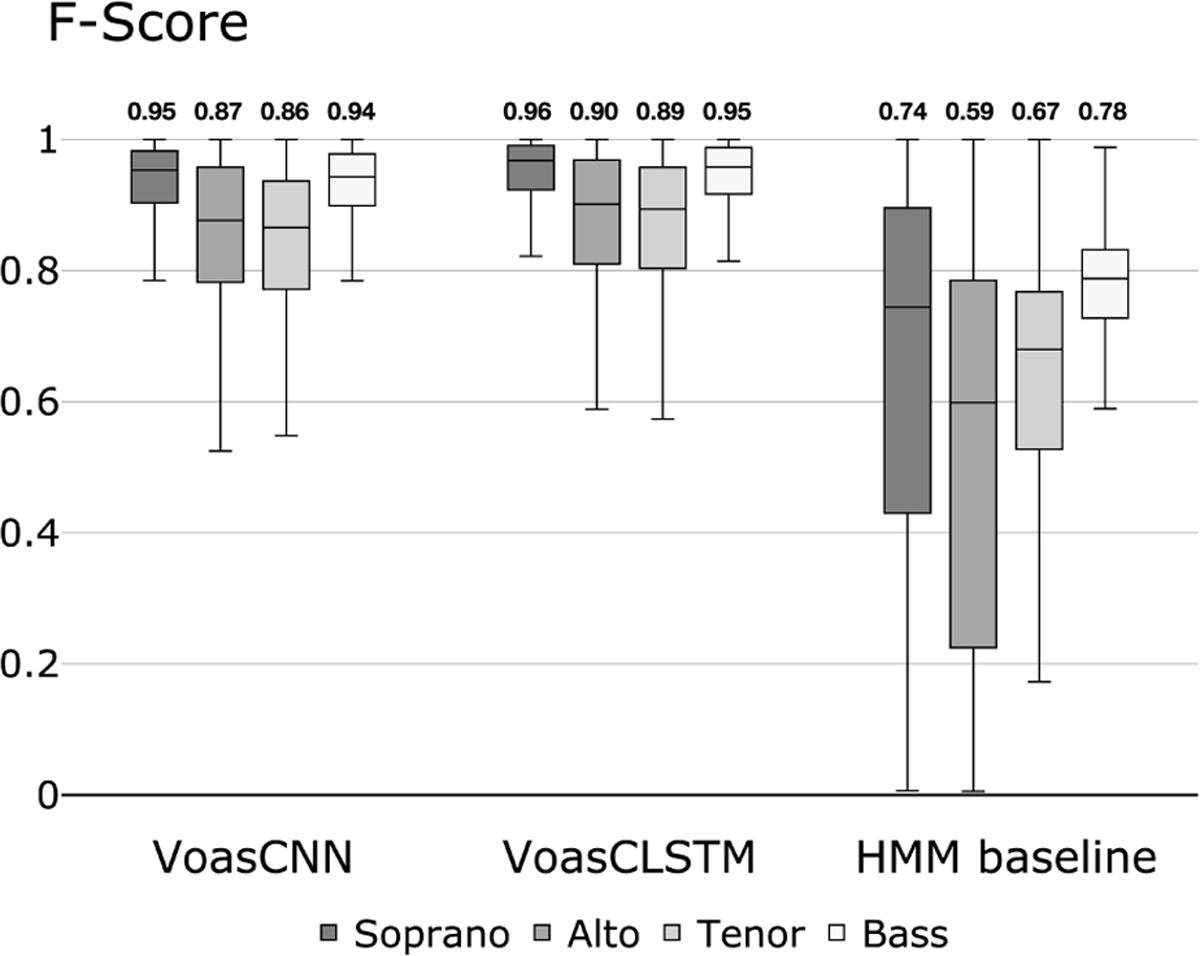
Figure 4
Experiment 1 results. Boxplots with the evaluation results (per-voice F-Score) of the two proposed models (VoasCNN and VoasCLSTM) and the HMM-based baseline on the synthetic test set. The horizontal line inside the boxes shows the median of the distribution, and the numbers above each box indicate the corresponding numerical value.
Table 1
Data degradation experiment results: voice-specific F-Score obtained with C-VoasCNN and D-VoasCNN (Fvoice), and multi-pitch F-Score (FMPE) calculated by combining the four assigned trajectories (post-VA). We additionally report the average FMPE obtained with L/D CNN (Late/Deep CNN, pre-VA). The best result for each voice is highlighted in bold and standard deviations are displayed in italics.
| Voice/Model | C-VoasCNN | D-VoasCNN | L/D CNN |
| FSoprano | 0.77 (0.05) | 0.73 (0.06) | – |
| FAlto | 0.51 (0.07) | 0.56 (0.10) | – |
| FTenor | 0.54 (0.05) | 0.56 (0.08) | – |
| FBass | 0.76 (0.06) | 0.71 (0.06) | – |
| FMPE | 0.75 (0.03) | 0.77 (0.03) | 0.85 (0.03) |

Figure 5
Post-VA F0 outputs (color) vs. F0 ground truth (black) for an excerpt of Virgen Bendita sin par from the Cantoría dataset. The thresholds we use for this experiment are optimized per-voice on the validation set.
Table 2
Evaluation results of the generalization experiment on the BSQ. L/D stands for Late/Deep, and HMM refers to the HMM-based baseline for VA. The first three rows correspond to MPE models, thus we only report MPE results. Rows 4 to 8 show MPE+VA results with two baselines (VOCAL4-VA and L/D + HMM) and our proposed models (L/D + C-/D-VoasCNN and D-VoasCLSTM). Standard deviations are indicated in italics, and the best performance for each voice and configuration are highlighted in boldface.
| Model generalization Barbershop Quartets Dataset | |||||
| Model | FSoprano | FAlto | FTenor | FBass | FMPE |
| MSINGERS | – | – | – | – | 0.71 (0.06) |
| VOCAL4-MP | – | – | – | – | 0.59 (0.05) |
| L/D CNN | – | – | – | – | 0.84 (0.03) |
| VOCAL4-VA | 0.42 (0.18) | 0.34 (0.16) | 0.35 (0.16) | 0.84 (0.06) | 0.75 (0.06) |
| L/D + HMM | 0.68 (0.12) | 0.43 (0.16) | 0.40 (0.18) | 0.66 (0.15) | 0.77 (0.06) |
| L/D + C-VoasCNN | 0.75 (0.12) | 0.50 (0.16) | 0.57 (0.13) | 0.89 (0.04) | 0.84 (0.04) |
| L/D + D-VoasCNN | 0.76 (0.09) | 0.59 (0.15) | 0.57 (0.14) | 0.85 (0.05) | 0.84 (0.04) |
| L/D + D-VoasCLSTM | 0.65 (0.15) | 0.54 (0.17) | 0.59 (0.14) | 0.84 (0.05) | 0.83 (0.05) |
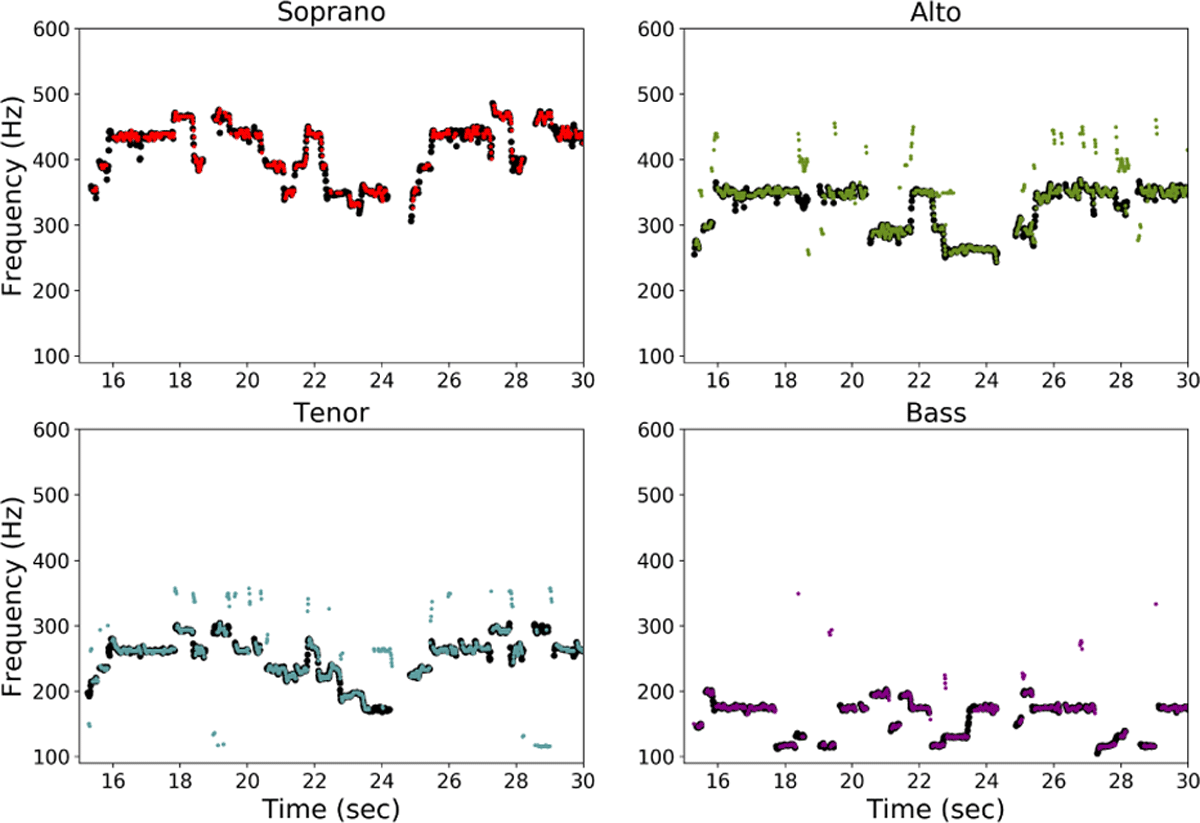
Figure 6
Excerpt of the output of Late/Deep CNN + D-VoasCLSTM on Virgen Bendita sin par from Cantoría dataset.