
1 Einführung
Mit dem Beginn des Computerzeitalters in der Schweiz im Jahr 1950 hat sich das Verständnis von Daten und Datenverarbeitung grundlegend verändert (Betschon, 2019, S. 11). Technische Entwicklungen fördern zwar Datenerfassungs- und -verarbeitungsprozesse, führen aber auch vermehrt zu Internetsicherheitsproblemen. Im Jahr 1997 nutzte weniger als eine von zehn Personen in der Schweiz das Internet mehrmals wöchentlich. Der Anteil regelmässiger Internetnutzenden ist seither gestiegen und lag im Jahr 2020 bei neun von zehn Personen (Bundesamt für Statistik, 2020b). Nutzt die Bevölkerung das Internet öfter und intensiver, können entsprechend häufiger Sicherheitsprobleme auftreten (Bundesamt für Statistik, 2020a). Gemäss der polizeilichen Kriminalstatistik durch das Bundesamt für Statistik (BFS) wurden im Jahr 2020 in der Schweiz knapp 24‘400 digitale Straftaten registriert. Die Tendenz zu einer zunehmenden Internetnutzung sowie die steigenden Sicherheitsprobleme sollten dazu führen, dass das Treffen von Sicherheitsmassnahmen einen hohen Stellenwert für Internetnutzende hat. In einer Omnibuserhebung zur Internetnutzung im Jahr 2021, gaben jedoch nur 60 Prozent der Internetnutzenden an, eine Vorsichtsmassnahme im Bereich Internetsicherheit ergriffen zu haben (Bundesamt für Statistik, 2021). Eine Umfrage zur Besorgnis über die Datensicherheit im Internet in der Schweiz vom Jahr 2018 zeigt jedoch, dass sich nur etwa drei Prozent der Befragten nicht um die Datenspuren, die sie im Internet hinterlassen, kümmern. Dagegen gaben 37 Prozent an, sich Sorgen zu machen, während die restlichen 60 Prozent mit «eher ja» oder «eher nein» antworteten (Schweizerisches Konsumentenforum kf, 2018). Es besteht also ein Widerspruch zwischen den Bedenken der Internetnutzenden einerseits und der mangelnden Bereitschaft, individuelle Sicherheitsvorkehrungen im Internet zu treffen andererseits. Dieses Phänomen wird als Datenschutzparadoxon bezeichnet (Lasarov & Hoffmann, 2021, S. 1535). In Anbetracht des Widerspruchs zwischen der Einstellung und dem Verhalten der Bevölkerung sowie der steigenden Bedeutung des Internets scheint es aus Perspektive der persönlichen Sicherheit aber essenziell, dass Menschen ihr Verhalten an die sich verändernden Umständen anpassen und das Datenschutzparadoxon in der Praxis aufgelöst wird.
Das Datenschutzparadoxon wurde in der Literatur mehrfach belegt (Barth & de Jong, 2017; Dienlin & Trepte, 2015; Kokolakis, 2017; Xu et al., 2010). Konkrete Massnahmen, die das Datenschutzparadoxon auflösen, sind jedoch wenig erforscht. Ziel dieser wissenschaftlichen Arbeit ist es, zu untersuchen, ob eine Bewusstseinsbildung im Sinne der Verdeutlichung der persönlichen Betroffenheit der einzelnen Internetnutzenden in diesem Zusammenhang zu einer Verhaltensänderung führt. Dazu sollen konkrete Massnahmen zur Reduzierung des Datenschutzparadoxons entwickelt und mithilfe eines Experiments getestet werden. Gestützt auf die Medienwirkungsforschung (Hangen, 2012, S. 122) wird folgende Forschungsfrage untersucht: Welche Auswirkungen hat das Auslösen persönlicher Betroffenheit durch öffentliche Medien auf das Teilen von sensiblen Daten im Internet?
Das Forschungsdesign entspricht einem quantitativen Experiment in Form eines online durchgeführten Umfrage-Experiments mit kontrollierter Randomisierung und zwei Gruppen (Kontroll- und Vergleichsgruppe). Zur Feststellung von Ursache-Wirkungs-Beziehungen wurden einzelne Bedingungsfaktoren oder Merkmale, welche als unabhängige Variablen definiert wurden, abgeändert, um herauszufinden, welche Effekte diese auf die abhängigen Variablen haben. Die Stichprobe (N=80) beinhaltet Angehörige der Deutschschweizer Bevölkerung. Der Fokus dieser Arbeit liegt darin, den kausalen Effekt persönlicher Betroffenheit auf das Teilen von sensiblen respektive persönlichen Daten im Internet zu überprüfen. Die Studie zeigt, dass persönliche Betroffenheit durchaus dazu führt, dass weniger persönliche Daten geteilt werden. Allerdings erweist sich der verwendete Stimulus als ungeeignet, so dass weitere Stimuli systematisch erforscht werden sollten.
2 Theoretischer Rahmen
Grundsätzlich können Tätigkeiten, welche über das Internet abgewickelt werden, als Daten im Internet zurückverfolgt, aufbewahrt, gespeichert und an Dritte weitergegeben werden (Lessig, 2002). Trotz rechtlicher Vorkehrungen zum Schutz der Daten im Internet, wie beispielsweise das Datenschutzgesetz in der Schweiz (DSG) oder die Datenschutzgrundverordnung der Europäischen Union (Verordnung (EU) 2016/679 des Europäischen Parlaments und des Rates vom 27. April 2016 zum Schutz natürlicher Personen bei der Verarbeitung personenbezogener Daten, zum freien Datenverkehr und zur Aufhebung der Richtlinie 95/46/EG (Datenschutz-Grundverordnung), 2018), nimmt die Anzahl von Datenschutzverletzungen im Zeitverlauf zu. Im Jahr 2021 wurden im Vergleich zum Vorjahr in der Schweiz 24 Prozent mehr digitale Straftaten registriert (Bundesamt für Justiz, 2022). Ebenso zeigen Umfragen, dass in der Bevölkerung die Sorgen bezüglich Datenschutz und Datensicherheit im Internet zunehmen (Goldfarb & Tucker, 2012; Latzer et al., 2017; Schweizerisches Konsumentenforum kf, 2018). Die Bedenken der Internetnutzenden beziehen sich dabei sowohl auf einen direkten Schaden, beispielsweise einem finanziellen Schaden beim Missbrauch von Zahlungsmittelinformationen, als auch einen indirekten Schaden durch eine Verletzung der Privatsphäre (Brown, 2001).
Das Datenschutzparadoxon bezeichnet ein Phänomen, bei dem Personen bei der Nutzung von Diensten im Internet einerseits Bedenken bezüglich der Sicherheit und dem Schutz ihrer Daten haben, andererseits aber ihre Daten freiwillig und nur für geringe Gegenleistungen zur Verfügung stellen. Gemäss des Privacy Paradox stimmen also die Meinungen und Haltungen von Personen nicht mit ihrem Verhalten überein. Die grundsätzliche Existenz des Phänomens wurde in mehreren Studien bestätigt. Als eine der ersten Studien zu diesem Phänomen, argumentieren Norberg et al. 2007, dass die grundsätzliche Bereitschaft zum Teilen von Daten durch die wahrgenommenen Risiken bestimmt werden, wohingegen das tatsächliche Teilen stärker vom Vertrauen in den Online-Dienst abhängt. Dies wird auch durch eine Literaturanalyse von Barth und de Jong (2017) bestätigt. Risiken werden demnach bei der Entscheidung zum tatsächlichen Teilen von Daten nicht beachtet oder verzerrt eingeschätzt. Willems et al. (2022) zeigen weiter, dass Personen mit Datenschutzbedenken bestimmte Apps insbesondere dann herunterluden und nutzten, wenn der wahrgenommene Nutzen der App hoch war. Allerdings zeigt die Studie auch, dass Personen eine App nicht weniger herunterladen, wenn sie mehr persönliche Daten teilen müssen. Dies bestätigt wiederum das Datenschutzparadoxon. Barth et al. (2017) zeigen allerdings, dass Sorgen um die Sicherheit der Daten im Internet zwar nicht zu einer geringeren Nutzung von Diensten im Internet führen, aber durchaus mit einer geringeren Wahrscheinlichkeit Informationen zu teilen sowie mit einer höheren Wahrscheinlichkeit für Datenschutzmassnahmen einhergehen.
Um den augenscheinlichen Widerspruch des Paradoxons zu erklären, werden die Faktoren empfundener Nutzen, Vertrauen, und technische Fähigkeiten angeführt. Der empfundene Nutzen des angebotenen Produkts oder der Dienstleistung, kann dazu führen, dass Datenschutzbedenken weniger Gewicht zukommt und Daten eher geteilt werden (Gabisch & Milne, 2014; White et al., 2008; Ziefle et al., 2016). Vertrauen in die Organisationen, welche die Produkte und Dienstleistungen im Internet zur Verfügung stellen, kann zu geringerer Achtsamkeit beim Teilen von Daten führen (Aguirre et al., 2015; Lutz & Strathoff, 2014). Geringe technische Fähigkeiten und technisches Wissen der NutzerInnen über die Verwertung ihrer Daten im Internet kann zu unvorsichtigerem Teilen von Daten führen (Büchi et al., 2017; Park, 2011).
Ein weiterer, bisher nur indirekt beachteter Faktor ist die persönliche Betroffenheit. Persönliche Betroffenheit wird definiert als das Empfinden von hoher persönlicher Relevanz oder Beteiligung, beziehungsweise hohe empfundene Wahrscheinlichkeit, dass ein konkretes Ereignis auf eine bestimmte Person zutreffen oder eintreten könnte (Greenwald & Leavitt, 1984, S. 583). Das Empfinden persönlicher Betroffenheit hat Auswirkugnen auf das Verhalten von Personen (Stucki et al., 2018). In Bezug auf Datenschutz zeigen Büchi et al. (2017), dass frühere, negative Erfahrungen mit Privatsphäreverletzungsen dazu führen, dass die NutzerInnen vorsichtiger beim Umgang mit ihren Daten im Internet sind. Dies stellt eine extreme Form von persönlicher Betroffenheit dar, da den InternetnutzerInnen auf schmerzliche Weise bewusst gemacht wurde, dass auch sie direkt von Datenmissbräuchen betroffen sind. Mehrere Studien argumentieren in abgeschwächter Weise, dass nicht das technische Wissen an sich, sondern das Wissen um die Möglichkeit des Missbrauchs der eigenen Daten zu vorsichtigerem Umgang mit den eigenen Daten führen kann (Park, 2011; Pötzsch, 2009; Weinberger et al., 2017). Daraus ergibt sich die Hypothese, dass Personen, welche eine höhere persönliche Betroffenheit empfinden, weniger sensible Daten im Internet teilen.
H1: Persönliche Betroffenheit führt zu vorsichtigerem Umgang mit persönlichen Daten.
Politik und Verwaltung, insbesondere Datenschutzbeauftragte suchen immer wieder nach Möglichkeiten, Wegen, und Instrumenten, um die Bevölkerung zu einem vorsichtigeren Umgang mit persönlichen Daten zu animieren (Datenschutzbeauftragte des Kantons Zürich (DBS), 2022). Aus der Literatur zu «involvement» zeigt sich für andere Bereiche, dass persönliche Betroffenheit durch geographische Nähe ausgelöst werden kann. Menschen engagieren sich persönlich, wenn das Thema für sie wichtig ist und sie sich dafür interessieren (Stucki et al., 2018; Thomsen et al., 1995, S. 192ff.).
Basierend auf dieser Literatur argumentieren wir, dass persönliche Betroffenheit durch das Aufzeigen von geographischer Nähe zu Datenmissbräuchen ein geeignetes Instrument sein könnte, um persönliche Betroffenheit auszulösen. Dabei erzeugen wir geographische Nähe experimentell, indem ein Zeitungsartikel mit einem Fall von Datenmissbrauch mit und ohne persönliche geographische Nähe zur befragten Personals Stimulus verwendet wird.
Dabei stützen wir uns auf die Medienwirkungsforschung, welche aufzeigt, dass Zeitungen in der Lage sind, Nähe herzustellen. Die Theorie der Medienwirkungsforschung versucht die Nutzung und die Auswirkung der Medien auf den Menschen zu erklären (Oliver, Raney und Bryant, 2019, S. 17). Mediennutzung kann bei Menschen zu Veränderungen von Kognitionen, Emotionen, Einstellungen und Verhaltensweisen führen (Valkenburg, Peter und Walther, 2016). Darüber hinaus zeigt eine Umfrage zur Mediennutzung in der Schweiz, dass Zeitungen mit einem Nutzeranteil von fast 90 Prozent in allen Altersgruppen das meistgenutzte Medium sind (Statista, 2021). Basierend auf diesen Erkenntnissen argumentieren wir, dass persönliche Betroffenheit durch das Lesen eines Zeitungsartikels ausgelöst werden kann.
H2: Durch das Lesen eines Zeitungsartikels mit geographischer Nähe kann persönliche Betroffenheit ausgelöst werden.
3 Forschungsdesgin
Für die empirische Untersuchung der Forschungsfrage und der beiden Hypothesen wurde im März 2022 ein Online-Experiment unter DeutschschweizerInnen durchgeführt. Das Forschungsdesign entspricht einem quantitativen Experiment in Form eines online durchgeführten Umfrage-Experiments mit kontrollierter Randomisierung. Zur Feststellung von Ursache-Wirkungs-Beziehungen wurden einzelne Bedingungsfaktoren oder Merkmale, welche als unabhängige Variablen definiert wurden, abgeändert, um herauszufinden, welche Effekte diese auf die abhängigen Variablen haben. Die Teilnehmenden wurden nach dem Zufallsprinzip mittels eines Randomisierers auf eine Versuchs- und eine Kontrollgruppe verteilt. Insgesamt haben 123 Personen am Experiment teilgenommen. Der Rücklauf betrug 80 vollständig beantwortete Fragebogen, somit umfasste jede Gruppe 40 Teilnehmende. Der Prozess der Auswahl von TeilnehmerInnen für das Experiment folgte einer unstrukturierten Rekrutierung. Das heisst, dass keine vordefinierten Kriterien oder Methoden für die Auswahl der TeilnehmerInnen verwendet wurden.1 Die Versuchsteilnehmenden wussten, dass es sich um ein Experiment handelt. Da dieses Experiment eine sozialpsychologische Komponente besitzt, war es wichtig, ein experimentelles Szenario zu entwickeln. Jonas et al. (2007, S. 47) betonen, dass es in einer Laborsituation wesentlich ist, ein Szenario mit einer überzeugenden und gut durchdachten Begründung zu entwickeln. Experimentelle Manipulationen und Messverfahren sollten den Versuchsteilnehmenden nicht sofort zur Kenntnis gebracht werden, sodass die Situation für diese realistisch ist und es ihnen ermöglicht wird, sich tatsächlich einzubringen. Die ‹Verpackung› des Experiments sollte ein realistisches Szenario bilden. Das Experiment begann somit mit dem folgenden einleitenden Text für beide Gruppen (Kontroll- und Vergleichsgruppe), mit dem Ziel, vom Thema Datenschutz und Datensicherheit abzulenken:
«Staatsoberhaupte übernehmen während ihres Amtes besondere Pflichten. Das Ziel dieses Experimentes ist es, einen Ländervergleich zu ziehen und Kompetenzen verschiedener Präsidenten zu überprüfen. Dazu wird ein kürzlich erschienener Zeitungsartikel einer Schweizer Zeitung vorgelegt und im Anschluss werden Fragen gestellt. Sie haben jederzeit die Möglichkeit, die Option «Möchte ich nicht beantworten» zu wählen.»
Um möglichst repräsentative Ergebnisse zu erhalten, müssen die Versuchsteilnehmenden zufällig den unterschiedlichen Bedingungen zugeteilt werden (Jonas et al., 2007, S. 41). Die Teilnehmenden durchlaufen jeweils nur eine Bedingung und sind somit unabhängig voneinander. Das Experiment beinhaltet die zwei Gruppen: ‹Zeitungsartikel Schweiz› (Intervention ‹persönliche Betroffenheit›) und ‹Zeitungsartikel Israel› (Kontrolle).
Als Stimulus wurde ein Zeitungsartikel im Zusammenhang mit einem Datenschutzproblem gewählt (vgl. Abbildung 1 und Abbildung 2), wodurch ein Bewusstsein für Privatsphäre ausgelöst werden sollte. Damit das Experiment möglichst der Realität entspricht, wurde ein originaler Zeitungsartikel verwendet (Spalinger, 2022) und die unabhängige Variable (persönliche Betroffenheit) in diesen eingebaut. Um geographische Nähe für die Versuchsgruppe herzustellen, wurde der Begriff ‹Israel› durch ‹Schweiz› und der Name des ehemaligen israelischen Ministerpräsidenten Benjamin Netanyahu, welcher 2021 sein zum Zeitpunkt der Erhebung letztes Amtsjahr hatte (Britannica, 2022), durch den des ehemaligen Schweizer Bundespräsidenten Guy Parmelin, der ebenfalls das Amt im Jahr 2021 innehatte (Schweizerische Eidgenossenschaft, 2022), ersetzt. Ausserdem wurde ein Satz in beiden Artikeln hinzugefügt, um einen Bezug zu Privatpersonen herzustellen. Der Zeitungsartikel sowie die direkte Konfrontation mit dem Datenschutzproblem wurden bewusst zu Beginn integriert, um das unmittelbare Verhalten messen zu können. Pötzsch (2009, S. 229) zufolge kann der Schutz der Privatsphäre verbessert werden, wenn Interaktionen – in diesem Fall das Lesen des Zeitungsartikels – die Menschen an ihre Absicht ‹erinnern›, die Privatsphäre zu schützen. Weiter wird somit untersucht, ob der Artikel über die Schweiz persönliche Betroffenheit und ein Schutzbedürfnis auslöst und der Artikel über Israel eher eine unterhaltende Wirkung hat. Da Israel geografisch weit entfernt liegt, wird vermutet, dass der entsprechende Artikel eine geringere persönliche Betroffenheit auslöst.

Abbildung 1
Fiktiver Zeitungsartikel (Israel).
Quelle: In Anlehnung an Spalinger (2022, S. 3).

Abbildung 2
Fiktiver Zeitungsartikel (Schweiz).
Quelle: In Anlehnung an Spalinger (2022, S. 3).
Nach der Präsentation der beiden Stimuli, wird den Befragungsteilnehmenden ein Fragebogen vorgelegt. Der Fragebogen gliedert sich in 19 Fragen (siehe Anhang Tabelle 5), welche neben der Abfrage von demographischen Faktoren und persönlicher Betroffenheit insbesondere zur unmittelbaren Verhaltensmessung nach Lesen des Zeitungsartikels dienen. Dazu wurden die Befragungsteilnehmenden gebeten, bestimmte Daten, wie beispielsweise ihr Geburtsdatum oder ihre Privatadresse, anzugeben.
4 Resultate
In der gesamten Stichprobe (N = 80) überwiegt der Frauenanteil knapp mit 52.50 % (n = 42) und ist in Bezug auf die Grundgesamtheit repräsentativ. Die Altersverteilung zeigt eine klare Konzentration. Die grösste Altersgruppe war die der 21- bis 30-Jährigen (43.75 %, n = 43), wie in der Tabelle 1 dargestellt. Jüngere Personen sind im Vergleich zur Grundgesamtheit somit überrepräsentiert. Für den Untersuchungsgegenstand ist eine eventuelle Verzerrung jedoch unproblematisch, da Jugendliche und junge Erwachsene aufgrund der höheren Internetnutzung vom Datenschutzparadoxon häufiger betroffen sind (Niemann & Schenk, 2012).
Tabelle 1
Deskriptive Beschreibung des Gesamtsamples: Häufigkeitsverteilung Geschlecht und Alter.
| VARIABLE | KATEGORIE | PROZENT | N |
|---|---|---|---|
| Geschlecht | Männlich | 43.75 % | 35 |
| Weiblich | 52.50 % | 42 | |
| Andere | 3.75 % | 3 | |
| Alter | 20 und jünger | 10.00 % | 8 |
| 21–30 | 65.00 % | 52 | |
| 31–40 | 10.00 % | 8 | |
| 41–50 | 6.25 % | 5 | |
| 51–65 | 5.00 % | 4 | |
| 66 und älter | 0.00 % | 0 | |
| Keine Angabe | 3.75 % | 3 | |
| Gesamt | 100.00 % | 80 | |
[i] Anmerkung: Häufigste Werte in Fettschrift.
Zur Beantwortung der Forschungsfrage wurde in einem ersten Schritt analysiert, ob es einen Unterschied im Teilen von persönlichen Daten zwischen der Versuchs- und der Kontrollgruppe gibt. Der Unterschied im Teilen von persönlichen Daten zwischen den beiden Gruppen wurde anhand einer Analyse der Menge an preisgegebenen persönlichen Informationen gemessen. Mithilfe einer Häufigkeitsverteilung wurde ausgewertet, wie die Personen in der Versuchs- und Kontrollgruppe die jeweiligen Fragen beantwortet haben.2 Wählten die Teilnehmenden die Antwortmöglichkeit «Möchte ich nicht beantworten», so haben sie die Daten nicht teilen wollen. In Tabelle 2 ist die Reihenfolge der Fragen, die Anzahl der Personen, die jeweils die Daten geteilt und somit nicht «Möchte ich nicht beantworten» angegeben haben, nach den Fragen und Gruppen angeordnet.
Tabelle 2
Gruppenunterschiede hinsichtlich des Teilens von Daten.
| FRAGE | GRUPPE | |||||
|---|---|---|---|---|---|---|
| ISRAEL | SCHWEIZ | GESAMT | ||||
| PROZENT | n | PROZENT | n | N | ||
| P1 | Geburtsort | 47.14 % | 33 | 52.86 % | 37 | 70 |
| P2 | Nationalität | 48.68 % | 37 | 51.32 % | 39 | 76 |
| P3 | Geburtsdatum | 51.72 % | 30 | 48.28 % | 28 | 58 |
| P4 | Privatadresse | 38.89 % | 7 | 61.11 % | 11 | 18 |
| P5 | E-Mail-Adresse | 60.87 % | 14 | 39.13 % | 9 | 23 |
| P6 | Handynummer | 33.33 % | 4 | 66.67 % | 8 | 12 |
| P7 | Familienstand | 50.68 % | 37 | 49.32 % | 36 | 73 |
| P8 | Name | 59.38 % | 19 | 40.63 % | 13 | 32 |
| P9 | Standort | 42.86 % | 6 | 57.14 % | 8 | 14 |
| P10 | Elternnamen | 50.00 % | 7 | 50.00 % | 7 | 14 |
[i] Anmerkung: Angaben in Zeilenprozenten. Es ist jeweils nur die Anzahl derjenigen Personen aufgelistet, die die betreffende Frage auch beantwortet haben. Insgesamt waren es N = 80 Teilnehmende. Die Fragen sind im Anhang vollständig aufgeführt.
Es lassen sich gesamthaft Unterschiede im Hinblick auf den Verlauf der Fragen aber auch innerhalb der Gruppen ‹Israel› und ‹Schweiz› feststellen. Zu Beginn war die gesamthafte Antwortquote (N = 80) hoch (P1: n = 70 [87.50 %], P2: n = 76 [95.00 %], P3: n = 58 [72.50 %]). Die Fragen P4 bis P6 hingegen haben durchschnittlich nur ca. ein Viertel der Teilnehmenden beantwortet (P4: n = 18 [22.50 %], P5: n = 23 [28.75 %], P6: n = 12 [15.00 %]). Nachdem die Frage P7 von 73 Teilnehmenden (91.25 %) beantwortet wurde, sank die Antwortquote bei den Fragen P8–P10 auf 40.00 % bzw. 17.50 % (P8: n = 32 [40.00 %], P9: n = 14 [17.50 %], P10: n = 14 [17.50 %]).
Das Balkendiagramm in Abbildung 3 veranschaulicht den Vergleich zwischen der Versuchsgruppe (Schweiz) und der Kontrollgruppe (Israel). Die Auswertung zeigt, dass die beiden Gruppen im Antwortverhalten einen ähnlichen Verlauf aufweisen.
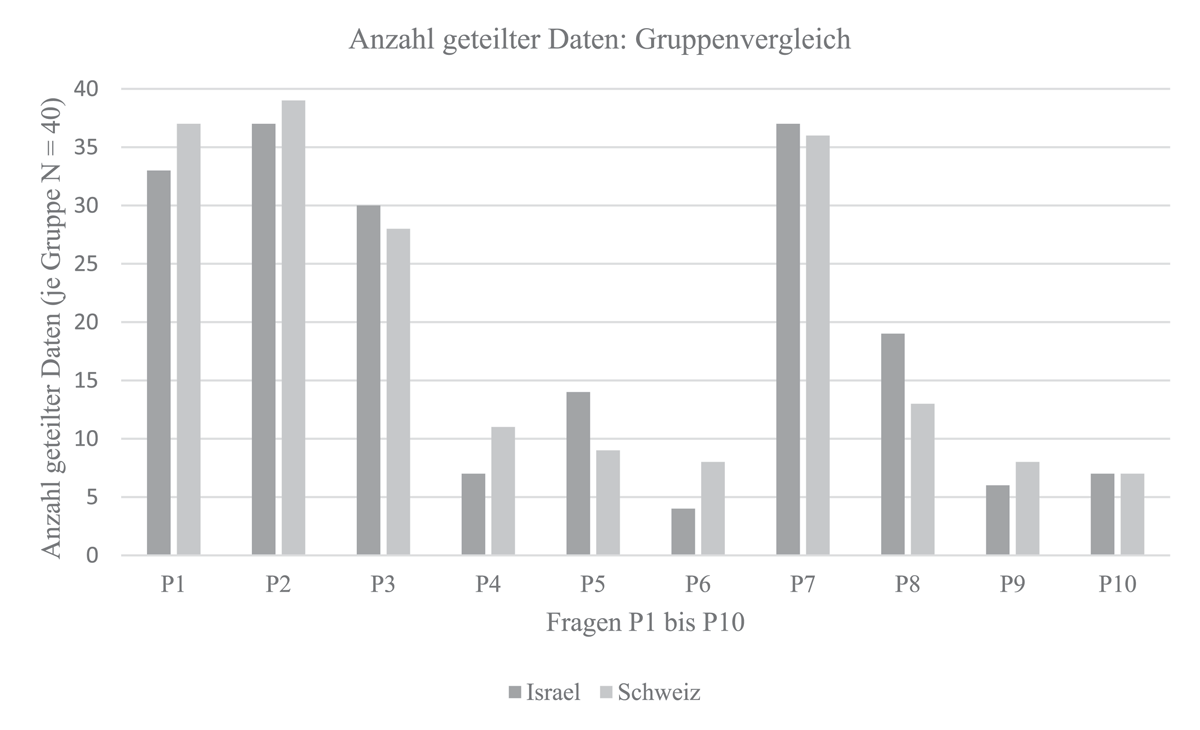
Abbildung 3
Gruppenvergleich ‹Israel› und ‹Schweiz›: Anzahl geteilter Daten.
Um nun die Relevanz des Konzepts der persönlichen Betroffenheit zu analysieren, werden die beiden Hypothesen genauer untersucht. Dazu werden die Ergebnisse der Frage zur Ermittlung der persönlichen Betroffenheit mit den jeweils preisgegebenen persönlichen Informationen verglichen. Somit werden die Personen, die sich vom Zeitungsartikel persönlich betroffen fühlten, mit denjenigen, die sich nicht persönlich betroffen fühlten, und denjenigen, die nicht wussten, ob sie sich persönlich betroffen fühlten, hinsichtlich ihrer Bereitschaft zum Teilen persönlicher Daten verglichen. Um die persönliche Betroffenheit zu messen, wurden die Teilnehmenden gefragt, ob sie sich beim Lesen des Zeitungsartikels persönlich betroffen fühlten oder nicht. Dazu wurden die vier Antwortmöglichkeiten «Ja», «Nein», «Weiss nicht» und «Möchte ich nicht beantworten» zur Auswahl gestellt.
Dabei zeigt sich, dass Personen, welche bei der Frage zur persönlichen Betroffenheit «Nein» angegeben haben, tendenziell mehr Daten teilen als Personen, welche die Frage mit «Ja» beantwortet haben (Abbildung 4). Insbesondere bei den Fragen nach der Privatadresse (P4, Anteil geteilter Daten: n = 12 [66.67 %]) der E-Mail-Adresse (P5, n = 15 [65.22 %]), der Handynummer (P6, n = 8 [66.67 %]) sowie nach dem Namen (n = 21 [65.63 %]) zeigten sich grössere Unterschiede (N = 42).
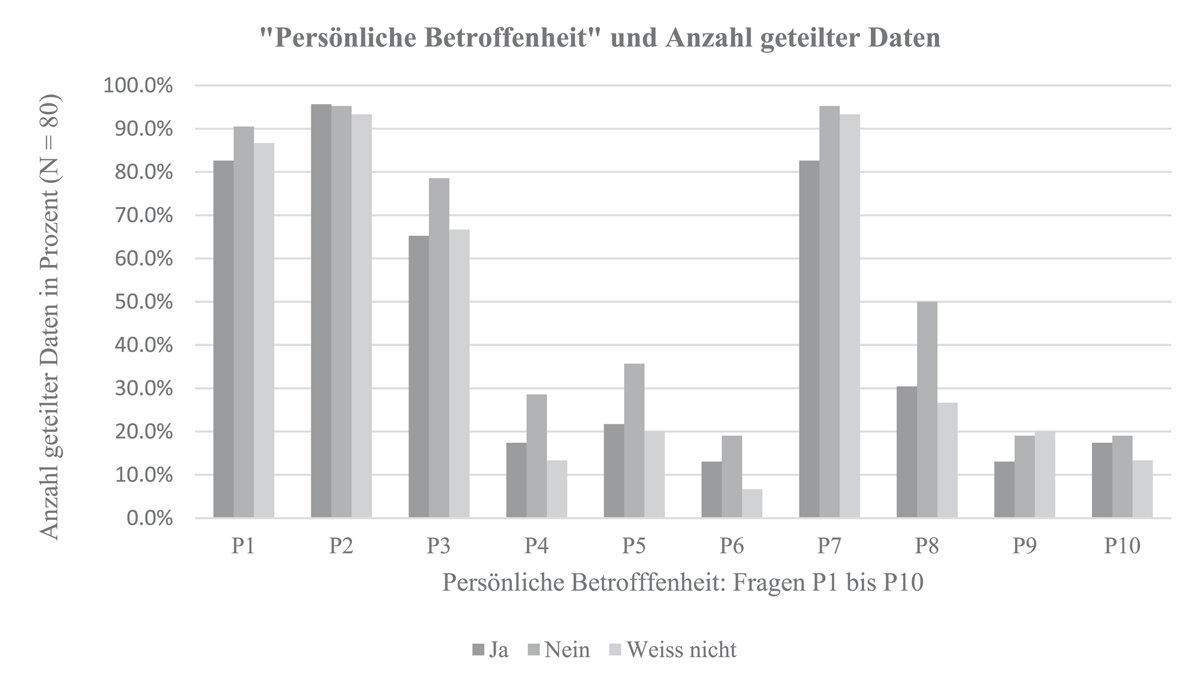
Abbildung 4
Balkendiagramm «Persönliche Betroffenheit» und Anzahl geteilter Daten.
Im Folgenden wurden diese Daten zum Teilen persönlicher Informationen über die einzelnen Informationen hinweg aggregiert und erneut zwischen persönlicher Betroffenheit und keiner Betroffenheit unterschieden. Tabelle 3 zeigt die Ergebnisse dieser Gegenüberstellung mittels einer Häufigkeitsverteilung.
Tabelle 3
Persönliche Betroffenheit und Anzahl geteilter Daten.
| ABSTIMMUNGSVERHALTEN | B1 FÜHLTEN SIE SICH BEIM LESEN DES ZEITUNGSARTIKELS PERSÖNLICH BETROFFEN? | ||
|---|---|---|---|
| JA IN PROZENT (N) | NEIN IN PROZENT (N) | WEISS NICHT IN PROZENT (N) | |
| Anzahl geteilter Daten | 43.91% (101) | 53.10% (223) | 44.00% (66) |
| Anzahl nicht geteilter Daten | 56.09% (129) | 46.90% (197) | 56.00% (84) |
| Anzahl Daten | 230 | 420 | 150 |
| Chi-Quadrat | 6.682* | ||
| Total Anzahl Daten | 800 | ||
[i] Anmerkung: * p < 0.05, ** p < 0.01, *** p < 0.001. χ2 = 6.682, N = 800, p = 0.035. Die totale Anzahl der Daten entspricht dem Produkt der Anzahl der Fragen in Frageblock P (P1–P10) mal der Anzahl der Teilnehmenden (N = 80).
Von den 800 Fragen (80 Teilnehmende mal 10 Fragen von Frageblock P) wurden insgesamt 390 Fragen beantwortet (48.75 %), während bei 410 Fragen «Möchte ich nicht beantworten» angegeben wurde (51.25 %). Nach Durchführung eines Chi-Quadrat Tests zeigte sich ein signifikanter Unterschied: Diejenigen Personen, welche sich vom Zeitungsartikel nicht persönlich betroffen fühlten, haben 53.10 % der Daten geteilt. Im Gegensatz dazu teilten Personen, welche sich vom Zeitungsartikel persönlich betroffen fühlten, mit 43.91 % signifikant weniger Daten (χ2 = 6.682, N = 800, p = 0.035). Diese Daten weisen also darauf hin, dass es einen signifikanten positiven Zusammenhang zwischen der persönlichen Betroffenheit und dem Teilen von persönlichen Informationen im Internet gibt.
Im nächsten Schritt interessiert nun, ob diese persönliche Betroffenheit von der geographischen Nähe ausgelöst wird. Hypothese zwei postuliert, dass durch das Lesen eines Zeitungsartikels mit geographischer Nähe persönliche Betroffenheit ausgelöst wird. Um dies zu überprüfen werden die Antworten zur Frage nach der persönlichen Betroffenheit zwischen der Versuchsgruppe mit geographischer Nähe und der Kontrollgruppe ohne geographische Nähe verglichen.
Tabelle 4 zeigt die Ausprägungen der Antworten zur Frage nach der persönlichen Betroffenheit im Gruppenvergleich. Die Frage, ob sich die Teilnehmenden beim Lesen des Zeitungsartikels persönlich betroffen fühlten, wurde von allen Teilnehmenden beantwortet (N = 80). Tabelle 4 zeigt, dass sich die Mehrheit der Teilnehmenden beider Gruppen beim Lesen der Artikel nicht persönlich betroffen fühlte (Israel: 57.50 %, N = 23; Schweiz 47.50 %, N = 19). Erkennbar ist, dass ein grösserer Teil der Teilnehmenden, der den Artikel über die Schweiz gelesen hat, nicht wusste, ob er sich persönlich betroffen fühlt oder nicht (27.50 %, N = 11). Um festzustellen, ob Gruppenunterschiede vorliegen, wurde ein Chi-Quadrat-Test durchgeführt. Hierbei lässt sich jedoch kein signifikanter Zusammenhang feststellen: Für die beiden Gruppen ‹Israel› und ‹Schweiz› gibt es in Bezug auf das Antwortverhalten zur persönlichen Betroffenheit keinen statistisch signifikanten Unterschied (χ2 = 4.039, N = 80, p = 0.133).
Tabelle 4
Persönliche Betroffenheit je nach Zeitungsartikel.
| FÜHLTEN SIE SICH BEIM LESEN DES ZEITUNGSARTIKELS PERSÖNLICH BETROFFEN? | ZEITUNGSARTIKEL | |
|---|---|---|
| ISRAEL IN PROZENT (N) | SCHWEIZ IN PROZENT (N) | |
| Ja | 32.50 % (13) | 25.00 % (10) |
| Nein | 57.50 % (23) | 47.50 % (19) |
| Weiss nicht | 10.00 % (4) | 27.50 % (11) |
| Möchte ich nicht beantworten. | 0.00 % (0) | 0.00 % (0) |
| Anzahl Teilnehmende | 40 | 40 |
| Chi-Quadrat | 4.039 | |
| Total Anzahl Teilnehmende | 80 | |
[i] Anmerkung: * p < 0.05, ** p < 0.01, *** p < 0.001. χ2 = 4.039, N = 80, p = 0.133.
Die vorliegende Studie deutet also darauf hin, dass das Lesen von Zeitungsartikeln mit geographischer Nähe kein Auslöser für persönliche Betroffenheit darstellt oder, dass das Treatment nicht ausgereicht hat, eine solche Betroffenheit hervorzurufen, entweder weil „Schweiz“ nicht ausgereicht hat, geographische Nähe herzustellen oder weil der Fall eines Politikers nicht ausgereicht hat persönliche Betroffenheit herzustellen.
5 Diskussion und Fazit
In unserer heutigen digitalen Welt sind persönliche, sensible Daten ein hohes und wertvolles Gut. Dieses gilt es sowohl von staatlicher als auch privater Seite zu schützen. Im Rahmen von gesetzlichen Vorgaben haben Staaten in aller Welt Grundregeln festgelegt, wie im Internet mit persönlichen Daten umgegangen werden darf und wie diese geschützt werden müssen. Neben diesen Grundregeln hat aber auch das individuelle Verhalten der NutzerInnen einen Einfluss darauf, wie stark die eigenen Daten geschützt sind. Während die meisten Menschen ihren persönlichen Daten und deren Schutz einen hohen Stellenwert zuweisen, verhalten sie sich im Internet oft nicht entsprechend und geben Daten freizügig preis. Diese Diskrepanz zwischen Einstellung und Verhalten wird als Datenschutzparadoxon bezeichnet. Um in einer sicheren, selbstbestimmten viralen Welt zu leben, gilt es dieses Datenschutzparadoxon dahingehend aufzulösen, dass das Verhalten stärker mit den Einstellungen in Einklang steht.
Das Ziel dieser Arbeit war es, die Rolle von persönlicher Betroffenheit im Kontext des Datenschutzparadoxons zu überprüfen. Basierend auf vorangegangener Literatur wurde angenommen, dass persönliche Betroffenheit ein bisher wenig beachteter Faktor zur Auflösung und Erklärung des Datenschutzparadoxons darstellt. Es wurde angenommen, dass, wenn sich Personen durch die Gefahr von Datenmissbräuchen persönlich betroffen fühlen, sie vorsichtiger mit persönlichen Daten im Internet umgehen. Somit würden sie unter dieser Randbedingung ihr Verhalten stärker ihren Einstellungen anpassen. Die persönliche Betroffenheit wurde mittels Lesen eines Zeitungsartikels mit geographischem Bezug experimentell erzeugt.
Das Verhalten beim Teilen von sensiblen Daten wurde gemessen, indem die Versuchsteilnehmenden nach Einführung des experimentellen Stimulus dazu aufgefordert wurden, persönliche Daten preiszugeben. Insgesamt beantworteten die Versuchsteilnehmenden 51.25 % der Fragen zu diesen persönlichen Daten. Dies deutet generell auf einen recht freizügigen Umgang mit persönlichen Daten hin. Innerhalb der Fragen zu den persönlichen Daten zeigen sich Muster. Zu Beginn war die Antwortquote sehr hoch (Fragen zu Geburtsort und Nationalität). Anschliessend nahm die Antwortquote stark ab. Insbesondere die Frage nach der Handynummer wurde sehr selten beantwortet. Dies könnte einerseits ein Reihenfolgeneffekt sein, bei dem die Versuchspersonen die ersten Fragen jeweils beantworten und die folgenden nicht mehr. Auch könnte ein Kummulationseffekt eine Rolle spielen, bei dem den Versuchsteilnehmenden bewusst sein könnte, dass die Kombination der preisgegebenen Informationen eine eindeutige Identifikation ihrer Person ermöglicht. Auch wäre es möglich, dass die Versuchspersonen einige Informationen als sensibler als andere betrachten und diese dann weniger preisgeben. Beispielswiese wurde die Frage zum Familienstand sehr häufig beantwortet, obwohl sie in der zweiten Hälfte des Fragenkatalogs gestellt wurde. Dies könnte allerdings auch dadurch erklärt werden, dass dies die einzige Frage mit vorgegebenen Auswahlmöglichkeiten war. Um zwischen diesen Effekten eindeutig unterscheiden zu können, sollten diese Art von Fragen in zukünftiger Forschung in randomisierter Reihenfolge gestellt werden.
Basierend auf diesem Experiment, konnte diese Studie erste Erkenntnisse in Bezug auf die Auflösung des Datenschutzparadoxons mittels persönlicher Betroffenheit liefern. Die vorliegenden Daten zeigten, dass Personen sich anders verhalten, wenn sie sich persönlich betroffen fühlen. Sie geben signifikant weniger persönliche Daten im Internet preis. Dies stellt einen wichtigen Ansatzpunkt für öffentliche und private Stellen dar, die den eigenverantwortlichen Umgang der Menschen mit ihren persönlichen Daten im Internet stärken möchten. Die Schaffung eines Bewusstseins über die persönliche Betroffenheit von Datenmissbräuchen könnte die Menschen dazu bringen, ihre eigenen Daten besser zu schützen und weniger freigiebig preiszugeben.
Basierend auf dieser Erkenntnis stellt sich nun die Frage, wodurch persönliche Betroffenheit und somit im Endeffekt ein vorsichtigerer Umgang mit persönlichen Daten im Internet ausgelöst werden kann. Basierend auf vorangegangener Literatur wurde untersucht, ob das Lesen eines Zeitungsartikels mit geographischer Nähe zu einem Datenmissbrauch-Skandal ein ausreichender Erzeuger von persönlicher Betroffenheit ist. Zu diesem Zweck wurden die Versuchspersonen in eine Versuchsgruppe und eine Kontrollgruppe unterteilt. Der Versuchsgruppe wurde ein Zeitungsartikel über einen Datenmissbrauch in ihrem Heimatland vorgelegt, der Kontrollgruppe ein äquivalenter Zeitungsartikel über ein geographisch entferntes Land. Die vorliegenden Daten zeigen, dass dieses Instrument nicht in der Lage ist persönliche Betroffenheit auszulösen. Grund dafür könnte die Art der Messung des Treatments sein: Das Land Israel, die Art des Mediums, oder die verwendeten Politiker haben womöglich nicht die entsprechende geographische Nähe ausgelöst, sodass es das Ergebnis signifikant hätte beeinflussen hätte. Dieses Ergebnis könnte darauf hindeuten, dass geografische Nähe zu einem Land keinen Einfluss auf das Gefühl der persönlichen Betroffenheit hat. Allerdings könnte der fehlende Zusammenhang auch durch andere Faktoren beeinflusst worden sein. Der verwendete Zeitungsartikel thematisiert in erster Linie einen Missbrauch von Daten von PolitikerInnen und hohen staatlichen BeamtInnen. Nur in einem Zusatz wurden BürgerInnen erwähnt. Hintergrund dieser Wahl war, das Experiment so realistisch wie möglich zu gestalten. Bei einem Datenmissbrauch von PolitikerInnen kann realistischerweise angenommen werden, dass Zeitungen darüber berichten, was bei einem Datenmissbrauch bei durchschnittlichen BürgerInnen nicht unbedingt der Fall ist. Daher kann es aber sein, dass sich durchschnittliche BürgerInnen von einer Meldung über PolitikerInnen nicht ausreichend betroffen fühlen. Dies könnte auch erklären, warum ein grösserer Teil der Teilnehmenden, welche den Zeitungsartikel über die Schweiz gelesen haben, nicht wussten, ob sie sich persönlich betroffen fühlten oder nicht. Eventuell fühlten sie sich zwar durch das Land persönlich betroffen, aber nicht durch die angesprochene Person des Politikers als Opfer des Datenmissbrauchs.
Darüber hinaus besteht die Stichprobe dieses Experiments grossteils aus jungen Erwachsenen (häufigstes Alter: 21 bis 30 Jahre, vgl. Tabelle 1). Diese Personengruppe informiert sich weniger über Zeitungen als eher über Social Media, weshalb sie bild- beziehungsweise videoorientiert sind. Auch dies kann ein fehlendes Gefühl der persönlichen Betroffenheit erklären. Eine weitere Limitation der Arbeit bestehen darin, dass der Fragebogen teilweise durch engere Verwandte und Freunde einer Mitautorin3 ausgefüllt wurden, welche mitteilten, dass sie persönliche Daten nur angegeben haben, um der Autorin einen Gefallen zu tun und dies in einem anderen Rahmen nicht tun würden. Dies könnten die Ergebnisse des Experiments verfälschen.
Diese Studie hat also gezeigt, dass persönliche Betroffenheit durchaus eine Rolle zur Verringerung des Datenschutzparadoxons spielen kann. In weiterer Forschung muss nun noch weiter untersucht werden, wie den Menschen ihre persönliche Betroffenheit besser vor Augen geführt werden kann. Denn in unserer der zunehmenden globalen, digitalen Welt, stellt das Datenschutzparadoxon eine immer grössere Herausforderung dar und nimmt somit stetig an Bedeutung zu. Die Ergebnisse der Arbeit bieten Chancen in Hinblick auf die zukünftige Entwicklung zur Auflösung des Datenschutzparadoxons, wodurch der Schutz der Privatsphäre der Bevölkerung eigenverantwortlich verbessert werden kann.
Appendices
Anhang
Tabelle 5
Fragebogen.
| NR. | FRAGE | ANTWORTMÖGLICHKEIT |
|---|---|---|
| A1 | Was ist Ihr Geburtsort? | Freies Textfeld Möchte ich nicht beantworten. |
| A2 | Was ist Ihre Nationalität? | Freies Textfeld Möchte ich nicht beantworten. |
| A3 | Was ist Ihr Geburtsdatum? | Freies Textfeld Möchte ich nicht beantworten. |
| A4 | Wie lautet Ihre Privatadresse? | Freies Textfeld Möchte ich nicht beantworten. |
| A5 | Wie lautet Ihre private E-Mail Adresse? | Freies Textfeld Möchte ich nicht beantworten. |
| A6 | Wie lautet Ihre private Handynummer? | Freies Textfeld Möchte ich nicht beantworten. |
| A7 | Was ist ihr Familienstand? | Ledig Getrennt Geschieden Verwitwet Verheiratet In eingetragener Partnerschaft Andere:___ Möchte ich nicht beantworten. |
| A8 | Wie lautet Ihr vollständiger Name? | Freies Textfeld Möchte ich nicht beantworten. |
| A9 | An welcher Adresse befinden Sie sich aktuell? | Freies Textfeld Möchte ich nicht beantworten. |
| A10 | Wie lauten die Namen Ihrer Eltern? | Freies Textfeld Möchte ich nicht beantworten. |
| B1 | Fühlten Sie sich beim Lesen des Artikels persönlich betroffen? | Ja Nein Weiss nicht Möchte ich nicht beantworten. |
| B2 | Wie oft lesen Sie Zeitung online? | Täglich 4- bis 6-Mal pro Woche 2- bis 3-Mal pro Woche Einmal pro Woche Seltener Nie Möchte ich nicht beantworten. |
| B3 | Welche Medien nutzen Sie, um sich über aktuelle Geschehen zu informieren? | (Mehrfachauswahl) Fernsehen Zeitung Radio Soziale Medien Internet Andere:___ Möchte ich nicht beantworten. |
| B4 | Wie hoch ist Ihr Vertrauen in staatliche Institutionen? | Skala von 0–10 (0 = tief, 10 = hoch) Möchte ich nicht beantworten. |
| B5 | Wie häufig nutzen Sie das Internet privat? | Täglich 4- bis 6-Mal pro Woche 2- bis 3-Mal pro Woche Einmal pro Woche Seltener Nie Möchte ich nicht beantworten. |
| B6 | Wie hoch ist Ihre Erwerbstätigkeit in Prozent? | 0–20% 21–40% 41–60% 61–80% 81–100% Möchte ich nicht beantworten. |
| B7 | Welchen Beruf üben Sie gegenwärtig aus? | Freies Textfeld Ich bin nicht erwerbstätig. Möchte ich nicht beantworten. |
| C1 | Bitte geben Sie Ihr Geschlecht an: | Männlich Weiblich Anderes |
| C2 | Bitte geben Sie Ihr Alter in Jahren an: | Freies Textfeld |
| D1 | Haben Sie Fragen/Anmerkungen? | Freies Textfeld |
Notes
[5] Bei der unstrukturierten Rekrutierung werden beispielsweise Personen dem persönlichen Umfeld rekrutiert, ohne im Voraus bestimmte Merkmale oder Eigenschaften festzulegen. Die Studie, welche die Grundlage für diesen Artikel darstellt, wurde im Rahmen einer Abschlussarbeit verfasst.
Konkurrierende Interessen
Die Autoren bestätigen, dass keine konkurrierenden Interessen bestehen.