
Table 1
Participant pool distribution of gender and ethnic background. The task was conducted in English. Native languages besides English included Assamese, Bengali, Gujarati, Hindi, Malayalam, Persian, Spanish, Telugu, and Urdu.
| MALE | FEMALE | CAUCASIAN NON-HISPANIC | HISPANIC/LATINO | ASIAN |
|---|---|---|---|---|
| 80% | 20% | 60% | 10% | 30% |
Table 2
Dataset descriptive statistics.
| AVG. | SD | MIN. | MAX. | |
|---|---|---|---|---|
| Participant age (yrs.) | 24.58 | 4.58 | 19 | 35 |
| Video length (mins.) | 17.00 | 7.00 | 9 | 34 |

Figure 1
Three participants engaged in the Weights Task. Participant #3 (on the right) is taking a block off the scale to try another configuration while Participant #2 (in the middle) wants to clarify the weight of the block under it. Multimodal information is required to make such a judgment.
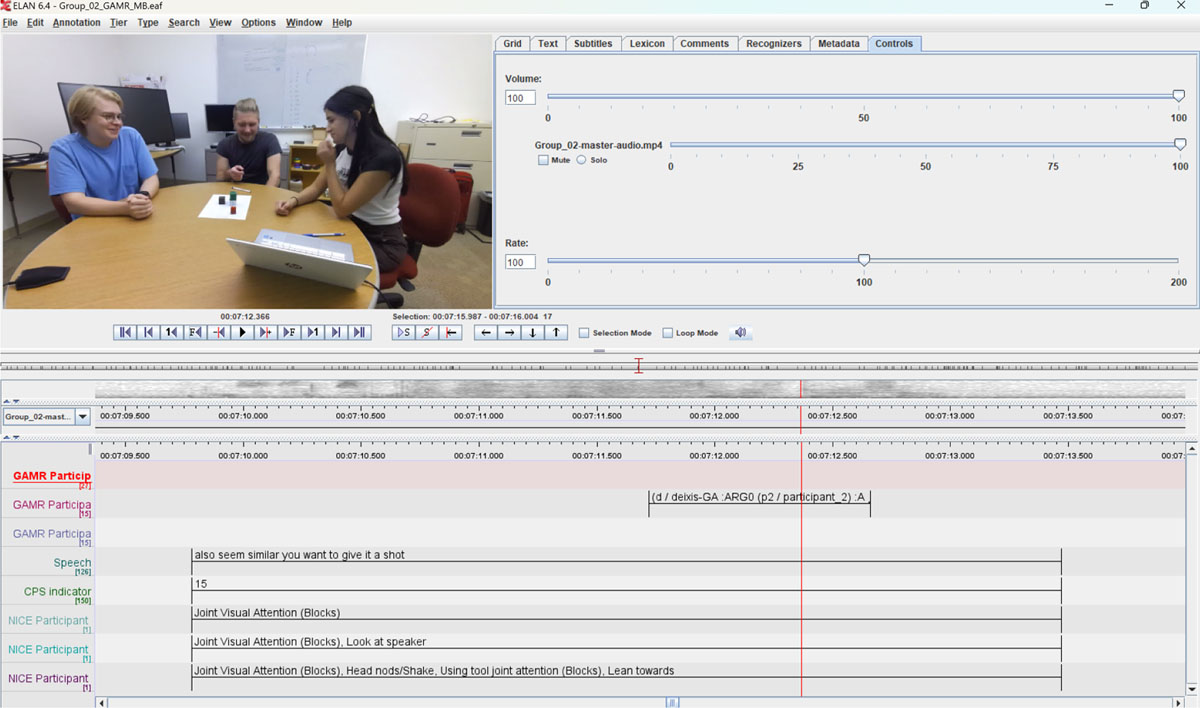
Figure 2
Multichannel (GAMR, NICE, speech transcription, and CPS) annotation “score” using ELAN (Brugman & Russel, 2004).