
(1) Overview
Repository location
JOHD Dataverse: https://doi.org/10.7910/DVN/S6RD4M
Context
The epic poems of Vergil, Ovid, and other major Roman authors contain an extraordinary density of references to earlier Greek and Latin literature. These references encompass a broad array of intertextual relationships, ranging from overt quotation of memorable passages to subtle allusions requiring deep readerly expertise to appreciate. Identifying and interpreting these intertextual parallels constitutes a major activity of Latin literary criticism and is vital to understanding the poems’ compositional artistry and cultural significance (Thomas, 1986; Hinds, 1998). As many parallels involve repetition or adaptation of short phrases, the study of Latin intertextuality is well-suited to computational approaches. Several foundational tools for corpus and intertextual search, including Diogenes, Tesserae, and TRACER, are now standard resources in the field (Heslin, 2019; Coffee et al., 2012; Moritz et al., 2016), and computational intertextual criticism of Latin literature continues to be an active topic of research (Bernstein et al., 2015; Burns 2017; Dexter et al., 2017; Forstall & Scheirer, 2019; Manjavacas et al., 2019). As part of our ongoing work on the quantitative study of Latin intertextuality, we have created a benchmark dataset of intertextual parallels in Latin epic, which can be used for thorough and consistent evaluation of different search methods. The dataset was originally released with the following paper about language models and Latin intertextuality:
Burns, P. J., Brofos, J. A., Li, K., Chaudhuri, P., & Dexter, J. P. (2021). Profiling of Intertextuality in Latin Literature Using Word Embeddings. Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (pp. 4900–4907). DOI: http://doi.org/10.18653/v1/2021.naacl-main.389.
(2) Methods
Steps
The dataset consists of a catalog of textual similarities (intertexts) between the first book of Valerius Flaccus’ Argonautica (VF 1) and other works in the Latin epic tradition. The catalog collates all references to four major Latin epics (Vergil’s Aeneid, Ovid’s Metamorphoses, Lucan’s Bellum Civile, and Statius’ Thebaid) recorded in three modern commentaries on VF 1 (Spaltenstein, 2002; Kleywegt, 2005; Zissos, 2008; Figure 1).
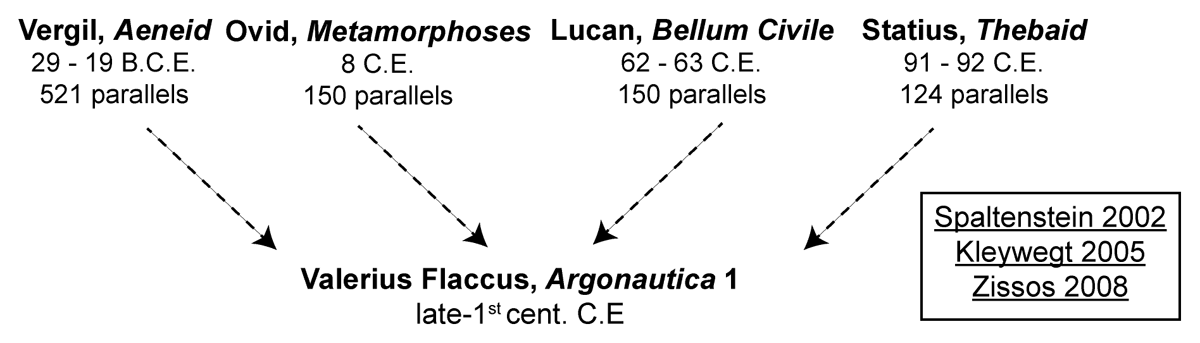
Figure 1
Overview of intertextuality dataset compiled from three commentaries on VF 1.
Since the leading Latin intertextual search tool, developed by the Tesserae Project, analyzes two-word phrases, our dataset follows the same practice for ease of comparison (Coffee et al., 2012). The Tesserae team also corroborated a common intuition among philologists that Latin intertexts frequently occur in the form of two-word phrases. On occasion, however, commentators refer to a single-word intertext or an intertext composed of several words. In these cases, our research team used expert judgment to choose a relevant two-word phrase. These phrases are composed of the key intertextual term plus a natural complement in close proximity (e.g., an adjective-noun, verb-object, or preposition-noun unit).
Our dataset uses the term “query phrase” to indicate a two-word phrase of interest in VF 1 derived from the commentaries and “result phrase” to indicate the two-word comparison phrase likewise derived from the commentaries. The terminology of “query” and “result” is intended to emphasize that the phrases are being deployed in a search and retrieval process that looks outward from VF 1 to a set of comparison texts. This unidirectional process is a technical simplification of human reading, of course, which takes account of multiple texts simultaneously in determining which phrases in any text might be of interest. In other words, a commentator’s choice of lemma can never arise from consideration of a single text in isolation but always emerges from a personal history of reading situated within a broader literary critical and cultural context.
In addition to the list of intertexts, the commentary sources, and the citation information, the dataset also includes three parameters describing the relationship between the phrase in VF 1 and the parallel phrases noted by commentators, which are labeled “Order Free,” “Interval,” and “Edit Distance”. “Order Free” is a binary parameter indicating whether the words comprising the result phrase (i.e., the intertext or parallel phrase) are either adjacent and in the same order as the source phrase (in which case the cell is marked “False”) or non-adjacent or in reverse order (“True”). “Interval” indicates the number of words between the words comprising the result phrase for parallels that are labeled “Order Free;” when the result phrase consists of adjacent words, the interval is zero. For fixed-order searches, the “Interval” column is left blank. “Edit Distance” indicates the number of character substitutions, additions, or deletions required to turn the query phrase into the result phrase. The first two parameters are necessary input data for the method of semantic intertextual search described in our original paper (Burns et al., 2021). The same parameters plus the edit distance parameter are required for another tool, Fīlum, which we developed to identify phonetically similar phrases (Chaudhuri et al., 2015; Chaudhuri & Dexter, 2017; see Reuse Potential for further discussion).
Sampling strategy
Select intertextual parallels previously recorded in the commentaries of Spaltenstein (2002), Kleywegt (2005), and Zissos (2008) were included in the dataset. No new parallels were added.
Quality control
All entries in the dataset were reviewed by multiple members of the project team for completeness and accuracy.
(3) Dataset Description
Object Name
vf_intertext_dataset_2_0.csv
Format names and versions
CSV
Creation dates
Start date: 2014–07–01
End date: 2023–08–31
Dataset creators
The dataset was created by Joseph P. Dexter, Pramit Chaudhuri, Patrick J. Burns, Elizabeth D. Adams, Thomas J. Bolt, Adriana Cásarez, Jeffrey H. Flynt, Kyle Li, James F. Patterson, Ariane Schwartz, and Scott Shumway.
Language
The language of entries in the dataset is Latin. The language of the metadata is English.
License
CC0 1.0
Repository name
JODH Dataverse
Publication date
The dataset was published on 2023–09–04.
(4) Reuse Potential
The dataset presented here provides a resource for researchers investigating intertextuality in historical language traditions, especially Latin. For philologists pursuing qualitative studies, the catalog assembles in a single source a systematic list of intertextual parallels between VF 1 and several major Latin epic poets who either influenced or were influenced by Valerius Flaccus. The availability of three modern, high-quality philological commentaries attests to the fact that this particular text is an especially rich model of intertextual relationships. The collation from multiple sources, furthermore, enables researchers to analyze the practices of modern philologists, in particular the patterns of reference and degree of overlap among the commentators. Such reuse could involve qualitative review of recorded intertexts, as well as quantitative and statistical analysis of the entire dataset. For instance, although the total number of parallels recorded by each commentator differs substantially (Kleywegt 757, Zissos 373, Spaltenstein 228), it is striking that the distribution over comparison texts is fairly consistent, with the Aeneid referred to most often (55–64%) and Ovid (7–17%), Lucan (17–18%), and Statius (11–13%) each referred to with approximately similar frequency.
Perhaps the greatest future potential, however, lies in the use of the dataset as a benchmark for testing intertextual search methods. This use case was already exemplified in the original paper (Burns et al., 2021), which compared lemma matching and semantic scoring using word embeddings as two complementary approaches to Latin intertextual search. The addition of the edit distance parameter in the revised dataset now facilitates evaluation of search methods based on character similarity, such as Fīlum.
To illustrate this kind of reuse potential, we used the dataset to conduct a large-scale validation analysis of Fīlum. In prior work, we applied Fīlum to a variety of case studies involving intertextuality in classical and post-classical Latin literature (Chaudhuri et al., 2015; Chaudhuri and Dexter, 2017), but we have not previously validated the performance of the tool at scale. We ran book-level Fīlum searches for all 945 intertexts in the dataset using the three parameters recorded therein (“Order Free,” “Interval,” and “Edit Distance”). To summarize these results, we calculated the precision@k and recall@k across a range of cutoffs (k = 1, 3, 5, 10, 25, 50, 75, 100, and 250), which are the metrics we used to validate the semantic search method (see Burns et al., 2021 for details). As shown in Figure 2, Fīlum outperforms semantic search in both precision and recall; more than half of all intertexts can be recovered with no off-target results, and more than 90% can be recovered with at most 250 off-target results. One example of the type of intertext pair well-suited to discovery using phonetic search (but not semantic search) is patuere doli (“his deceptions were revealed,” VF 1.64) and [nec] latuere doli (“deceptions did [not] escape the notice,” Aeneid 1.130). Although the phrases are phonetically very similar – only a single character (p/l) distinguishes them – they are semantically distinct; the two verbs are almost antonymic. As a consequence, the similarity score for the pair calculated from word embeddings is not especially high, which contrasts with the very low edit distance and, therefore, the absence of off-target results in a Fīlum search.
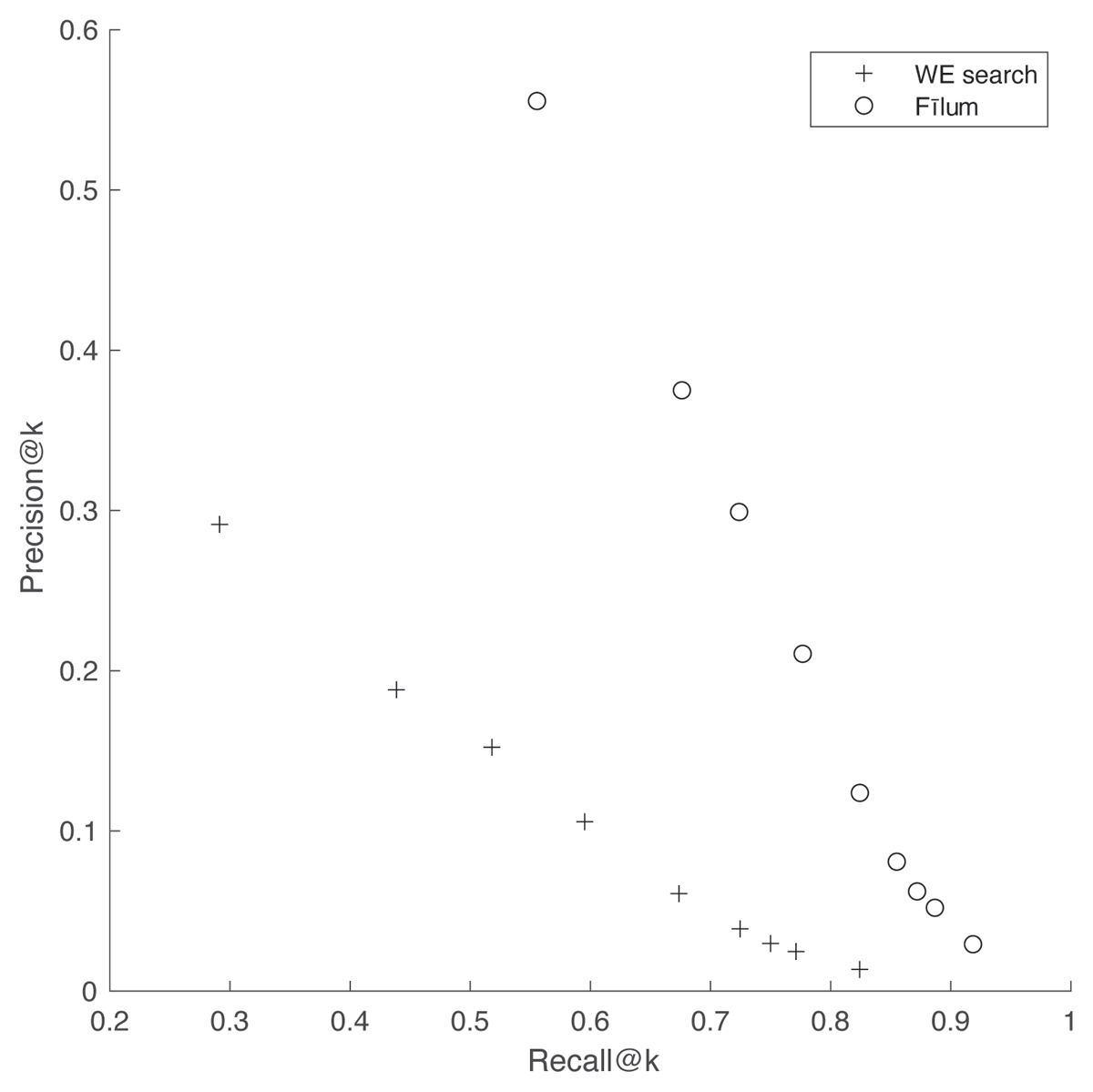
Figure 2
Precision@k and recall@k for Fīlum and semantic search on the full VF 1 dataset. The semantic search data are reprinted from Burns et al., 2021.
Acknowledgements
We thank James A. Brofos, Jorge A. Bonilla Lopez, Tathagata Dasgupta, and Nilesh Tripuraneni for their contributions to our ongoing research on Latin intertextuality, and Neil Coffee and the Tesserae Project team for helpful discussions about intertextuality benchmarking.
Funding Information
This research was conducted under the auspices of the Quantitative Criticism Lab (www.qcrit.org) and was supported by a National Endowment for the Humanities Digital Humanities Start-Up Grant (grant no. HD-248410-16), a National Endowment for the Humanities Digital Humanities Advancement Grant (grant no. HAA-271822-20), an American Council of Learned Societies Digital Extension Grant, and a Neukom Institute for Computational Science CompX Faculty Grant. JPD was supported by a Neukom Fellowship and a Harvard Data Science Fellowship, and PC was supported by a New Directions Fellowship from the Andrew W. Mellon Foundation.
Competing interests
PJB is guest editor of the special collection Representing the Ancient World through Data and a member of the editor board for JOHD; he did not take part in the editorial process pertaining to this manuscript. All other authors have no competing interests.
Author Contributions
Joseph P. Dexter: Conceptualization, Data Curation, Formal Analysis, Funding Acquisition, Investigation, Methodology, Project Administration, Resources, Software, Supervision, Validation, Visualization, Writing – Original Draft, Writing – Review & Editing.
Pramit Chaudhuri: Conceptualization, Data Curation, Formal Analysis, Funding Acquisition, Investigation, Methodology, Project Administration, Resources, Software, Supervision, Validation, Visualization, Writing – Original Draft, Writing – Review & Editing.
Patrick J. Burns: Conceptualization, Data Curation, Formal Analysis, Investigation, Methodology, Project Administration, Resources, Software, Supervision, Validation, Visualization, Writing – Review & Editing.
Elizabeth D. Adams: Data Curation, Formal Analysis, Investigation, Validation, Writing – Review & Editing.
Thomas J. Bolt: Data Curation, Formal Analysis, Investigation, Validation, Writing – Review & Editing.
Adriana Cásarez: Data Curation, Formal Analysis, Investigation, Validation, Writing – Review & Editing.
Jeffrey H. Flynt: Conceptualization, Data Curation, Investigation, Methodology, Software, Validation, Visualization.
Kyle Li: Data Curation, Formal Analysis, Investigation, Methodology, Software, Validation.
James F. Patterson: Data Curation, Formal Analysis, Investigation, Validation, Writing – Review & Editing.
Ariane Schwartz: Data Curation, Formal Analysis, Investigation, Validation, Writing – Review & Editing.
Scott Shumway: Conceptualization, Data Curation, Investigation, Methodology, Software, Validation, Visualization.