
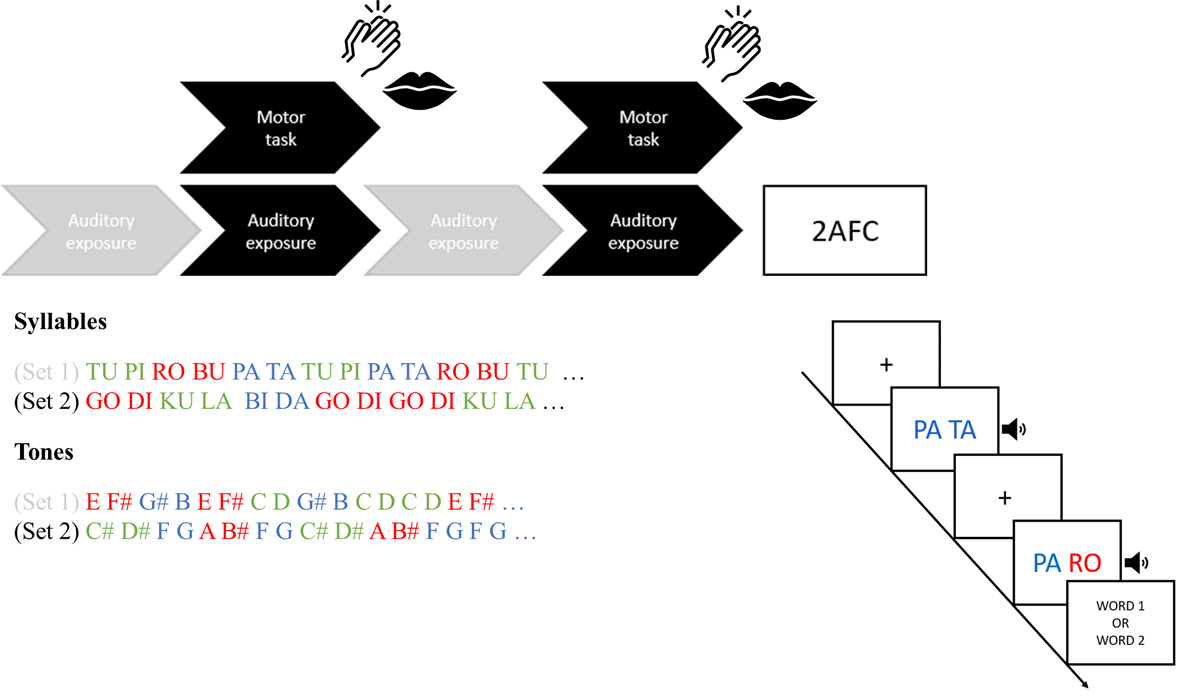
Figure 1
Experimental Design.
Experimental protocol. In all three experiments, participants listened to clips of two different structured auditory streams in alternating order. Statistical learning of the hidden structures was tested afterwards via a 2AFC recognition test. In Experiment 1, participants listened to structured syllable streams (syllables set 1 and 2). They were instructed to continuously whisper the speech sound ‘tah’ (speech motor task) or clap hands (non-speech motor task) during the clips of one stream (black). During the clips of the other stream (grey), they were not instructed to perform an additional motor task (only listen). In Experiment 2, participants listened to structured speech (syllables set 1 and 2) or structured non-speech (tones set 1 and 2). They concurrently performed the speech motor task (whispering ‘tah’) during the clips of one stream (black) and only listened to the clips of the other stream (grey). In Experiment 3, participants listened to one structured speech stream (tones set 1 or 2) and one structured syllable stream (syllables set 1 or set 2). No motor task was performed in Experiment 3. Following the exposure phase, participants across all three experiments completed a 2AFC recognition task to measure SL of the sound structures.
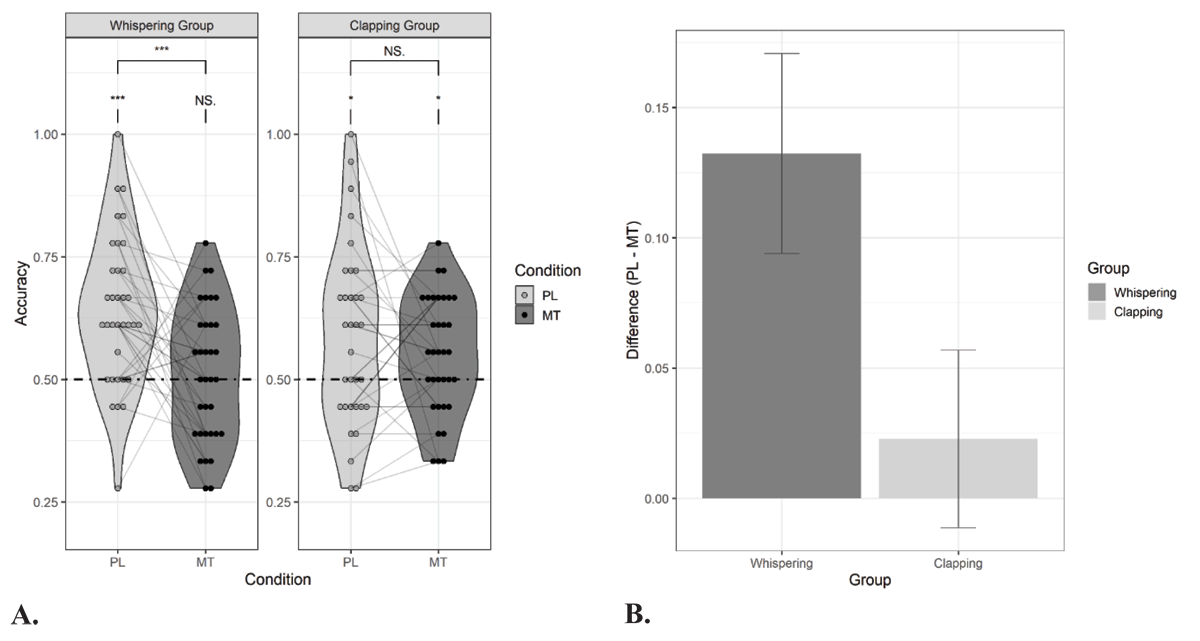
Figure 2
Performance in the forced-choice recognition task in Experiment 1.
Panel A: Proportion correct responses for speech duplets that were presented under a passive listening (PL) and motor task (MT) condition during exposure. Thirty-four participants performed a concurrent speech motor task (whispering) and thirty-four participants performed a concurrent non-speech motor task (clapping). The dashed line indicates chance level performance. Asterisks denote significance for one-sample t-tests and paired t-tests: *p < .05, **p < .01, ***p < .001, NS. = non-significant. Panel B: The effect of the motor task on statistical learning (i.e., accuracy for passive listening condition – accuracy for motor task condition) for both the whispering group and clapping group.
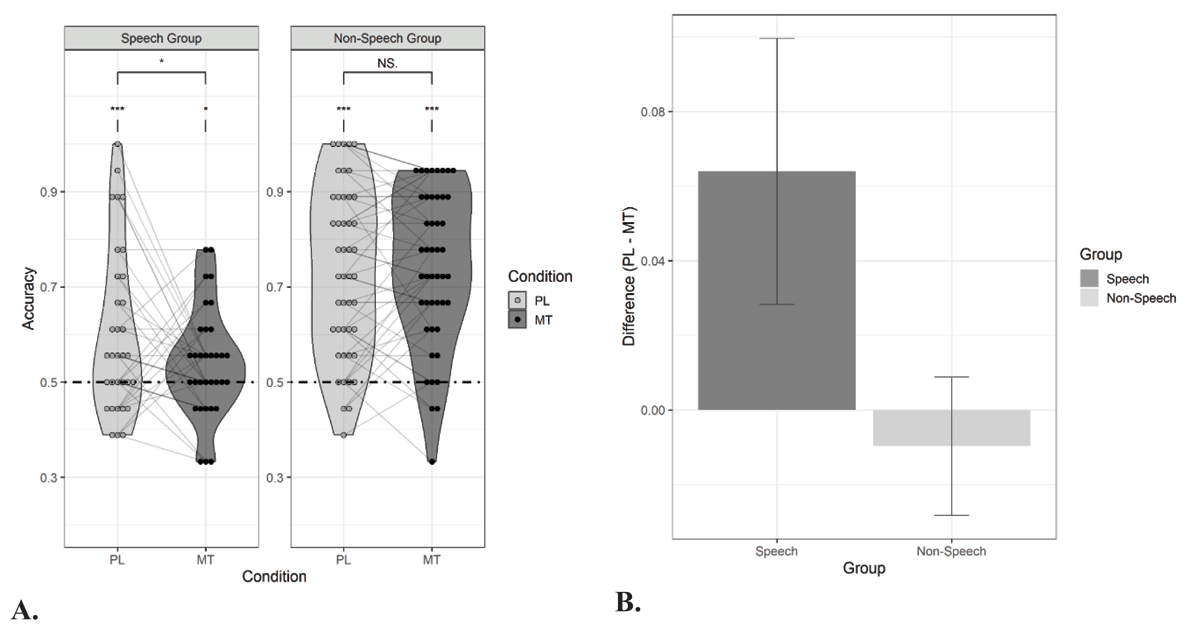
Figure 3
Performance in the forced-choice recognition task in Experiment 2.
Panel A: Proportion correct responses for sound duplets that were presented under passive listening (PL) and motor task (MT) conditions during exposure. In Experiment 2, the motor task condition was the same for both groups, namely whispering the syllable ‘tah’. Thirty-three participants listened to duplets of syllables (Speech Group) and forty-six participants were exposed to tone duplets (Non-Speech Group). The dashed line indicates chance level performance. Panel B: Visualization of the suppressive effect of the motor task on statistical learning (i.e., accuracy for passive listening condition – accuracy for motor task condition, here whispering) for both the Speech group and Non-Speech group. Asterisks denote significance for one-sample t-tests and paired t-tests: *p < .05, **p < .01, ***p < .001, NS. = non-significant.