
1 Introduction
Many research funding agencies now require a data management plan (DMP) as part of the grant application process or as an early deliverable (National Science Foundation, 2024; European Commission, 2024c; Eindhoven University of Technology Library, 2024). While these plans typically contain similar content, their structure varies significantly across funders, creating challenges for researchers who must adapt their submissions accordingly (Jones et al., 2019; ELIXIR, 2024a). This lack of standardization complicates not only the initial creation of DMPs, but also their reuse, their adaptation to new requirements, and long-term maintenance throughout the project lifecycle.
In practice, researchers often revise and reuse earlier DMPs, but evolving funder policies, legal regulations (e.g., GDPR), and shifting project requirements can necessitate significant rework. When funding proposals are rejected and resubmitted elsewhere, the same DMP content must often be restructured to fit a new template. During the execution of a funded project, DMPs must also be updated to reflect changes in data, licensing, or storage. These updates are difficult to manage with traditional document-based approaches.
Moreover, evaluating DMPs remains a largely manual task (Miksa et al., 2023). Reviewers must read and interpret free-text documents to verify compliance, structure, and data stewardship practices. This process is time-consuming and difficult to scale. Overall, the current approach lacks flexibility, is hard to update, and cannot support automation.
To address these challenges, we propose a modular, ontology-based framework that supports versioning, customization, and semi-automated processing of DMP content. Instead of static documents, our approach produces structured, interoperable artifacts that evolve alongside requirements while remaining human-readable and machine-interpretable. The solution is designed to support researchers, data stewards, and funding organizations alike.
To illustrate its practicality, we include a step-by-step case study based on real-world DMP templates from Horizon Europe and Science Europe. This demonstration shows how organizations can transition from document-based processes to structured workflows, and how domain-specific requirements (such as those in clinical trials) can be seamlessly accommodated without affecting core components.
Although our primary focus is data stewardship, the framework has broader applicability for other domains that rely on structured, evolving documents.
2 Goals and Research Objectives
This study aims to develop a structured framework (G1), to implement it (G2), and to demonstrate its applicability through a real-world case study (G3). To achieve these goals, we define a set of focused research objectives that address key technical and organizational challenges in data stewardship. These objectives target specific problems that must be solved to realize a modular and evolvable approach to data management planning. Based on feedback from researchers and data stewards, we identified practical issues—some long-standing, others newly emerging—that affect both the research community and funding agencies. These insights directly informed the formulation of our research objectives, which aim to close critical gaps in current data stewardship practices.
Research Objectives:
RO1: Addressing Evolving Requirements
– Challenge: DMPs must adapt to evolving legal, ethical, and policy requirements (e.g., GDPR or changes in Horizon Europe templates).
– Need: An efficient mechanism that allows researchers to migrate existing DMPs to updated versions with minimal effort and modifications.
RO2: Accommodating Domain-Specific and Organizational Needs
– Challenge: While some DMP elements apply broadly, others vary significantly across disciplines and funding agencies. For example, certain requirements may be less relevant in social sciences but critical in life sciences. Additionally, funding agencies may wish to tailor standard DMPs to align with their branding and policies.
– Need: A flexible system for customizing DMP templates while allowing for shared components to prevent duplication and inefficiencies.
RO3: Facilitating Seamless Migration Between Templates
– Challenge: Researchers often need to reformat a DMP when transitioning between funding agencies, such as when an initial grant application is unsuccessful. A major difficulty is ensuring that as much information as possible is preserved without the need for extensive manual rewriting.
– Need: A structured mechanism that enables the seamless migration of DMPs between different templates with minimal modifications (e.g., from Science Europe to Horizon Europe).
RO4: Enabling Semi-Automated or Fully Automated DMP Evaluation
– Challenge: DMPs are traditionally written for human reviewers, which makes them difficult to assess automatically. As a result, funding bodies must manually evaluate hundreds of DMPs to check for structure, completeness, or even licensing strategies. This process is resource-intensive and can significantly slow down decision-making.
– Need: A machine-readable DMP format that allows automated or semi-automated evaluation based on predefined metrics, reducing the workload on funding bodies while improving assessment quality.
RO5: Enhancing Data Management Through Embedded Guidance
– Challenge: Many researchers lack formal training in data management. As a result, DMPs should not only document best practices but should also serve as a guiding tool to help researchers make informed decisions about data preservation and reuse. This is particularly crucial for early-career researchers who are unfamiliar with DMP requirements.
– Need: An integrated guidance system that prompts relevant questions and assists in crafting effective DMPs, and that serves as a knowledge substitute for experienced colleagues and improves overall data stewardship practices.
3 Theoretical Background and Related Work
This section introduces the theoretical foundations of our work, focusing on data stewardship and the principles of Normalized Systems Theory (NST) to support modular and evolvable system design.
3.1 Data Stewardship
Data stewardship has been defined in various ways. Rob Hooft describes it as “the responsible planning and execution of all actions on digital data before, during, and after a research project, with the aim of optimizing the usability, reusability, and reproducibility of the resulting data” (Hooft, 2024). Effective data stewardship ensures that research data remain accessible, interpretable, and reusable, contributing to long-term knowledge preservation and reproducibility.
3.1.1 Data Management Plan
A crucial component of data stewardship is the planning process, which leads researchers to develop a DMP. A DMP is a formal document that outlines how research data will be managed throughout its lifecycle (Stanford University Libraries, 2024). This includes considerations such as data description, file formats, storage, access policies, and publication strategies. Beyond its role in the initial planning phase, a DMP serves as a dynamic document that evolves throughout and beyond the research project. As research progresses, updates are necessary to accommodate changes in project scope, data collection methods, or compliance requirements (ELIXIR, 2024b).
3.1.2 Tools for Data Management Planning
While researchers are often required to create DMPs from scratch, several tools exist to streamline this process. These tools offer similar core functionalities but differ in terms of the templates they provide and the specific requirements they address. A comparative analysis of these tools is available in Jones et al. (2019). The primary purpose of these tools is to simplify the integration of standardized templates and regulatory requirements.
Typically, users select a template endorsed by their funding body, which ensures compliance with institutional or grant-specific guidelines. The tool then structures the document accordingly and guides users through the process of completing predefined sections. Some tools offer text-based input fields, while others employ structured forms to collect relevant information.
For comparative analysis, we selected DMPOnline and Argos, two widely tools recommended by the European Commission under the Horizon Europe Programme Guide (European Commission, 2025). These tools serve as benchmarks for evaluating the effectiveness and adaptability of our proposed solution.
Existing tools often rely on static templates with limited automation or reuse. To address these gaps, recent initiatives have proposed machine-actionable DMPs that are based on semantic technologies and linked data (Research Data Alliance, 2024; Miksa et al., 2018; Cardoso et al., 2020), and that aim to improve interoperability and sustainability in data stewardship.
3.2 Normalized Systems Theory
NST (Mannaert et al., 2016) provides a framework for designing evolvable systems by minimizing combinatorial effects, where the effort to implement changes increases disproportionately with system size (Mannaert et al., 2012). Originally developed for enterprise information systems (Oorts et al., 2014), NST has since been applied to fields such as requirements engineering (Verelst et al., 2013), study program design (Oorts et al., 2016), and business modeling (Van Nuffel, 2011).
NST emphasizes modularity as a foundation for evolvability, and advocates for highly cohesive and loosely coupled components (Mannaert et al., 2016). It defines four principles to ensure system adaptability:
Separation of Concerns – The principle emphasizes the need to separate distinct components within a system.
Data Version Transparency – The principle ensures parameters can be updated without disrupting the processing function.
Action Version Transparency – An invoked action should be modifiable without disrupting the caller.
Separation of State – When invoking an action, its state should remain separate.
Expanders are automation tools that convert structured system models into code, ensuring modularity and adaptability. By generating consistent implementations from predefined rules, they minimize manual coding effort and prevent combinatorial effects, allowing seamless updates as requirements change.
NST provides a structured approach to system evolvability by eliminating combinatorial effects through modularity. While originally focused on software, its principles have proven valuable in broader disciplines, enabling scalable and maintainable system designs.
4 Theoretical Foundation
This section establishes the theoretical foundation for our framework by explicitly adapting and contextualizing key theorems and principles from NST (Mannaert et al., 2016) to our specific use case. Rather than applying them directly, we reinterpret these concepts to suit the structure and challenges of data management planning. Focusing on stability and modularity, we introduce the virtual unit Unit of Work (UW) to demonstrate the necessity of modularity. We validate the relevance of Separation of Concerns and Data Version Transparency while excluding Action Version Transparency and Separation of State as non-applicable, as in (Oorts et al., 2017; Suchánek and Pergl, 2018). This section is divided into two parts: acquiring and presenting knowledge, each addressed systematically.
4.1 Knowledge Acquisition
Our framework gathers user information through a question-answering system, using predefined questions to generate a human-readable document. These questions stem from a domain ontological model, which defines the document’s content. This section explores how changes affect the domain ontological model.
4.1.1 Stability
A core principle of NST is stability, derived from Systems Theory, which states that a bounded change should have a bounded impact (Mannaert et al., 2016). In our context, stability requires that a bounded change in a class within the domain ontological model results in a similarly bounded effect on the questions. Otherwise, as the number of classes and questions grows, changes could become unbounded, making their impact dependent on system size rather than the change itself.
4.1.2 Modularity
NST and Modularization
NST emphasizes modular design to maximize reuse. The key principle is that while development and maintenance efforts grow linearly, the number of possible module combinations—and their benefits—increase exponentially. Minimizing module coupling is crucial, as interdependencies complicate maintenance. Effective partitioning ensures modules remain independent, preserving modularity’s advantages.
To reduce effort, common elements (e.g., funder entity) are extracted into reusable modules instead of duplicating them across domain ontological models. This avoids redundant work and improves efficiency.
Proof
The proof highlights the need for modularization by comparing its impact on system evolution effort. Using UW as a unit of effort, we quantify tasks such as adding properties to a class. Consider the following example, in which we need to expand information on a funder entity across five domain ontological models.
Without Modularization
Each update to a funder entity in three domain models requires separate modifications. If one update costs , the total cost is: .
With Modularization
The update is made once in a shared module, fixing the effort at regardless of the number of models.
Conclusion
Under the assumption of unlimited system evolution (Mannaert et al., 2016), domain ontological models can grow indefinitely. In non-modularized systems, each addition or change increases workload exponentially, whereas modularization keeps it manageable and predictable. This highlights the efficiency and scalability of modular design in evolving systems.
4.1.3 Separation of Concerns
The Separation of Concerns principle advocates dividing a system into distinct components, each addressing a single concern. Every component should have a single change driver, ensuring modifications in one area do not impact unrelated parts.
In our work, this principle dictates that each module contains only one class from the domain ontological model, ensuring stability and independence.
Theorem 1 A module must contain only one class from the domain ontological model to maintain stability.
Proof
Let module include two classes, and . Suppose has one version, while evolves into versions (Figure 1).
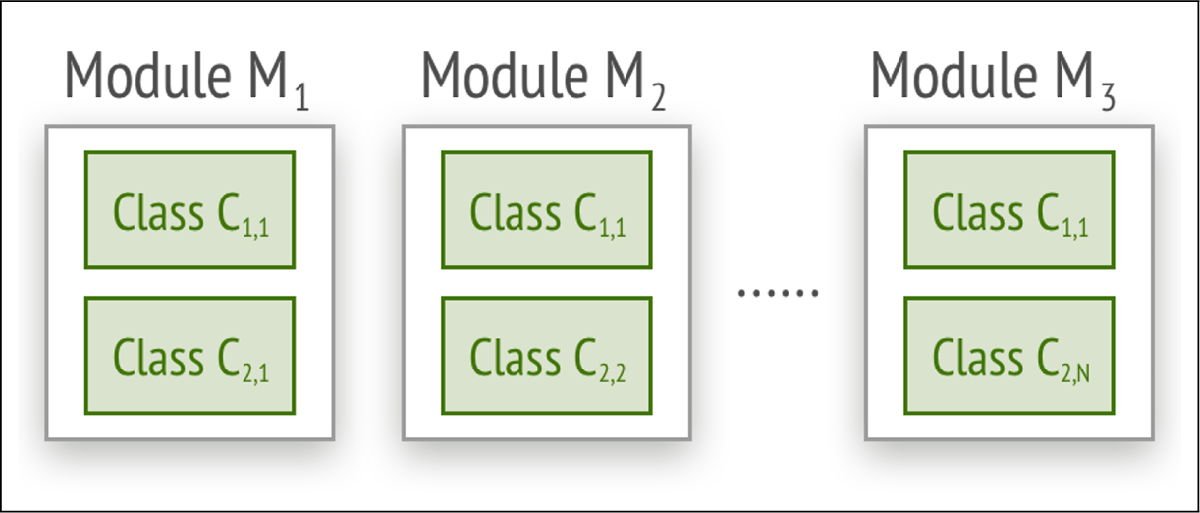
Figure 1
Separation of Concerns: Schematic representation of one module with two classes and multiple versions.
If updates from to , all versions of must integrate this change. Given the assumption of unlimited system evolution, grows unbounded, leading to an unbounded impact from changes in .
Thus, a module containing multiple classes cannot ensure system stability.
4.1.4 Data Version Transparency
Data Version Transparency ensures that parameter updates do not affect a function’s processing. In our case, this principle allows a class in the domain ontological model to be updated without impacting others.
Theorem 2 A class in the domain ontological model must exhibit data version transparency to maintain stability.
Proof
Let property of class be used in domain ontological models, denoted as for (Figure 2).
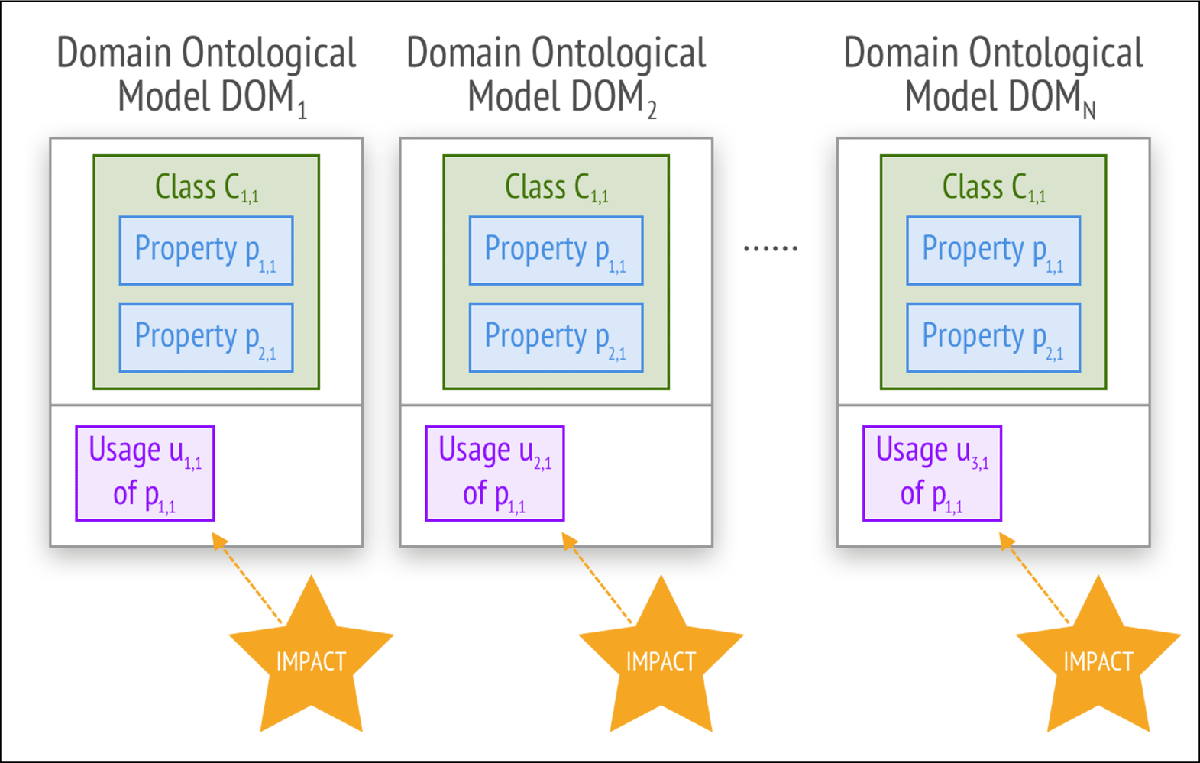
Figure 2
Data Version Transparency: Representation of domain ontological models using class .
If updates to , class upgrades to . Without data version transparency, all domain models require an upgrade, resulting in new versions.
By the assumption of unlimited system evolution, grows unbounded, making modifications unmanageable. Thus, changes should be independent of usage to ensure stability.
4.2 Knowledge Presentation
This section focuses on knowledge presentation, using the term Data Component to describe an entity that defines how data from the domain ontological model is displayed. It examines how changes in the model affect these components. Since the principles, theorems, and proofs align with those in Knowledge Acquiring, this section applies them to data components. This work also builds on insights from a previous publication (Slifka et al., 2023), which was co-authored with Jan Slifka.
4.2.1 Stability
Building on the previous section, a bounded change in a domain ontological model class should have a limited impact on data components (Slifka et al., 2023). Otherwise, as classes and data components grow, changes could become unbounded.
4.2.2 Modularity
As with Knowledge Acquiring, we aim to reduce template development and maintenance effort. To avoid duplication, templates should be divided into separate data components. Without this modularization, workloads scale with the number of templates, reducing efficiency.
4.2.3 Separation of Concerns
In our approach, each data component is limited to a single class from the domain ontological model to ensure stability and independence.
Theorem 3 A data component must contain only one class from the domain ontological model to maintain stability (Slifka et al., 2023).
Proof
Let be a data component containing two classes, and . While has a single version at a time, evolves into versions.
If upgrades from to , it must be integrated into all versions of . Under the assumption of unlimited system evolution, grows unbounded, causing an unbounded increase in versions and impacting accordingly.
Thus, a data component with multiple classes cannot ensure long-term system stability.
4.2.4 Data Version Transparency
In our context, modifying a class in the domain ontological model should not impact data components.
Theorem 4 A class used in data components must exhibit data version transparency to ensure stability (Slifka et al., 2023).
Proof
Let property of class be used in data components, denoted as for .
If updates to , class upgrades to . Without data version transparency, all data components require updates, leading to new versions.
By the assumption of unlimited system evolution, grows unbounded, making modifications unmanageable. Thus, the upgrade’s impact depends on both the change itself and its expanding use in data components.
5 Our Solution
This section presents our approach to enhancing data stewardship planning through structured, modular, and automated transformations. The solution is built on a domain ontological model, which defines structured information, leading to the generation of a knowledge model for user interaction. User responses are transformed into machine-readable outputs and document templates, enabling automated evaluation and document generation.
The workflow involves multiple transformations, from structuring domain concepts to processing user input and generating documents. The overall process is illustrated in Figure 3.
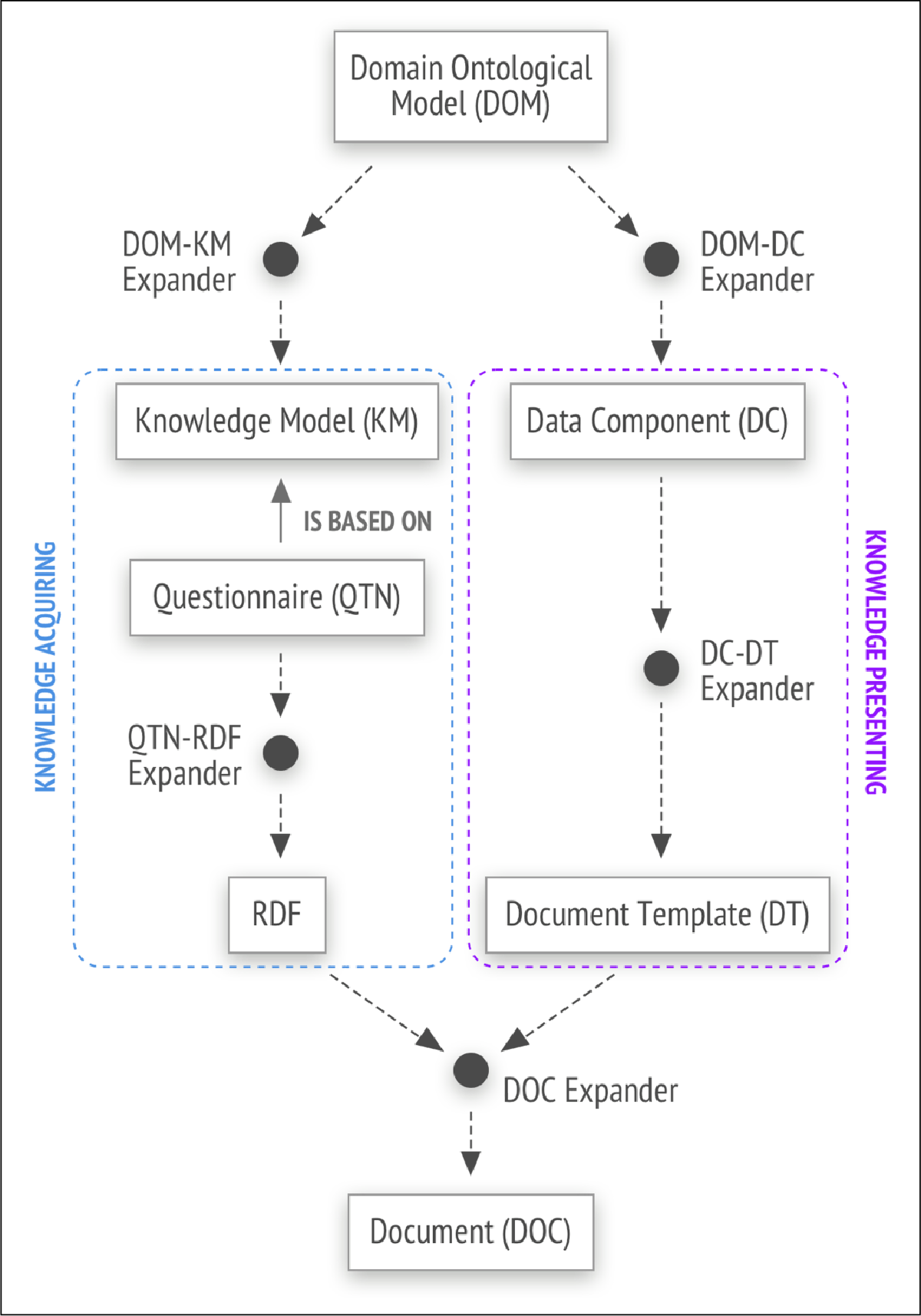
Figure 3
Transformation Workflow: From Domain Ontological Model to Final Document.
Our approach is based on previous findings published by ourselves (Knaisl and Pergl, 2022) and together with Jan Slifka (Slifka et al., 2023).
5.1 Components
Our solution builds on five main components: the domain ontology, knowledge model, questionnaire, data components, and document template.
Domain Ontological Model: This is defined using OWL (Web Ontology Language), which is a standard formalism for representing structured knowledge in a machine-readable way. This enables automated processing, reuse, and alignment with linked data principles.
Knowledge Model: The knowledge model organizes questions into a hierarchical structure (e.g., chapters, sections), and specifies their types. Supported question types include:
Value Question: Retrieves a single value (e.g., URL, date, number, or text).
Options Question: Provides predefined choices, with the possibility of triggering follow-up questions.
Multi-Choice Question: Allows the selection of multiple options without follow-up questions.
List of Items Question: Captures structured data, such as metadata for multiple datasets.
Integration Question: Similar to a value question but with predefined answers from an external service.
Questionnaire: A questionnaire is an instance of the knowledge model storing user responses in a structured format. Each response follows a hierarchical path, ensuring clarity in data organization. Examples include:
<chapter>.<question>
<chapter>.<question>.<subquestion>
<chapter>.<question>.<item>.<subquestion>
<chapter>.<question>.<answer>.<subquestion>
Data Components and Document Template: Data components serve as an intermediate layer that defines how questionnaire responses should be structured and visualized. Described in the Resource Description Framework (RDF) using the View Ontology (Slifka, 2025), they support reuse and customization. Document templates, implemented in Jinja2 (Pallets, 2024), are then automatically generated from these components. It, along with the RDF output from the questionnaire, serves as an input for document generation.
5.2 Domain Ontological Model Transformation
This subsection outlines the transformation of a domain ontological model into a knowledge model and data components.
5.2.1 Transformation to Knowledge Model
The transformation converts the domain ontological model into the knowledge model :
where consists of classes, object properties, or datatype properties. The transformation ensures a lossless mapping, embedding identifiers as annotations to facilitate machine-actionable outputs. Tables 1, 2, 3 illustrate the transformation of inputs into knowledge model constructs .
Transformation of Classes.
| ONTOLOGY | KNOWLEDGE MODEL | DESCRIPTION |
|---|---|---|
| Class | List of items question | Direct mapping |
| Class identifier | Question title | Extracted from URI and formatted |
| Comment | Question description | Directly copied |
| Object property | Child question | Converted to sub-questions |
| Datatype property | Child question | Converted to value questions |
Table 2
Transformation of Object Properties.
| ONTOLOGY | KNOWLEDGE MODEL | DESCRIPTION |
|---|---|---|
| Object property | Child of list question | Defines parent-child relationships |
Table 3
Transformation of Datatype Properties.
| ONTOLOGY | KNOWLEDGE MODEL | DESCRIPTION |
|---|---|---|
| Datatype property | Value question | Direct conversion |
| Class identifier | Question title | Extracted from URI |
| Comment | Question description | Directly copied |
Handling Changes in the Domain Ontological Model
To accommodate updates in the domain ontological model, the transformation process must include a migration mechanism that adapts modifications into the knowledge model. The simplest approach is to compare the existing and updated models, generating structured updates as required.
5.2.2 Transformation to Data Components
Transformation maps the domain ontological model to data components:
This transformation is semi-automated, allowing users to define the document structure while adhering to modularity principles.
Each ontology class should correspond to a single data component.
Information from separate classes should not be mixed within a single data component.
A predefined data component structure can be generated automatically to enforce modularity. However, minor deviations may be necessary for specific use cases. While such cases are expected to be infrequent, they should be minimized to maintain long-term system sustainability.
Handling Changes in the Domain Ontological Model
If users modify the data component structure, integrating updates from the ontological model becomes more complex. A potential solution is to generate a new structure and to compare it to the modified version. A supporting tool could assist in the detection of missing or changed attributes, though updating data components remains a more manual process than migrating the knowledge model.
5.3 Knowledge Model Metamodel Evolution
Each knowledge model is built according to a specific metamodel, which defines the available question types, their attributes, and their structural rules. The metamodel functions as a schema or blueprint for the construction of consistent and interpretable knowledge models across different use cases. As system requirements evolve (e.g., to support new question types or additional metadata), the metamodel itself must also evolve. This introduces a need to migrate existing knowledge models to remain compatible with the latest version of the metamodel. The migration process updates a knowledge model based on metamodel to a new version based on metamodel :
While migration can be bidirectional, reverting to a previous metamodel may result in data loss, particularly if constructs or attributes have been removed. Each migration must be defined separately to ensure consistency across different knowledge models.
5.4 Questionnaire Evolution
Since each questionnaire relies on a specific version of the knowledge model, updates to the model require migration of corresponding questionnaires. The migration process transitions a questionnaire based on knowledge model to based on :
This process is semi-automated, which assists researchers in reviewing and preserving as much data as possible. Changes are categorized as:
New Question
Modified Question
Moved Question
As migration is not lossless, reverting to an earlier knowledge model version may result in missing data, especially if questions were removed.
5.4.1 Sanitization
To maintain consistency, the migration process implements the following sanitization steps:
Remove replies if the corresponding question, answer, or choice no longer exists in the updated knowledge model.
Adjust replies when a question type changes (e.g., value to integration), following the mapping rules in Table 4.
Update reply paths if a question is moved, ensuring responses are correctly linked to the new structure.
Table 4
Question Type Changes: Reply Handling.
| ORIGINAL TYPE | TARGET TYPE | ACTION |
|---|---|---|
| Value Question | Integration Question | Preserve original value |
| Value Question | Other types | Remove reply |
| Options Question | Other types | Remove reply |
| Multi-Choice Question | Other types | Remove reply |
| List of Items Question | Other types | Remove reply |
| Integration Question | Value Question | Preserve original value |
By applying these mechanisms, the migration process minimizes disruptions while ensuring compatibility with updated knowledge models.
5.5 Questionnaire Transformation
The questionnaire transformation serves two purposes: (1) generating documents and (2) enabling automated or semi-automated DMP evaluations. The transformation process, defined as:
where is the filled questionnaire, is the knowledge model, and is the resulting structured output.
The transformation is nearly lossless and bi-directional, allowing re-importation of exported data if needed. However, item order in list-based questions is not preserved. It is fully automated, utilizing embedded annotations within the knowledge model to map questions to the domain ontological model.
5.5.1 Mapping
Two types of annotations are used:
rdfType: Links list and value questions to ontology classes or datatype properties.
rdfRelation: Defines relationships between list questions and their child elements.
For example, rdfRelation may map a dataset-related question to its parent DMP structure. This structured approach ensures accurate transformation while maintaining machine-actionability.
5.6 Data Component to Document Template Transformation
Data components can be expanded into various software primitives through automated transformation. The process maps data components to platform-specific structures and is one-directional, meaning transformations cannot be reversed without information loss.
where are data components, are any applied customizations, and is the generated document template. We utilize an expander to transform data components into Jinja2-based templates, which allows structured document generation from questionnaire responses.
5.6.1 Customization Retention
As document templates may require branding elements, styles, or structural modifications, a mechanism to retain customizations during re-expansion is needed. Inspired by modular system principles, our approach preserves user modifications by harvesting custom subsections before re-expansion and reinserting them afterward.
5.6.2 Mapping Rules
Data components are mapped to Jinja2 macros using predefined rules:
Content elements (e.g., Email, Date, URL) are directly printed.
Containers display child elements.
Iterative containers render repeated content (e.g., datasets).
Conditional elements select content based on predefined logic.
Headings adjust dynamically based on content hierarchy.
Each macro includes designated subsections for customizations, which ensures modifications persist across re-expansions.
5.7 Document Transformation
The final transformation generates the structured document:
where is the structured questionnaire output, is the document template, and is the resulting document.
As content formatting is applied without preserving the original structure, the transformation is one-directional. Unlike direct questionnaire rendering, our approach processes structured outputs using Jinja2 filters, which enables flexible document generation.
6 Reference Implementation
To demonstrate the technical feasibility of our approach, we implemented a prototype based on the Data Stewardship Wizard (DSW) (Pergl et al., 2019), an open-source tool licensed under Apache-2.01. The implementation supports transformation and versioning of knowledge structures, generation of questionnaires, and export to machine-readable formats. It is designed for workflows of data stewards (e.g., modeling requirements), researchers (e.g., completing plans), and organizations (e.g., maintaining templates across funding calls).
The core of the implementation builds on the DSW backend (written in Haskell) and frontend (developed in collaboration with the DSW team2). The backend follows a client-server architecture with PostgreSQL and S3-compatible storage and was extended with features to support modularity and evolvability, particularly in knowledge model and questionnaire handling. These extensions allow data stewards to manage evolving requirements while enabling the reuse of existing user input.
The transformation (Domain Ontology to Knowledge Model) is realized as an expander within the DSW backend that converts OWL ontologies into structured knowledge models. For instance, adding a new property to a funder class results in the automatic addition of a corresponding question in the generated model.
To support (Knowledge Model Metamodel Evolution), we introduced versioning of the knowledge model metamodel. Each knowledge model is tied to a specific metamodel version, and models are automatically migrated upon loading. These migrations allow the platform to evolve structurally (e.g., by introducing new answer types) without affecting user data, thus ensuring backward compatibility for researchers working with legacy questionnaires.
(Questionnaire Migration) is realized through a guided migration process for questionnaires, implemented both on the server and client side. Changes in the knowledge model (e.g., added or moved questions) are detected and presented to users, who can tag items for later revision. Both backend logic and frontend interaction were extended to support this functionality as part of broader platform development.
The export to RDF, i.e., , is implemented using Jinja2 templates that map questionnaire responses to ontology-aligned RDF outputs. The templates are available as open source (Knaisl, 2025e).
The transformation (Domain Ontology to Data Components) is implemented in Python using rdflib. It maps OWL classes to reusable data components described using the View Ontology (Slifka, 2025). These components define how content should be visualized and rendered. The source code is available on Zenodo (Knaisl, 2025d).
To support the manual creation and customization of data components, a template editor was developed as part of the overall platform. It allows users to define components based on User Interface (UI) ontology elements, preview RDF output, and test expansions using live questionnaire data. The main focus of our work was on the transformation logic, while the frontend for authoring and interaction was developed in collaboration with the broader Datenzee team3.
The transformation (Data Components to Document Templates) maps View Ontology classes to Jinja2 document templates. Implemented in Python, the expander generates reusable macros and includes a rejuvenation mechanism to preserve customizations across updates (Knaisl, 2025c). This allows templates to evolve in sync with the underlying ontology while retaining institution-specific sections.
6.1 Document Generation
Finally, (Document Generation) is supported by extending the existing DSW Document Worker4 to render documents from RDF-based questionnaire replies. We integrated an RDF transformation layer into the expander, enabling seamless generation of documents based on RDF structures rather than the native DSW format.
All components and tools used in the reference implementation are publicly available and were used in the accompanying case study.
7 Evaluation
This section evaluates how well the proposed solution meets the defined research objectives. Each objective is examined in terms of its practical implementation, in comparison with existing tools and practices, and in its fulfillment of the corresponding requirement. The evaluation highlights the benefits of our approach in terms of flexibility, reusability, automation, and user guidance across different data management planning scenarios.
7.1 Research Objective RO1: Addressing Evolving Requirements
RO1 focuses on supporting the integration of evolving requirements, such as legal updates or revised DMP templates. In our approach, changes are first introduced at the level of the domain ontological model. This updated model is imported into the system, which automatically regenerates the corresponding knowledge model. All questionnaires based on the previous version are then migrated to align with the new model version using built-in migration mechanisms.
If changes also affect the data components, the data steward reruns the expander to regenerate components and updates them manually where needed. The document template is subsequently regenerated and re-imported. As a result, new documents reflect all required updates consistently across plans.
For example, when Horizon Europe updated its template to include explicit references to metadata standards and licensing strategies, only the ontological model needed to be updated to introduce new concepts. The system automatically generated the new knowledge model and allowed pre-filled questionnaires from earlier versions to be migrated. Data stewards only needed to revise the licensing section in the document component. This ensured that all DMPs across multiple projects were updated consistently and quickly.
Let represent the work required to implement a change in a single DMP. In our approach, the change is applied once at the model level and reused across all plans. The total work therefore remains constant:
7.1.1 Comparison
Traditional DMP approaches (e.g., static documents, DMPOnline, Argos) require manual updates for each individual plan. As the number of plans increases, the total work scales linearly:
In contrast, our model-driven approach keeps the workload independent of the number of DMPs. This scalability advantage is visualized in Figure 4, which highlights the growing effort required in traditional approaches versus the stable effort in ours.
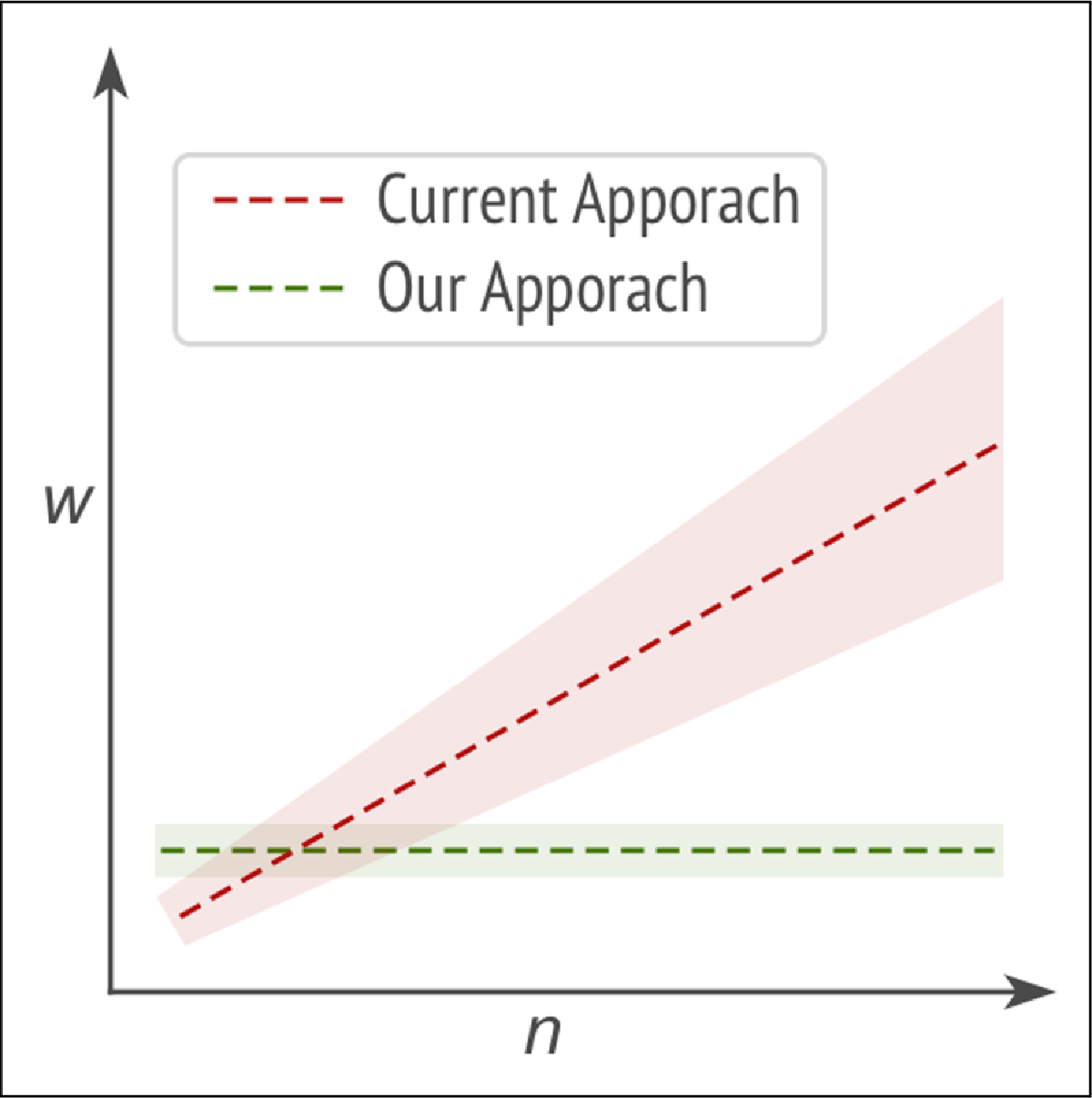
Figure 4
Comparison of Current Approaches and Our Approach.
7.1.2 Requirement Fulfillment
RO1 maps to requirement R1: “We need an efficient mechanism for migrating the existing data management plan to meet updated requirements with minimal effort and modifications.” Our solution satisfies this requirement by centralizing changes and automating their propagation, significantly reducing overall effort.
7.2 Research Objective RO2: Supporting Field- and Organization-Specific Customization
RO2 addresses the need to adapt data management plans to specific disciplines and funding bodies. While some plan elements are broadly applicable, others vary significantly; for example, sections essential in life sciences may be irrelevant in social sciences. Similarly, funding agencies may impose specific branding or other requirements.
Our solution supports customization through extensions of the domain ontological model. Data stewards can add, modify, or remove elements and can import the updated model into the system. During import, differences are computed, and a new customized knowledge model is created. This model can be named and versioned independently, while still allowing future updates to be integrated from the core model.
At the presentation layer, data components can also be selectively extended or replaced. Because components are modular and composable, only the necessary parts are overridden. This ensures maintainability and simplifies future updates by preserving the reuse of shared components.
For instance, an organization conducting biomedical research can extend the base model to include concepts such as patient consent, data anonymization, and clinical trial phases. These elements are added to the ontological model and are linked to new questions in the knowledge model, while the rest of the DMP (such as data storage or publication strategy) remains untouched. A funding agency may additionally add custom branding or legal disclaimers into the document templates without modifying the underlying logic.
7.2.1 Comparison
Traditional documents offer high flexibility but lack any system for reusing shared components, leading to poor maintainability. DMPOnline supports limited customization, while Argos offers none. In contrast, our solution balances customization with structure and sustainability, enabling tailored DMPs while promoting reuse.
7.2.2 Requirement Fulfillment
RO2 aligns with requirement R2: “We need a mechanism to tailor the requirements and templates to accommodate the distinct needs of various fields of study and individual funding agencies, while sharing common components to avoid duplications.” Our solution provides this capability, fulfilling the requirement effectively.
7.3 Research Objective RO3: Transitioning Between Templates
RO3 addresses the challenge of reusing existing data when switching to a different DMP template—typically necessary when seeking funding from multiple agencies. The goal is to avoid rewriting the plan from scratch by enabling migration between templates with minimal effort.
Our solution enables such transitions by leveraging shared ontologies within the domain ontological model. Since many templates describe similar concepts (e.g., datasets, contributors), models and data components often overlap. Data components are designed to abstract over document templates, requiring only ontology classes as input, allowing them to be reused across contexts.
To migrate, the data steward creates a new ontological model, reusing elements from existing ones where possible. Updated or new data components are created and used to generate a new document template. Both the model and the template are imported into the system; the original questionnaire can then be migrated to the new structure. Researchers need only to provide missing data, and the new document can be generated immediately.
As an illustration, a researcher initially prepared a DMP according to Science Europe guidelines but later needed to submit a Horizon Europe version. The system enabled them to reuse the majority of information (such as dataset descriptions, responsible persons, or storage locations) while adapting only a few additional fields specific to the new template (e.g., a more detailed licensing breakdown). This transition required minimal manual effort and eliminated the need to rewrite the plan from scratch.
7.3.1 Comparison
Traditional documents, DMPOnline, and Argos do not offer any support for migrating between templates. Our solution introduces this capability as a novel contribution.
7.3.2 Requirement Fulfillment
RO3 aligns with requirement R3: “We need a mechanism to facilitate the migration of the current data management plan to various templates with minimal effort and required modifications.” While the solution depends on ontology and component reuse, it significantly improves on current tools, which lack migration support entirely.
7.4 Research Objective RO4: Enabling Automated Assessment
RO4 targets the need for semi-automated or fully automated evaluation of DMPs. Current DMPs are primarily written for human readers, making evaluation labor-intensive and costly. Automating this process can reduce the burden on reviewers and improve assessment consistency.
Our solution addresses this by capturing structured, machine-readable data using ontologies. All inputs are collected in a format that can be processed automatically, thus enabling the use of predefined evaluation metrics and supporting scalable review mechanisms.
In practice, this allows a funding body to automatically evaluate whether the submitted DMP includes essential elements such as persistent identifiers (PIDs) for datasets, data retention policies, or references to repositories compliant with the Findable, Accessible, Interoperable, and Reusable (FAIR) principles. For example, the presence of a license like CC-BY or a DOI for each dataset can be verified without human intervention. This automated validation supports both early screening and post-submission audits.
7.4.1 Comparison
Traditional documents are not machine-actionable. While DMPOnline and Argos support data exports in JSON or XML formats, these lack semantic modeling, limiting their utility for automated evaluation. In contrast, our approach combines structured data with domain ontologies, ensuring semantic clarity and broader applicability for automated tools.
7.4.2 Requirement Fulfillment
RO4 corresponds to requirement R4: “We should capture the data in a machine-readable format, enabling computers to assess the data management plan using predefined metrics.” Our use of RDF, aligned with ontological definitions, meets this requirement and provides a foundation for automated assessment.
7.5 Research Objective RO5: Improving Data Management Through Guidance
RO5 addresses the gap in data management expertise among researchers. While experts in their domains, many struggle with creating effective DMPs. To bridge this gap, guidance must be integrated into the planning process—especially for beginners.
Our approach incorporates guidance directly into the questionnaire. Questions may include built-in explanations, predefined answers, or integrate with external APIs to suggest relevant options (e.g., selecting existing datasets or team members). Additionally, metrics can be assigned to responses, allowing researchers to receive real-time feedback—for example, through FAIRness scoring.
For example, when a researcher selects “personal data” as part of a dataset description, the system automatically prompts questions about anonymization strategies and ethical approvals. Similarly, if a dataset is marked for open access, the system recommends appropriate licenses and trusted repositories. Such guided interactions help even non-experts produce high-quality DMPs aligned with community best practices.
7.5.1 Comparison
Traditional documents provide no embedded guidance. DMPOnline offers some support via customizable help texts and predefined answers, while Argos guides users through a structured question flow. However, neither tool provides interactive feedback or scoring during the process. Our approach extends beyond passive help by offering dynamic, context-aware support and evaluation.
7.5.2 Requirement Fulfillment
RO5 maps to requirement R5: “We need a guidance mechanism that can serve as a substitute for the wisdom of more experienced colleagues. This mechanism should prompt relevant questions and assist in crafting improved data management plans, ultimately leading to enhanced data management practices.” By embedding guidance, metrics, and integration features directly in the questionnaire, our solution supports researchers in creating higher-quality, well-informed DMPs.
8 Demonstration Case Study
This section illustrates the practical application of our modular, ontology-driven solution through a step-by-step case study. Using real-world DMP templates from Horizon Europe and Science Europe, we demonstrate how the approach meets key research objectives and supports customization, template migration, and evolution.
We first provide a high-level overview of the methodology and its component relationships. This is followed by a walkthrough of the main implementation steps, focusing on the transformations and customization mechanisms involved. The section concludes with an evaluation of the case study results in relation to the research objectives, including a discussion on scalability and broader applicability.
8.1 Methodology and Scope
This case study demonstrates a structured methodology for transforming DMP templates into our proposed solution, emphasizing scalability and evolvability. The process begins with defining a domain ontological model, which serves as the foundation for generating all other components – knowledge models, questionnaires, data components, and document templates. This ensures consistency, modularity, and adaptability to changing requirements or different domains.
The case study focuses on two prominent DMP templates:
Horizon Europe template (European Commission, 2024a), mandatory for EU-funded Horizon Europe projects (European Commission, 2024c), backed by a 93.5 billion EUR budget (European Commission, 2024b).
Science Europe template (Science Europe, 2024a), issued by Science Europe (Science Europe, 2024b), representing 40 national research organizations with over 25 billion EUR in annual investments (Science Europe, 2024c).
Although only selected parts of the templates are used for demonstration, the methodology is applicable to full template transformations and supports domain-specific customization.
All artifacts are publicly available via Zenodo (Knaisl, 2025a).
8.2 Implementation Steps
This section demonstrates how the solution supports diverse requirements and adapts to evolving needs. Each implementation covers the transformation of a domain ontological model into knowledge models, questionnaires, data components, document templates, and final documents. Figure 5 illustrates the structure and evolution of these models.
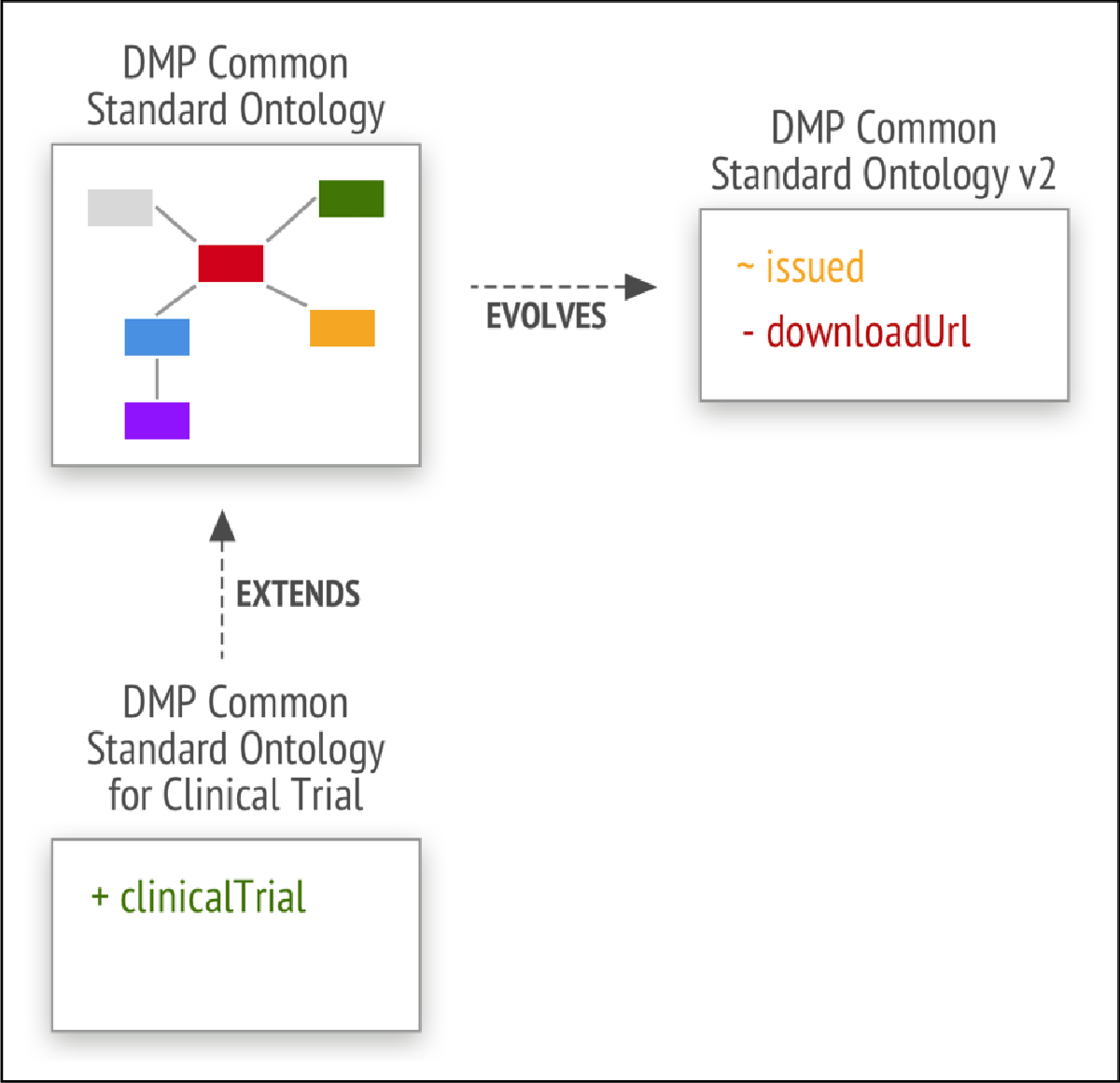
Figure 5
Model Evolution Overview.
8.2.1 Implementation of Horizon Europe and Science Europe Templates
This implementation showcases the full transformation pipeline using the Horizon Europe and Science Europe templates. The process is illustrated in Figure 6.
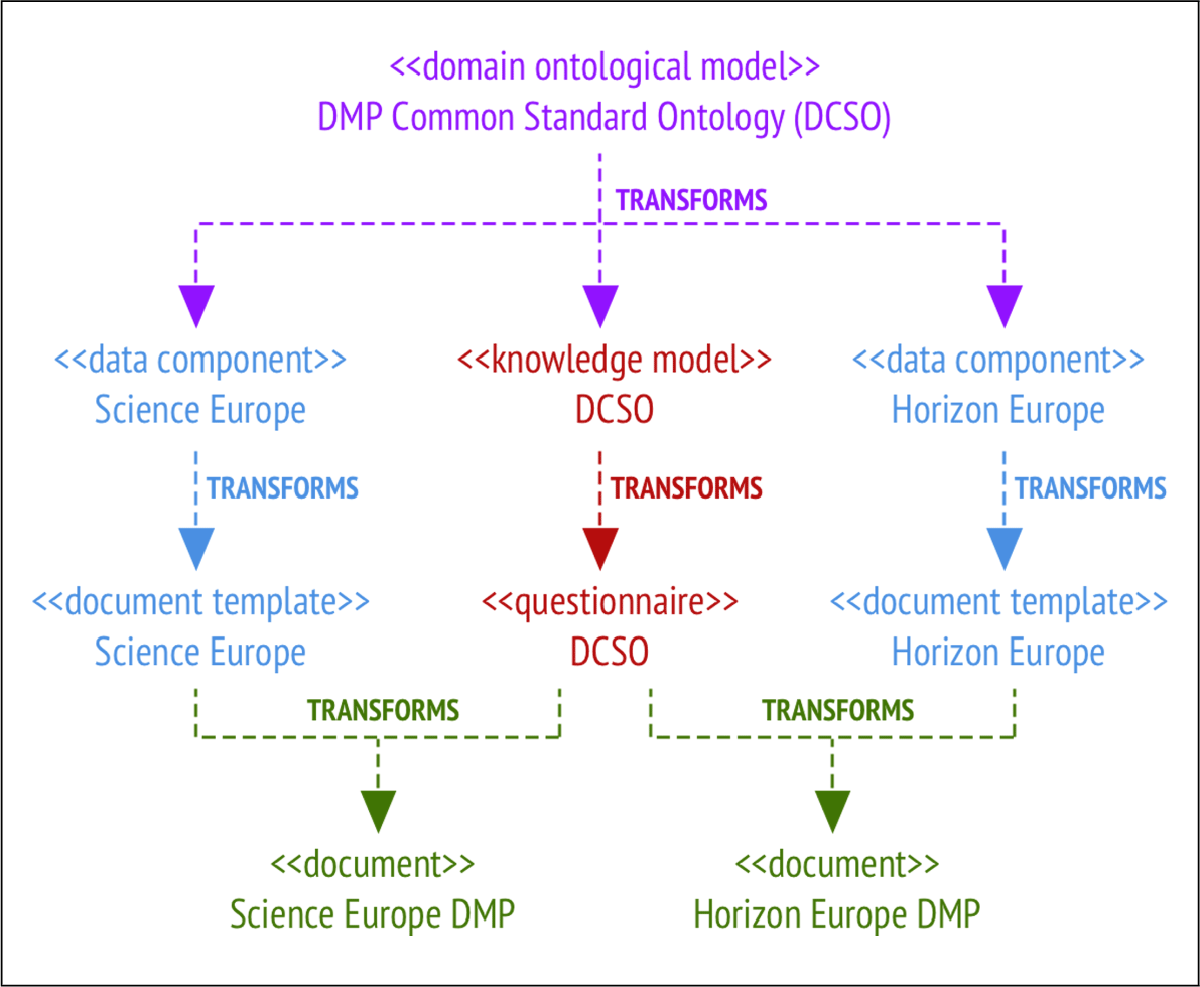
Figure 6
Implementation of Horizon Europe and Science Europe Templates.
A shared domain ontological model based on the DMP Common Standard Ontology (DCSO) (Cardoso et al., 2022; RDA DMP Common Standard Working Group, 2024; Knaisl, 2025b) was used to generate a knowledge model and questionnaire. The completed questionnaire was transformed into RDF (dcso/questionnaire/replies.ttl).
Two sets of reusable data components were created (dcso/dc-horizon-europe, dcso/dc- science-europe), then expanded into document templates (dcso/dt-horizon-europe, dcso/dt-science-europe). These preserved edits such as logos or layout changes.
Finally, the templates and RDF replies were combined to produce the final documents:
dcso/doc-horizon-europe/dcso-he.pdf
dcso/doc-science-europe/dcso-se.pdf
8.2.2 Extending the Horizon Europe Template for Clinical Trials
This case extends the Horizon Europe template to support clinical trials, as shown in Figure 7.
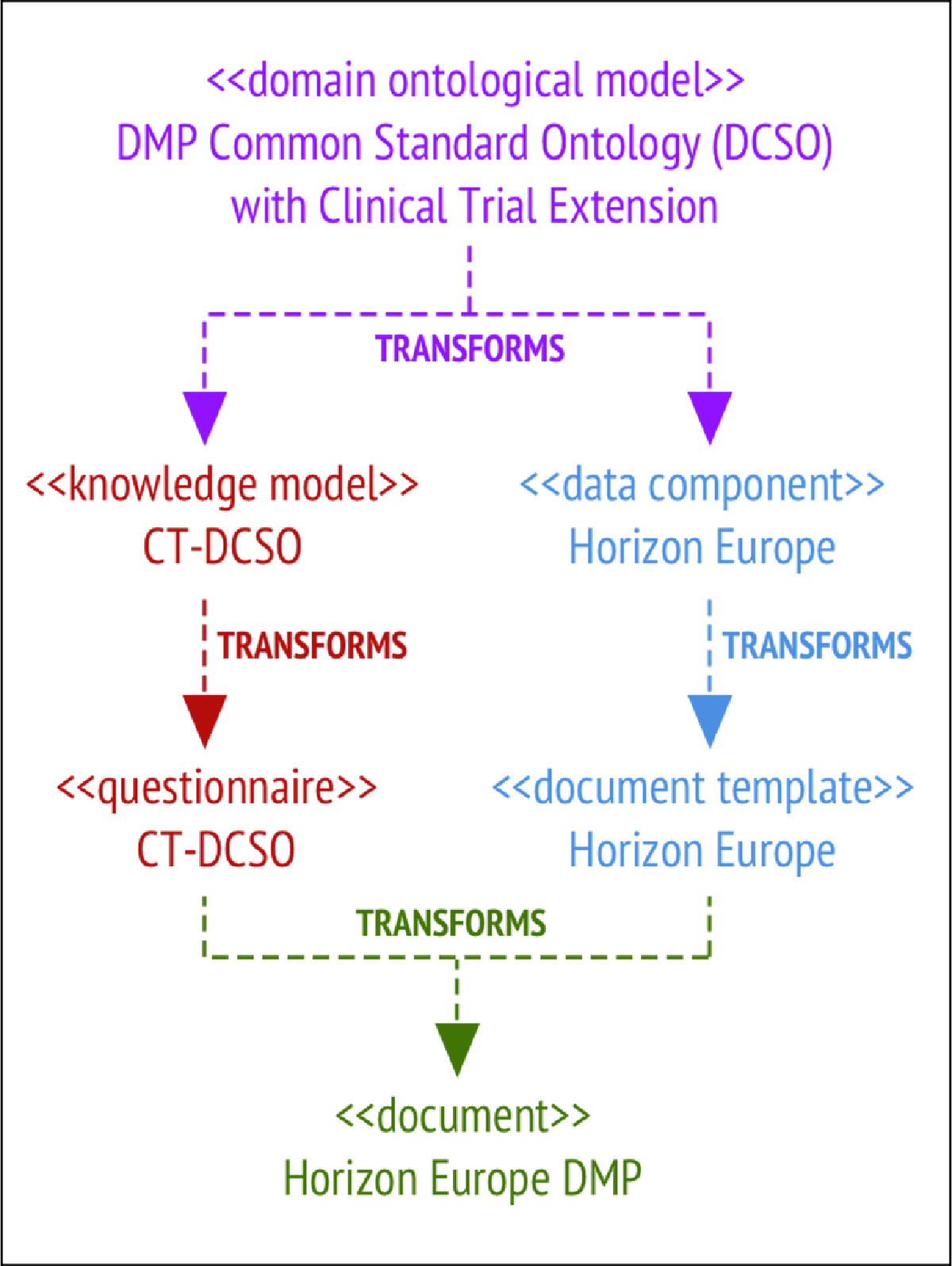
Figure 7
Implementation of Clinical Trial Customization.
The domain ontological model was extended with a clinicalTrial property (ct-dcso/ ontology/ct-dcso.ttl) and transformed into a knowledge model (ct-dcso/km/ datenzee_ct-dcso_1.0.0.km). A questionnaire was generated and filled, then exported to RDF (ct-dcso/questionnaire/replies.ttl).
A new data component for clinical trial links was added to the Horizon Europe document template (ct-dcso/dc-horizon-europe, ct-dcso/dt-horizon-europe). This illustrates how specific needs (e.g., trial registration) can be accommodated through focused extensions without disrupting the rest of the template.
The final customized DMP was generated and is available at ct-dcso/doc-horizon-europe/ ct-dcso-he.pdf.
8.2.3 Updating the DMP Ontology and Migrating Existing Content
This case shows how our solution handles ontology updates, as illustrated in Figure 8.
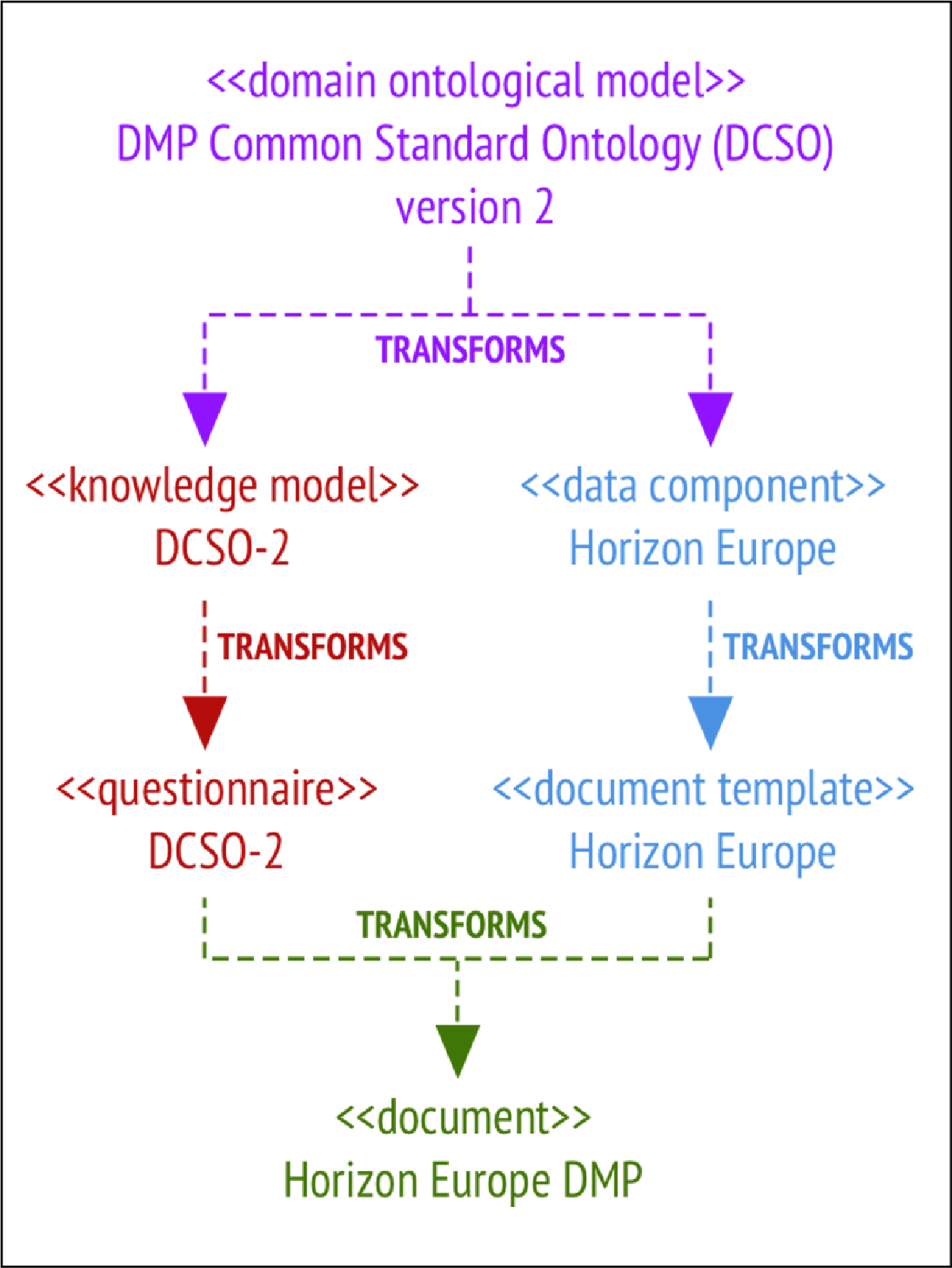
Figure 8
Implementation of the Second Version of the DMP Common Standard Ontology.
The DCSO was updated by changing dct:issued to xsd:date and removing dcat: downloadURL (dcso-2/ontology/dcso-2.ttl). A new knowledge model was generated (dcso-2/km/datenzee_dcso_2.0.0.km), and existing questionnaires were migrated, preserving unaffected responses (dcso-2/questionnaire/replies.ttl).
Data components were updated and applied to Horizon Europe only (dcso-2/dc-horizon- europe). The previous document template was reused without changes (dcso-2/dt- horizon-europe).
The final DMP was generated from the updated components and is available at dcso-2/doc- horizon-europe/dcso-2-he.pdf.
8.3 Evaluation of Research Objectives
This section evaluates how the case study meets the research objectives. The order of objectives is adapted to follow the case study’s implementation steps logically. We focus on RO2, RO3, and RO1, while RO4 and RO5 are fulfilled inherently through the proposed architecture.
RO2: Addressing Domain-Specific and Organizational Requirements
The clinical trial extension illustrates how domain-specific requirements can be supported without disrupting other components. By adding a new property ctdcso#clinicalTrial to the ontology and generating a corresponding data component, all downstream artifacts (questionnaire, RDF, and document template) were updated automatically. This minimizes manual effort and avoids unintended changes elsewhere. The example demonstrates how funding bodies or organizations can tailor DMPs while maintaining consistency with the core model.
RO3: Migrating Between Templates
The transformation from the Horizon Europe to Science Europe template shows how shared components (such as Contact or Contributor) can be reused, and how questionnaires do not need to be refilled. The ability to reapply the same RDF answers across templates enables researchers to adjust their submissions with minimal effort. This supports practical reuse when switching funding agencies or institutional guidelines. From a researcher’s perspective, this migration mechanism enables reuse of prior inputs with minimal editing. When switching from one template to another (e.g., Horizon Europe to Science Europe), most answers remain valid and are automatically preserved, reducing the need for repetitive data entry and minimizing administrative overhead.
RO1: Managing Evolving Requirements
Our solution handles evolving requirements through a modular architecture that enables systematic updates. Changes, such as adding new properties, modifying existing ones, or removing outdated elements, are applied to the domain ontological model and automatically reflected in all related components. This approach minimizes manual effort by propagating updates through the knowledge model, questionnaire, RDF outputs, document templates, and final documents without needing to update each DMP individually. Template customizations such as logos, styles, or branding are preserved using a harvesting mechanism. Even after re-expanding data components, these edits remain intact, ensuring consistent and maintainable results. For example, if a funding agency introduces a new mandatory field in their DMP template, data stewards can update the domain ontology accordingly. All downstream models and templates are then regenerated, and existing questionnaires can be migrated automatically, prompting researchers only where new input is required. This ensures policy updates are reflected consistently across submissions without requiring full rewrites.
8.4 Discussion
The case study confirms the feasibility and scalability of our modular, ontology-driven solution for data management planning. It demonstrates how reusable, versioned components and semantic models can support evolving requirements, domain-specific extensions, and template migration. The current implementation is a prototype, not a production-grade tool. Practical deployment would require robust, user-friendly software that simplifies the underlying complexity for end users.
The implementation demonstrates key design principles (such as separation of concerns, modularity, and reuse) that are critical for long-term maintainability. For instance, when adding clinical trial specific information to the Horizon Europe template, only a new property and one data component were added, leaving all other parts of the system unchanged. Similarly, the transition from Horizon Europe to Science Europe required only a switch in the document template, while reusing the same ontological model and questionnaire answers. Updating the ontology to a newer version (e.g., modifying a data type or removing a property) triggered a regeneration of the downstream components without requiring users to rewrite existing content.
To illustrate how the solution could be adopted in practice, consider a national funding agency managing multiple DMP templates for different grant programs. Today, they maintain each template as a standalone document. By adopting our approach, the agency could define a shared domain ontological model for core concepts (e.g., dataset, contact, legal compliance) and derive template-specific variants via modular extensions. Common knowledge models, questionnaires, and data components would be reused across templates, while individual programs could customize only the sections they need. Reviewers could automatically assess compliance using the structured outputs, and updates to policies or standards would propagate automatically through the system with minimal disruption.
Despite these practical benefits, broader adoption presents certain challenges. The approach introduces a shift from traditional document-centric workflows to semantically structured, machine-actionable processes. This may require training for data stewards and the development of user-friendly tools to abstract away the technical complexity.
Nevertheless, the growing emphasis on machine-actionable and interoperable DMPs, reinforced by initiatives such as the Research Data Alliance, creates a favorable environment for this type of solution. As the research community becomes more familiar with structured approaches, the extensibility and automation benefits of our method offer a promising path toward sustainable data stewardship.
9 Conclusion
This paper introduced a modular, ontology-driven framework for generating structured, semantically rich DMPs. By connecting domain ontologies with a series of evolvable transformations, the framework enables the creation of customizable and machine-readable documents, supports template migration, and simplifies ongoing updates.
Through a practical case study, we demonstrated how the solution addresses a wide range of real-world needs—from supporting multiple DMP templates and domain-specific extensions (e.g., clinical trials) to handling ontology evolution. The use of reusable components, versioned artifacts, and structured outputs reduces manual effort and avoids the limitations of traditional document-based approaches.
All research objectives were successfully met: evolving requirements are addressed through version-controlled transformations; domain-specific and organizational needs are supported via modular customization; DMPs can be migrated across templates; machine-readable outputs enable automated evaluation; and built-in guidance assists researchers in improving their data practices.
Adoption of this approach may require training and new tooling, as it shifts from static templates to structured, machine-actionable workflows. However, the demonstrated benefits—in reduced manual workload, greater consistency, and readiness for automation—offer compelling incentives for institutions seeking to modernize their data stewardship infrastructure.
Future directions include extending domain ontologies, applying AI for model and document generation, broadening the framework to other structured-document domains, and enhancing the expressiveness of the view ontology for richer user interfaces.
Data Accessibility Statement
All data and code are publicly available on Zenodo and GitHub, with links provided directly in the article.
Notes
Acknowledgements
I would like to thank the NSLab at FIT CTU in Prague for providing a collaborative environment to further explore Normalized Systems Theory.
Competing Interests
The authors have no competing interests to declare.
Author Contributions
Vojtech Knaisl conducted the research, developed the framework, implemented the prototype, and wrote the manuscript, except for specific components explicitly credited in the text as reused or developed in collaboration. Robert Pergl supervised the work.