
1. Understanding research data management in collaborative research
1.1. Introduction
Sustainable research data management (RDM) lays the groundwork for long-term access to data, which is key to good scientific practices, especially when it comes to unique data or data that have been generated with high effort. Furthermore, efficient RDM practices generate findable, accessible, interoperable, and reusable (FAIR, Wilkinson et al., 2016) data, fostering scientific collaboration across disciplines and innovative data evaluation. However, good RDM requires considerable resources such as time and effort when data documentation is not supported by automated processes. In addition, there exist cultural barriers for data sharing at an early stage of research, especially for data that are not (yet) intended for public access.
Therefore, funding institutions like the German Research Foundation (DFG) increased their emphasis on implementing RDM practices in research projects, demonstrated, e.g., by a revision of its guidelines for safeguarding Good Scientific Practice (DFG, 2022). Within the German research funding landscape, DFG’s Collaborative Research Centers (CRCs) are one of the largest funding lines for collaborative research. In spring 2024, the DFG funded 278 CRCs with a total budget of €871 million, which corresponds to 24% of the DFG’s total budget (DFG, 2024). Within a CRC, dedicated funding for RDM can be received by the application for information management (INF) projects.
For large interdisciplinary research projects, the agreement and implementation of common standards for metadata is a critical step for efficient RDM. CRCs are thereby an ideal starting point to explore the implementation of metadata schemes as a basis for overarching RDM practices.
1.2. Case Study: Overview of CRC 1280’s collaborative environment
CRC 1280 ‘Extinction Learning’, which is headed scientifically and organizationally by its elected spokesperson Prof. Dr. Dr. hc. Onur Güntürkün, aims to study the neural, behavioral, ontogenetic, and clinical mechanisms of extinction learning in various species. This is achieved through computational simulations as well as experimental test sessions with human or animal subjects, utilizing diverse measurement techniques such as microscopy, single-cell recording, magnetic resonance imaging, and questionnaires. As a result, multi-session and multi-modality data are measured and analyzed. Given the involvement of human subjects as well as clinical settings, data collection often entails sensitive information covered by the General Data Protection Regulation of the European Union (Regulation EU 2016/679).
Over the span of two consecutive funding phases (2017–2021, 2021–2025), the CRC has expanded to encompass 81 researchers from 18 scientific groups distributed across four different institutions (Ruhr University Bochum, University of Duisburg-Essen, Leibniz Research Centre for Working Environment and Human Factors at TU Dortmund University, and Philipps University of Marburg). Two of these groups, known as focus groups, have been strategically established to capitalize on data from streamlined experimental designs. Their main objective is to integrate internally shared data from the other CRC research groups to run large-scale analyses yielding comprehensive insights. However, a timely and efficient reuse is only possible if data is shared at an early stage of research within the CRC. Therefore, a strategy for sharing data within the CRC appeared indispensable, including the development of a common metadata schema.
1.3. Metadata solutions for interdisciplinary data sharing
Metadata-based solutions to promote early data sharing and reuse in collaborative, interdisciplinary settings are rare. CRC 1280, which involves not only neuroscience but also related disciplines such as medicine, biology, and psychology, did not have the opportunity to fall back on an established metadata schema in 2016. At the same time as the development of the CRC’s metadata schema, progress was made on discipline-specific RDM standards and metadata schemas. As of May 2024, FAIRsharing.org (Sansone et al., 2019) lists 66 standards with the subject ‘neuroscience’. However, discipline-specific standards are not yet widespread and in daily use, as a 2021 survey within the German neuroscience community shows, which still finds a perceived lack of standards for data and metadata in neuroscience (Klingner et al., 2023). A prominent standard for neuroimaging is the Brain Imaging Data Structure (BIDS), which was introduced in 2016 (Gorgolewski et al., 2016). It implements a hierarchical file and folder structure and naming scheme with highly detailed technical and experimental metadata that is stored using an inheritance strategy. Although BIDS is used in CRC 1280 for neuroimaging, a simple, easy-to-implement solution was additionally needed for improved interdisciplinary communication.
2. Development of metadata schema
2.1. Iterative process of metadata schema development
The primary objective behind creating a common CRC metadata schema was to facilitate cross-group communication about data at an early stage of the research, thereby fostering efficient collaborations. To this end, it had to be possible to integrate the schema into daily workflows with minimal additional effort for researchers, underlining the goal of a simple and practical metadata schema implementation. To enable cross-group data sharing on a practical level, the development of the metadata schema was accompanied by the setup of a central storage for the CRC, a network drive operated by the central university IT, as well as the adoption of a RDM policy (Pacharra et al., 2022).
To ensure sustainability and early adherence to FAIR principles, the central Research Data Services (RDS) team of the CRC’s main institution, the Ruhr University Bochum, was involved from the beginning. As a result of this collaboration, the aim to map the metadata schema to the bibliometric standards DataCite (v4.2, DataCite Metadata Working Group, 2019) and Dublin Core (release 2012-06-14, Dublin Core Metadata Initiative, 2012) was directly included in the development process.
The development of the metadata schema posed several challenges, which extended the timeline beyond initial projections. From autumn 2016 to spring 2019, over eight in-person meetings and frequent email exchanges were held. This schedule was constrained by the need to accommodate participants’ availability across institutions during the demanding CRC application period. Initial efforts focused on raising awareness about the value of a unified metadata schema for promoting reusable data in the CRC. All discussions encompassed not only the content of the metadata itself but also the general data model of the CRC, including a folder structure in which the data and metadata should be stored. In parallel, tools for creating and searching metadata were developed and iteratively tested by the groups together with the metadata schema. Reconciling the different needs of the CRC research groups needed time and ultimately resulted in a metadata schema with 14 fields. Among these fields, 13 are mandatory, and one is mandatory solely for studies involving animal or ethics applications (‘Animal/Ethics Approval Number’).
The metadata schema needed to be amended twice since its inception based on feedback from the researchers. Firstly, an optional free text field entitled ‘Extra Information’ was added in 2020 to indicate test subjects or sessions excluded from the data analysis and the reasons for this, resulting in 15 fields. Subsequently, in 2022, at the start of the CRC’s second funding period, a comprehensive review with the researchers led to expansions in controlled vocabularies, incorporating newly created research groups and their measurement techniques in already existing fields of the metadata schema (i.e., fields ‘Group ID’ and ‘Modality’). Furthermore, a new, mandatory metadata field called ‘Experimental Description was introduced to allow researchers to provide background information on their studies, resulting in a total of 16 fields (see Table 1).
Table 1
CRC 1280 metadata schema, M = mandatory, O = Optional.
| ID | FIELD NAME | OBLIGATION | DESCRIPTION | CONSTRAINTS OR CONTROLLED VOCABULARIES |
|---|---|---|---|---|
| 1 | Group ID | M | internal ID of CRC research group | controlled vocabulary: A01, A02, A03, A04, A05, A06, A07, A08, A09, A10, A11, A12, A13, A14, A15, A16, A18, A19, A21, F01, F02 |
| 2 | Experiment Title | M | title of the experiment | free text entry |
| 3 | Creator | M | main experimenter(s) or collector(s) of data | use of specific delimiters to separate first and last name and individuals |
| 4 | Contributor | M | other experimenters or individuals involved | use of specific delimiters to separate first and last name and individuals |
| 5 | Record Date | M | date when the data were collected or recorded | ISO 8601 date format |
| 6 | Resource Type | M | type of data | controlled vocabulary: Analysed, Measured, Simulated |
| 7 | Modality | M | characteristics of the data | controlled vocabulary: Behavioral, ECG|Pulse, EDA, EEG, Eyetracking, Histology, Hormone Measurements, LFP, MRI, Questionnaires, Respiration, Single cell recording, TMS |
| 8 | Shared With | M | CRC group ID to share data with | controlled vocabulary: A01, A02, A03, A04, A05, A06, A07, A08, A09, A10, A11, A12, A13, A14, A15, A16, A18, A19, A21, F01, F02 |
| 9 | Experiment Description | M | short scientific abstract of the experiment | free text entry |
| 10 | Subject ID | M | ID that uniquely identifies each subject | for human subjects: the 11-digit CRC subject code (Diers et al., 2023) |
| 11 | Subject Species | M | species of the subject studied in the experiment | controlled vocabulary: Humans, Pigeons, Mice, Rats, Crows, Jackdaws |
| 12 | Subject Type | M | characteristics of the subject in the context of the experiment | controlled vocabulary: Healthy test subject, Patient, Healthy control subject |
| 13 | Subject Sex | M | specification of the sex | controlled vocabulary: male, female, diverse, undefined |
| 14 | Subject Age | M | age of the test subject | in years |
| 15 | Animal/Ethics Approval No. | M | official number or code of the animal/ethics approval | free text entry |
| 16 | Extra Information | O | any extra information of relevance e.g., subject exclusions | free text entry |
[i] Note: For the mappings to Dublin Core and DataCite, please refer to the Supplement, Table A.
2.2. Description of resulting data model and metadata schema
For efficient storage and better findability of data and metadata in the CRC, the metadata schema was designed to operate within a predefined data model. This model incorporates a structured folder hierarchy, illustrated in Figure 1, comprising the levels CRC Group, Experiment, Subject, Session, and Modality.
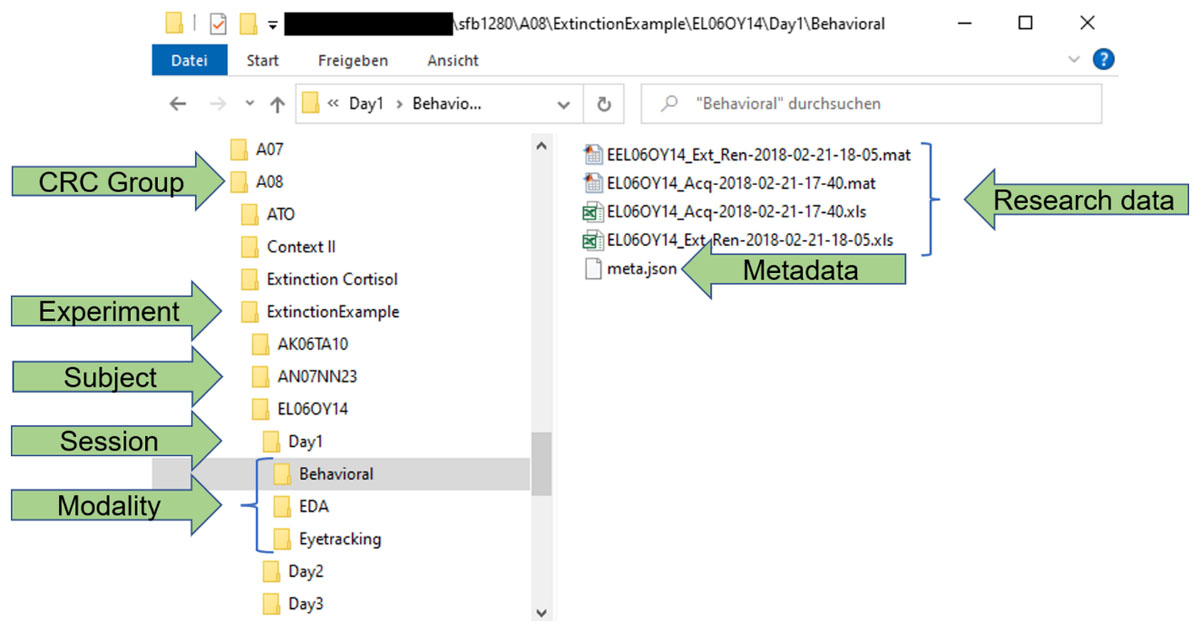
Figure 1
Example of structured folder hierarchy in the CRC data model incorporating the levels CRC Group, Experiment, Subject, Session, and Modality.
Within this data model, the storage of CRC metadata in JSON format is mandatory at the modality level, where the metadata is fully nested as a single file within the folder structure. At this level, the metadata is comprehensive and complete, incorporating information from the experiment, subject, session, and specific modality. To this end, metadata information from the higher levels (e.g., ‘Experiment Title’) is inherited by the lower levels, whereby only a single metadata entry (‘Modality’) is added specifically for the lowest folder level.
To ensure consistency in field completion, seven of the 16 metadata fields employ controlled vocabularies (see Table 1). An additional four fields enforce specific constraints, e.g., entries to the ‘Creator’ field need to adhere to clear format requirements, and ‘Subject ID’ for humans must comply with CRC’s subject code specifications (Diers et al., 2023). To enhance interoperability, six of the 16 CRC fields are mapped to Dublin Core terms and/or DataCite properties (see Supplement, Table A).
3. Implementation and use of the metadata schema
3.1. Rationale behind the development of MetaDataApp and DatabaseApp
User-friendly, researcher-tailored solutions have been developed as common tools within the CRC to streamline metadata creation and search. The open-source MetaDataApp (Zomorodpoosh et al., 2024) and DatabaseApp (Diers et al., 2024) are Java-based applications with intuitive graphical user interfaces (GUIs) that introduced a standardization in the CRC for handling metadata, thereby increasing efficiency and reducing errors associated with manual editing of files. In particular, the visibility of metadata in the DatabaseApp should increase the motivation for sharing data in the CRC.
The use of these tools required training and ongoing support to ensure effective adoption. Support efforts include detailed user manuals, an internal knowledge database, regular training sessions, and on-demand assistance from the CRC’s INF project (Pacharra, Winter and Otto, 2024).
3.2. User-centric development and key usability features
3.2.1. MetaDataApp: Simplifying the creation of metadata
The MetaDataApp allows researchers to easily enter metadata and store metadata in local (JSON) files according to the CRC metadata specification. The primary interface includes the 16 CRC metadata fields, which are mandatory and should be populated first by researchers (see Figure 2). Thereafter, researchers have the option to populate further Dublin Core fields and then DataCite fields in two additional windows of the app (see Supplement, Table A).
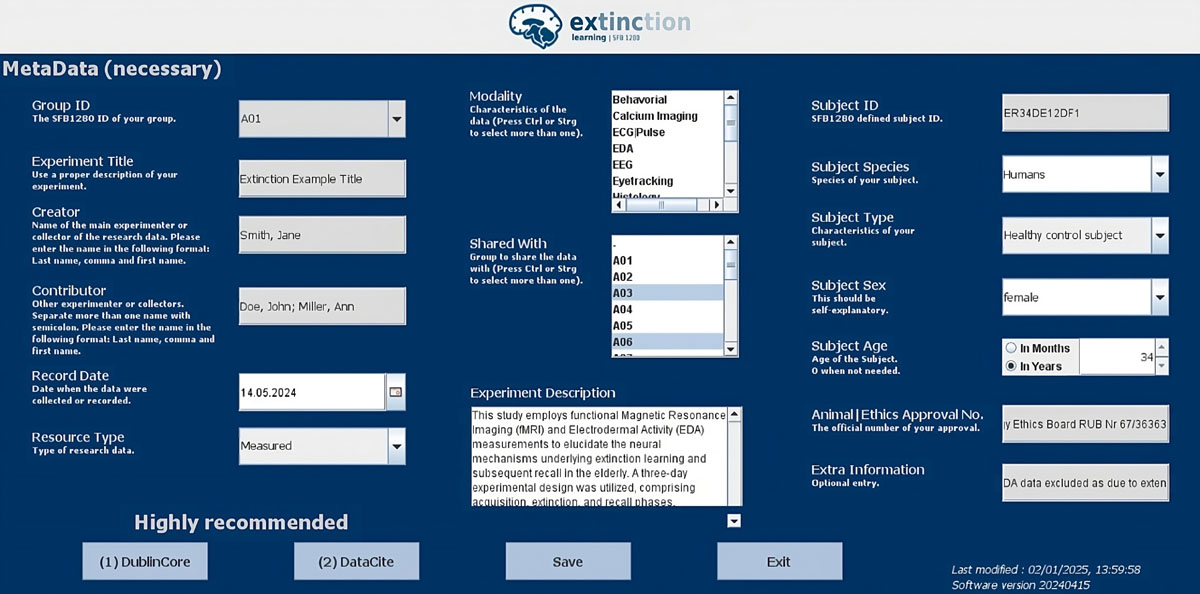
Figure 2
Primary interface of the MetaDataApp with exemplary entries: Opening the MetaDataApp in the Modality folder, only the Modality needs to be selected. The other metadata are automatically copied from the higher folder levels.
Four key features were developed to make the app user-friendly:
The app’s inheritance strategy is specifically designed to simplify metadata entry for the CRC nested data model with a predefined hierarchical folder structure (compare Figure 1). The feature eliminates the need for redundant metadata entry, such as entering the experiment title for each test subject and then again for every experimental session with that test subject. Instead, entries made at a higher level (e.g., the experiment) within the multi-level CRC folder structure are automatically transferred to subsequent subfolders (e.g., Subject, Session, Modality) when the application is opened in these lower folder levels (compare Figure 2). To achieve this, metadata files are searched for in the higher folder levels, and the more general entries are read out and copied into the corresponding fields.
The app automatically maps entered CRC metadata to both DataCite and Dublin Core standards (see Supplement, Table A). For instance, a title entered is stored not only as Experiment Title in the metadata but also as Dublin Core-Title and DataCite-Title. Furthermore, the app facilitates the input of additional Dublin Core and DataCite metadata, whereby the app recommends populating Dublin Core first and then DataCite, thus avoiding duplication of work due to an implemented DataCite-Dublin Core mapping (DataCite Metadata Working Group, 2021).
The MetaDataApp streamlines the process of metadata creation further by automatically storing prescribed metadata entries in the DataCite or DublinCore schema, such as information about the funding agency (compare Supplement, Table A). As this information is identical for all CRC groups, it is saved without any user input together with the experiment-specific metadata.
To help ensure metadata completeness, the app includes a validation feature. If a user attempts to exit the app without filling in all mandatory fields, a warning message appears that encourages a timely update of metadata. Validation and quality assurance are further supported during data curation by the CRC’s INF project using dedicated tools and workflows (Pacharra, Winter and Otto, 2024).
3.2.2. DatabaseApp: A tool for faceted search and search retrieval
An auxiliary tool, the DatabaseCreator (Diers, Otto and Pacharra, 2024), has been developed to run regularly, scanning the CRC’s central storage for all CRC metadata and writing the results into a SQLLite database, which is then also stored on the central storage. Researchers can efficiently explore available metadata records in this database by using the faceted search interface of the DatabaseApp, which can run locally.
In particular, the DatabaseApp allows the application of single or multiple filters to narrow down the search results according to the 16 fields and controlled vocabularies of the CRC metadata schema. Researchers can save the metadata search as well as the search results in CSV format and seamlessly download the data and metadata associated with the search results from the central storage to their local hard drives. Thus, the DatabaseApp simplifies data and metadata search as well as retrieval.
3.3. Evaluating the effectiveness of the implemented metadata schema
As of May 2024, the central storage contains a substantial collection of CRC metadata files, totaling 10,797 individual records. These metadata belong to more than 3,200 human and animal test subjects that have been tested in over 6,400 individual recording sessions by CRC researchers. Among these records, 65.3% contain complete CRC metadata, encompassing entries in all 15 mandatory CRC metadata fields. Excluding the ‘Experimental Description’ field, only introduced during the second funding period, increases the completion rate to 94.9%.
Analysis of the optional DataCite and Dublin Core fields in the records suggests a positive impact of the MetaDataApp. Entries automatically generated by the app or with a controlled vocabulary in the app exhibit high completion rates, notably DataCite-funderName at 85.7% and DublinCore-Coverage at 97.2%. In contrast, completion rates for the Dublin Core schema are lowest for DublinCore-Rights at 21.5% and for the DataCite schema for DataCite-relationType at 4.8%. For these metadata fields, the app did not offer a selection from a controlled vocabulary until version 3.0, which was released in spring 2024 (Zomorodpoosh et al., 2024).
The CRC metadata files contain metadata on more than 40 individual creators, with at least three opting for their own programmatic approaches to create metadata instead of using the provided MetaDataApp. Due to the multimodality of their experiments and their good programming skills, this approach was more time-efficient for them. Consequently, an estimated 24.7% of metadata on the central storage were not created with the MetaDataApp. Remarkably, the standardized vocabulary of the CRC is not used consistently in only a small number of these metadata (4.9%).
Unsurprisingly, the two focus groups and the INF group of the CRC are core users of DatabaseApp. While the other 16 CRC research groups may not use the app regularly, it is used during RDM consultation sessions between INF and the groups as a tool to highlight the visibility of their work within the CRC.
4. Lessons learnt to strengthen the implementation
Continuous improvement, facilitated by iterative feedback loops with users, offers a pathway to refine the CRC metadata schema and associated tools over time. However, revisions to the metadata schema itself, while often necessary, can adversely impact completion rates, as updating existing metadata is perceived as unpopular and time-intensive by researchers. Notably, despite being mandatory, the completion rate for the subsequently introduced CRC metadata field ‘Experiment Description’ with 65.3% is not ideal, underscoring the need for caution when amending metadata schemas.
Since the adoption of the CRC metadata schema five years ago, only two fields had to be added, so that the negative effects are still manageable. However, these results underline that any modifications of a metadata schema should be made with caution, preferably in consultation with experts, to mitigate adverse impacts on completion rates. As a best practice, it is advisable to include a dedicated metadata field for the version of the metadata schema from the outset. Such a field provides a clear record of which schema version was in use at the time of metadata creation, eliminating ambiguities and supporting future analyses and comparisons of metadata.
A first, internally released version of the MetaDataApp (v0.1, released 2020-09-09) included ambiguous instructions regarding the unit for ‘Subject Age’. This resulted in researchers entering the ages of lab animals in months rather than years. Subsequent releases of the app and revisions of the manual introduced clearer instructions as well as the option to enter age as either ‘in months’ or ‘in years’ in the app. For better usability and standardization, the app now automatically converts an entry in months to years for storage in the created JSON files. Although such a timely development of technical solutions in iterative loops with users costs time and resources, agile development is recommended for enhanced effectiveness and user-friendliness.
While the metadata schema was designed to work in conjunction with the CRC folder structure, a standardized folder naming schema was never prescribed, resulting in inconsistent names and challenges in session-based data analysis. This underlines the importance of thorough documentation not only of the metadata schema itself but also of the whole data model and accompanying processes.
5. Conclusion and outlook: Transferability and sustainability of the approach
As the CRC use case shows, agreeing on a common metadata schema for collaborative research takes time, especially when a data model and RDM tools are developed in parallel. It took the CRC researchers around two years to agree on just 14 metadata fields, including controlled vocabularies and mappings. An early start to such a process is therefore highly recommended.
The size of a metadata schema is a crucial field of tension when bringing it into use. Favoring fewer but essential fields in the metadata schema facilitates swift cross-collaboration communication and aligns with researchers’ daily RDM workflows. This is demonstrated by high completion rates for the initially introduced metadata fields and a high number of internally shared datasets within the CRC. While a more complex metadata schema may be more comprehensive, it risks discouraging data sharing due to increased workload. In conclusion, the decision for the size of a metadata schema should be carefully made under consideration of the aims of its introduction and its subsequent use.
Interestingly, parallels between the independently but simultaneously developed CRC data model and BIDS for neuroimaging (Gorgolewski et al., 2016) emerged, such as hierarchical folder structure and metadata inheritance. In particular, inheritance strategies within hierarchical data models have proven to be effective in avoiding duplication of work. These shared design principles may reflect essential features for the representation of multi-session and multi-modality research data.
Expert guidance, e.g., from a university’s central RDM support, can substantially strengthen the sustainability of the metadata development. The advice of the RDS team to map the metadata schema to bibliometric standards resulted in an automated mapping to DataCite and Dublin Core via the MetaDataApp. This approach significantly increases the interoperability of the metadata schema with low additional effort for the researchers.
For improved sustainability, the CRC metadata schema will be implemented in the new Hyrax-based repository of the Ruhr University Bochum (Frenzel et al., 2023) with a migration of all CRC data and metadata scheduled for mid-2024. This will enable CRC researchers to continue working efficiently and collaboratively with their data while meeting the requirements of Open Science (data publication) and good scientific practice (10 years of preservation) on one platform. The CRC’s intensive metadata-based work created the researchers’ acceptance and understanding to integrate this system into the research process.
Data Accessibility Statement
The tools developed in the framework of this study are available at https://gitlab.ruhr-uni-bochum.de/sfb1280. The MetaDataApp (https://doi.org/10.5281/zenodo.11203063), DatabaseApp (https://doi.org/10.5281/zenodo.11203222), and MetaDatabaseAnalyzer (https://zenodo.org/records/13912364) used for the analysis of the CRC metadata are all published under a CC-BY-SA license.
Additional File
The additional file for this article can be found as follows:
Acknowledgements
We thank Jürgen Windeck and Dirk Rosemann for their consultation when creating the metadata schema and Erik Diers and Setareh Zomorodpoosh for their help in programming the MetaDataApp and DatabaseApp. We thank Sandra Linn, Alexander Esser, and Veronika Josenhans for helpful comments on this manuscript and proofreading.
Funding Information
This work was funded by the Deutsche Forschungsgemeinschaft (DFG, German Research Foundation) – Projektnummer 316803389 SFB 1280 (project INF).
Competing Interests
The authors have no competing interests to declare.
Author Contributions
M.P.: Conceptualization, Methodology, Data Curation, Formal Analysis, Writing – Original Draft Preparation, Writing – Review and Editing; T.O.: Conceptualization, Methodology, Supervision, Writing – Review and Editing; N.O.C.W.: Conceptualization, Supervision, Writing – Original Draft Preparation, Writing – Review and Editing.