
1. Introduction
In recent years, the rapid growth in unstructured and semi-structured data has led to the increasing prevalence of NoSQL databases due to their flexibility and scalability advantages over traditional relational databases (Belefqih, Zellou and Berquedich, 2023). NoSQL databases provide benefits including the ability to handle large volumes of rapidly changing heterogeneous data, scalability across commodity servers, and structural flexibility for evolving data models as illustrated in Figure 1.
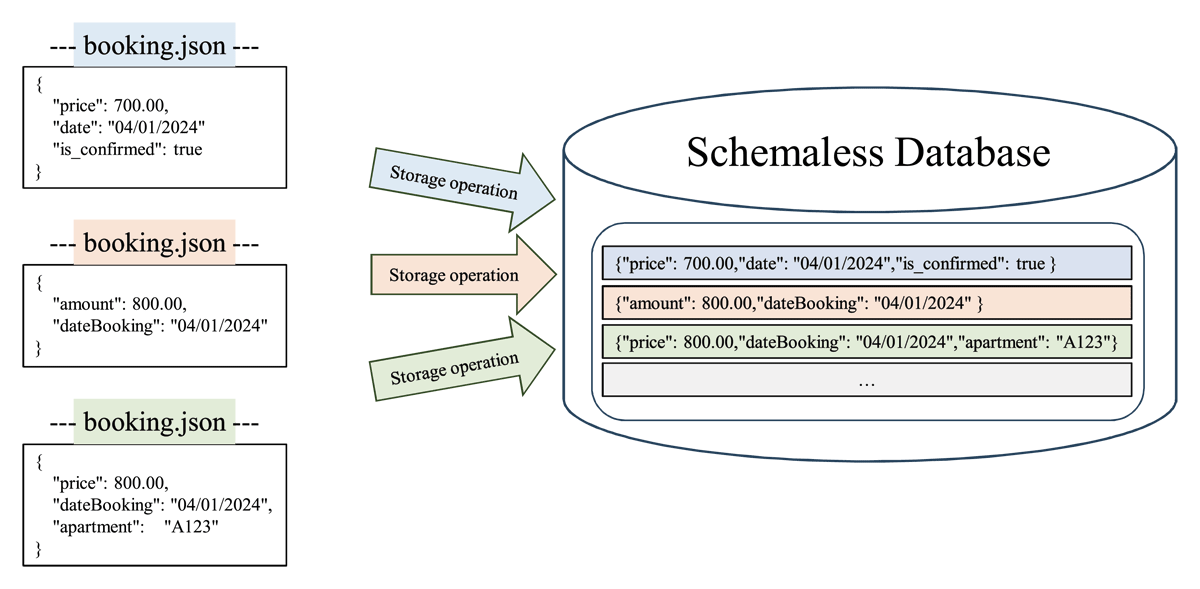
Figure 1
Flexibility Character of Database Schema-less.
Despite their benefits, the schema-less nature of most NoSQL databases poses significant challenges. Although these databases are designed to operate without a predefined schema, understanding the implicit schema remains crucial for several tasks. In Data Integration, schemas help unify data from diverse sources, ensuring consistency and reliability. In Business Intelligence and analytics, clearly defined schemas are essential for efficient report generation and data analysis (Reda et al., 2020). Moreover, schema extraction improves metadata creation, enhances query performance, and simplifies data integration, while reducing storage and migration costs. These factors are critical for optimizing operational efficiency and ensuring high data quality, which are vital for informed decision-making (Ajarroud, Zellou and Idri, 2018; Yazidi, Zellou and Idri, 2012).
Manually extracting schemas from NoSQL databases is impractical, especially for large or complex datasets. This process typically requires database administrators or data engineers to manually inspect data structures, a task that is time-consuming, error-prone, and infeasible at scale. Given the volume and complexity of modern data, automated approaches to schema extraction have become essential.
This research addresses the challenge by proposing a systematic approach for extracting schemas from NoSQL databases. Our primary focus is on inferring the structural properties of JSON data, the most common format used in NoSQL databases, and presenting them as a visual schema to facilitate interpretation. Our method addresses key challenges by: (i) Identifying primitive data types such as Strings, Integers, and Booleans. (ii) Detecting reference data types such as arrays, maps, and nested objects. This reveals complex hierarchical structures in the data. (iii) Uncovering associations between entities based on keys or other linking attributes. This enables joining connected entities. (iv) Discerning structural variations such as attributes being updated. This highlights schema evolution over time.
The remainder of this paper structured as follows: Section 2 provides foundational definitions and background information relevant to our research. Section 3 reviews relevant existing research related to this paper’s focus. Section 4 presents our proposed approach for extracting schemas from NoSQL databases in detail. Section 5 outlines the experimental evaluation. Section 6 details the results from testing our approach. Finally, Section 7 summarizes the conclusions from this work and suggests directions for further research building on these contributions.
2. Preliminaries
NoSQL Databases
NoSQL databases, unlike traditional relational databases, offer flexible schema designs and scalability (Belefqih, Zellou and Berquedich, 2023). They are categorized into several types: (i) Key-Value Stores: These databases use a simple key-value pair structure to store data. Examples include Redis and DynamoDB (Liu et al., 2015). (ii) Document-Based Databases: These databases store data in documents (usually JSON or BSON format), allowing for a more flexible schema. Examples include MongoDB and CouchDB (Jose and Abraham, 2019). (iii) Graph-Based Databases: These are designed to handle data with complex relationships, such as social networks or organizational structures. Examples include Neo4j and Amazon Neptune (Fabregat et al., 2018). (iv) Wide Column-Based Databases: These databases store data in columns rather than rows, which can be useful for handling large datasets. Examples include Apache Cassandra and HBase (Vora, 2011).
Triplet-Based Representation
A key aspect of our schema extraction approach is the use of a triplet-based representation to capture the inherent structure of NoSQL databases. This representation follows a subject-predicate-object model, where entities, attributes, and data types are encoded in an intuitive format. By extracting triplets from JSON documents, we create an intermediate representation suitable for schema analysis. This format helps maintain relationships between database elements, making it easier to analyze the structure and detect schema components.
BERT Contextualized Embeddings
To enhance schema extraction, we utilize BERT (Bidirectional Encoder Representations from Transformers), a powerful NLP model that uses an attention mechanism to generate contextualized embeddings. These embeddings capture the meaning of words or phrases based on their specific context within a sentence or document. Unlike static embeddings, which offer fixed vector representations, BERT’s contextualized embeddings dynamically adjust according to surrounding text, providing a nuanced understanding of semantic relationships. This capability is crucial for studying semantic textual similarity and enhances our schema extraction approach for NoSQL databases (Chowdhary, 2020; Reimers and Gurevych, 2019).
Similarity Analysis
Similarity analysis quantifies how closely related two entities are based on their contextualized embeddings. Using metrics like cosine similarity, which measures the angular distance between vectors, this analysis evaluates the degree of similarity between entities by assessing the alignment of their contextual representations. By applying this technique, we can precisely determine which triplets to retain in the final schema, ensuring an accurate representation of the data (Yousfi, Elyazidi and Zellou, 2018; Semantic Textual Similarity Methods, Tools, and Applications: A Survey, 2016).
3. Related Work
Several approaches have been proposed to address the challenge of inferring schemas from schema-less databases. Sevilla Ruiz, Morales and García Molina (2015) employed Model-Driven Engineering (MDE) techniques to generate versioned schemas. The process involves mapping attribute value to a type, resulting in raw schemas, which are then refined to eliminate redundancies, producing versioned entities.
Another schema inference approach, presented by Klettke et al. (2017), utilized schema version graphs to summarize the structure of selected entities. This graph-based approach enables tracking schema evolution, including operations such as adding, modifying, copying, or moving properties. Baazizi et al. (2019) proposes a two-step technique for schema extraction from a single JSON collection, involving individual type inference and type reduction based on mapping and reduction operations.
In the context of NoSQL columnar databases, Frozza, Defreyn, Mello and dos (2020) suggested copying the hierarchical structure into a new namespace and analysing each column to infer data types. Meanwhile, Bouhamoum et al. (2018) focuses on discovering schema and entity links from RDF data sources using a clustering algorithm without prior schema information.
Addressing the challenge of automatic schema extraction, Souibgui et al. (2022) proposed a three-step approach. The first step involves global schema extraction, where JSON document fields and types are identified. The second step, Discovery of Candidate Identifier, identifies pairs of identifiers and references through a validation process. The third step, identifying candidate pairs of key fields, uses graph-based techniques and rules for compatibility, syntactic similarity, and semantic similarity.
Additionally, Bansal, Sachdeva and Awasthi (2023) introduced a concise approach for generating schemas in document stores in three steps: Conceptual Model and application workload input, Intermediate Transformation to generate Query Graph and Query Labels, and Final Schema Generation for MongoDB schema. Klessinger et al. (2023) presented an approach using tagged unions, enhancing semantic clarity by capturing dependencies between attributes.
Machado et al. (2021) proposed a schema extraction process based on text similarity in four steps: Pre-processing, Similarity Analysis using NLP and Semantic Web techniques, Identification of Equivalences, and Structure Representation to visualize the schema.
To validate the extracted schema, comparing it with the original schema is advisable, particularly in a production environment. In such scenarios, assessing performance metrics becomes crucial to ensure the quality of the extraction schema. Key criteria for evaluation include Input/Output Format, Structural Components, Integrity Constraints, Optional Properties, Inference Process, and Scalability. For instance, Koupil, Hricko and Holubová (2022) accepts diverse formats as input, while Abdelhedi, Rajhi and Zurfluh (2022) demonstrated the capability to extract various structural components.
The techniques for detecting and recovering permanent schema changes. Many approaches, like the Darwin architecture proposed by Störl and Klettke (2022), used timestamps for versioning and schema evolution management. Meanwhile, Möller, Klettke and Störl (2019) introduced schema versions, assigning incremental numbers for each schema extraction operation, creating a chronological history of schema versions. These approaches offer continuous schema updates, crucial for evolving data models.
4. Schema Extraction Approach
Our schema extraction approach involves four essential steps, as illustrated in Figure 2. In the initial ‘Triplet Extraction’ phase, we retrieve JSON objects from the NoSQL database and transform each attribute into a triplet format (Entity, Property, Type). Since JSON is a common format used in different types of NoSQL databases, including Key-Value, Document-Based, Graph-Based, and Wide Column-Based databases. This approach ensures flexibility and applicability to all these database types.
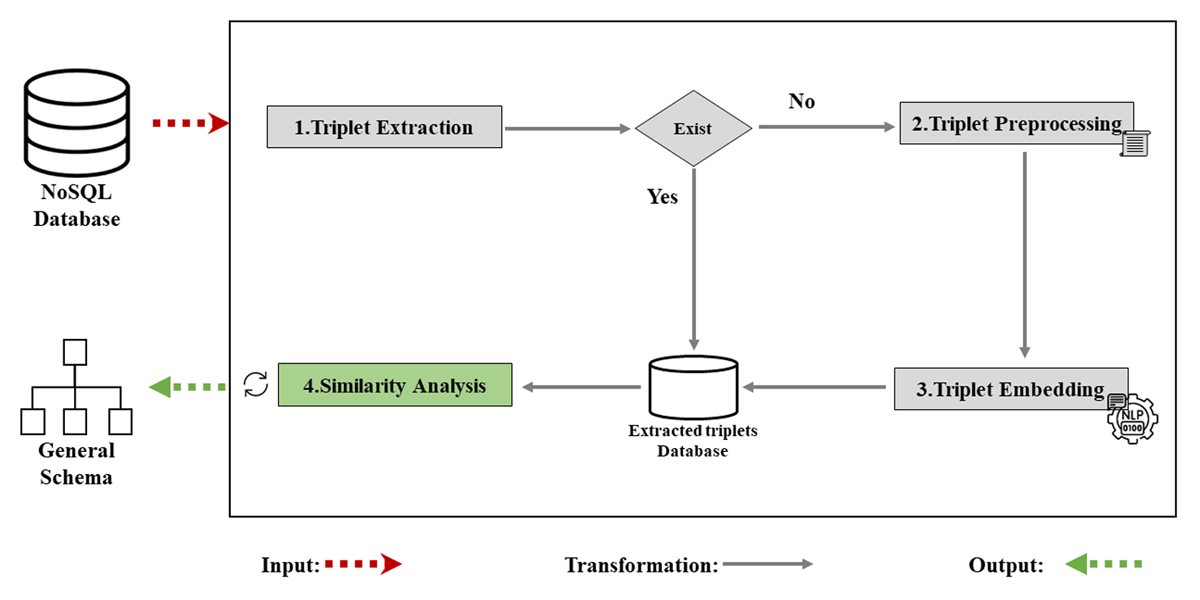
Figure 2
Our Schema Extraction Approach.
In the subsequent ‘Triplet Preprocessing’ stage, we perform triplet cleaning, which includes the eliminating property naming conventions. During the ‘Triplet Embedding’ step, Google’s BERT NLP model is employed to generate embeddings for each triplet. BERT is utilized for its ability to produce rich, context-aware embeddings, essential for capturing the detailed relationships within the triplets. Its bidirectional training approach enables it to understand and embed complex hierarchical structures, making it well-suited for the nested nature of NoSQL databases.
Finally, in the ‘Similarity Analysis’ stage, we assess the degree of similarity between triplets based on their embeddings and merge distinct triplets into a cohesive schema.
4.1. Extract Triplets
In the ‘Extract Triplets’ step, we begin by parsing JSON objects retrieved from the NoSQL database and transforming them into a structured format called triplets. These JSON objects typically follow a specific structure, consisting of an object name followed by a series of key-value pairs. Within this structure, the key serves as the property name, while the value represents the content.
Our methodology is structured to represent JSON objects as a series of triplets, each one comprising three essential components:
The first part is dedicated to storing the object’s name.
The second part accommodates the property name.
The third and final part contains the data type of the property.
Our approach identifies and extracts three types of data, as clarified in Figure 3:
Primitive Type (PT): When the value assigned to the key is of type string, number, or Boolean, we create a triplet in the format T (Entity, Property, Type). In this format, ‘Entity’ represents the object’s name, ‘Property’ denotes the key, and ‘Type’ signifies the primitive data type. A triplet can be represented mathematically as follows:
Object Type (OT): In the case where the value is an object nested within the current object, we define the triplet as T (Entity, Property, Entity). Here, the first ‘Entity’ refers to the name of the current object, ‘Property’ contains the keyword ‘hasObject’ to indicate nested object inclusion, and the second ‘Entity’ pertains to the name of another triplet. This nesting is accomplished through recursive traversal of the child object. Mathematically, a triplet can be depicted as:
Array Type (AT): This is the third form of value, typically containing a list of similar objects. Our process creates a triplet for a single child element, as the other child elements refer to the same object. The form is as follows: T (Entity, Property, Entity), where the first ‘Entity’ is the name of the current object, ‘Property’ includes the keyword ‘hasArray’ to indicate the relationship between entities, and the second ‘Entity’ is the name of the first object within the list. Mathematical representation of a triplet involves the following:
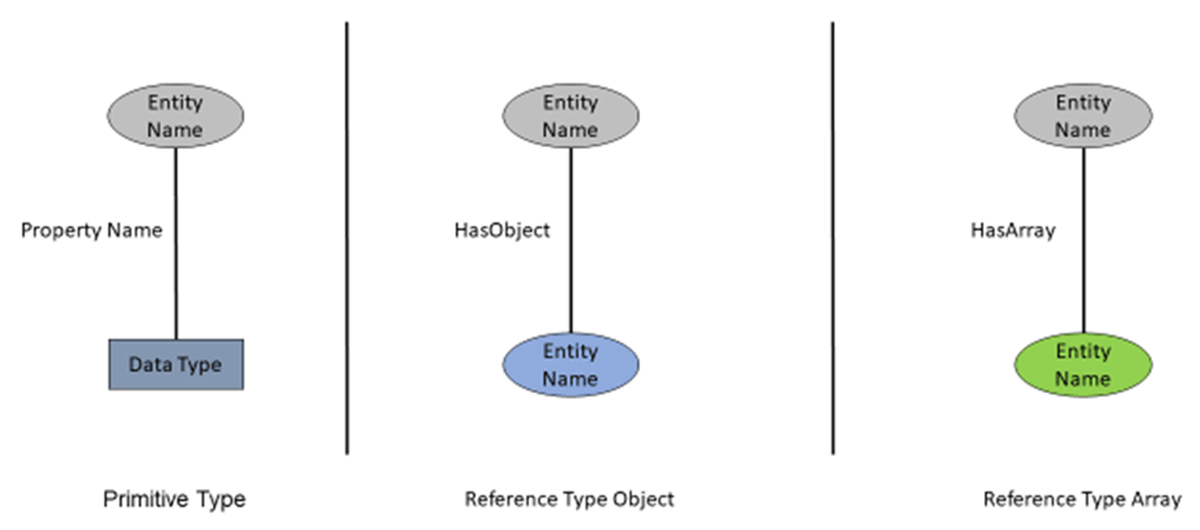
Figure 3
Extract Triplets Step.
The algorithm shown in Figure 4 was designed to extract triples from JSON objects. It can handle primitive data types, nested objects, and arrays of objects. This allows the algorithm to fully represent the relationships present in the JSON structure. The end result is a set of triples that captures the connections between data elements in the JSON.

Figure 4
Triple Extraction Algorithm.
4.2. Transformation 2: Triplet Preprocessing
The main goal of this step, As shown in Figure 5, is to prepare the extracted triplets for similarity analysis. Pre-processing plays a crucial role in this process, enabling the refinement of triplets. Extracted Triplets often contain terms formatted according to coding conventions like CamelCase, snake_case, and the inclusion of numeric values in identifiers. By addressing these formatting challenges, we not only reduce noise but also enhance the overall data quality. Consequently, we achieve better accuracy and improved results in our subsequent similarity analysis.
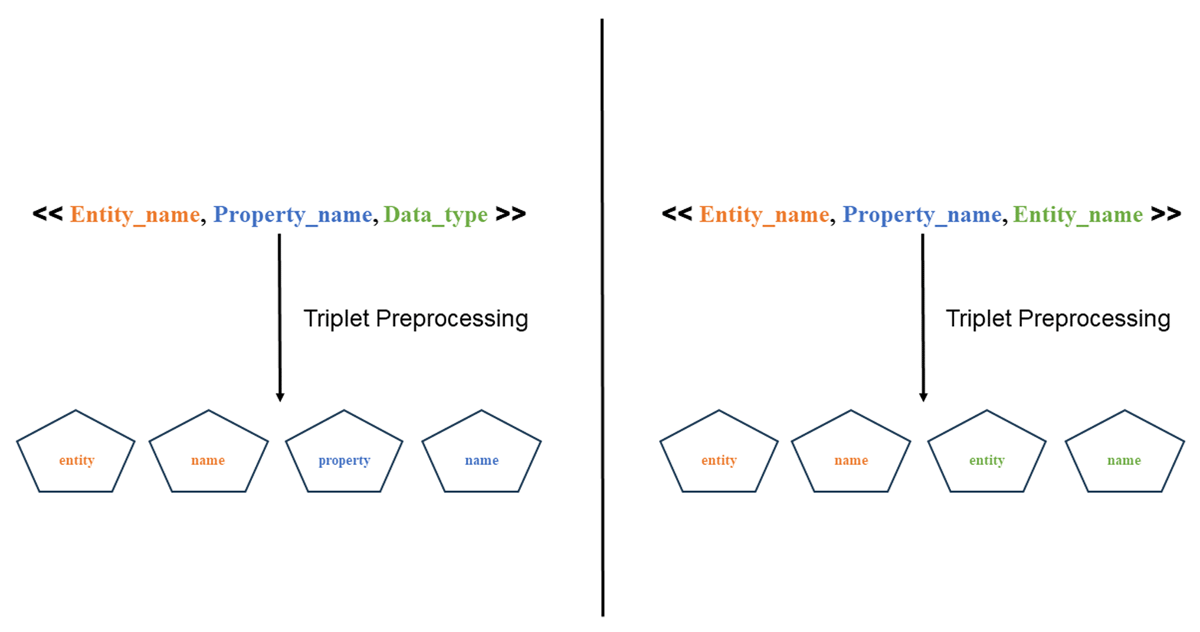
Figure 5
Triplet Preprocessing Step.
Pre-processing begins with (i) Tokenization, where each triplet component is divided into smaller tokens to segment compound words (e.g., ‘no_student’ becomes ‘no, student’). (ii) Identifier Normalization standardizes the triplet components into a uniform format, typically by converting them to lowercase and removing numeric values (e.g., name1, name2, etc.). (iii) Acronym Handling is applied to replace acronyms with their corresponding full terms. For instance, acronyms like ‘no’, ‘num’, and ‘numb’ are transformed into ‘number’, while ‘acct’ is changed to ‘account’, among others. This transformation relies on a predefined list of common acronyms commonly used by programmers and developers to ensure the triplets are normalized. Toward the end of this process.
To address missing and noisy data during preprocessing, we implemented several strategies. Missing values were managed through imputation techniques, assigning default values based on the expected data type to maintain consistency across the dataset. For noisy data, we removed duplicates that could distort the schema. If the triplet already exists in the database, it implies that preprocessing and embedding processes have already been applied, further simplifying the workflow.
4.3. Transformation 3: Triplet Embedding
In this phase, we utilize NLP to semantic analysis on triplets. The similarity study in our case is distinctive due to the characteristics of the input data, which involves triplets rather than plain text. This complexity necessitates a deliberate choice, leading us to opt for Google’s BERT model due to its performance, precision, and its demonstrated effectiveness with short text (triplets).
The Triplets Embedding phase involves the adoption of the BERT model to generate a unique vector for each triplet. This BERT vector provides us with a contextualized representation for each element within the triplet, setting it apart from other NLP models like Word2Vec and GloVe, which produce context-free vectors without considering the triplet’s context (Church, 2017; Pennington, Socher and Manning, 2014).
The BERT model, as illustrated in Figure 6, takes the pre-processed tokens generated in the previous step as input. It then progresses through several critical stages: (i) Word Embedding: The primary function of this component is to convert each token into a fixed-dimensional, non-contextual vector, capturing the core meaning of individual words while disregarding contextual details. (ii) Positional embedding: This component provides positional information for each token in a sequence, enabling BERT to discern the word order in the input text. (iii) Transformer Encoder: At this juncture, the BERT model employs a multi-layer transformer architecture, consisting of multiple stacked encoder layers. Each encoder layer comprises a multi-head self-attention mechanism and a feedforward neural network.
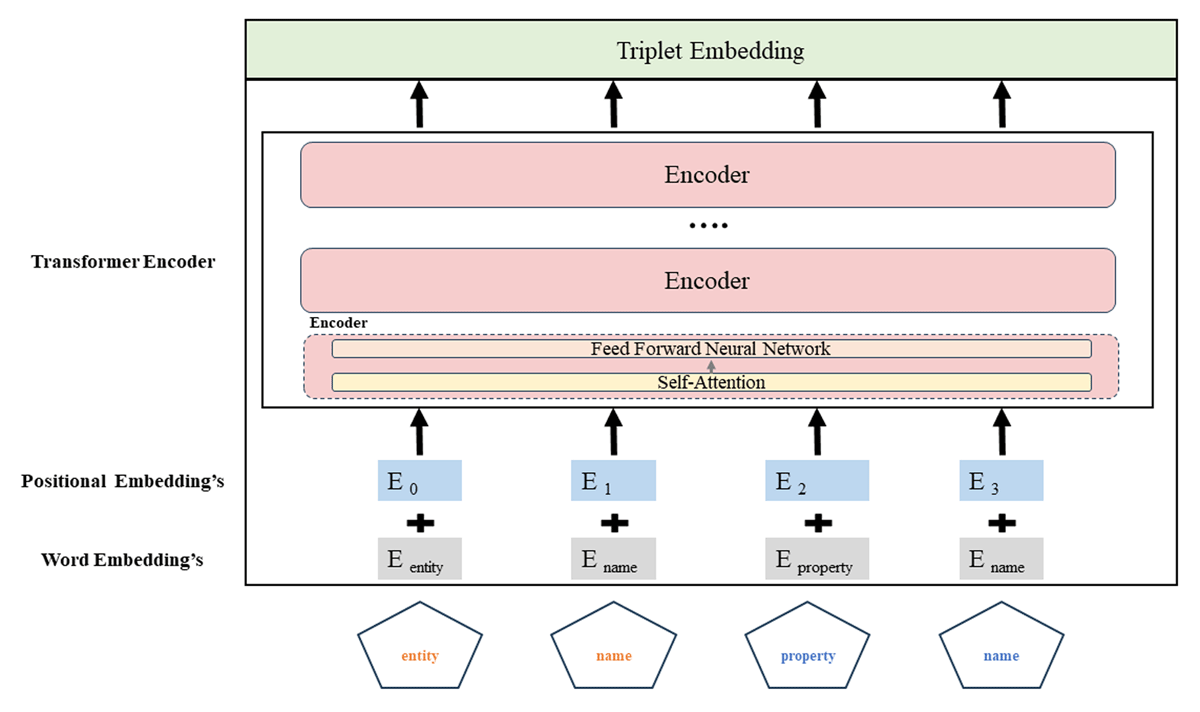
Figure 6
Triplet Embedding Step.
The self-attention mechanism empowers the BERT model to capture token relationships in both directions (left-to-right and right-to-left), which is essential for comprehending each token’s context. Within each encoder layer, the BERT model simultaneously processes all tokens, updating the contextual embedding of each token based on the context provided by the other tokens in the sequence. This contextualization enables the BERT model to grasp the meaning of each token within the triplet’s context. This iterative process unfolds across multiple encoder layers, with each layer enhancing contextual integration. Upon completion of processing by all encoder layers, we obtain a contextualized vector encompassing the entire triplet, referred to as ‘Triplets Embedding’. The triplets Embedding produced will be stored in a database for later use in the similarity analysis.
4.4. Similarity Analysis
In the context of our ‘similarity analysis,’ we utilize the triplets of embeddings previously stored in the database to assess the similarity among them. To do this, we use cosine similarity as a fundamental measure to evaluate the semantic similarity between triplets. This similarity measure is based on the contextualized embeddings we obtained in the previous step, which encapsulate the rich semantics of our triplets. Cosine similarity, a widely used method, evaluates the angular distance between vectors, making it a natural choice for quantifying similarity between contextualized embeddings.
The mathematical formula for the cosine similarity between the two vectors A and B is as follows:
The final stage of processing involves merging the triplets that have a lower similarity score, thereby building a complete schema comprising distinctive triplets. This schema condenses the relevant information into coherent groups, while ensuring that the unique characteristics of each triplet are retained. By consolidating triples with lower similarity scores, we create a holistic representation that facilitates understanding of the NoSQL database.
After completing the initial stages of triplet preparation, which include triplet extraction, pre-processing, and triplet embedding, we proceed to the crucial phase of similarity analysis. During this step, we employ BERT embeddings and the cosine similarity metric to assess the semantic similarity among the contextualized triplets. The goal of the approach isn’t just merging all triplets, as doing so might lead to redundancy in the schema. Instead, we adopt a strategic approach to similarity analysis, aiming to identify and safeguard the uniqueness of triplets displaying low cosine similarity scores. By quantifying the semantic relatedness among triplets through cosine similarity scores, we unveil their semantic connections. Triplets with lower cosine similarity scores, indicative of distinctive semantic attributes, are specifically retained as essential components of the schema. We avoid merging them with others because retaining these important details is crucial for a comprehensive schema that enhances our understanding of the NoSQL database structure and supports seamless data integration.
5. Experimental Evaluation
The process consists of executing the sequence of sub-activities presented in the four steps: Triplet Extraction, Triplet Preprocessing, equivalence identification and structure representation.
The project’s source code implementation is available in Belefqih (2023). As presented in Figure 7, for our experiments, we utilized Document-Based NoSQL databases, specifically MongoDB, with sizes ranging from 1GB to 10GB, encompassing millions of JSON documents. This dataset size was considered sufficient according to standard practices for evaluating schema extraction methods in real-world scenarios. The diversity and scale of these datasets enabled us to effectively assess the generalization capacity of our approach, ensuring that the schema extraction process is robust for both small and large-scale NoSQL deployments. In order to test our process, we conducted (i) a fine-tuning process used to adapt our BERT model’s ability to capture the similarity of triplets. (ii) An export of JSON documents from a NoSQL database, we implemented the following steps:
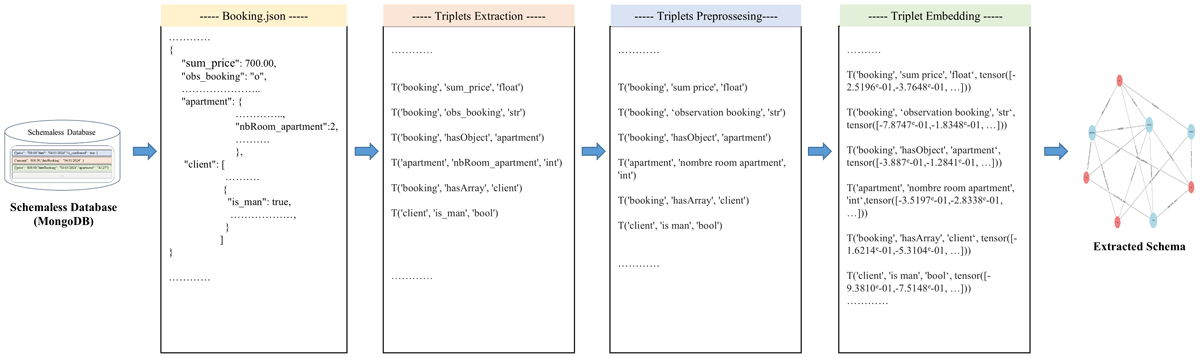
Figure 7
Semantic Schema Extraction Process Visualization.
Step 1: Conversion of the attributes of JSON Objects to a triplet-based representation (entity-property-dataType). We defined a function called ‘extract_triplets’ to convert the content of JSON documents from a NoSQL database, into a structured representation in three parts: entities, attributes and data types. Figure 8 shows an input/output example of our function. This function analyses all the JSON documents and generates a new data collection containing the triplet representation.
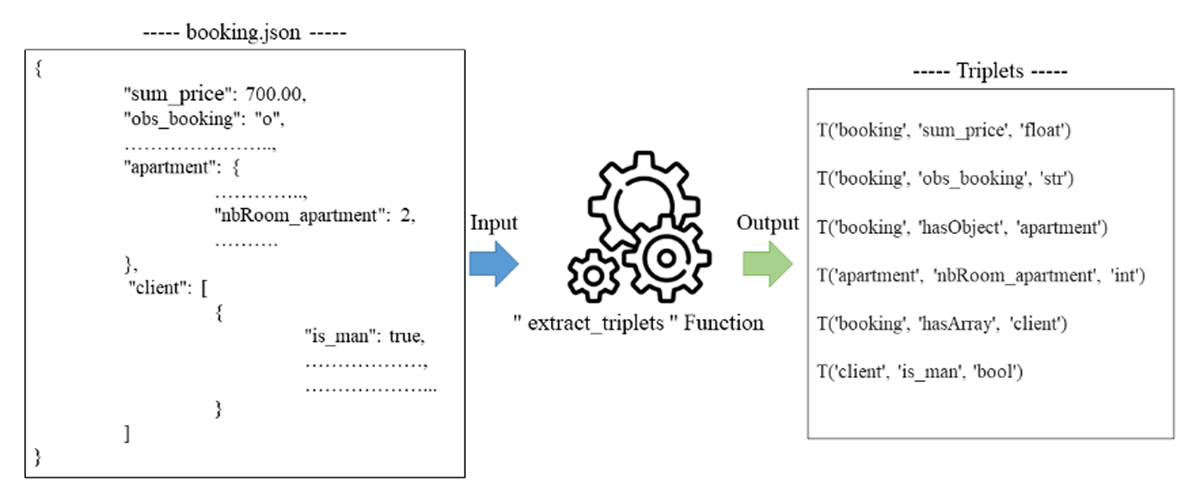
Figure 8
‘triplet_to_Embeddings’ Function.
Step 2: Application of preprocessing rules on the extracted triplets. We implemented a second function called ‘triplet_to_Embeddings’ to apply preprocessing rules namely the elimination of numeric values, special characters and normalization on all triplets. Our function also identifies and replaces acronyms with their meanings from a predefined list stored in the database.
Step 3: Generation of contextual embeddings of triplets. We used the previously pre-trained BERT model. Through the fine-tuning of the BERT model, our extraction approach acquires the ability to generate contextual integrations of triplets. This processing is handled by our second function ‘triplet_to_Embeddings’. As Figure 9 shows, our function returns triplets with associated vectors as output.
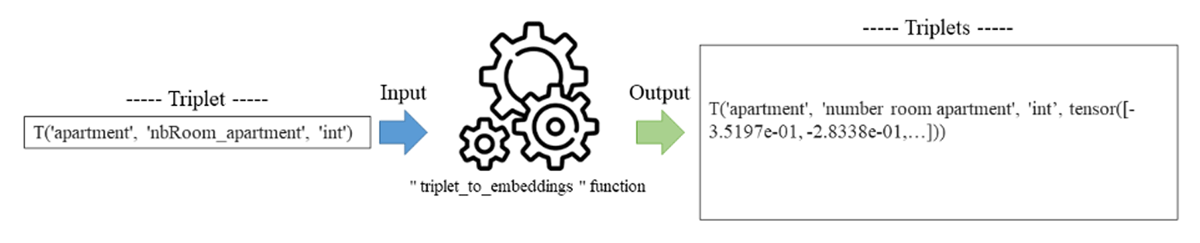
Figure 9
‘triplet_to_Embeddings’ Function.
Step 4: Elimination of Similar Triplets. We developed a function called ‘eliminate_similar_triplets’ to remove similar triplets. The similarity triplet, derived from BERT Embeddings, serves as a pivotal component in our schema extraction methodology. BERT Embeddings capture the contextual semantics of triplets, converting them into numerical vectors that encode rich information about the relationships within the schema-less data. The similarity, calculated using cosine similarity on these embeddings, provides a quantitative measure of the resemblance between each pair of triplets. A high cosine similarity score signifies a strong semantic connection, indicating that the corresponding triplets share similar contextual information. This similarity study aids in identifying and eliminating redundancies (highly similar triplets) based on a specified threshold parameter. Figure 10 demonstrates the similarity matrix between the triplets.
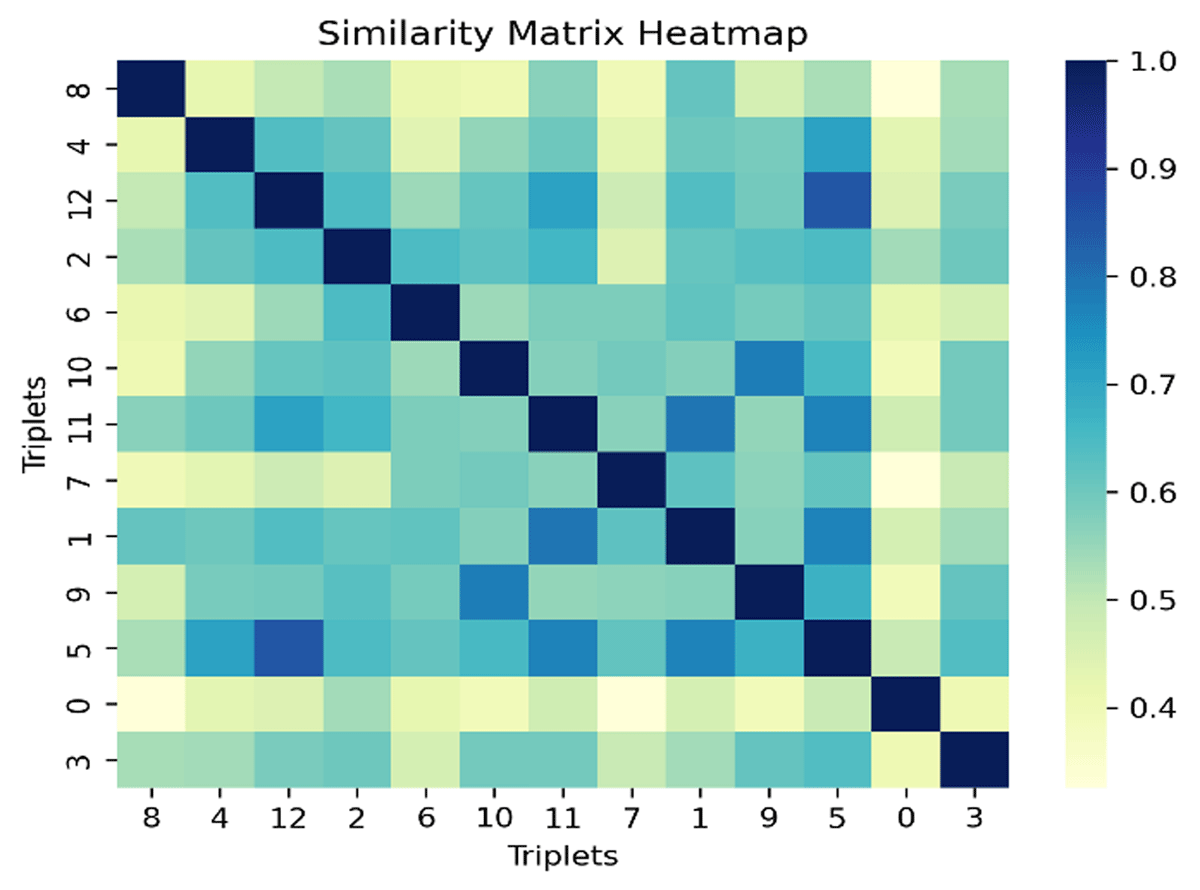
Figure 10
The Similarity Matrix Visualization.
Step 5: Visual representation of schema. The final step of our process involves building and presenting the global schema. The construction of the global schema is based on the remaining triplets. To properly represent our schema, we assigned colors to entities, attributes, and data types, with light blue, light green, and light coral, respectively. Figure 11 shows the global schema extracted from NoSQL databases.
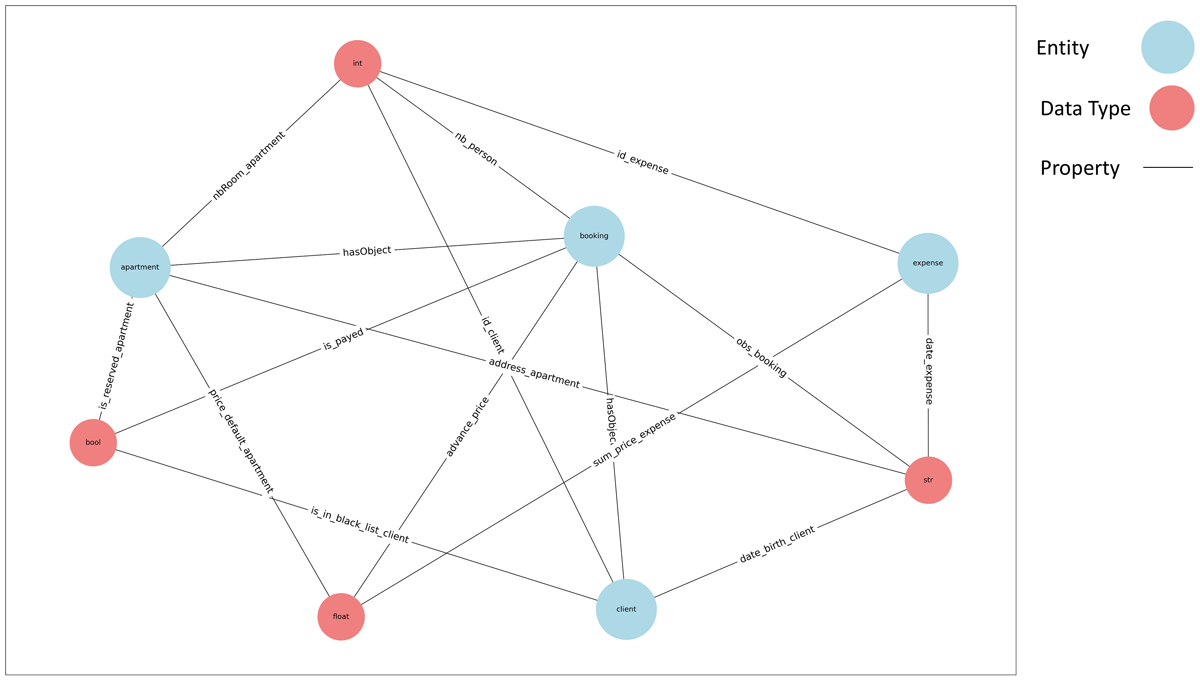
Figure 11
Global Schema Extracted from NoSQL Databases.
6. Discussion
This paper introduces a novel BERT embedding-based approach for schema extraction from NoSQL databases, leveraging NLP and semantic embedding to analyze triplets extracted from JSON documents in schema-less NoSQL databases. The key findings and their implications are as follows.
The approach effectively integrates triplet extraction, triplet pre-processing, triplet embedding, and similarity analysis to extract structured schemas, demonstrating promising performance when evaluating real-world NoSQL datasets containing nested objects and arrays. As shown in Figure 12, our approach achieves a high precision score of 1.0, signifying its ability to accurately extract valid triplets from raw JSON documents without introducing any false positives that deviate from the ground truth schema.
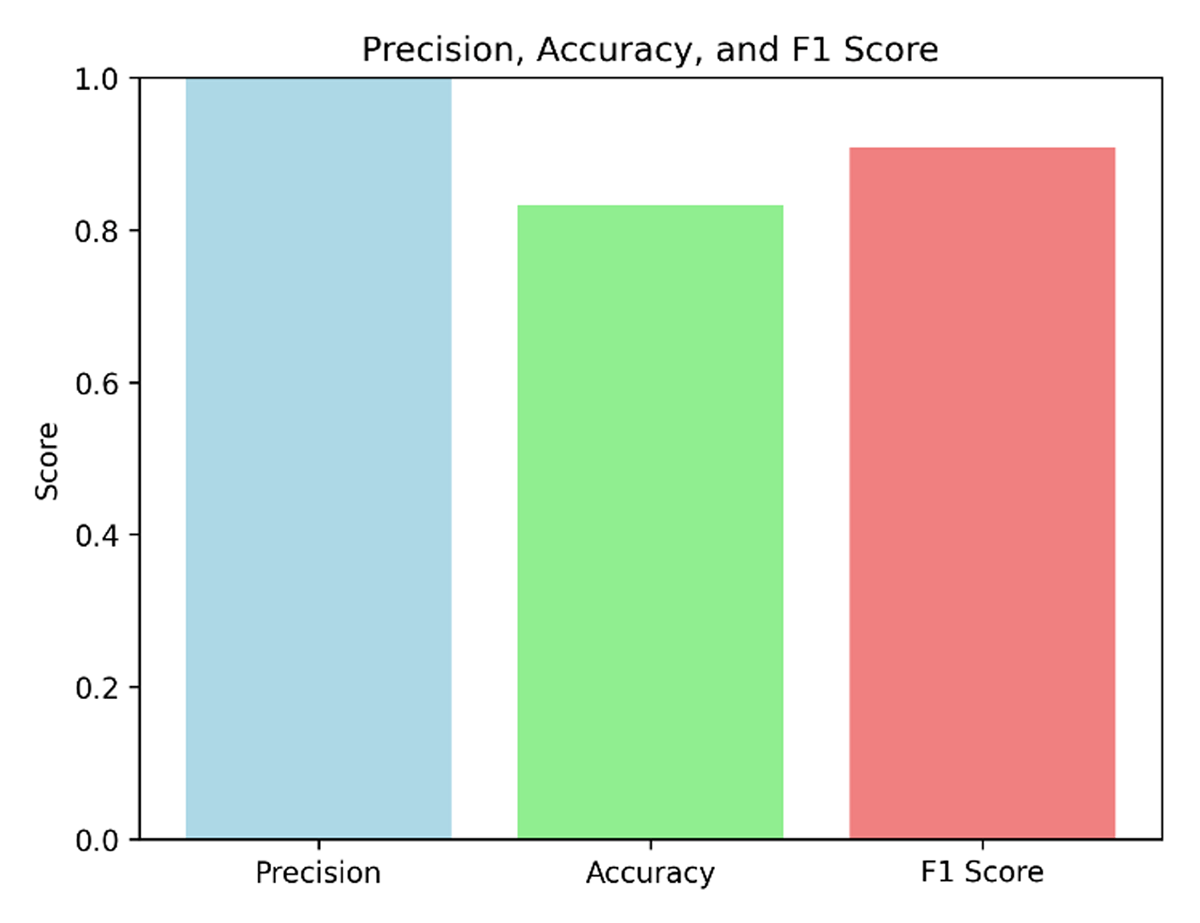
Figure 12
Evaluation of Our Approach.
To evaluate the accuracy of the extracted schemas following the embedding stage, we used precision, recall, and F1 scores by comparing the extracted schema components to a manually curated ground truth schema. This provided a clear benchmark for assessing the quality of the schema extraction process. Our method achieved an accuracy score of 0.833, demonstrating good coverage by correctly identifying over 83% of the triplets within the complex, nested structures of the NoSQL databases. Despite the challenges presented by deeply nested relationships, the approach balances precision and coverage effectively, leading to a strong F1-score of 0.909. This underscores the method’s reliability in extracting accurate schemas from both simple and intricate NoSQL data structures.
Our methodology offers a more comprehensive solution to schema extraction than existing approaches (Belefqih, Zellou and Berquedich, 2023), offering significant robustness and adaptability. The method generalizes effectively across a broad spectrum of NoSQL database formats, including Key-Value, Document-Based, Graph-Based, and Wide Column-Based databases. It seamlessly accommodates both simple data types, such as Strings, Integers, and Booleans, as well as more complex structures like Objects and Arrays. Leveraging a semantic triplet-based representation, it enables precise schema extraction from databases with highly nested architectures. This adaptability, coupled with its ability to handle complex data structures, ensures the resulting schema accurately reflects the intricate architecture of the underlying NoSQL database. The method’s versatility across different databases and data complexities further underscores its capability to deliver accurate, representative schema extraction, even in the most demanding data environments.
Nevertheless, certain limitations should be considered. The size and complexity of datasets can affect the accuracy of the extracted schemas, as larger datasets may introduce noise or outliers that complicate the extraction process. Noisy data and outliers can distort the accuracy of schema extraction by leading to incorrect or inconsistent embeddings, which in turn impacts the overall effectiveness of the process. Additionally, generating BERT embeddings is computationally intensive, which could hinder performance when processing large-scale datasets. Moreover, while BERT excels at generating rich, context-aware embeddings, its effectiveness depends on the quality of the pre-trained model. This reliance on pre-trained data may impact BERT’s ability to fully capture domain-specific terms, potentially affecting embedding accuracy.
In summary, the promising results validate our approach as an effective solution for schema extraction in schema-less NoSQL databases, with strengths in precision, accuracy, and handling complex data structures. Addressing scalability challenges and optimizing performance for larger, more complex datasets will be essential for future improvements. Additionally, enhancing BERT’s capacity to better understand domain-specific terms will further ensure the robustness of the method across diverse datasets.
7. Conclusions and Future Work
This research introduces a novel NLP-based method for extracting structured schemas from schema-less NoSQL databases. The proposed pipeline achieved strong results, with over 83% coverage and 100% precision on real-world datasets, demonstrating its robustness in handling complex, nested data structures. This approach presents practical benefits, including automating schema induction, improving metadata creation, enhancing query performance, and simplifying data integration, all while reducing storage and migration costs. Future work will focus on refining extraction thresholds, implementing parallel processing to improve scalability, and introducing outlier detection techniques to address noisy data. Additionally, integrating extracted triplets for semantic descriptions using Resource Description Framework Schema (RDFS) standards could further broaden the method’s applicability. Overall, this work opens new possibilities for automated schema extraction from unstructured data, highlighting its potential in database management and other practical applications.
Competing Interests
The authors have no competing interests to declare.
Author Contributions
Saad Belefqih: Conceptualization, methodology, formal analysis, writing – original draft.
Ahmed Zellou: Data curation, validation, writing – review & editing.
Mouna Berquedich: Supervision, writing – review & editing.