
1 Introduction
The FAIR principles, formulated in 2015 by Wilkinson et al. strive to enhance the findability, accessibility, interoperability, and reusability of research data (Wilkinson et al., 2016). Their goals align closely with those of the open data initiative, as mirrored by their inclusion into the UNESCO Recommendations for Open Science in 2021 (UNESCO, 2021).
Implementing FAIR data practices on the level of research performing organizations and research data repositories in a harmonized way is challenging. In the Helmholtz Association – Germany’s largest, federated, non-university research organization with 18 research centers, the Helmholtz Metadata Collaboration (HMC) platform was launched in 2019 to turn FAIR into reality. Its long-term goal is establishing a FAIR data space, as defined by Nagel et al. a ‘decentralized infrastructure enabling trustworthy data sharing’ and exchange within data ecosystems, founded on commonly-agreed principles and extending across research centers and domains. Helmholtz Metadata Collaboration is focused on bringing together technical and social solutions to improve FAIR data practices.
Here we discuss a three-step, data-driven approach to improving FAIR data practices in our federated research organization:
Measure: Where is research data in a cross-disciplinary, federated research organization published and what FAIR criteria does this data meet or not meet?
Learn: Identify data publishing themes and gaps towards improving the FAIRness of data.
Act: Engage communities and data infrastructure to implement steps to close identified gaps.
Iteration through these steps forms an effective feedback-loop towards improving FAIR data practices in a step-wise manner. After engaging communities and data infrastructure we reassess progress, identify next steps, and engage again. Over time this builds trust with our communities, which in turn leads to more and faster progress.
The first of these steps, finding research data outputs from a specific research performing organization or ecosystem is challenging. Institutional catalogs often contain only minor amounts of research data publications, since data historically was not recognized as a first-class research output. To find data publications associated with research articles, harvesting approaches often engage complex text mining workflows to extract data availability statements from research articles. This requires access to full-text articles and often also manual supervision, and hence additional resources. (Bassinet et al., 2023; Iarkaeva et al., 2023).
Alternative approaches include harvesting metadata directly from repositories; however, these often lack application programming interfaces and standardized affiliation metadata which would allow linking data publications back to the research organizations they were created at. Such an approach requires knowing which repositories to harvest from—you need to know where your community deposits its data. This itself is non-trivial—in HMC we have used a multi-method approach ranging from community surveys (Arndt et al., 2022) to manual mapping to answer the question of where Helmholtz research data lies.
In contrast, the data harvesting approach discussed in this contribution harvests the manually curated literature metadata provided by the research organization’s institutional libraries. As funding has historically been linked to this information there is a strong interest for it to be correct. Starting from these publications, linked data publications are identified by harvesting metadata that is openly available in so-called Scholix links, (Burton et al., 2017) as described in the methods section. In contrast to harvesting data citations from research articles only, Scholix links unveiled forward- and backward-references from literature to data publications and vice versa. As the approach relies on metadata in standard formats it is resource-light compared to text-mining workflows.
Since research data is on its way to becoming a first-class research output, quality metrics are required to allow for quality control of data publications. (Bahim et al., 2020; Castell et al., 2024; Cobey et al., 2023) Evaluating and monitoring how several thousands of data publications perform regarding the FAIR criteria requires automated tools like the F-UJI framework. (Devaraju & Huber, 2020; Devaraju & Huber, 2021; Huber & Devaraju, 2021) This provides useful information to identify and address gaps when counseling communities and infrastructure to effectively improve FAIR data practices.
In this contribution, the results obtained from a combined data harvesting and evaluation pipeline are presented in an openly accessible dashboard. Open science dashboards are widely used tools to monitor and communicate research outputs on institutional (BIH Quest, n.d.; BIH Quest Center for responsible research, 2024) to the national (Jeangirard, 2019) and international scales. (Liu et al., 2024; OpenAIRE, n.d.; OpenAlex, n.d.). Here, a dashboard approach is presented as an initial way to communicate data and results and to engage communities and infrastructure. This aligns with our overall strategy to measure, learn, and act on our way to a unified FAIR data space in our federated research organization.
2 Methods
To solve these challenges, we have built a pipeline to find data publications of a research organization. Our key approach is to identify data publications linked to literature, published at our research organization. The modules of this pipeline are schematically visualized in Figure 1.
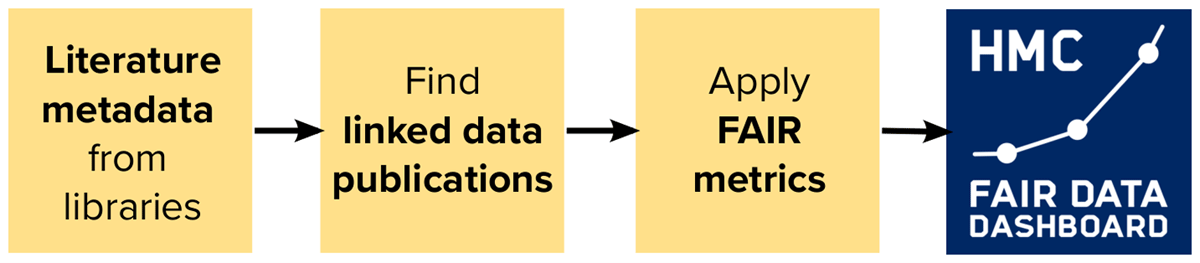
Figure 1
Schematic illustration of the modular pipeline used to find and assess linked data publications of a research organization.
First, metadata of literature publications is harvested from the OAI-PMH interfaces (Lagoze et al., 2015), as provided by the libraries of 15 research centers of our federated research organization (status: June 2023). Connection of further center libraries is underway. Library metadata is provided mainly in OAI-DC and MARC-XML formats. Harvesting from the manually curated literature catalogs of the research institutes in our federated research organization makes sure that, with a high probability, these and all linked ‘supplementary’ data publications found in the next step can be assumed to originate from these centers. This affiliation, and optionally other relevant metadata, is hence inferred from the literature to the linked data publications.
Second, for all literature PIDs (Persistent Identifiers) found in these literature catalogs, we identify linked datasets by harvesting Scholix-links (Burton et al., 2017) via the ScholExplorer API, (ScholExplorer, n.d.) representing a subset of the OpenAIRE research graph. All software code and data presented in this contribution are based on data collected in the first two quarters of 2023, collected with version 1 of the ScholExplorer API. In an upcoming, yet unpublished software update, version 2 is employed.
All harvested Scholix-links are filtered for the target-type to be dataset and the Scholix RelationshipType (in version 2 SubType) for the value IsSupplementedBy. This combination of filters selects an incomplete, yet reliable set of data publications with ‘supplementary’ and hence closely associated connection between literature and linked data publications. This is supported by manual analyses (Kubin, 2022) and and an evaluation of the most frequent Scholix RelationshipType (SubType) categories where we assumed that data publications with a ‘supplementary’ character, in relation to their linked literature publications, share similar titles and lists of author names (Kubin, 2024). The essence of this analysis is shown in Figure 2 and substantiates our choice of filters to maximize the confidence in the ‘supplementary’ character while minimizing false-positive hits for the data publications included in the dashboard.
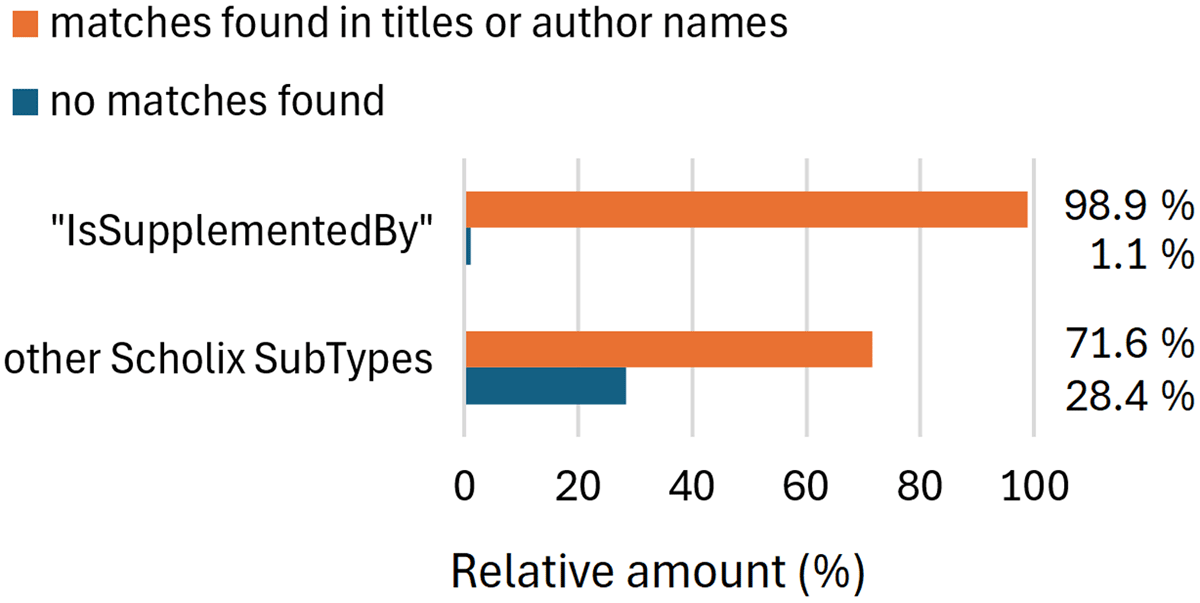
Figure 2
Evaluation of Scholix RelationshipTypes (SubTypes) based on sample data (Kubin, 2024). The category ‘matches found (…)’ requires at least 25% matches, on average, of significant words in the publication titles (excluding articles, prepositions, etc.) or at least one same author name.
Third, as a first approach to automated FAIR assessment of the datasets identified thereby, we have adopted the F-UJI framework (Devaraju & Huber, 2020; Devaraju & Huber 2021). F-UJI automatically tests 15 out of 17 FAIR principles based on metrics developed by the European FAIRsFAIR project (Devaraju et al., 2020). F-UJI scores were determined automatically for each dataset included in the dashboard, using a locally deployed docker image of F-UJI (Huber & Devaraju, 2021). The code and data discussed here are based on F-UJI version 1.4.7 and metrics in version 0.4. An upcoming, yet unpublished update employs F-UJI version 3 probing metrics in version 0.5.
The results retrieved with this approach are stored in a relational database and visualized in an interactive dashboard (Helmholtz-Metadata Collaboration, 2023). Separate sub-pages of the dashboard allow to explore statistics of data publications and FAIR-related aspects from different viewpoints, e.g., from the institute, repository, or the individual perspective to address target groups ranging from institutional data professionals and repository providers to individual researchers interested in improving FAIR data.
3 Results
Disclaimer: Data publication statistics presented here and in the dashboard are neither complete nor entirely free of falsely identified data publications. These numbers can be used to identify qualitative trends. If intended to be used for sensitive topics such as targeted funding, we highly recommend a manual review of the data. Please note that F-UJI cannot truly assess how FAIR data is but provides useful guidance for improving FAIR data.
With the data harvesting approach described in the methods section, 300’684 literature publications and 32’817 ‘filtered,’ linked data publications (see the methods section for details) have been identified in the time span from January 2000 to June 2023 for the 15 research centers harvested at that time.
The time evolution of these publication numbers is observed in Figure 3, as presented on the landing page of the dashboard. Since the data was collected in the middle of 2023, publication numbers decrease towards the end of the timeline. Before this decrease, literature publications range on a plateau on the order of 20,000 per year, data publications on the order of 3,000 per year.
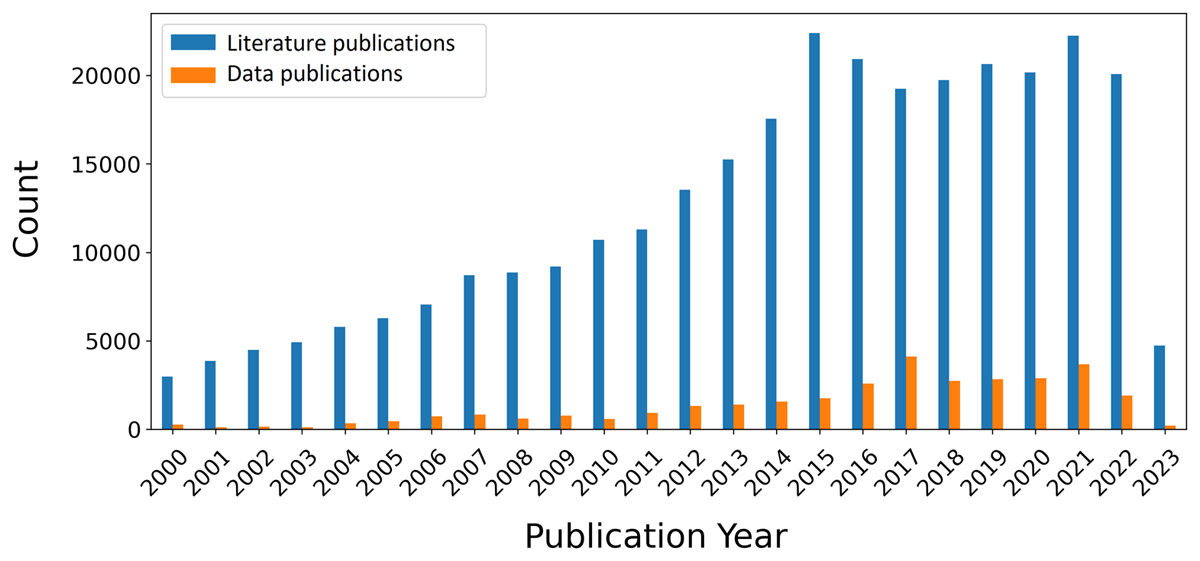
Figure 3
Time evolution of literature- and linked data-publication numbers (after filtering), as presented on the dashboard. (status: June 2023).
As motivated in the introduction, identifying the repositories that research communities use to publish research data is often challenging. Our data pipeline provides one approach to collecting this information. For the data on the dashboard, we identified a list of 56 unique publishers (repository providers).
Figure 4 shows an exemplary decomposition of annual publication numbers for the five most frequently found publishers. These range from non-institutional generic to non-institutional disciplinary and institutional disciplinary data repositories. This information can be used to learn about the time-evolution of community-specific data publishing practices and is a starting point for further analyses.
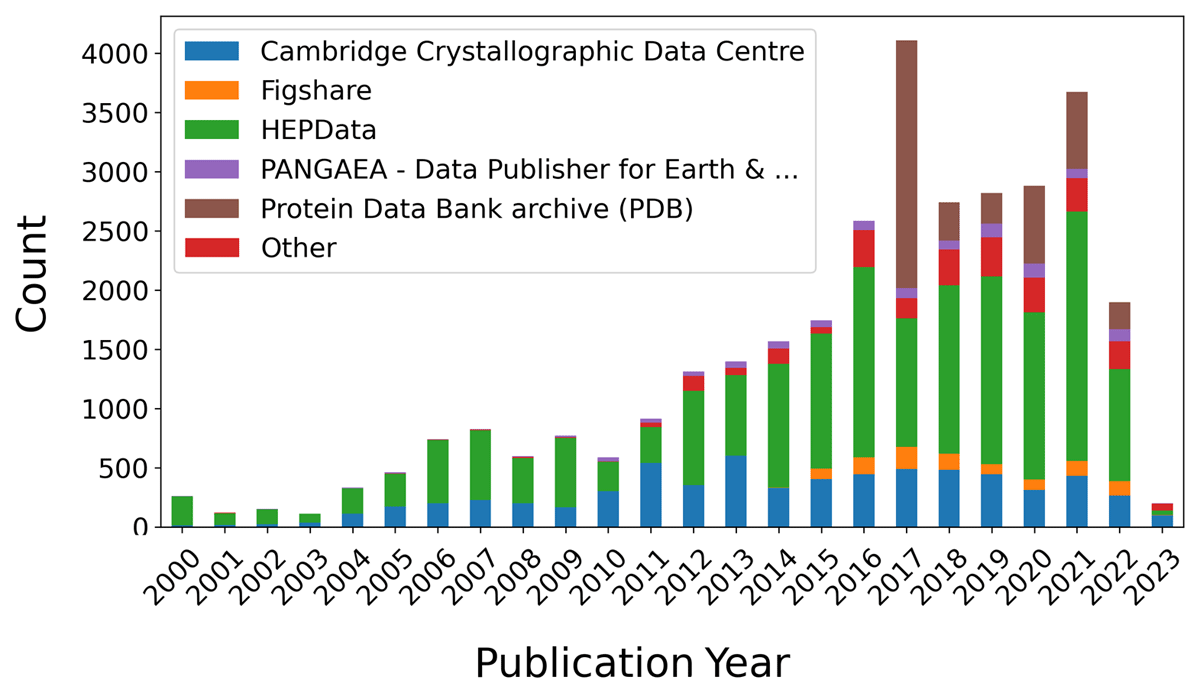
Figure 4
Time evolution of linked data publications contained in the dashboard approach, after filtering (status: June 2023). The color codes indicate the five most frequent publisher names associated to that data.
Integration of research data into a federated FAIR data space requires closing systematic gaps in the FAIRness of this data. Automated evaluation tools can help to identify such systematic gaps. In a first approach, we adopted the F-UJI framework to automatically perform a number of automated tests, probing specific aspects of FAIR. A weighted sum of scores for these tests leads to an overall score.
A histogram of overall F-UJI scores can be observed in Figure 5. It reveals several clusters with similar scores. The Figure also encodes information about how the five most frequently used data repositories are represented in that data. A prominent observation is the almost uniform F-UJI score for data published in a disciplinary data repository for the high energy physics communities. This observation indicates a major influence of data repositories on specific aspects of FAIR. We attribute this to repository-specific technical implementations.
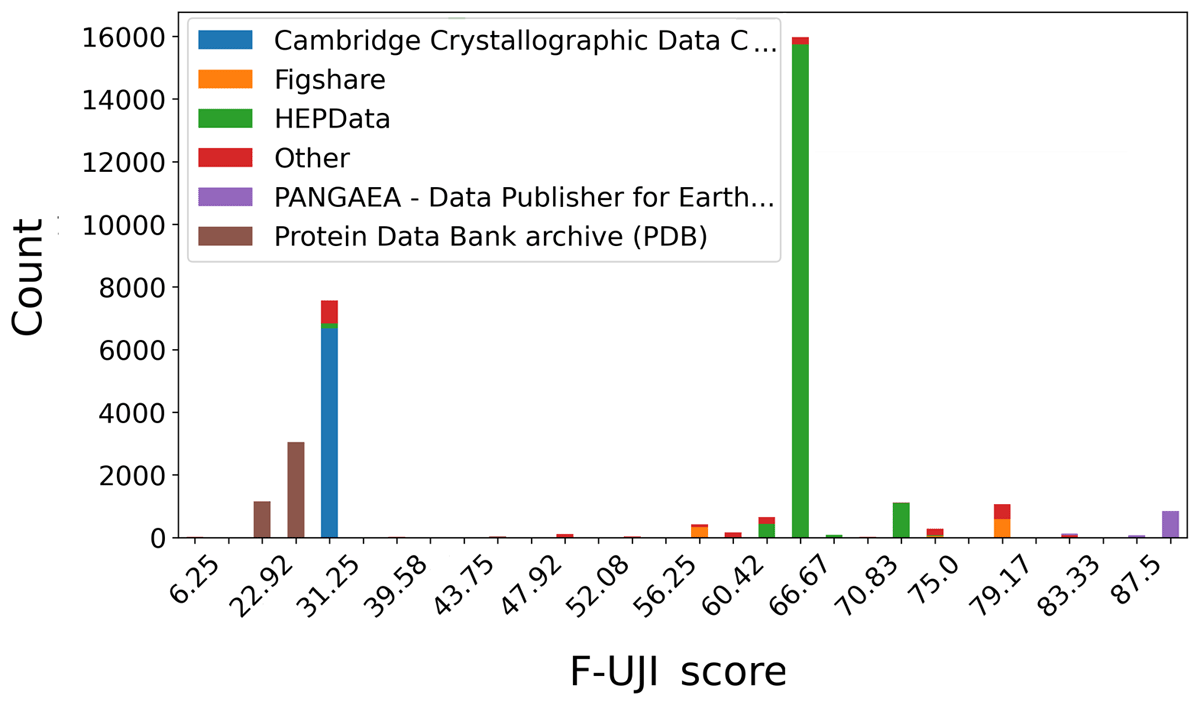
Figure 5
Histogram of scores determined with F-UJI version 1.4.7 for filtered data publications, as presented in the dashboard (status: June 2023). The color codes indicate the five most frequent publisher names associated with these data publications.
The dashboard allows for detailed inspection of the test results related to specific FAIR criteria and hence for targeted gap analyses. For example, a follow-up analysis for FAIR principle R1.1 (not shown) reveals that a large portion of data publications in crystallographic databases lack clearly identifiable human- or machine-readable license information. This contributes to the rather low overall scores for the cluster observed at the lower end of Figure 5. This example illustrates how the data shown in the dashboard can help to identify and visualize specific gaps related to specific aspects of FAIR on the level of data repositories.
4 Discussion
4.1 Findability of research data publications
Data publications, to be discovered and included in the dashboard, need to meet minimum requirements of findability (the F in FAIR). The dashboard, hence, systematically lacks research data that is neither indexed nor linked to literature publications. The list of 56 research repositories identified from the data harvesting pipeline overlaps only partially with (i) a list of institutional repositories with active contributions from our federated research organization (Helmholtz Open Science Office, n.d.) and (ii) a list of repositories derived from a broad community survey. (Arndt et al., 2022; Gerlich et al., 2022) We attribute this discrepancy (a) to the findability-bias and (b) to the finding that lots of research data is published in community-established, non-institutional, disciplinary repositories which are not included in the list of institutional data repositories. This also shows the importance of a multi-method approach.
Our advice to research data infrastructure who strive to improve the findability of data publications by automated approaches is, hence, (a) to register persistent identifiers (e.g. DOIs) with metadata records and (b) to include qualified links (for example, when choosing DataCite, by using the field relatedIdentifiers to link related research outputs while specifying the field relationType for the relationship between the primary and the linked research outputs). Specifically, when registering a PID at DataCite for data that directly supplements a research article, the use of the term IsSupplementTo supports an improved findability and a clearer assignment of its relationship to the research article. The evaluation of Scholix links for literature and linked data publications (Kubin, 2024) indicates that a considerable amount of data publications is not identified by the filter mechanisms discussed here. A reason for this could be inconsistent registration practices of relationship types by research data infrastructure or publishers.
A general advice to those publishing research articles is to incentivize research communities to ‘formally’ cite supplementary data publications in the reference list with their persistent identifiers. Manual sampling of the literature harvested indicated that data citation practices in research articles are heterogeneous, ranging from mentioned database IDs to data availability statements with a data citation in the reference list. Along the lines of Gregory et al. (2023), this greatly improves the findability of supplementary data publications by humans and machines. Changing the culture of data citation practices will involve stakeholders from data infrastructure providers, journal publishers and research communities. Communication to include the topic of data citation practices into training curricula is underway. A future topic to study with adaptations of the dashboard could focus on data citation practices.
4.2 FAIR evaluation of research data
The data harvesting and evaluation pipeline presented here adopted the F-UJI framework as one prominent example for automated FAIR evaluation of research data. As illustrated in the Results section, testing specific, machine-actionable aspects of the FAIR principles can provide useful guidance for identifying and closing systematic gaps in FAIR data practices, particularly on the level of research data infrastructures. For the future, we aim at integrating complementary evaluation frameworks to ensure cross-validation of results.
Most machine actionable aspects of FAIR depend on the research data infrastructure used to make data available. As discussed above, critical infrastructure to ensure findability and accessibility of research data is in the hands of repository providers. In addition, they can help by technically supporting machine-understandable metadata in standardized metadata records and on the landing pages as well as by incentivizing the use of license information to enable the reuse of research data.
A pilot approach to counseling research data infrastructure providers revealed first insights into repository providers’ needs ranging from (a) metadata considerations and consultation, (b) addressing technical questions, and (c) general guidelines and resources to (d) FAIR metrics and tools. We would also like to highlight the expressed need for (e) networking and exchange with other institutional repository providers. We aim at further intensifying our exchange with data infrastructure providers in the future. The dashboard was a useful communication tool for such an individual counseling session and further consultancy approaches are underway.
Manual FAIR evaluation of research data based on the FAIR Data Maturity Model (Bahim et al., 2020; FAIR Data Maturity Model Working Group, 2020) complementary to the automated assessment with F-UJI, shows that on the dataset level, interoperability and reusability of research data rather depends on the researchers and data professionals producing and curating the data. (Günther et al., 2024; Kubin et al., 2022) Improving these requires effective strategies to implement and harmonize metadata practices across researchers and data professionals. Models on how to engage communities on the practical implementation of the FAIR principles are described, for example, in recent articles by Belliard et al. (2023) and Rocca-Serra et al. (2023).
5 Conclusion
We have established a data collection and analysis pipeline to monitor and assess the state of FAIR data within our federated research organization. The data collected in this way can be explored interactively in an open-access dashboard aimed at various communities. The dashboard serves several purposes: It enables the identification of the research data infrastructure used by researchers within the research organization to make their research data available, it enables the review of assessment results regarding the FAIRness of data publications, and helps to identify gaps on the way to a unified FAIR data space. It engages both the research communities and data infrastructure providers, fostering collaboration and improving data management practices. By providing this interactive dashboard, we aim to improve the visibility and accessibility of research data assets within our organization while making progress towards FAIR data practices on a broad scale.
Data Accessibility Statement
The data discussed in this contribution and presented on the dashboard (Helmholtz-Metadata Collaboration, 2023), and data used to analyze Scholix RelationshipType categories, are published on Zenodo (Kubin, 2024; Kubin et al., 2024).The source code developed for the harvesting pipeline (Preuß et al., 2024) and the interactive dashboard (Sedeqi et al., 2024) is published on Zenodo and on GitLab. (Helmholtz Metadata Collaboration, 2023).
Acknowledgements
We thank the Helmholtz libraries for the friendly support in setting up OAI-PMH harvesting pipelines, the Helmholtz Open Science Office for many useful discussions, individual test users providing essential feedback for improving the usability of the dashboard, and the staff of RODARE for the insightful discussions.
Funding information
This project was developed by HMC Hub Matter, located at Helmholtz-Zentrum Berlin (HZB) and part of the Helmholtz Metadata Collaboration (HMC), an incubator-platform of the Helmholtz Association within the framework of the Information and Data Science strategic initiative.
Competing Interests
The authors have no competing interests to declare.
Author Contributions
Author contributions are summarized following the CRediT taxonomy: M.K. conceptualized the study. M.K, M.R.S, G.P. curated the data. M.K, M.R.S, A.S, A.G, G.G. formally analyzed the data. M.K, M.R.S, A.S, A.G, T.G, V.S, G.G, N.L.W, G.P. conducted the investigation. M.K, M.R.S, A.S, A.G, T.G, V.S, G.P, O.M developed the methodology. M.K. administrated the project. M.K, A.G, G.G, N.L.W, G.P, O.M provided study materials (resources). M.K, M.R.S, A.S, A.G, T.G, G.P. worked on the software. M.K, O.M supervised the project. M.K, M.R.S, A.S, A.G, G.G, G.P. validated the data. M.K, M.R.S, A.S, A.G, V.S. visualized the data. M.K. wrote the original draft of this report. M.K, T.G, N.L.W, G.P, O.M reviewed and edited the report.