
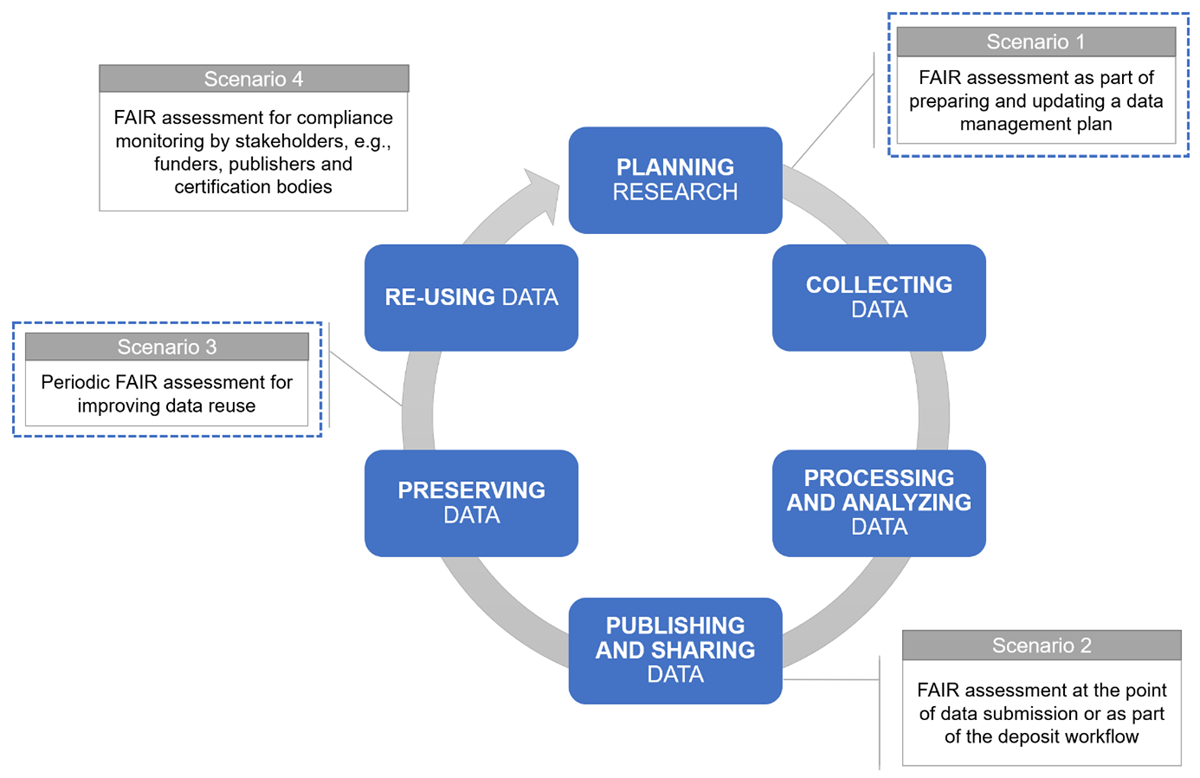
Figure 1
Research data lifecycle.
Table 1
Scenarios for FAIR data assessment.
| SCENARIO | SHORT DESCRIPTION | IMPLEMENTATION |
|---|---|---|
| 1 | Researchers want to check their plans for producing FAIR data at the outset of their project as part of a data management plan (DMP) process and to periodically assess FAIRness over the life of their project through updating their DMP. They also want to check that selected data are as FAIR as possible before depositing the data in any repository for wider sharing (e.g., using FAIR-Aware as detailed in section 5.1). | The assessment can be implemented by providing manual checklists or automated assessment as part of e.g., data management planning tools and could involve Research Performing Organization, Funders and/or Publishers. |
| 2 | Data repositories and researchers want to make it easier to provide FAIR data during the deposit process and at the point of submission to the repository. | This can be implemented by either a manual, automatic or semi-automatic checklist tool tailored to a repository’s data curation practice or by implementing a repository feature to automatically check certain aspects as part of the deposit workflow. |
| 3 | Data repositories want to periodically re-assess the FAIRness of the datasets they hold (e.g., using F-UJI as detailed in section 5.2). | This would support an internal review of data service provision and can be implemented by an automated assessment tool for published datasets. |
| 4 | Additional stakeholders (e.g., funding bodies, publishers, and certification bodies) may want to monitor research data compliance and adjust their policies and requirements accordingly. | The assessment tool to address scenario 3 can be adapted and integrated with the stakeholder’s processes. |
Table 2
FAIRsFAIR Object Assessment Metrics (v0.3).
| FAIRSFAIR OBJECT METRIC | RDA FAIR DATA MATURITY MODEL | ADOPTION AND IMPROVEMENT |
|---|---|---|
| FsF-F1-01D Data is assigned a globally unique identifier. | RDA-F1-02D Data is identified by a globally unique identifier | No changes to the indicator, but assessment details and related resources are specified. |
| FsF-F1-02D Data is assigned a persistent identifier. | RDA-F1-01D Data is identified by a persistent identifier RDA-A1-03D Data identifier resolves to a digital object | Merged two overlapping indicators on persistence and resolvability. |
| FsF-F2-01M Metadata includes descriptive core elements (creator, title, data identifier, publisher, publication date, summary, and keywords) to support data findability. | RDA-F2-01M Rich metadata is provided to allow discovery | Refined the indicator by clarifying core metadata descriptors. |
| FsF-F3-01M Metadata includes the identifier of the data it describes. | RDA-F3-01M Metadata includes the identifier for the data | No changes to the indicator, but its assessment verifies the identifiers of the data and data content. |
| FsF-F4-01M Metadata is offered in such a way that it can be retrieved by machines. | RDA-F4-01M Metadata is offered in such a way that it can be harvested and indexed | Rephrased to avoid jargon and put emphasis on automated (machine-aided) retrieval. |
| FsF-A1-01M Metadata contains access level and access conditions of the data. | RDA-A1-01M Metadata contains information to enable the user to get access to the data | Extended the assessment by distinguishing access conditions by different data types. |
| FsF-A2-01M Metadata remains available, even if the data is no longer available. | RDA-A2-01M Metadata is guaranteed to remain available after data is no longer available | Narrowed down the scope of the assessment to deleted or replaced objects. On a practical level, this indicator applies to repository assessment as continued access to metadata depends on a data repository’s preservation practice. |
| FsF-I1-01M Metadata is represented using a formal knowledge representation language. | RDA-I1-02M Metadata uses machine-understandable knowledge representation | No changes to the indicator, but assessment details and related resources are specified. |
| FsF-I1-02M Metadata uses semantic resources. | RDA-I1-01M Metadata uses knowledge representation expressed in standardized format | Distinguished two types of semantic resources which comprise the resources for modelling data (e.g., dcat) and the other for describing ‘contents’ (e.g., taxonomy). |
| FsF-I3-01M Metadata includes links between the data and its related entities. | RDA-I3-01M Metadata includes references to other metadata RDA-I3-02M Metadata includes references to other data RDA-I3-02D Metadata includes references to other metadata RDA-I3-04M Metadata includes qualified references to other data | Merged overlapping indicators as a data object may be linked to n-types of related entities. |
| FsF-R1-01MD Metadata specifies the content of the data. | RDA-R1-01M Plurality of accurate and relevant attributes are provided to allow reuse | Addressed a specific aspect of metadata plurality, which examines if the contents of a dataset are specified in the metadata, and it should be an accurate reflection of the actual data deposited. |
| FsF-R1.1-01M Metadata includes license information under which data can be reused. | RDA-R1.1-01M Metadata includes information about the licence under which the data can be reused RDA-R1.1-02M Metadata refers to a standard reuse licence | Combined indicators. Standard and bespoke licenses are verified as part of the assessment. |
| FsF-R1.2-01M Metadata includes provenance information about data creation or generation. | RDA-R1.2-01M Metadata includes provenance information according to community-specific standards | Refined by providing minimal metadata properties representing data provenance. |
| FsF-R1.3-01M Metadata follows a standard recommended by the target research community of the data. | RDA-R1.3-01M Metadata complies with a community standard | Rephrased for clarity and to highlight the research community. |
| FsF-R1.3-02D Data is available in a file format recommended by the target research community. | RDA-R1.3-01D Data complies with a community standard | Rephrased for clarity and extended the assessment to cover both open and future-proof file formats. |
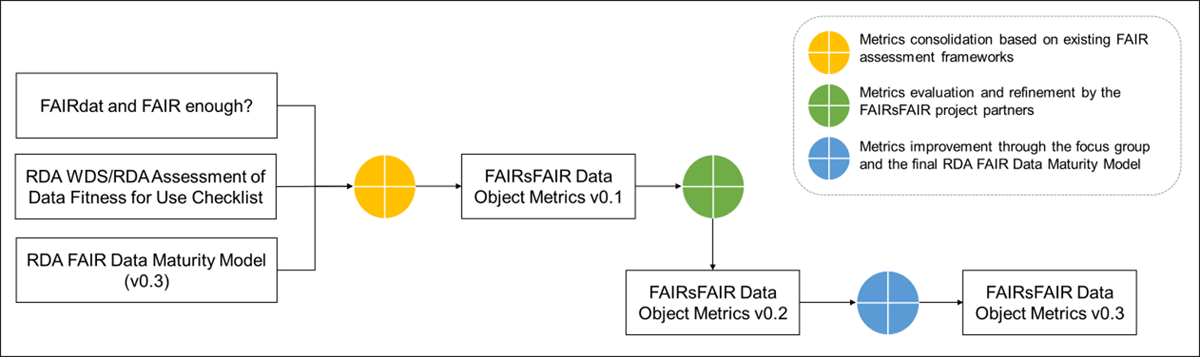
Figure 2
The Development of the FAIRsFAIR Data Object Metrics.
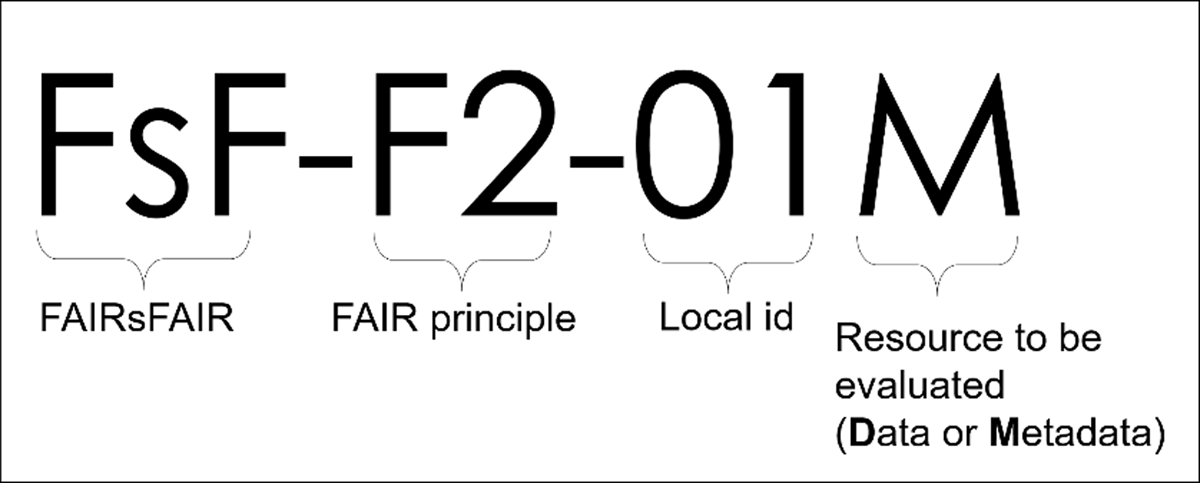
Figure 3
Anatomy of FAIRsFAIR metric identifier.
Table 3
Use cases, related scenarios, and tools.
| USE CASE | ASSESSMENT SCENARIO (AS LISTED IN TABLE 1) | ASSESSMENT TOOL |
|---|---|---|
| Stakeholders (e.g., institutions, data service providers) offer a generic manual self-assessment tool to educate and raise awareness of researchers on making their data FAIR before publishing the data. | 1 | FAIR-Aware (section 5.1) |
| A data service provider (e.g., data repository, data portal or registry) committed to FAIR data provision wants to programmatically measure datasets for their level of FAIRness over time. | 3 | F-UJI (section 5.2) |

Figure 4
FAIR-Aware self-assessment tool.13
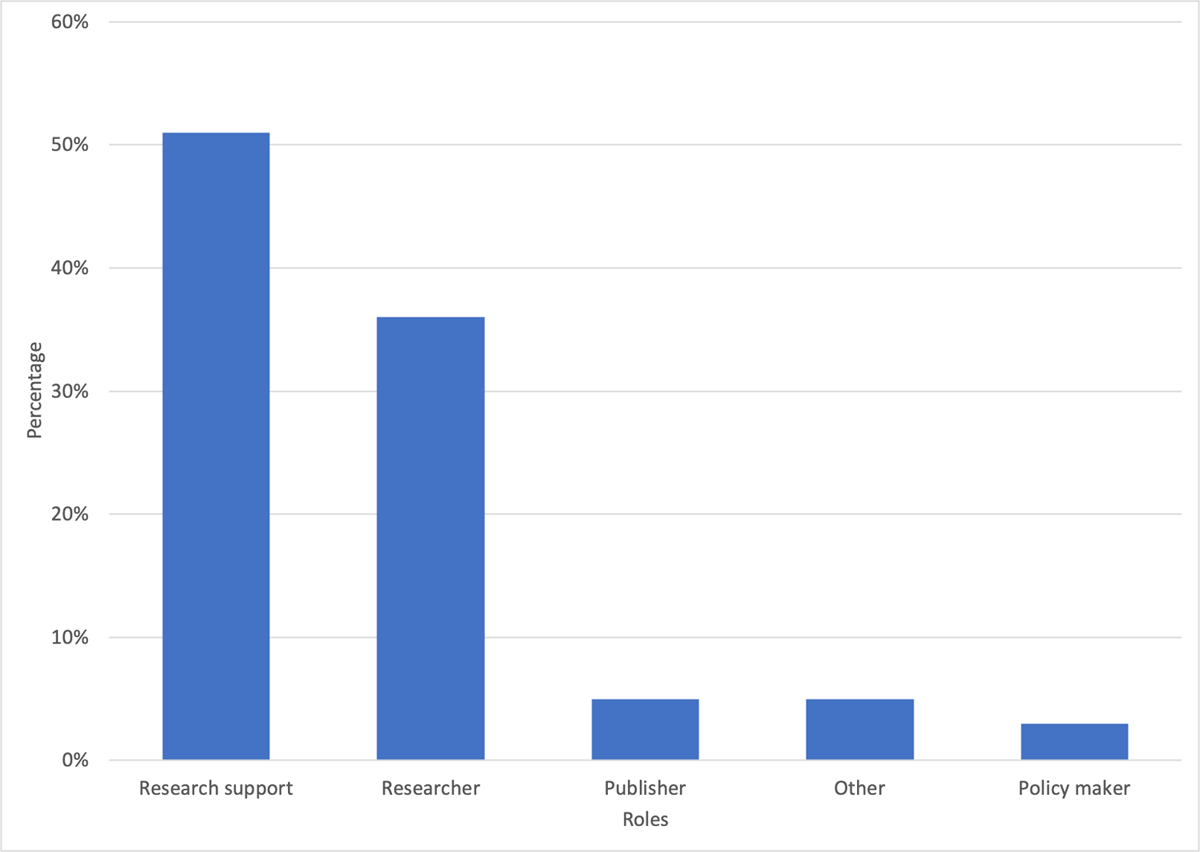
Figure 5
Testers covered a total of 59 roles with a majority identifying themselves as research support staff, followed by researchers (n = 49).
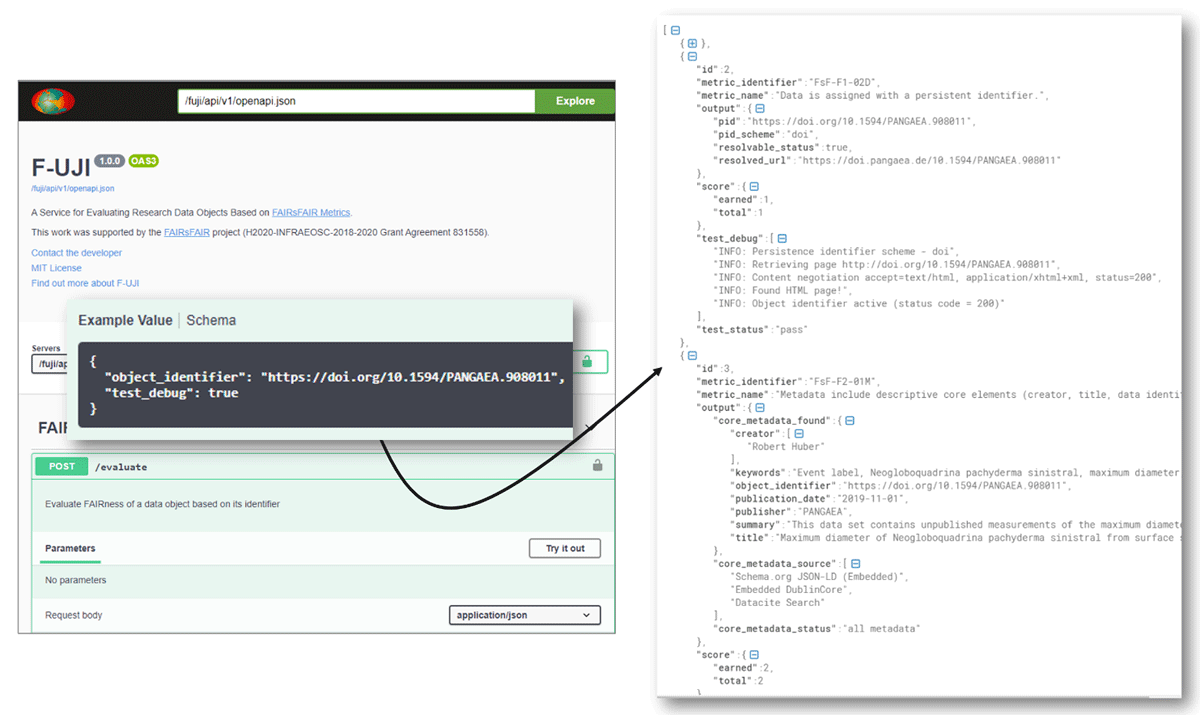
Figure 6
An automated assessment of the FAIRness of data objects through the F-UJI service.
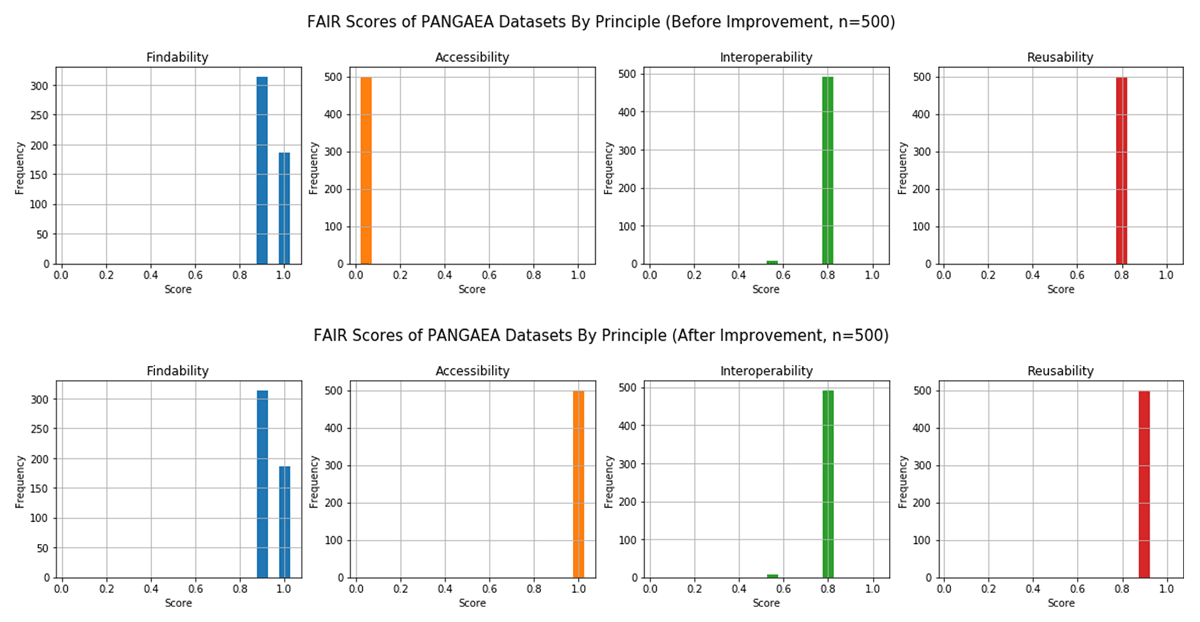
Figure 7
FAIR scores of the PANGAEA datasets before (upper part) and after improvement of metadata (lower part).