
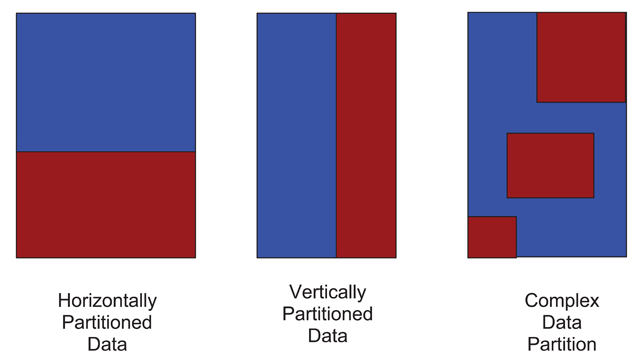
Figure 1
Different partitions of data ownership within a database.
Table 1
MPC architectures.
| Model | Trust Requirements | Performance | Involvement of data owners | Scalability with number of data owners |
|---|---|---|---|---|
| Single cloud | Low | Low | Low | Good |
| Multiple cloud providers | Medium | High | Low | Good |
| Private servers | Low | Medium | High | Bad |
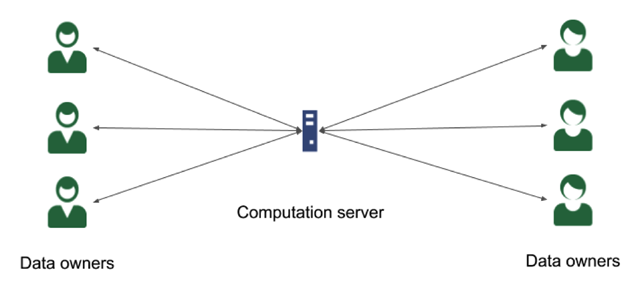
Figure 2
Data owners send (encrypted) data to the computation server, the server performs the computation, and returns (encrypted) results. In this protocol, the server learns nothing about the underlying data. The computational burden on the data owners does not increase as the complexity of the computation increases.
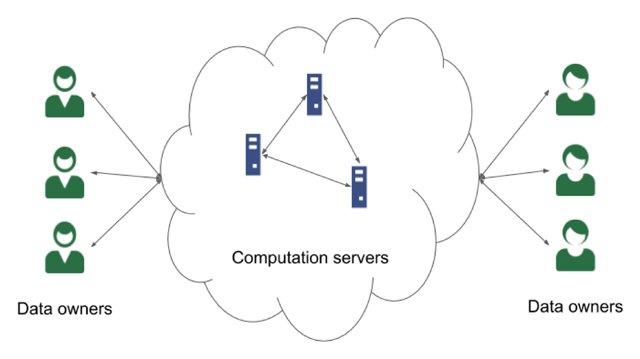
Figure 3
The data owners “secret-share” their data among a small number of computation servers. The servers execute an MPC protocol and return the result (or encryptions of the result) to the data owners (or an analyst). In this model, the data owners must trust the computation servers not to collude. If the servers do not collude, then the servers learn nothing about the data (or nothing beyond what is revealed by the output of the computation alone if the result is returned in the clear). The computational burden on the data owners does not increase as the complexity of the computation increases.
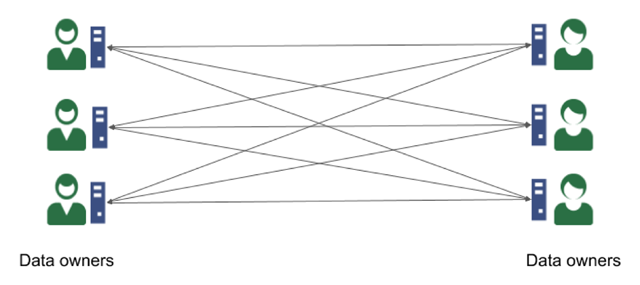
Figure 4
The data owners play the role of computation servers, and each data owner installs and runs the MPC client software locally. In this model, the data owners no longer have to trust the computation servers not to collude. On the other hand, the this increases the computational (and communication) burden of the data owners who must now execute the MPC protocol themselves. Since all data owners must now communicate with all other data owners, the communication cost of this architecture does not scale to support a large number of data owners.