
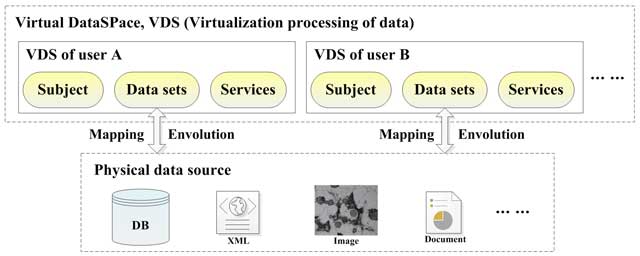
Figure 1
The basic structure of the relationships between subject, data sets, and services in VDS.
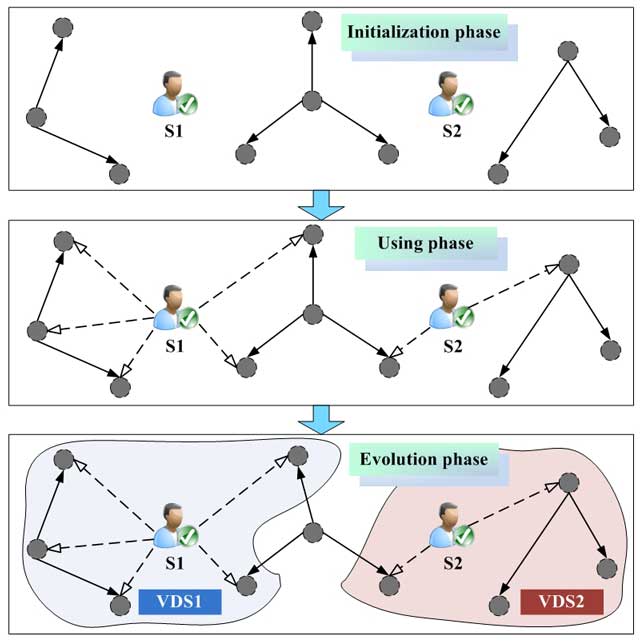
Figure 2
The working principle of VDS in different stages.

Figure 3
The user requirement model of VDS.
Table 1
The evolution algorithm of schema matching using the feedback instances.
| Algorithm. RefineMappings (Map Mi, UFI instan) | ||
| Inputs Map: A set of candidate mappings | ||
| UFI: A set of user feedback instances | ||
| Outputs Map: A set of refined mappings | ||
| Begin | ||
| 1 | If (Mi ≠ null){ | |
| 2 | S_Map = Mi; | |
| 3 | O_Map; | |
| 4 | Foreach OL ∈ S_Map { | |
| 5 | If (OL ≠ null) | |
| 6 | {Add <OL, OG> To O_Map} | |
| 7 | } | |
| 8 | AnnotateMappings(O_Map, UFI); | |
| 9 | C_Map = CombineMappings(O_Map); | |
| 10 | Return C_Map; | |
| 11 | } | |
| End | ||
Table 2
Characteristics comparison between VDS and traditional data management methods.
| Traditional database | Semantic data integration | VDS | |
|---|---|---|---|
| Data object | Data in relational database | All data | All data |
| Data mode | Relational model (Schema-First) | Ontology model (Schema-First) | Multiple models (Schema-Later) |
| Data type | Structured data (tables) | Structured data, Semi-structured data, Non-structured data | Structured data, Semi-structured data, Non-structured data |
| Data source | Single source, isomorphism | Multi-source, heterogeneous | Multi-source, heterogeneous |
| Data association | Simple association, structural stability | Complex association, structure is relatively stable | Complex association, dynamic evolution |
| Semantic | Without semantic | Pre-established semantic information | Gradually improved semantic information |
| Quality of data access | Accurate and complete results | Accurate and complete results | Currently optimal results (Best-effort) |
| Construction and services | First building, after use (Pay-before-you-go) | First building, after use (Pay-before-you-go) | Construction and optimisation with use (Pay-as-you-go) |
Table 3
The model comparison of dataspaces.
| Model comparison | iDM (ETH Zürich) | UDM (University of Washington) | P-DM (Stanford University) | T-DM (Carleton University) | CSM (Renmin University of China) | VDM (USTB) |
|---|---|---|---|---|---|---|
| Data source | Centralised, heterogeneous data | Centralised, heterogeneous data | Distributed, heterogeneous data | Distributed, heterogeneous data | Centralised, heterogeneous data | Distributed, heterogeneous data |
| Model structure | Based on the graph | Based on the sort tree | Based on the probability mode | Based on the RDF | Based on the graph | Based on the ontology |
| Integration approach | Only database | Database, information extraction | Data integration | RDF | Association rules | Semantic integration |
| Applicable field | Personal Information Management (PIM) | Personal Information Management (PIM) | Not involved in the specific application areas | Not involved in the specific application areas | Personal Information Management (PIM) | The field of materials engineering |
| Uncertainty | Does not support | Does not support | Support | Does not support | Does not support | Support |
| Subject feature | Does not consider | Does not consider | Does not consider | Does not consider | Individual users as the core | Users in material field as the core |
| Applicability | Good query performance, and support the semantic | Query interface | Support the top-k sorting query results | The processing capability of query language is strong | Support the multi-faceted semantic queries | Diversified query strategy and strong semantic support |
Table 4
The comparison of MatVDS and other dataspace systems in the initialisation phase.
| Prototype system | Data type | Location of data source | Integration model | Type of schema integration | Processing of schema integration | Endpoints of schema matching | Processing procedure of mapping |
|---|---|---|---|---|---|---|---|
| MatVDS | Structured (stru), semi-structured (semi), unstructured (unst) | Local, distributed | Proprietary model | Union, merge | Automatic, manual | Source mode (sour) and integrated mode (inte) | Automatic |
| OrientSpace | stru, semi, unst | Local | Proprietary model | — | Automatic | — | Automatic |
| SEMEX | stru, semi, unst | Local, distributed | Proprietary model | Merge | Manual | sour & inte | Automatic |
| iMeMex | stru, semi, unst | Distributed | Proprietary model | Union | Automatic | sour & sour | Semi-automatic |
| PayGo | stru | Distributed | Proprietary model | Union | Automatic | sour & sour | Automatic |
| UDI | stru | Local | Proprietary model | Merge | Automatic | sour & sour, sour & inte | Automatic |
| Roomba | — | — | Universal model | Union | Automatic | sour & sour | Automatic |
| Quarry | semi | Local | Universal model | Union | Automatic | — | — |
| Cimple | stru | Distributed | Proprietary model | Merge | Manual | sour & sour, sour & inte | Semi-automatic |
| CopyCat | stru, semi | Distributed | Proprietary model | Union | Semi-automatic | sour & sour | Semi-automatic |
| Octopus | stru, semi | Distributed | Proprietary model | Merge | Semi-automatic | sour & inte | Semi-automatic |
Table 5
The comparison of MatVDS and other dataspace systems in the use phase.
| Prototype system | User interest and behaviour | Load | Query type | Query result |
|---|---|---|---|---|
| MatVDS | Consider the user interests and behaviour habits | Pre-integrated, and dynamic evolution | Keyword query, structured query, visualisation query | Union |
| OrientSpace | Consider the behaviour characteristics and habits | Dynamic evolution | Keyword query, structured query | Union |
| SEMEX | Does not consider | Run-time integration | Keyword query, structured query | Merge |
| iMeMex | Does not consider | Run-time integration | Keyword query, structured query | Union |
| PayGo | Does not consider | Run-time integration | Keyword query | Union |
| UDI | Does not consider | Run-time integration | Structured query | Merge |
| Roomba | Does not consider | Pre-integrated | Keyword query, structured query | Merge |
| Quarry | Does not consider | Run-time integration | Structured query | Union |
| Cimple | Does not consider | Run-time integration | Keyword query, structured query | Merge |
| CopyCat | Does not consider | Pre-integrated | Visualisation query | Union |
| Octopus | Does not consider | Pre-integrated | Keyword query | Merge |
Table 6
The evolutionary comparison of MatVDS and other dataspace systems.
| Prototype system | Use output | Evolution method | Evolution processing |
|---|---|---|---|
| MatVDS | Sort results, browsing, sources | A variety of user feedback instances, explicit and implicit | Matching and mapping, the user requirement model |
| OrientSpace | Sort results, browsing, sources | User behaviour, implicit | Core dataspace, task space, associated information |
| SEMEX | Results, browsing | — | — |
| iMeMex | Results, browsing, sources | — | — |
| PayGo | Sort results | User feedback, explicit | Sorting query results |
| UDI | Sort results | — | — |
| Roomba | Results | User feedback, explicit | Matching |
| Quarry | Results, browsing | User feedback, explicit | Matching |
| Cimple | Sort results, browsing | User feedback, explicit | Matching |
| CopyCat | Results, sources | User feedback, explicit | Integration mode, mapping |
| Octopus | Results | User feedback, explicit | Integration mode, mapping |
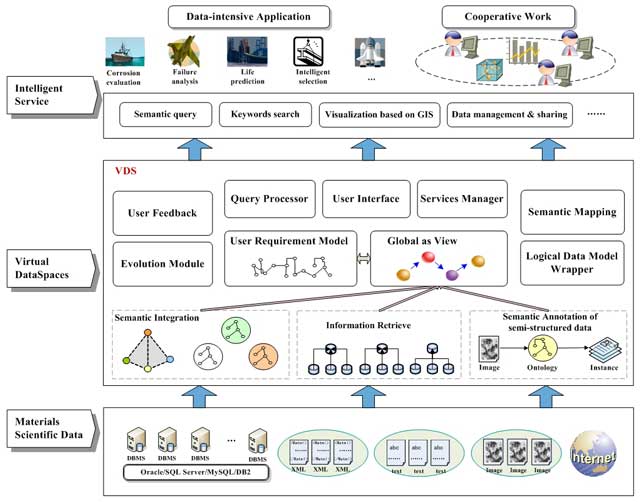
Figure 4
The system architecture of MatVDS.

Figure 5
The collection of intelligent services in MatVDS.

Figure 6
The demand-oriented data service instance in MatVDS.