

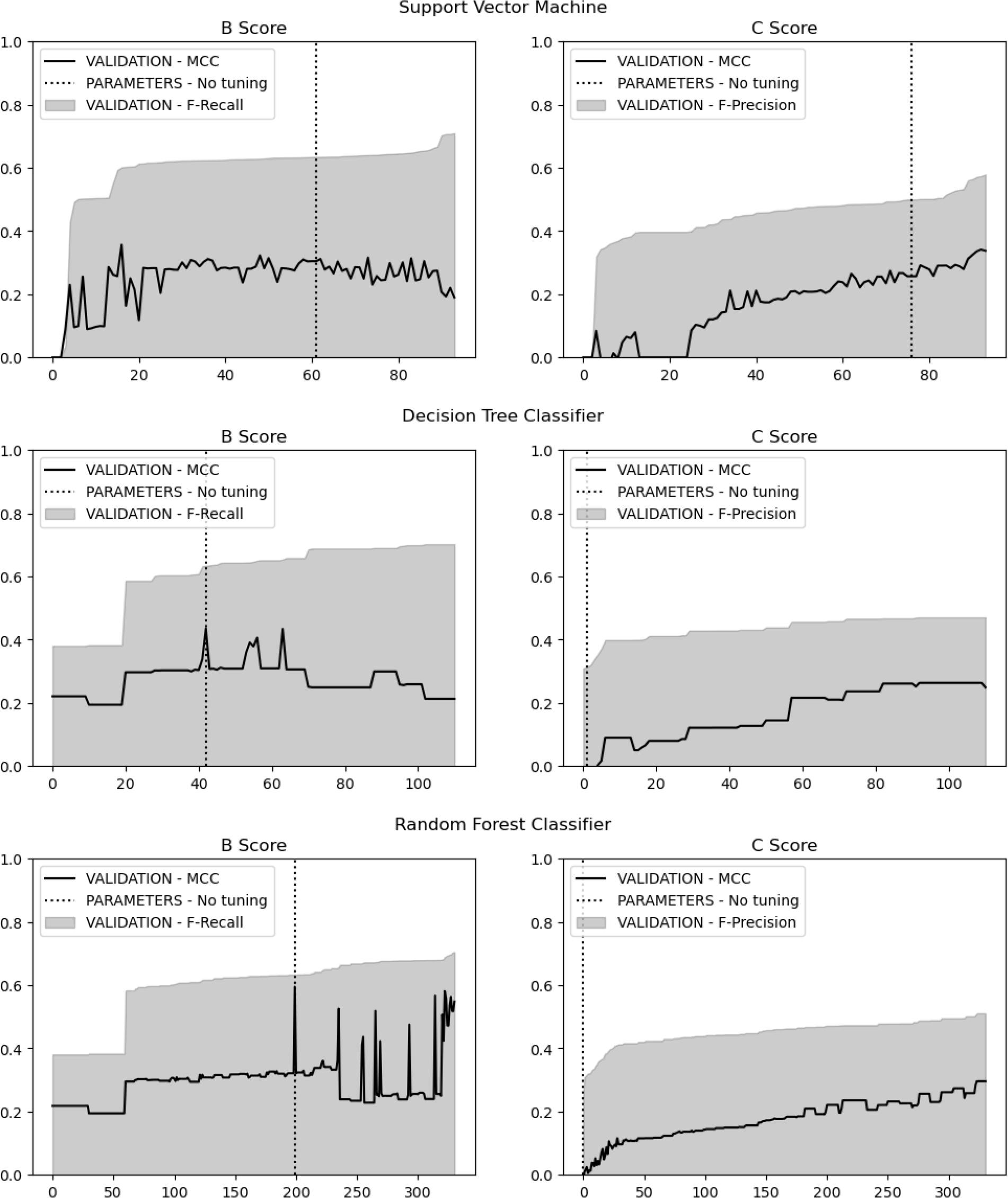
Figure 1.
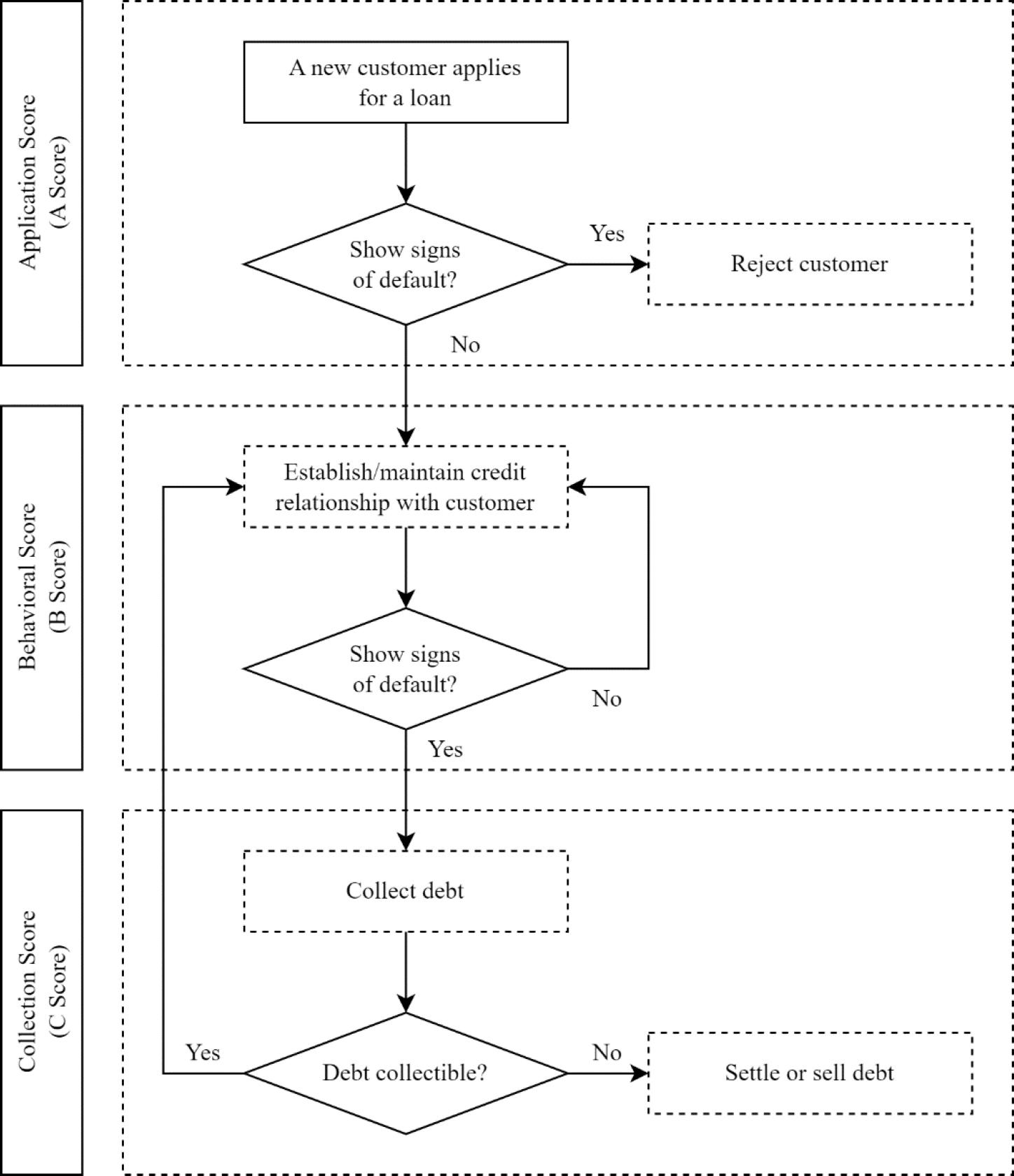
Figure 2.
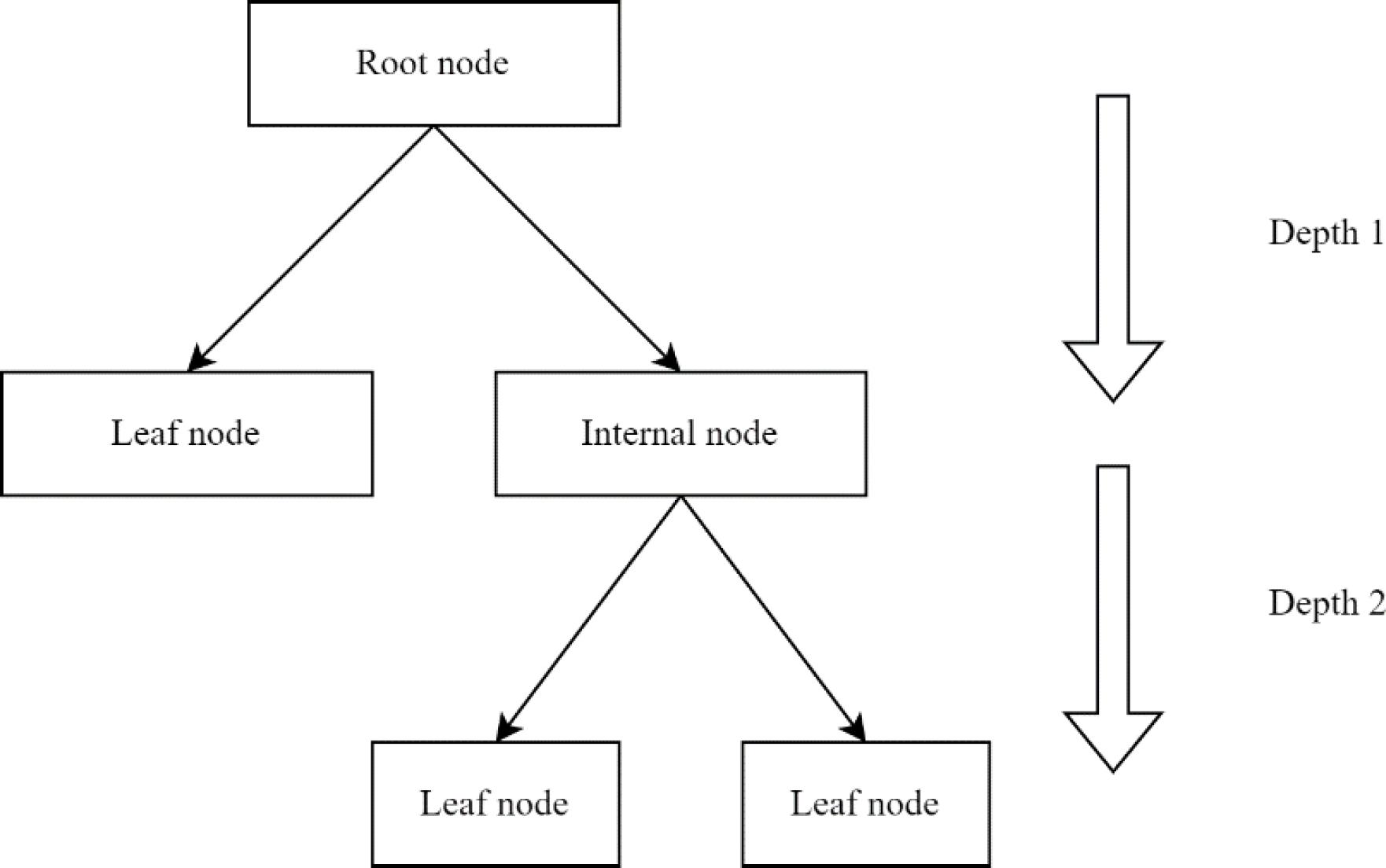
Figure 3.
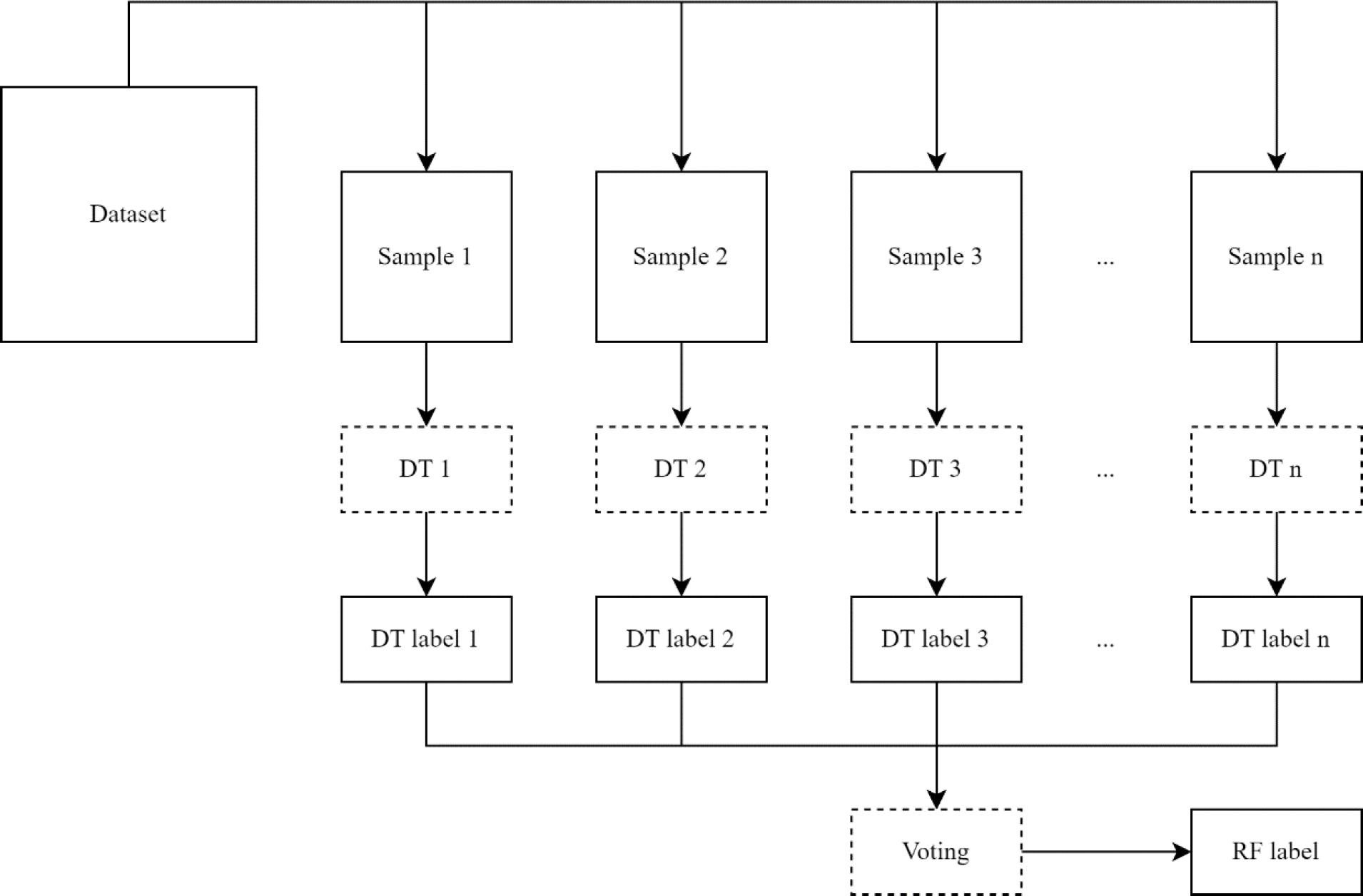
Figure 4.
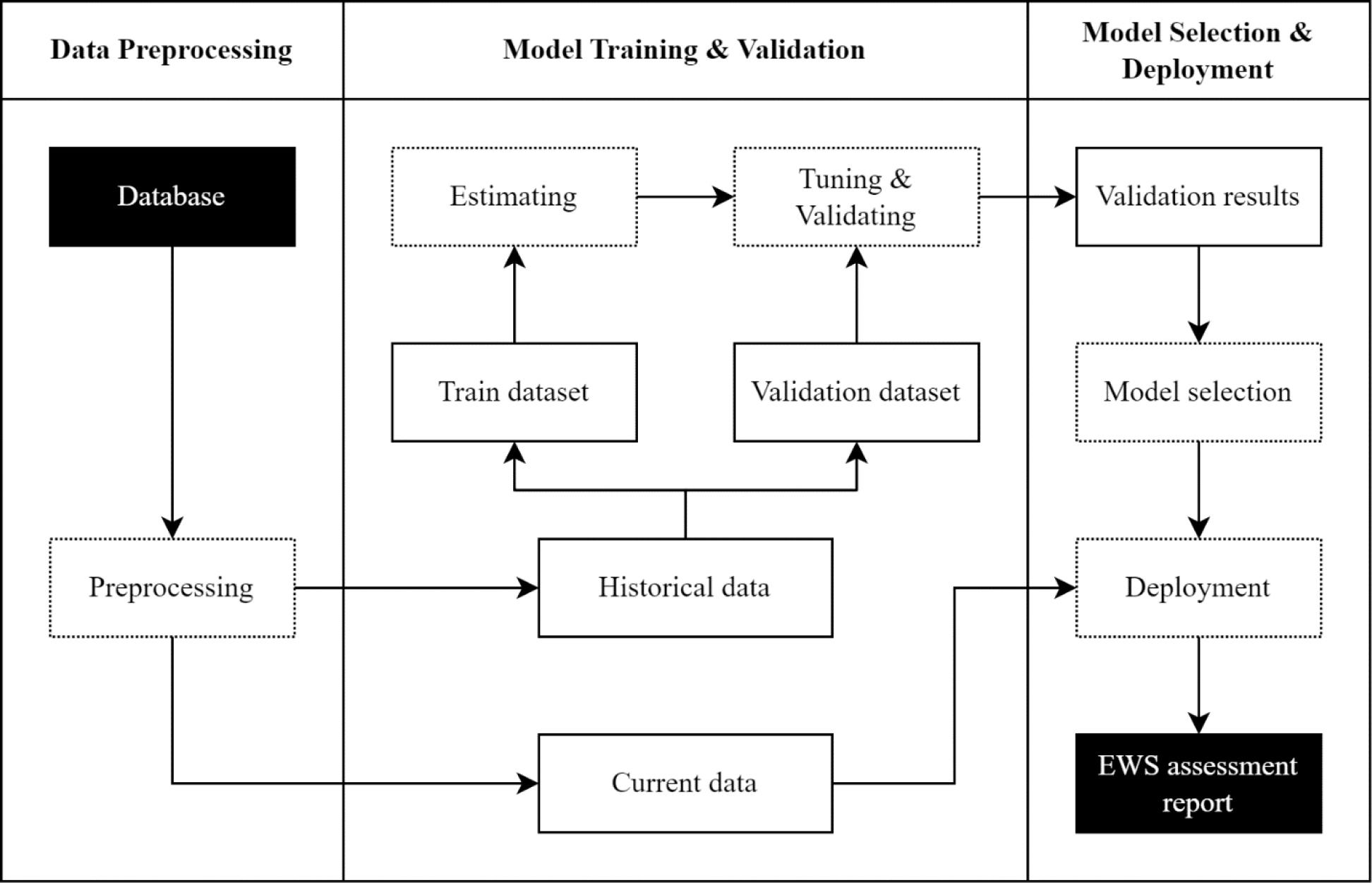
Figure 5.
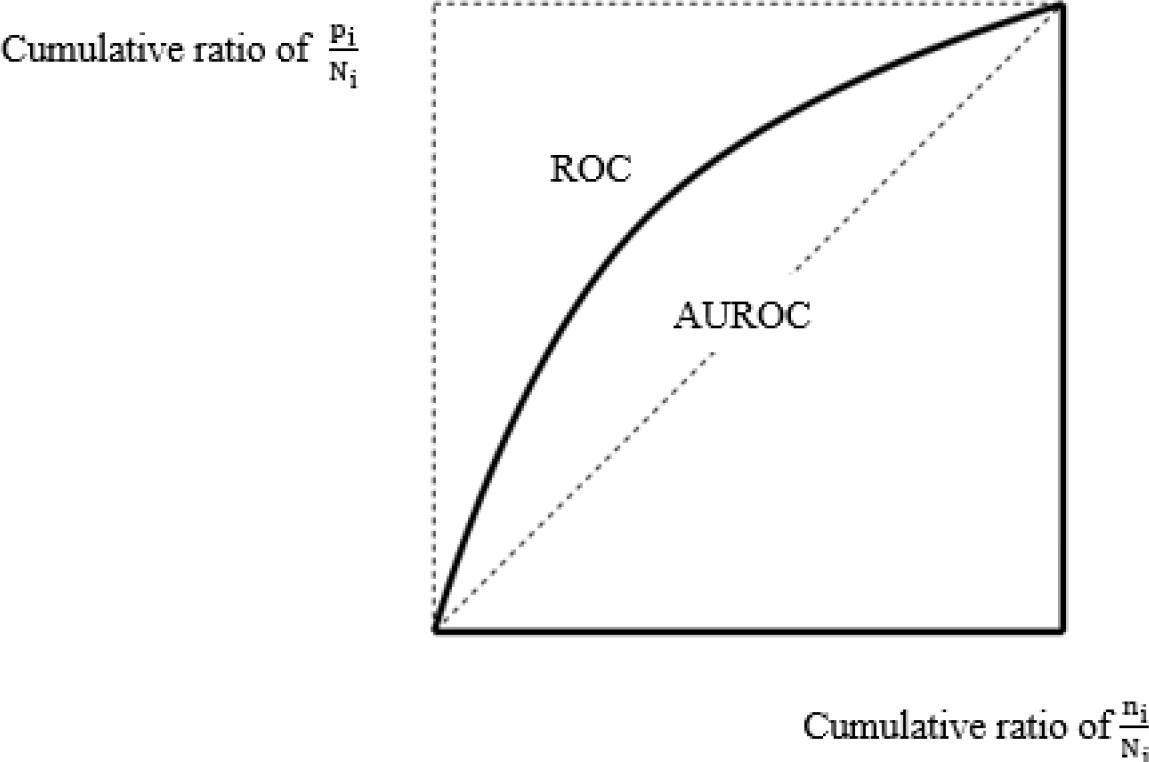
Figure 6.
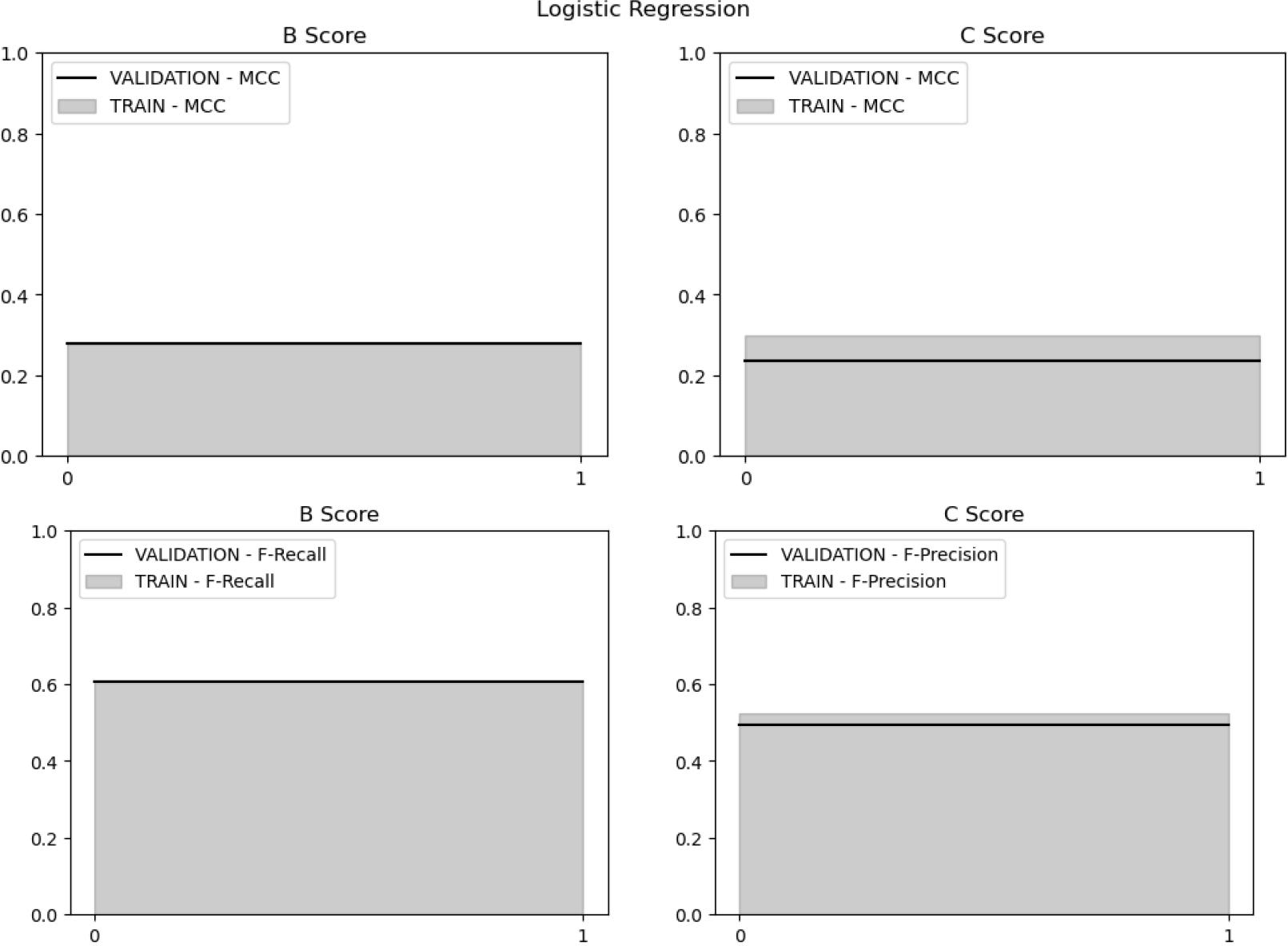
Figure 7.
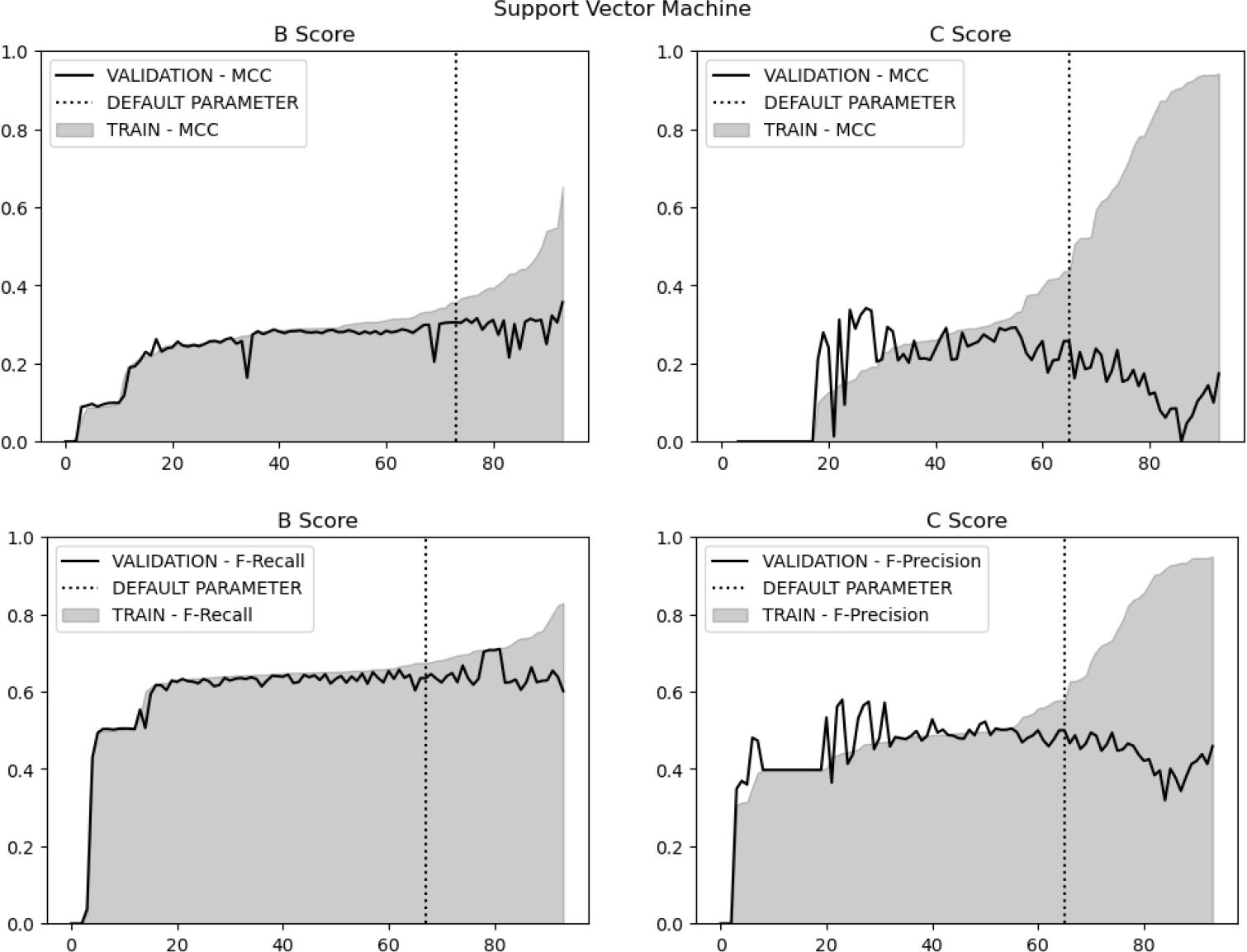
Figure 8.
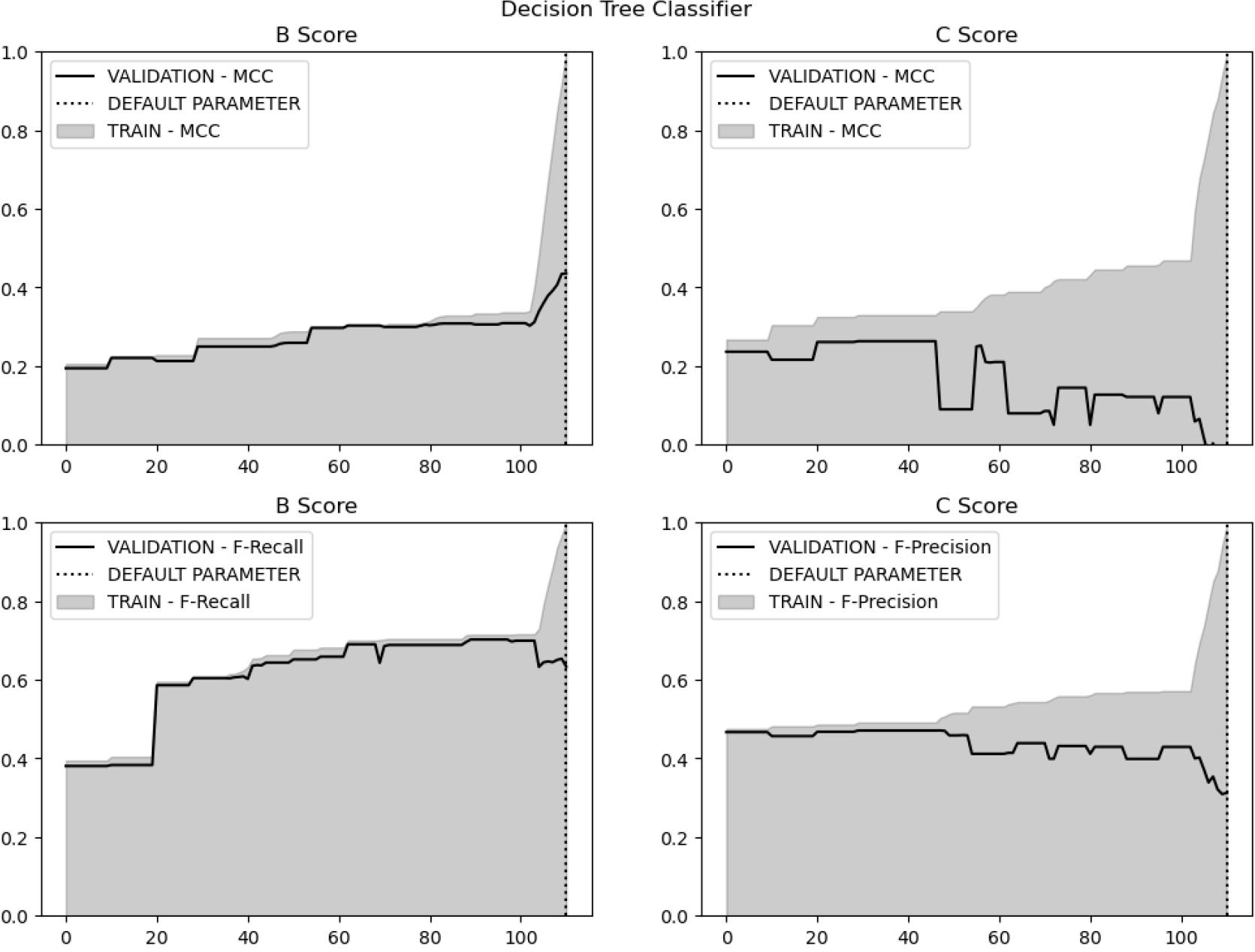
Figure 9.
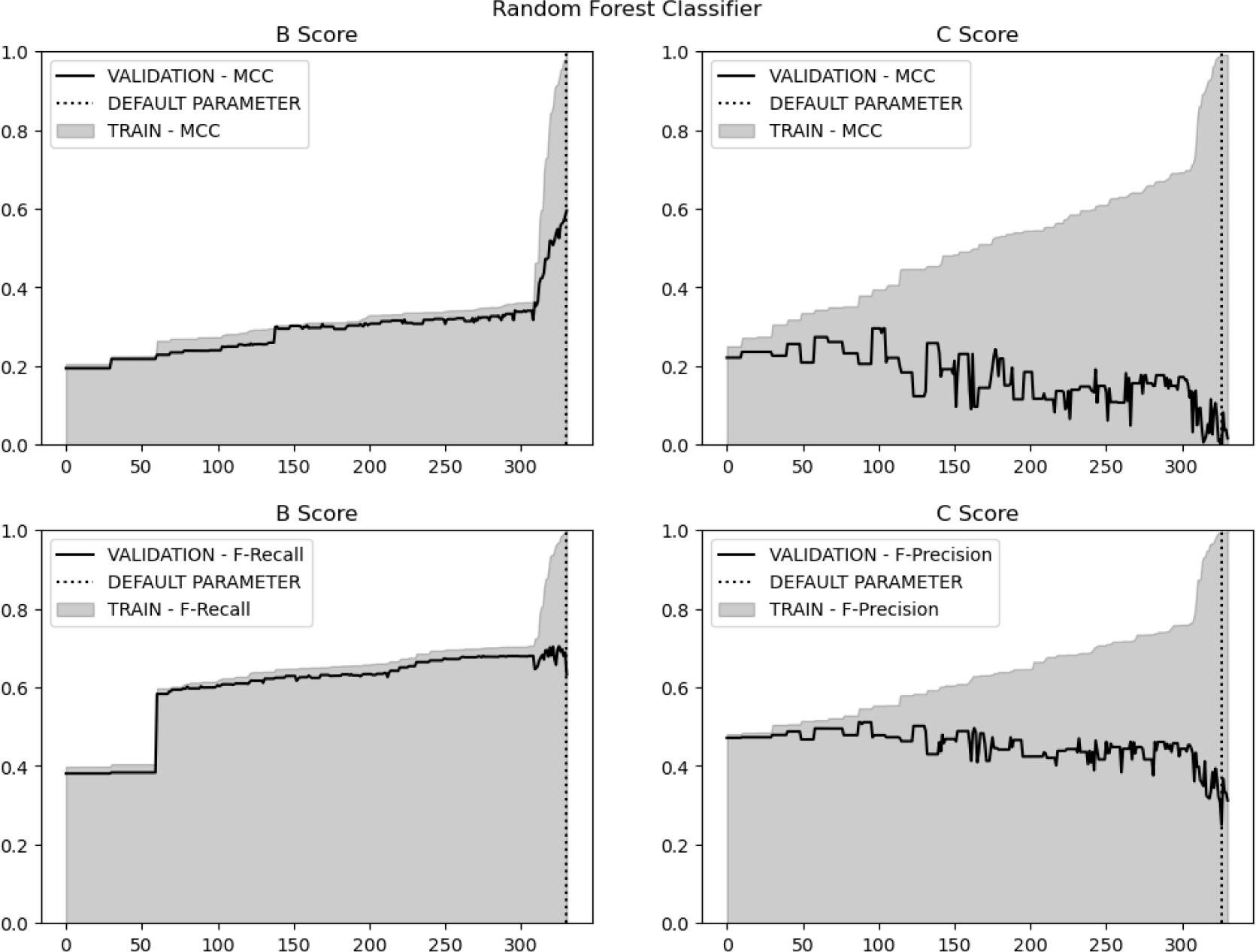
Figure 10.
The results of the evaluation criteria for the B Score model (Source: Author’s own calculation)
| Dataset | Criteria (%) | Tuned by MCC | Tuned by F-Recall | ||||||
| LR | SVM | DT | RF | LR | SVM | DT | RF | ||
| Train | Accuracy | 64.62 | 83.22 | 96.29 | 99.06 | 64.62 | 47.05 | 50.31 | 96.11 |
| Recall | 65.19 | 86.98 | 98.20 | 99.97 | 65.19 | 91.53 | 90.05 | 99.10 | |
| Precision | 47.59 | 69.86 | 91.29 | 97.27 | 47.59 | 37.73 | 39.19 | 90.15 | |
| F1 | 55.02 | 77.48 | 94.62 | 98.60 | 55.02 | 53.44 | 54.61 | 94.41 | |
| F-Recall | 60.70 | 82.91 | 96.74 | 99.42 | 60.70 | 71.22 | 71.49 | 97.17 | |
| F-Precision | 50.31 | 72.72 | 92.59 | 97.80 | 50.31 | 42.76 | 44.18 | 91.81 | |
| MCC | 27.92 | 65.34 | 91.94 | 97.92 | 27.92 | 19.60 | 22.82 | 91.68 | |
| Validation | Accuracy | 64.66 | 70.58 | 74.09 | 81.84 | 64.66 | 46.62 | 50.41 | 79.85 |
| Recall | 64.98 | 61.58 | 66.95 | 67.45 | 64.98 | 91.48 | 87.83 | 70.78 | |
| Precision | 47.62 | 55.08 | 59.79 | 75.26 | 47.62 | 37.52 | 39.02 | 69.20 | |
| F1 | 54.96 | 58.15 | 63.17 | 71.14 | 54.96 | 53.22 | 54.04 | 69.98 | |
| F-Recall | 60.56 | 60.16 | 65.39 | 68.88 | 60.56 | 71.04 | 70.26 | 70.46 | |
| F-Precision | 50.31 | 56.27 | 61.10 | 73.56 | 50.31 | 42.54 | 43.90 | 69.51 | |
| MCC | 27.89 | 35.71 | 43.45 | 58.13 | 27.89 | 18.94 | 21.29 | 54.83 | |
Matrix for different types of alerts (Source: Reihart, et al_, 2010)
| - | The event occurred | The event did not occur |
|---|---|---|
| There is a warning signal | A | B |
| There is no warning signal | C | D |
Summary of parameters of models (Source: Author’s compilation)
| Model | Parameter | Description |
|---|---|---|
| LG | None | The baseline model is a linear regression model combined with the sigmoid (logit) activation function, so no tuning is required |
| SVM | Kernel function | The activation function used to transform data into a different feature space for linear separation includes Linear, Polynomial, Sigmoid, and RBF |
| C | The coefficient for balancing the weight between distance and noise | |
| d | The degree parameter when using the Polynomial kernel, which takes a natural number value | |
| γ | The gamma parameter for Polynomial, Sigmoid, and RBF kernels, which takes a non-negative value | |
| r | The intercept for the Polynomial and Sigmoid kernels | |
| DT | Depth | It is necessary to limit the depth of the DT to avoid overfitting and reduce computational cost |
| Number of leaf nodes | It is necessary to limit the number of leaf nodes of the DT to avoid overfitting and reduce computational cost | |
| RF | Depth | It is necessary to limit the depth of each DT to avoid overfitting and reduce computational cost |
| Number of leaf nodes | It is necessary to limit the number of leaf nodes of each DT to avoid overfitting and reduce computational cost | |
| Number of DTs | The number of DTs in Random Forest Classifier (RF) needs to be considered for computational cost when the number is too high |
Confusion matrix (Source: Author’s illustration)
| Target variable | Predicted: 1 | Predicted: 0 | Total |
|---|---|---|---|
| Actual: 1 | TP: True positives | FN: False negatives | P |
| Actual: 0 | FP: False positives | TN: True negatives | N |
| Total | P + N |
Early warning system deployment for B Score customers (Source: Author’s own calculation)
| Criteria (%) | Tuned by MCC | Tuned by F-Recall | |
|---|---|---|---|
| RF (best) | SVM (best) | RF (second best) | |
| Accuracy | 81.84 → 78.67 | 46.62 → 36.86 | 79.85 → 76.56 |
| Recall | 67.45 → 29.01 | 91.48 → 91.53 | 70.78 → 38.14 |
| Precision | 75.26 → 42.84 | 37.52 → 22.44 | 69.20 → 39.37 |
| F-Recall | 68.88 → 31.01 | 71.04 → 56.65 | 70.46 → 38.38 |
The results of the evaluation criteria for the C Score model (Source: Author’s own calculation)
| Customer | Model | Selection | Parameters |
|---|---|---|---|
| B Score | Best | RF tuned by MCC | n_estimators = 100; |
| SVM tuned by F-Recall | kernel = ‘sigmoid’; | ||
| Second best | RF tuned by F-Recall | n_estimators = 100; | |
| C Score | Best | SVM tuned by MCC | kernel = ‘poly’; |
| SVM tuned by F-Precision | kernel = ‘poly’; |
Model tuning parameters in Scikit-learn (Source: Author’s own research)
| Model | Parameter | Parameters in Scikit-learn | Range of values for tuning |
|---|---|---|---|
| LG | None | None | None |
| SVM | Kernel function | kernel: accepts a value from ‘linear’, ‘poly’, ‘rbf’, ‘sigmoid’. The default value is ‘rbf’ | ‘linear’, ‘poly’, ‘rbf’, ‘sigmoid’ |
| C | C: data type is float; the default value is 1 | 0.01, 0.1, 1, 10 | |
| d | degree: data type is integer; the default value is 3 | 2, 3, 4, 5 (this is applicable only when kernel is set to ‘poly’) | |
| γ | Gamma: accepts a value from ‘scale’, ‘auto’. The default value is ‘scale’. It can also be specified as a non-negative float | 0.01, 0.1, 1, 10 (not applicable when kernel is set to ‘linear’) | |
| DT | Depth | max_depth: data type is integer or none. The default value is none, which means the tree is expanded until the maximum depth is reached | The range from 2 to 21 (with a step size of 2) and none |
| Number of leaf nodes | max_leaf_nodes: data type is integer or None. The default value is none, which means an unlimited number of leaf nodes will be developed, regardless of max_depth | The range from 2 to 21 (with a step size of 2) and none | |
| RF | Depth | Similar to DT | Similar to DT |
| Number of leaf nodes | Similar to DT | Similar to DT | |
| Number of DTs | n_estimators, data type is integer. The default value is 100 | 10, 50, 100 |
Early warning system deployment for C Score customers (Source: Author’s own calculation)
| Criteria (%) | Tuned by MCC | Tuned by F-Precision |
|---|---|---|
| SVM (best) | SVM (best) | |
| Accuracy | 70.78 → 61.94 | 71.60 → 65.54 |
| Recall | 53.57 → 54.48 | 45.24 → 50.00 |
| Precision (*) | 58.44 → 40.33 | 62.30 → 43.79 |
| F-Precision (*) | 57.40 → 42.54 | 57.93 → 44.91 |