

Figure 1
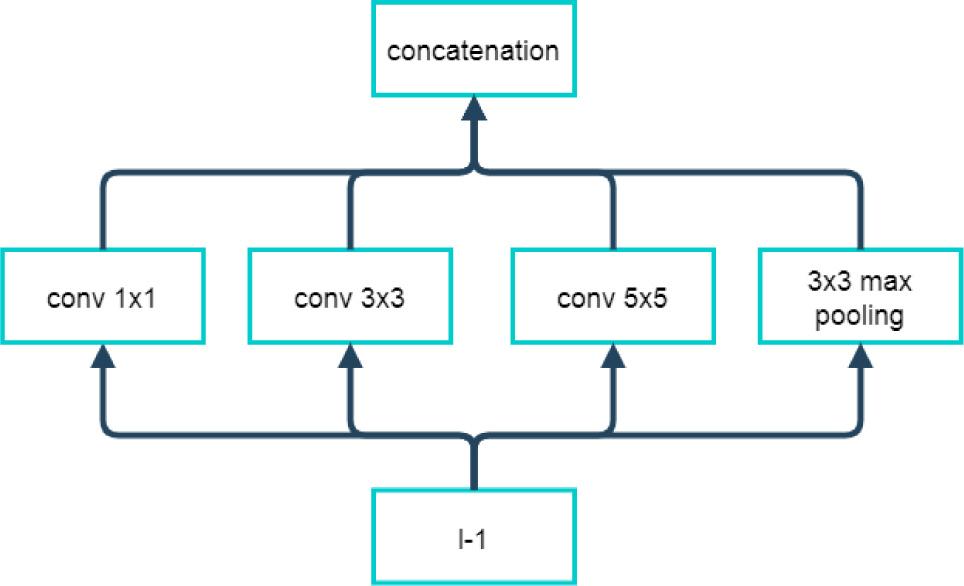
Figure 2

Figure 3
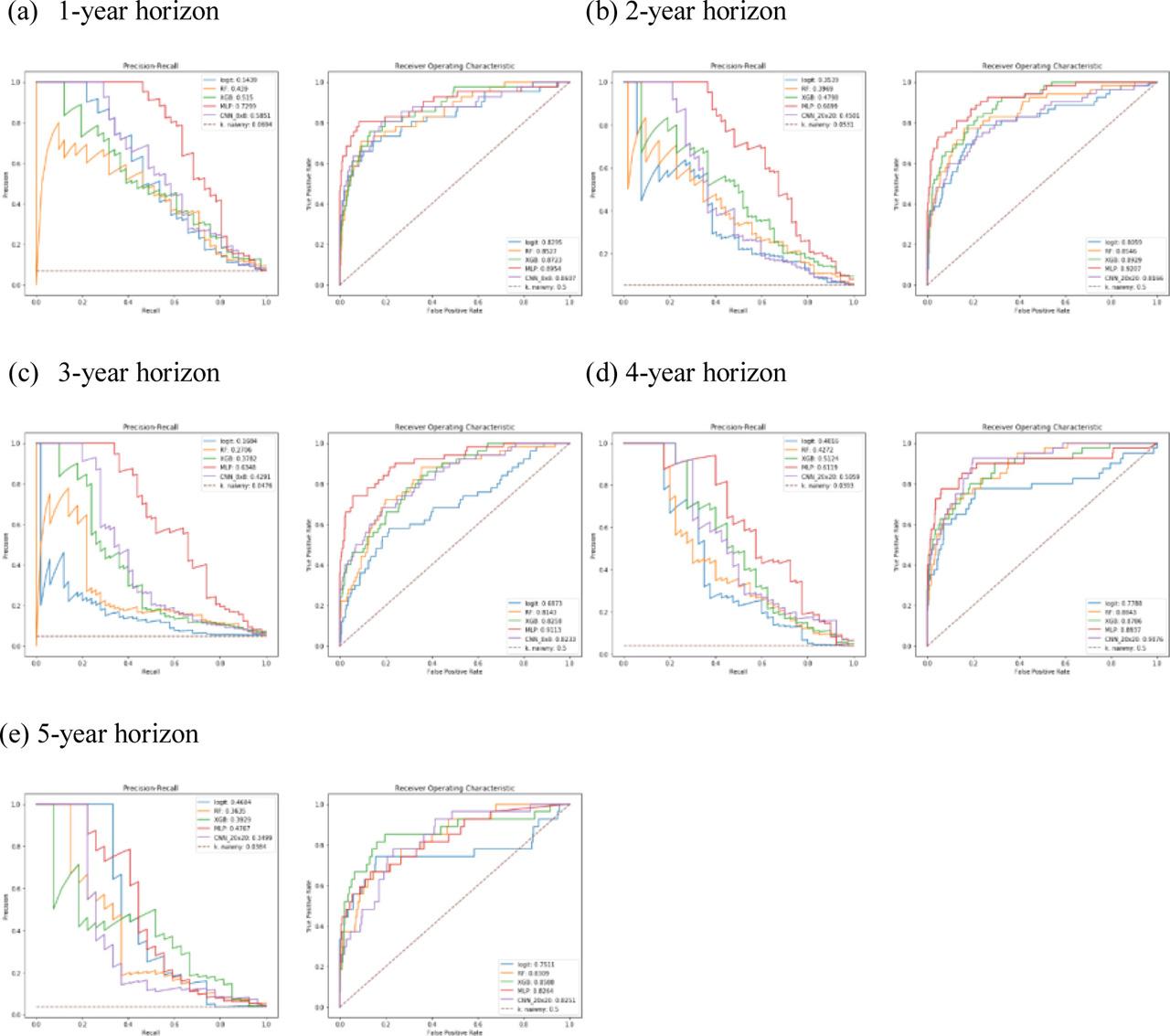
Figure A1

Figure A2

Figure A3

Figure A4

Figure A5

Figure A6

Figure A7

Figure A8

MLP and convolutional neural networks: hyperparameters and results for best networks, all horizons
| Network | Horizon (balance) | 1 year (6.94%) | 2 years (5.25%) | 3 years (4.71%) | 4 years (3.93%) | 5 years (3.86%) |
|---|---|---|---|---|---|---|
| MLP neural networks | Architecture | |||||
| dense layer | + | + | + | + | + | |
| neurons | 60 | 60 | 60 | 60 | 60 | |
| activation | tanh | tanh | tanh | tanh | tanh | |
| dropout | 0.4 | 0.4 | 0.4 | 0.4 | ||
| regularisation | L1 0.00005 | L1 0.00005 | L2 0.00005 | L1 0.00005 | ||
| dense layer | + | + | + | + | + | |
| neurons | 60 | 60 | 60 | 60 | 60 | |
| activation | sigmoid | sigmoid | sigmoid | sigmoid | sigmoid | |
| dropout | 0.4 | 0.4 | 0.4 | 0.4 | 0.4 | |
| regularisation | L1 0.00005 | L1 0.00005 | L2 0.00005 | L1 0.00005 | ||
| dense layer | + | + | + | + | + | |
| Neurons | 1 | 1 | 1 | 1 | 1 | |
| activation | sigmoid | sigmoid | sigmoid | sigmoid | sigmoid | |
| early stopping | 4,873 | 3,972 | 4,892 | 6,843 | 7,243 | |
| batch size | 394 | 394 | 394 | 394 | 394 | |
| Optimiser | Adam | Adam | Adam | Adam | Adam | |
| Results | ||||||
| AUC-PR | 0.717 | 0.611 | 0.632 | 0.629 | 0.519 | |
| overfitting PR | 0.238 | 0.214 | 0.35 | 0.282 | 0.34 | |
| AUC-ROC | 0.929 | 0.895 | 0.9 | 0.909 | 0.883 | |
| overfitting ROC | 0.065 | 0.079 | 0.098 | 0.085 | 0.106 | |
| 8×8 convolutional neural networks | Architecture | |||||
| inception module | + | + | − | + | + | |
| #F1 | 4 | 4 | 4 | 4 | ||
| #F2in/#F2out | 1/4 | 1/4 | 1/4 | 1/4 | ||
| #F3in/#F3out | 1/4 | 1/4 | 1/4 | 1/4 | ||
| #F4out | 4 | 4 | 4 | 4 | ||
| Activation | ReLU | ReLU | ReLU | ReLU | ||
| inception module | + | + | − | + | + | |
| #F1 | 8 | 8 | 8 | 8 | ||
| #F2in/#F2out | 4/8 | 4/8 | 4/8 | 4/8 | ||
| #F3in/#F3out | 4/8 | 4/8 | 4/8 | 4/8 | ||
| #F4out | 8 | 8 | 8 | 8 | ||
| Activation | ReLU | ReLU | ReLU | ReLU | ||
| Convolution | − | − | + | − | − | |
| Size | 3 × 3 | |||||
| #F | 32 | |||||
| Padding | same | |||||
| Stride | 1 × 1 | |||||
| Activation | ReLU | |||||
| Convolution | − | − | + | − | − | |
| Size | 3 × 3 | |||||
| #F | 64 | |||||
| Padding | same | |||||
| Stride | 1 × 1 | |||||
| Activation | ReLU | |||||
| Max pooling | − | − | + | − | − | |
| Size | 2 × 2 | |||||
| Padding | Valid | |||||
| Stride | 2 × 2 | |||||
| Convolution | − | − | + | − | − | |
| Size | 1 × 1 | |||||
| #F | 32 | |||||
| Stride | 1 × 1 | |||||
| Activation | ReLU | |||||
| Average pooling | + | + | − | + | + | |
| Size | 2 × 2 | 2 × 2 | 2 × 2 | 2 × 2 | 2 × 2 | |
| Padding | valid | valid | valid | valid | ||
| Stride | 2 × 2 | 2 × 2 | 2 × 2 | 2 × 2 | 2 × 2 | |
| flatten layer | + | + | + | + | + | |
| dense layer | + | + | + | + | + | |
| Neurons | 256 | 256 | 512 | 256 | 256 | |
| Activation | ReLU | ReLU | sigmoid | ReLU | ReLU | |
| Dropout | 0.4 | 0.4 | 0.4 | 0.4 | ||
| regularisation | L1 0.000025 | L2 0.00005 | L2 0.00005 | L2 0.0001 | L2 0.00005 | |
| dense layer | − | − | + | + | − | |
| neurons | 256 | 128 | ||||
| activation | sigmoid | ReLU | ||||
| dropout | ||||||
| regularisation | L2 0.00005 | L2 0.00005 | ||||
| dense layer | + | + | + | + | + | |
| neurons | 1 | 1 | 1 | 1 | 1 | |
| activation | sigmoid | sigmoid | sigmoid | sigmoid | sigmoid | |
| early stopping | 418 | 350 | 112 | 220 | 326 | |
| batch size | 394 | 394 | 394 | 394 | 394 | |
| optimiser | Adam | Adam | RMSprop | Adam | Adam | |
| Results | ||||||
| AUC-PR | 0.547 | 0.393 | 0.392 | 0.342 | 0.306 | |
| overfitting PR | 0.219 | 0.404 | 0.43 | 0.414 | 0.392 | |
| AUC-ROC | 0.885 | 0.828 | 0.84 | 0.814 | 0.793 | |
| overfitting ROC | 0.07 | 0.147 | 0.136 | 0.156 | 0.169 | |
| 20 × 20 convolutional neural networks | early stopping | 189 | 157 | 137 | 155 | 239 |
| Results | ||||||
| AUC-PR | 0.542 | 0.456 | 0.401 | 0.394 | 0.345 | |
| overfitting PR | 0.233 | 0.447 | 0.489 | 0.576 | 0.553 | |
| AUC-ROC | 0.881 | 0.846 | 0.837 | 0.847 | 0.811 | |
| overfitting ROC | 0.074 | 0.143 | 0.152 | 0.151 | 0.173 | |
Hyperparameters and results for the best models, all horizons
| Model | Horizon (balance) | 1 year (6.94%) | 2 years (5.25%) | 3 years (4.71%) | 4 years (3.93%) | 5 years (3.86%) |
|---|---|---|---|---|---|---|
| Logit | λ | 1 | 0.08 | 0 | 0.05 | 0.03 |
| Results | ||||||
| AUC-PR | 0.497 | 0.28 | 0.251 | 0.221 | 0.27 | |
| overfitting PR | 0.05 | 0.067 | 0.035 | 0.07 | 0.075 | |
| AUC-ROC | 0.852 | 0.782 | 0.762 | 0.726 | 0.764 | |
| overfitting ROC | 0.003 | 0.022 | 0.03 | 0.04 | 0.036 | |
| Random forests | max depth | 12 | 12 | 13 | 12 | 8 |
| max number of characteristics | 52 | 58 | 54 | 55 | 33 | |
| min observations to divide | 4 | 18 | 8 | 10 | 5 | |
| min observations in the leaf | 4 | 17 | 6 | 9 | 4 | |
| number of trees | 200 | 200 | 200 | 600 | 100 | |
| preprocessing | q+n | p+n | - | q+p+n | p+n | |
| Results | ||||||
| AUC-PR | 0.535 | 0.337 | 0.284 | 0.292 | 0.264 | |
| overfitting PR | 0.416 | 0.412 | 0.67 | 0.603 | 0.564 | |
| AUC-ROC | 0.89 | 0.84 | 0.829 | 0.817 | 0.795 | |
| overfitting ROC | 0.1 | 0.1367 | 0.168 | 0.175 | 0.192 | |
| XGBoost | max depth | 6 | 7 | 5 | 5 | 4 |
| learning rate η | 0.08 | 0.03 | 0.07 | 0.1 | 0.07 | |
| column fraction | 0.8 | 0.8 | 1 | 0.8 | 0.9 | |
| raw fraction | 0.9 | 0.9 | 0.9 | 0.9 | 0.8 | |
| loss reduction γ | 3 | 5 | 0.08 | 4 | 2 | |
| regularisation L1 | 0.4 | 1 | 1 | 0.4 | 0.1 | |
| regularisation L2 | 0.4 | 0.2 | 0 | 1 | 0.3 | |
| preprocessing | q+n | - | q+n | - | n | |
| estimators median | 122 | 271 | 209 | 246 | 164 | |
| Results | ||||||
| AUC-PR | 0.596 | 0.411 | 0.39 | 0.392 | 0.355 | |
| overfitting PR | 0.392 | 0.52 | 0.598 | 0.571 | 0.54 | |
| AUC-ROC | 0.909 | 0.869 | 0.864 | 0.86 | 0.835 | |
| overfitting ROC | 0.09 | 0.124 | 0.136 | 0.137 | 0.145 | |