
Figure 1:

Figure 2:
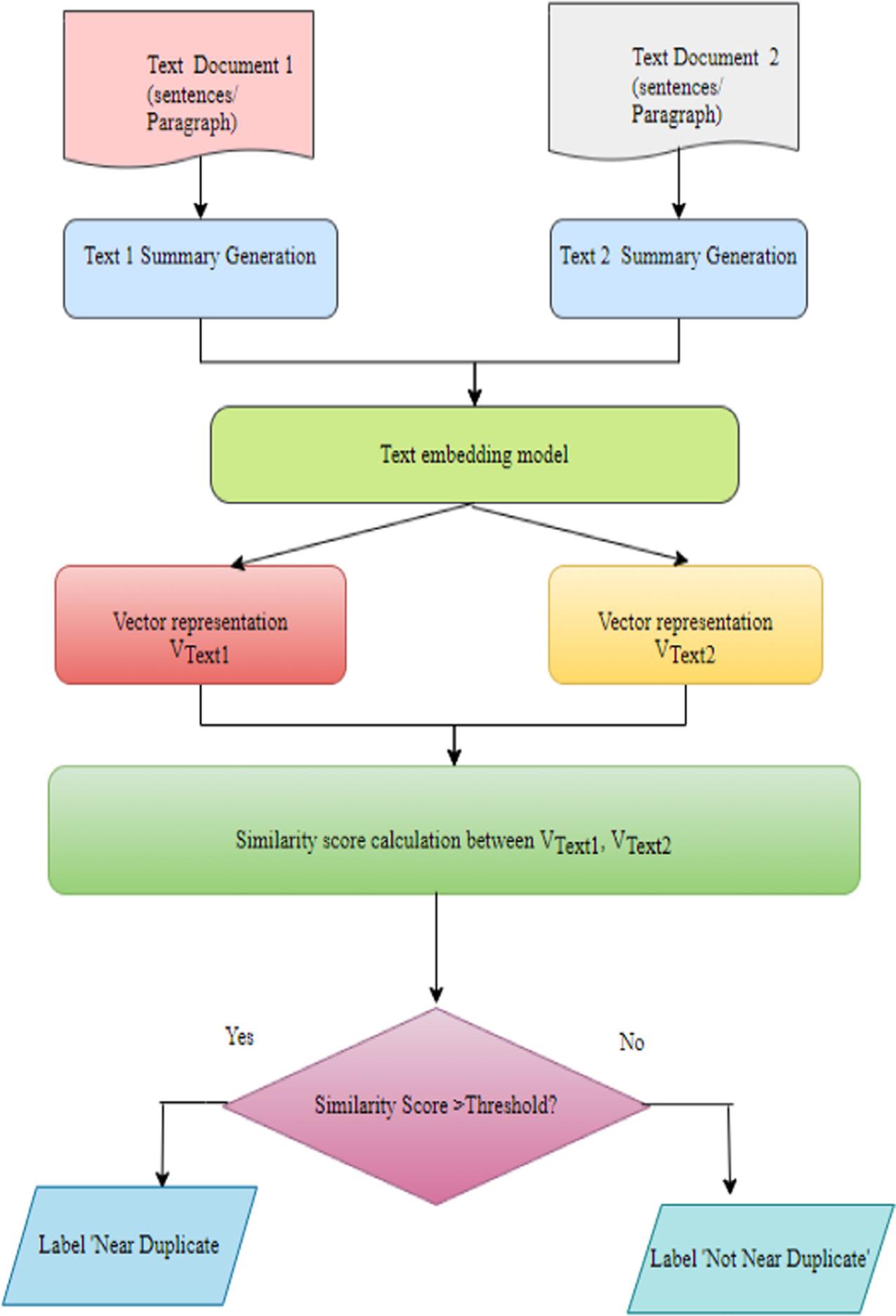
Figure 3:
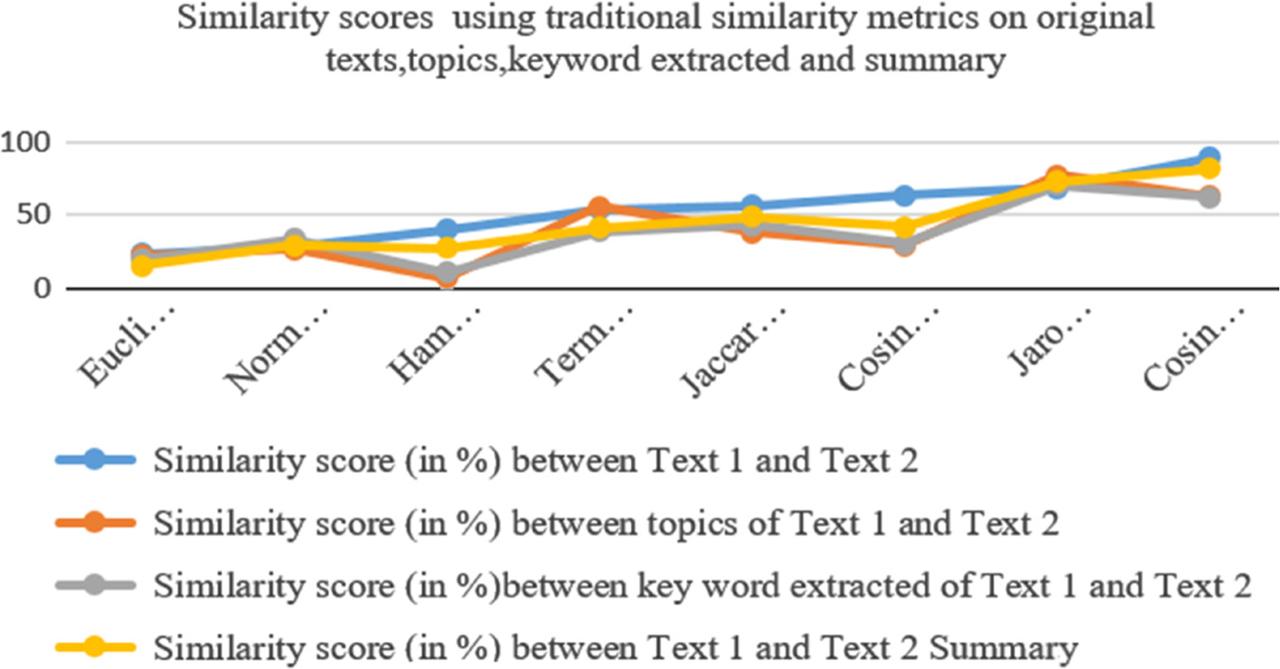
Figure 4:
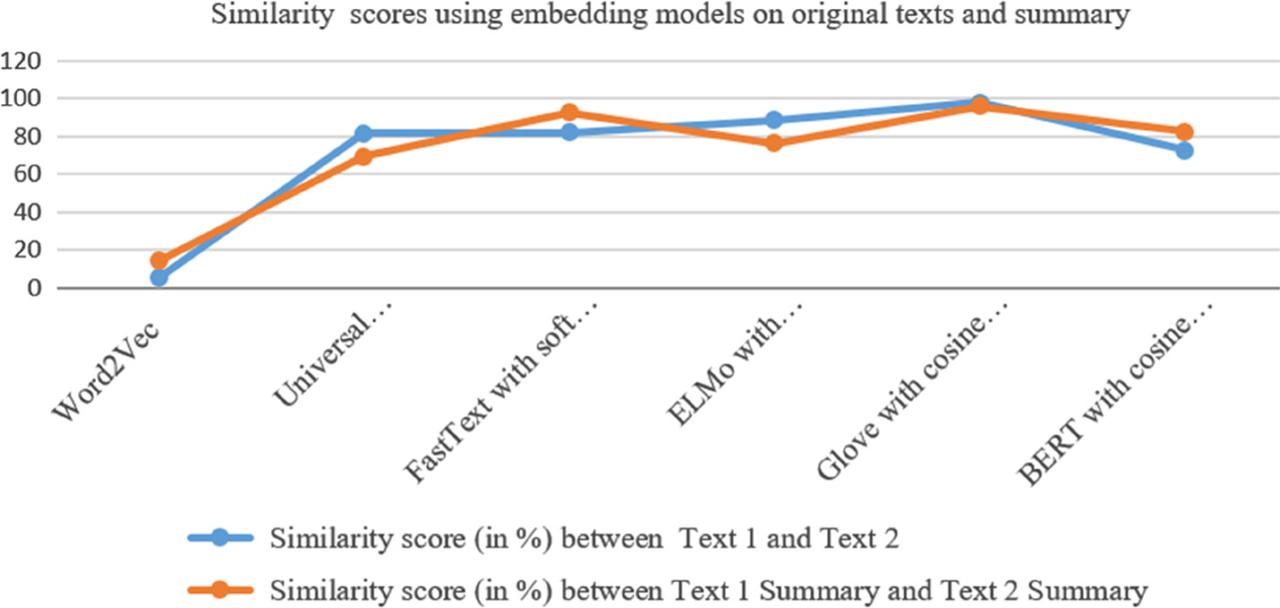
Figure 5:
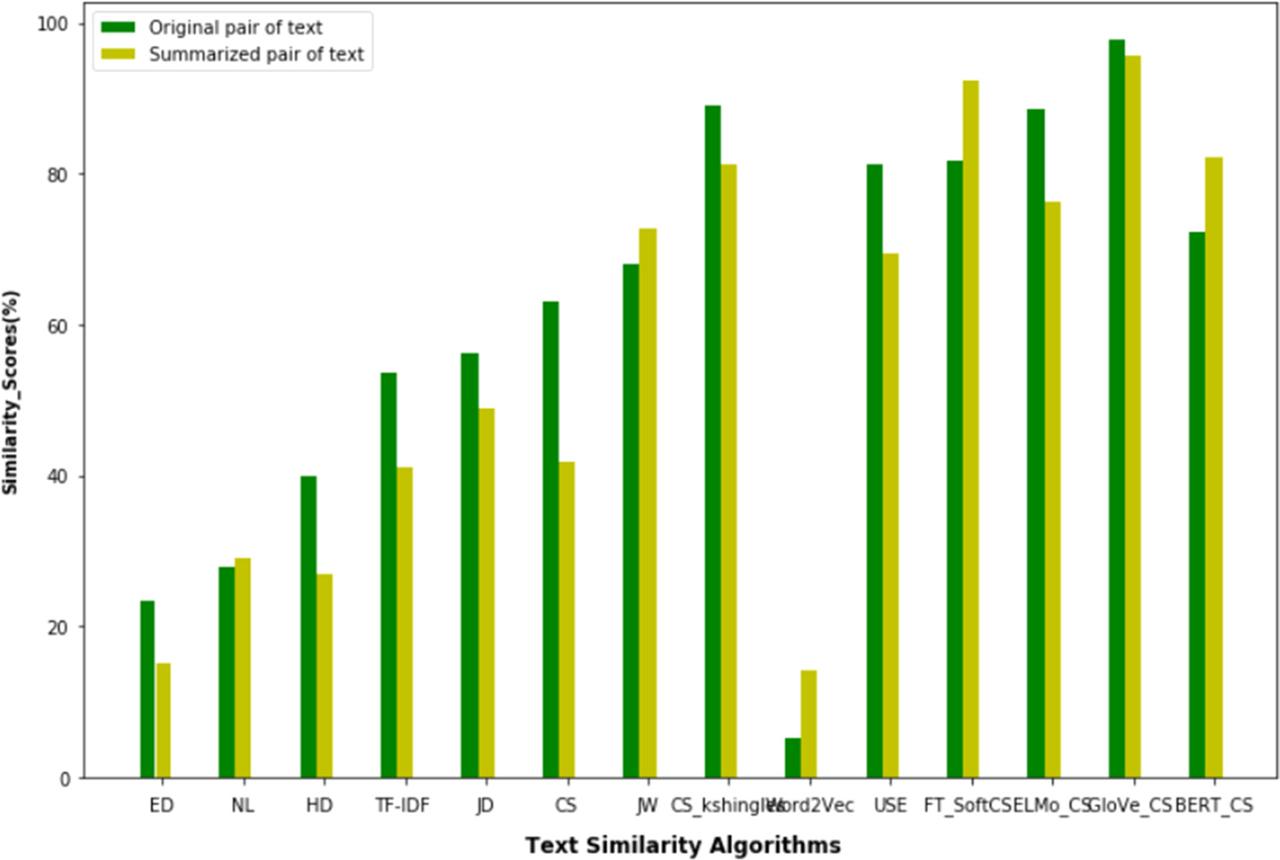
Figure 6:
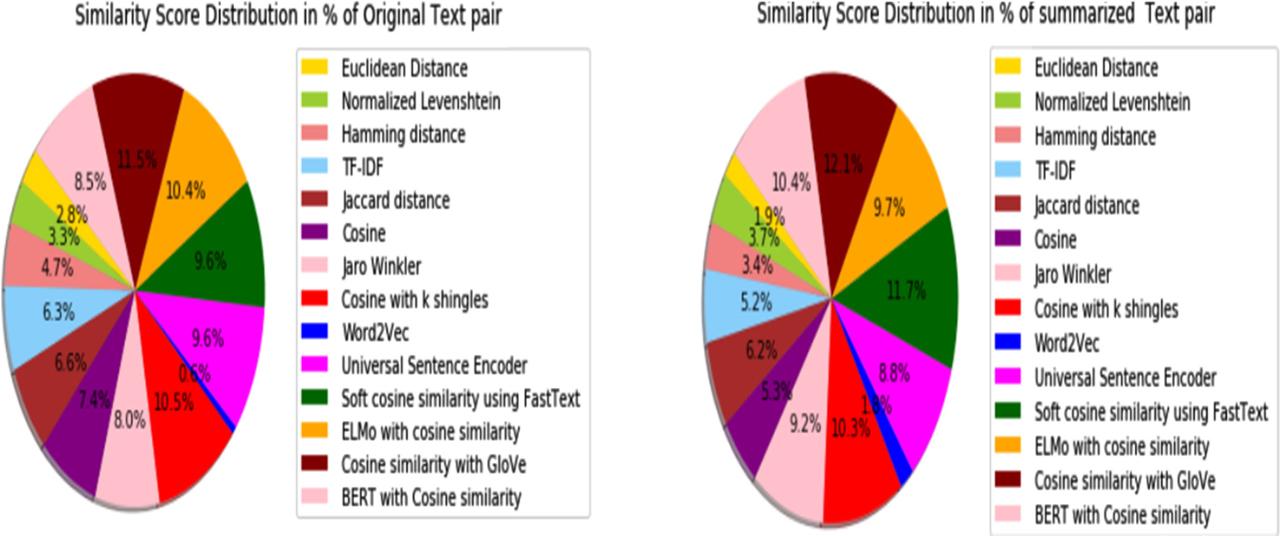
Figure 7:
Figure 8:
Input texts_
| Input | Original text |
|---|---|
| Text 1 | “Everyday large volume of data is gathered from different sources and are stored since they contain valuable piece of information. The storage of data must be done in efficient manner since it leads in difficulty during retrieval. Text data are available in the form of large documents. Understanding large text documents and extracting meaningful information out of it is time-consuming tasks. To overcome these challenges, text documents are summarized in with an objective to getrelated information from a large document or a collection of documents. Text mining can be used for this purpose. Summarized text will have reduced size as compare to original one. In this review, we have tried to evaluate and compare different techniques of Text summarization.” |
| Text 2 | “In the view of a significant increase in the burden of information over and over the limit by the amount of information available on the internet, there is a huge increase in the amount of information overloading and redundancy contained in each document Extracting important information in a summarized format would help a number of users. It is therefore necessary to have proper and properly prepared summaries. Subsequently, many research papers are proposed continuously to develop new approaches to automatically summarize the text. ''Automatic Text Summarization" is a process to create a shorter version of the original text (one or more documents) which conveys information present in the documents. In general, the summary of the text can be categorized into two types: Extractive-based and Abstractive-based. Abstractive-based methods are very complicated as they need to address a huge-scale natural language. Therefore, research communities are focusing on extractive summaries, attempting to achieve more consistent, non-recurring and meaningful summaries. This review provides an elaborative survey of extractive text summarization techniques. Specifically, it focuses on unsupervised techniques, providing recent efforts and advances on them and list their strengths and weaknesses points in a comparative tabular manner. In addition, this review highlights efforts made in the evaluation techniques of the summaries and finally deduces some possible” |
Categorization of Text similarity measurement techniques_
| Text similarity measure | Category | Considers semantic? | Approach used | Characteristics |
|---|---|---|---|---|
| String based | Character based | No | Hamming Distance, Levenshtein distance, Damerau-Levenshtein, Needleman-Wunsch, Longest Common Subsequence, Smith-Waterman, Jaro, Jaro-Winkler and N-gram | Used to find typographical mistakes but less efficient text analytics and computationally less effective for large text documents. Used in String matching approximation |
| Token/term based | No | Jaccard similarity Dice’s coefficient Cosine similarity Manhattan distance and Euclidean distance | Useful in case of recognition of term rearrangement | |
| Statistics based | Corpus/knowledge base | Yes | TF-IDF, (Latent Semantic Indexing (LSI)word2Vec, GloVe, Bidirectional Encoder Representations from Transformers (BERT), Latent Semantic Analysis (LSA), LDA | It uses only text representation and does not consider distance between texts |
j_ijssis-2022-0002_TU2
| Algorithm 2: Generation of summary for the input documents present in document_set using Extractive approach |
| 1. function Generate_ Summary(document_set) |
| Input: pair of text documents |
| returns generated summary |
| 2. forall text document in document_set do |
| 3. Pre-processing: Block level breaking of text into key phrases or sentences, Tokenization (sentences), Lemmatization, stemming, stop word removal, POS tagging, Named Entity Recognition |
| 4. Identification of interrelated sentences: Similarity measuring functions are used to find related sentences to be included in the summary |
| 5. Weighting and ranking of selected sentences: Numeric values are assigned to find important features. Higher ranked sentences are selected for summary |
| 6. output_set:= {text 1_summary, text 2_summary}; |
| 7. return output_set // pair of summarized text |
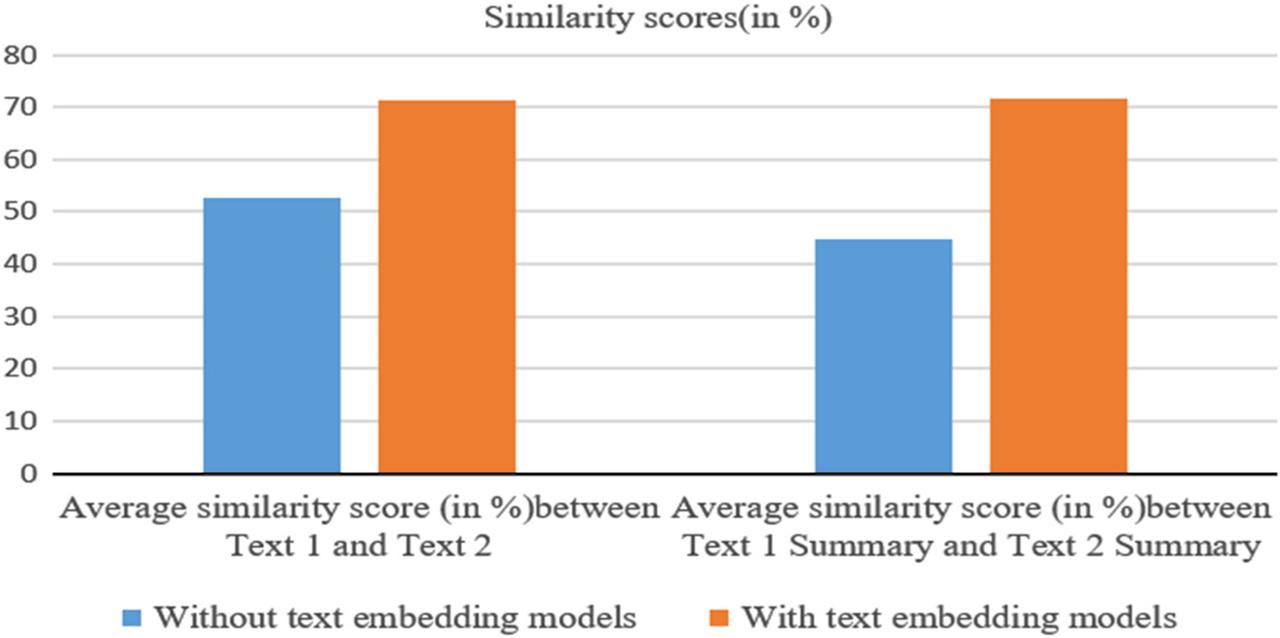
Analysis of impact of embedding models on Text similarity measurement_
| No. of Text similarity algorithms | Approach used | Average similarity score (in %) between Text 1 and Text 2 | Average similarity score (in %) between Text 1 summary and Text 2 summary | Difference (in %) |
|---|---|---|---|---|
| 8 | Without text embedding models | 52.68 | 44.685 | 7.995 |
| 6 | With text embedding models | 71.19 | 71.71 | 0.52 |
j_ijssis-2022-0002_TU3
| Algorithm 3: Text representation using embedding model to generate vectors |
| 1. function Generate_ vector(output_set) |
| Input: Pair of summarized text documents |
| returns vector representation for input document pairs |
| 2. forall summarized text document in output_set do |
| 3. vector_set = embedding_model(output_set); |
| 4. vector_set={VText1, VText2}; |
| 5. return vector_set // pair of vectors |
Topic modeling on original text_
| Topic modelling (using LDA method) on | Topics with weights |
|---|---|
| Text 1 | Topic #1 [(‘different’, 1.06), (‘since’, 1.03), (‘data’, 0.97), (‘try’, 0.88), (‘evaluate’, 0.88), (‘technique’, 0.88), (‘review’, 0.88), (‘summarization’, 0.88)] |
| Topic #2 (‘text’, 1.42), (‘document’, 1.39), (‘large’, 1.16), (‘form’, 1.01), (‘available’, 1.01), (‘summarize’, 0.91), (‘information’, 0.9), (‘meaningful’, 0.85)] | |
| Text 2 | Topic #1 [(‘information’, 1.24), (‘summary’, 1.1), (‘summarize’, 1.05), (‘research’, 1.0), (‘amount’, 0.9), (‘increase’, 0.9), (‘help’, 0.84), (‘would’, 0.84)] |
| Topic #2 [(‘text’, 1.36), (‘based’, 1.34), (‘provide’, 1.08), (‘extractive’, 1.07), (‘summarization’, 1.07), (‘abstractive’, 1.06), (‘technique’, 1.02), (‘summary’, 1.01)] |
j_ijssis-2022-0002_TU1
| Algorithm 1: Near duplicate detection using summarized text |
| 1. document_set := {Text 1, Text 2}, threshold := ø // Initialize |
| 2. function Near_Duplicate_Detection(document_set) |
| Input: Pair of text documents |
| returns labeled documents as near duplicate or non-duplicate |
| 3. output_set=Generate_ Summary(document_set) ; // Phase 1: Generation of summary |
| 4. vector_set = Generate_ vector(output_set) ; // Phase 2: Text representation |
| 5. similarity_score=calculate_similarity_score(vector_set; // Similarity score calculation |
| 6. if similarity_score > ø then // comparison with threshold |
| 7. label ‘Near Duplicate’ |
| 8. else |
| 9. label ‘ Non Duplicate’ |
| 10. end function |
j_ijssis-2022-0002_TU4
| Algorithm 4: Similarity score calculation for summarized text vectors |
| 1. function calculate_similarity_score (vector_set) |
| Input: pair of vectors |
| returns similarity scores of the summarized text documents |
| 2. similarity_score = similarity_function(vector_set) |
| 3. return similarity_score |
Text representation techniques_
| Text representation method | Concept used | Characteristics | Merits | Demerits |
|---|---|---|---|---|
| Vector Space Model | Word count/BOW model | It uses the concept of linear algebra to compute similarity | Simple to compute based on the frequency of words | Ignore the importance of rare words |
| Document vectors | TF-IDF vectors | It also computes the count of documents in which a particular word is present along its significance | It does not give importance to most frequent words in the document which does not contribute much in similarity computation | Does not consider the semantic aspect |
| Embedding model | Word embedding | These are the high dimensional representations of words | Handle words having similar meaning i.e., synonyms. Does not require any feature engineering | It cannot be applied directly in the computation of text similarity |
| Topic modeling | Latent Dirichlet Allocation(LDA) | Documents are represented by inherent latent topics where each topic can be drawn as probability of distribution of words | Probabilistic model, for defining feature matrix of a document based on semantics | Requires prior knowledge of the number of and it does not capture correlation |
Result analysis_
| Similarity function | Original text | Summarized text | |
|---|---|---|---|
| Without embedding model | Jaro Winkler [JW] | 68 | 72.80 |
| Cosine similarity with k shingles [CS_kshingles] | 89.0 | 81.30 | |
| With embedding model | Soft cosine similarity using FastText [FT_SoftCS] | 81.76 | 92.40 |
| Cosine similarity with GloVe (GloVe_CS) | 97.89 | 95.60 |
Conventional near duplicate detection techniques_
| Category | Approach | Characteristics | Merits |
|---|---|---|---|
| Keyword based | BOW (Bag of Words) | Comparing words and frequency of words with respect to other documents | Used in large documents uses Term Frequency -Inverse Document Frequency (TF-IDF) to create fingerprints. Reduces storage space |
| Fingerprint based | Shingling | Compares short phrases adding context to the word | Fingerprints are created with tokenized documents by using overlapped substrings and consecutive words. Statistical concepts are used to find near duplicates |
| SimHash | Generate fixed length hashes for each document which are stored for duplication detection | Obtain ‘f’ bit fingerprint for each document. Used as dimension reduction | |
| Hash based | MinHash | Phrases are hashed into numbers for comparison to identify duplication and content hashes are stored | It stores a small amount of information for each document for effective comparison |
| Locality Sensitive Hashing (LSH) | Probabilistic approach to detect similar documents. Hash function generated similar hashes for similar shingles | Search space contains only those documents which tend to be similar which maximizes the probability of collision for similar content |
Similarity scores using traditional similarity metrics on original texts, topics, keyword extracted and summary_
| Text similarity measure | Similarity score (in %) between Text 1 and Text 2 | Similarity score (in %) between topics of Text 1 and Text 2 | Similarity score (in %) between key word extracted of Text 1 and Text 2 | Similarity score (in %) between Text 1 and Text 2 Summary |
|---|---|---|---|---|
| Euclidean distance [ED] | 23.70 | 22.40 | 20.03 | 15.36 |
| Normalized Levenshtein [NL] | 27.80 | 26.43 | 33.69 | 29.08 |
| Hamming Distance [HD] | 40.0 | 7.14 | 10.8 | 27.0 |
| Term Frequency-Inverse Document Frequency [TF-IDF] | 53.71 | 55.90 | 38.86 | 41.11 |
| Jaccard Distance [JD] | 56.23 | 38.2 | 42.75 | 48.97 |
| Cosine Similarity [CS] | 63.0 | 29.46 | 30.15 | 41.86 |
| Jaro Winkler [JW] | 68.0 | 76.8 | 70.0 | 72.80 |
| Cosine similarity with k shingles [CS_kshingles] | 89.0 | 62.5 | 61.92 | 81.30 |
Topic modeling on summary of original text_
| Topic modelling (using LDA method) applied on | Topics with weights |
|---|---|
| Text 1 Summary | Topic #1 [(‘document’,0.091),(‘data’,0.065),(‘information’,0.065), (‘piece’,0.039)’,’(‘contain’,0.039), (’summarize’,0.039), (’manner’, 0.039), (‘do’,0.039), (‘must’,0.039), (‘large’, 0.039)] |
| Topic #2 [(‘document’,0.044), (‘information’, 0.044), (‘data’,0.044), (‘source’, 0.044), (‘different,’0.043), (‘valuable’,0.043), (‘lead’, 0.043), (‘challenge’, 0.043), (‘collection’, 0.043), (‘relate’, 0.043] | |
| Text 2 Summary | Topic #1 [(‘information’,0.056),(‘increase’,0.040),(‘effort’,0.040), (‘amount’,0.040), (‘technique’,0.040),(‘specifically‘,0.024), (‘unsupervised‘,0.024),(‘future’,0.024), (‘overload’,0.024),(‘comparative’, 0.024)] |
| Topic #2 [(‘information’,0.027), (‘technique’, 0.027), (‘amount’,0.027), (‘effort’, 0.026), (‘increase’,026), (‘possible’, 0.026), (‘redundancy’,0.026), (‘make’,0.026), (‘summary’,0.026), (‘strength’, 0.026)] |
Key phrase extraction on Text 1 and Text 2 using weighted TF-IDF method_
| Key phrase extraction method applied on | Key phrases with weights |
|---|---|
| Text 1 | [(‘form’, 0.57699999999999996), (‘large documents’, 0.57699999999999996), (‘text data’, 0.57699999999999996),(‘large text documents’, 0.57699999999999996), (‘meaningful information’, 0.57699999999999996), (‘time-consuming tasks’, 0.57699999999999996), (‘different techniques’, 0.57699999999999996), (‘review’, 0.57699999999999996), (‘text summarization’, 0.57699999999999996), (‘different sources’, 0.47599999999999998)] |
| Text 2 | [(‘prepared summaries’, 1.0), (‘abstractive-based methods’, 0.70699999999999996), (‘huge-scale natural language’, 0.70699999999999996), (‘documents’, 0.66700000000000004), (‘summary’, 0.63200000000000001), (‘types’, 0.63200000000000001), (‘elaborative survey’, 0.57699999999999996), (‘extractive text summarization techniques’, 0.57699999999999996), (‘review’, 0.57699999999999996), (‘many research papers’, 0.53400000000000003)] |
Recent research studies on text similarity and representation_
| Concept/algorithm/method used | Author(s) | Usage |
|---|---|---|
| Text similarity (SimHash, MinHash), Text clustering | Pamulaparty et al., 2014, 2015, 2017) Hassanian-esfahania and Karga (2018) | Near Duplicate detection on the basis of keywords generated from text, Fuzzy C means clustering with discriminant function, Random forest method for classification of near duplicates |
| Text similarity | Yung-Shen et al. (2013) Gali et al. (2016) | Near Duplicate detection on the basis of 21 similarity metrics computation between a pair of documents or two titles |
| Signature based text similarity measurement | Mohammadi and Khasteh, 2020 (Hajishirzi et al., 2010) | Reference texts are generated using genetic algorithms to obtain signatures for text documents as a sequence of 3 grams for detection of duplicate and near duplicate documents. For generating signature cosine text similarity measure is used on the datasets on CiteseerX, Enron and Gold Set of Near-duplicate News Articles |
| Text similarity | Do and LongVan (2015) | Near Duplicate detection by applying signatures generated based on ontology on extracted key phrases |
| Text representation methods | Al-Subaihin et al. (2019), Mishra (2019) | TF-IDF combined with LSI for topic modeling, spam classification |
| Text mining, clustering, natural language processing and text similarity | Alqahtani et al. (2021) | Text matching methods |
| Semantic similarity | Chandrasekaran and Mago (2021) | Any NLP task which involves semantic textual similarity |
| Semantic similarity | Roul and Sahoo (2020) | Near Duplicate detection of web pages on DUC dataset |
| Deep learning based semantic similarity | Mansoor et al. (2020) | Sentence similarity using LSTM and CNN per trained with word2vec on Quora dataset |
| Text representation using ELMo model | Peters et al. (2018) | Question answering, Textual entailment, semantic role labelling, Named entity extraction, sentiment analysis |
| Text representation using FastText model | Shashavali et al. (2019) | In goal oriented conversational agents (Chabot) |
| Text similarity based on distance | Stefanovicˇ et al. (2019) | Plagiarism detection |
| Semantic similarity for short text based on corpus, knowledge and deep learning model | Han et al. (2021) | Text classification and text clustering, sentiment analysis, information retrieval, social networks plagiarism detection on the dataset |
| Text classification based on text embedding method | Li and Gong (2021) | Deep Learning Text classification on the dataset Sohu news dataset |
| Text Similarity based on text distance and text representation | Wang and Dong (2020) | Information retrieval, Machine translation, question answering, machine, document matching |
| Text representation using BERT model | Wang et al. (2019) | Extractive-Abstractive Text summarization with BERT embedding model with Reinforcement Learning on CNN/Daily Mail dataset and DUC2002 |
| Word Embedding Model, Text classification, Word tagging | Ajees et al. (2021) Alqrainy and Alawairdhi (2021) | SVM classification to classify animate nouns for Malayalam text, comprehensive tag for Arabic language |
| Lexical Taxonomy | Nazar et al. (2021) | Elimination of incorrect hypernym links, taxonomy with new relations in Spanish, English and French |
Similarity scores using text embedding models on original and summarized document_
| Embedding model | Similarity score (in %) between Text 1 and Text 2 | Similarity score (in %) between Text 1 summary and Text 2 summary |
|---|---|---|
| Word2Vec | 5.28 | 14.26 |
| Universal Sentence Encoder [USE] | 81.36 | 69.39 |
| FastText with soft cosine similarity [FT_SoftCS] | 81.76 | 92.40 |
| ELMo with cosine similarity (ELMo_CS) | 88.59 | 76.32 |
| Glove with cosine similarity (GloVe_CS) | 97.89 | 95.60 |
| BERT with cosine similarity (BERT_CS) | 72.28 | 82.29 |
Different embedding models for text representation (Khattak et al_, 2019; Mishra et al_, 2020)_
| Embedding model | Characteristics | Merits | Demerits | Variants |
|---|---|---|---|---|
| One hot encoding | Maps each word from vocabulary to unique index in vector space | Learn dense representation of words | Dependent on corpus knowledge | – |
| Word2Vec | Maps each word to a point in vector space E.g. | Used in Neural networks for predicting focus words as prediction-based models | Dimension is between 50 and 500. | Doc2Vec |
| GloVe | Term co-occurrence matrix based on vocabulary size is used | Minimized reconstruction error, captures larger dependency due to larger context window, Count based model | Order of dependencies are not preserved; performance depends on data type | GloVe with skip gram window |
| FastText | Sub words are also considered | Extends the functionality of Word2Vec skip gram to handle out of vocabulary (OOV) words | Longer time to train | Probabilistic FastText |
| Embedding from Language Models (ELMo) | Captures context at both word and character level. | Performs sentence level embedding by using bidirectional Recurrent Neural Networks (RNN), can be used in transfer learning | Unable to use left to right and right to left context at the same time | – |
| Bidirectional Encoder Representations from Transformers | Considers n bidirectional representations in unsupervised mode | It can be pre trained using one extra output layer | Random sentence is replaced by special tokens(‘Mask’) to | Robustly Optimized BERT Pre Training Approach (RoBERTa), |
Text summarization on original text_
| Text summarization (using LSA method) on | Generated summary |
|---|---|
| Text 1 | “Everyday large volume of data is gathered from different sources and are stored since they contain valuable piece of information. The storage of data must be done in efficient manner since it leads in difficulty during retrieval. To overcome these challenges, text documents are summarized in with an objective to get related information from a large document or a collection of documents.” |
| Text 2 | “In the view of a significant increase in the burden of information over and over the limit by the amount of information available on the internet, there is a huge increase in the amount of information overloading and redundancy contained in each document. Specifically, it focuses on unsupervised techniques, providing recent efforts and advances on them and list their strengths and weaknesses points in a comparative tabular manner. In addition, this review highlights efforts made in the evaluation techniques of the summaries and finally dedtices some possible future trends.” |
Popular Text similarity metrics (Pamulaparty et al_, 2014, 2015; Gali et al_, 2016; Yung-Shen et al_, 2013)_
| Similarity measurement method | Highlights |
|---|---|
| Euclidean distance | Consider the distance of text in vector form. Uses frequency of tokens to generate feature vectors |
| Cosine | Consider the angle between two vectors. Fails to capture variations of the representation for unstructured/semi structured text |
| Manhattan | Consider the distance between two real vectors |
| Hamming | Consider the count of positions in which two bits are different. Binary strings must be of the same length |
| Jaccard distance | Compute’s length of two strings and then finds common characters to indicate the presence in near locations. Transposition in reverse order is performed to find matching characters between two strings |
| Jaro Winkler | It extends the Jaro distance metric by a prefix value (p = 0.1). This provides a higher value of weights to the strings having common prefix length whose value lies in the range of (Xiao et al., 2008; Khattak et al., 2019) |
| Cosine similarity with k shingles/k gram | Shingling the document means considering consecutive words and grouping as a single entity. A more general approach is to shingle the document. This takes consecutive words and groups them as a single object. In general, the set of all 1-shingles represents the’ bag of words’ model |
| TF-IDF | Based on the concept of term frequency (TF) which is the count of occurrence of a token in a document. The inverse document frequency (IDF) is the way to find the relevance of unique or odd words. Cosine similarity with TF-IDF is used to find similarity scores |
| Normalized Levenshtein | Based on the minimum number of edit operations |
| Soft-TFIDF | TF-IDF and Jaro Winkler are combined to measure similarity. First Jaro Winkler finds pairs of tokens common to both strings and then TF-IDF is used to find similarity scores exceeding the suitable value of threshold set in Jaro Winkler |