
Figure 1

Figure 2
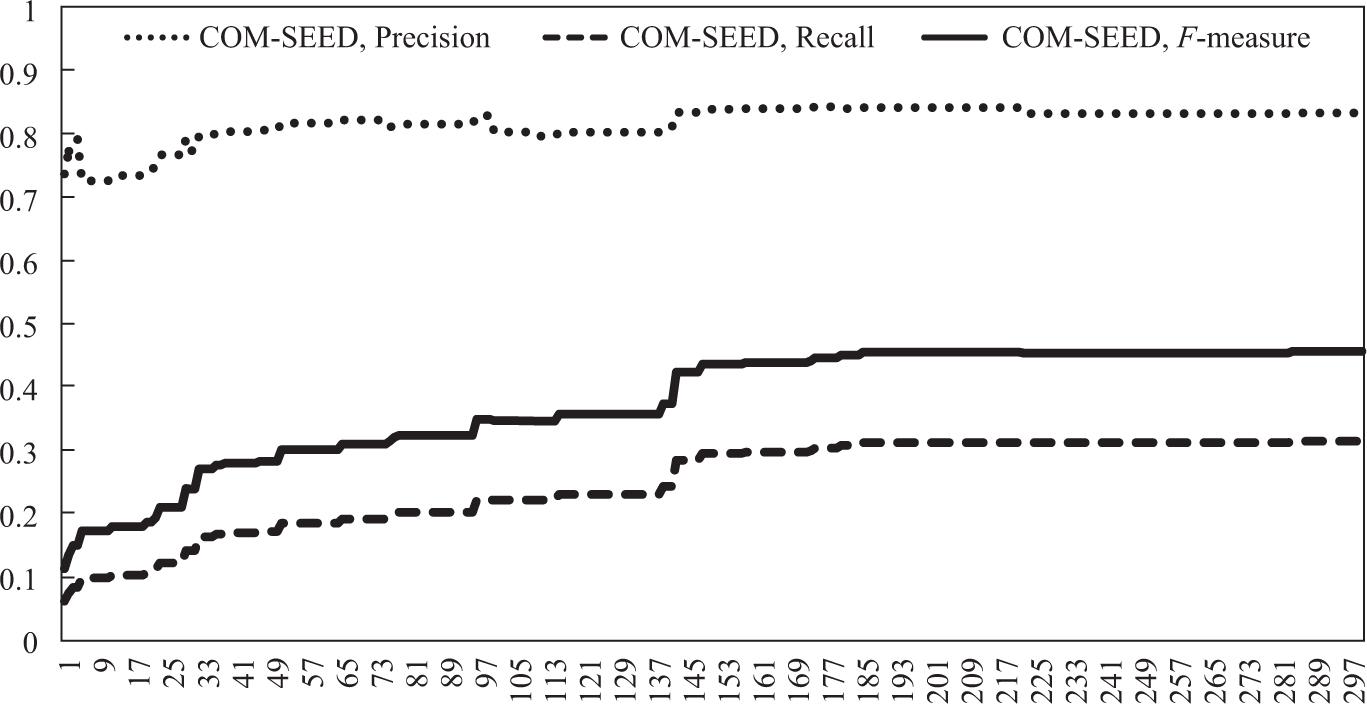
Figure 3

Figure 4
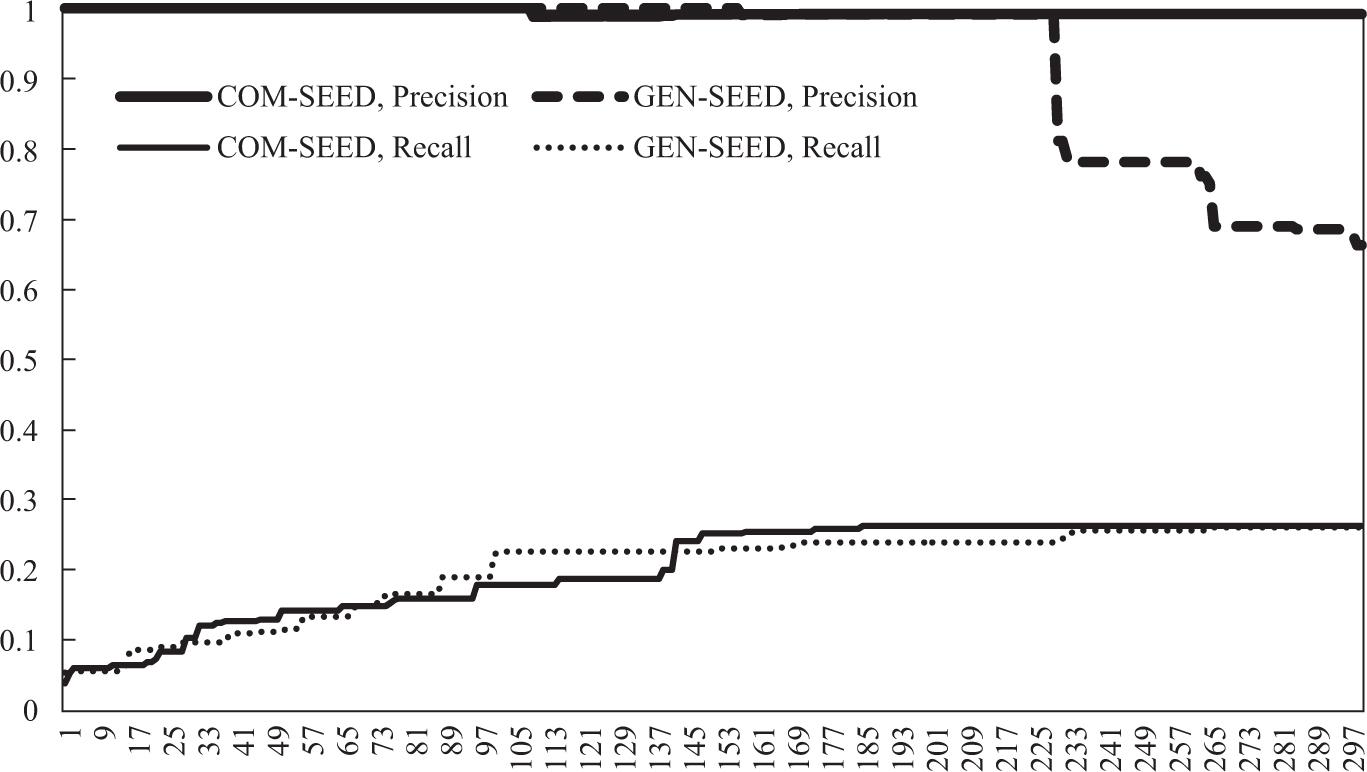
Figure 5

Figure 6

DUS examples_
| Statements | Positive (☑) OR negative (☒) |
|---|---|
| In our experiments, the experimental subset contains 1,552 images selected from the GT database and the FERET databases. | ☑ The name, source, and compositions of data |
| The large-scale database contains 93,638 images captured from 9,668 palms of 4,834 individuals, in which 4–10 images are collected for each palm. | ☑ The source and compositions of data |
| Consequently, both of the two experimental subsets contain 1,200 samples for training and 1,200 samples for testing. | ☑ Data compositions and application |
| In order to show the robustness over short noisy intervals and satisfy the two defined semantics R1 and R2, we generate two completely separated clusters, C1 and C2, using two disjoint interval sequences, Q1 and Q2, and add the synthetically generated short noisy intervals marked in red. Each group contains 10 subjects. | ☒ Algorithm description |
| ☒ Experiment participants | |
| The average training time of the repeated random sub-sampling validation is 1.83 × 30 = 54.9 s, and that of the CBE cross-validation is 1.84 × 5 = 9.2 s. | ☒ Experiment process |
Elementary statistics on extraction results_
| Seed-selection strategy | Pattern | Seed number | Pattern number | Statement number |
|---|---|---|---|---|
| COM-SEED | Predicate + Object | 14,000 | 670 | 29,722 |
| Subject + Predicate | 5,105 | 596 | 11,869 | |
| GEN-SEED | Predicate + Object | 18,235 | 404 | 35,711 |
| Subject + Predicate | 5,530 | 334 | 11,247 |
Exemplifications of pattern construction_
| Pattern | Sentences covered by this pattern and the extracted data_clue words |
|---|---|
| Consists of # samples | The breast cancer set consists of 569 samples with 357 benign and 212 malignant. Dataset 1 is referred to as Char250, which has 250 samples per category for lower and upper cases, respectively; dataset 2 is referred to as Char1000, which has 1,000 samples per category for lower and upper cases, respectively. (Please note this pattern occurs twice here.) |
| We perform experiments | To assess the ability of the proposed clustering algorithm for classifying the shape classes, we perform experiments on an increasing number of shapes in the two Aslan and Tari datasets. We perform our experiments on a real-estate system with real-life house dataset used in. |
Initial seed words_
| Seed-selection strategy | COM-SEED | GEN-SEED |
|---|---|---|
| Initial seed words | tree # | data |
| kdd eup | dataset | |
| tree | corpus | |
| wall street journal | data set | |
| the # kdd eup | ||
| dataset | ||
| corpus |
Precision of statement extraction from CSExperiment-triple (2000–2013)_
| Seed-selection strategy | Pattern | Precision (%) |
|---|---|---|
| COM-SEED | Predicate + Object | 96.34 |
| Subject + Object | 69.67 | |
| Overall | 83.01 | |
| GEN-SEED | Predicate + Object | 95.34 |
| Subject + Predicate | 37.00 | |
| Overall | 66.17 |